基于BPSO和SVM的烟叶近红外有用特征光谱选择
2015-03-10赵海东申金媛刘润杰刘剑君穆晓敏
李 航,赵海东,申金媛,刘润杰,刘剑君,穆晓敏
(1. 郑州大学 信息工程学院,河南 郑州 450001;2.郑州市烟草专卖局,河南 郑州 450006)
基于BPSO和SVM的烟叶近红外有用特征光谱选择
李 航1,赵海东1,申金媛1,刘润杰1,刘剑君2,穆晓敏1
(1. 郑州大学 信息工程学院,河南 郑州 450001;2.郑州市烟草专卖局,河南 郑州 450006)
为提高基于近红外光谱识别烟叶等级的效率,利用BPSO联合SVM对原始光谱数据进行有用特征光谱选择. 利用BPSO将对分级影响不好或没有影响的特征剔除,采用SVM对烟叶的等级进行识别. 结果表明:BPSO选择的最佳特征光谱可减少特征光谱的数目,提高烟叶的正确分级率. 对于相同的光谱范围,采样间隔越大,经过特征光谱选择后,原始光谱数据数目减少的比例越大. 此外,有用特征光谱的选择可以有效地减少光谱数据的采集量,减少了分级模型的计算复杂度,提高烟叶分级的速度.
近红外光谱;BPSO;支持向量机;烟叶分级
1 引 言
烟叶的近红外光谱几乎包含烟叶化学成分的所有含氢基团,可以映射烟叶的内部化学成分. 因此,很多学者通过光谱数据构建模型,对烟叶的化学成分和含量进行了研究分析[1-2]. 张建平等[3]利用近红外光谱实现烟叶的产地和部位识别,从烟叶粉碎、筛选、压制等制作过程中提取样本,从样本中获取光谱,光谱数据不能反映烟叶的厚度信息,不能用于烟叶实时无损的智能分级. 章英等[4]依据近红外光谱数据用最近邻判别分析方法实现了烟叶的自动分组. 申金媛等[5-6]依据红外光谱运用概率神经网络、径向基网络等实现烟叶的自动分级.
光谱分辨率越高越能反映烟叶内部的信息,相应的仪器精确度要求也就越高,采集的成本也就越高,获得的烟叶特征也就越多,光谱间的相关性就越大. 原始光谱数据中可能包含与烟叶分级不相关的特征,对近红外光谱特征的提取就变得相当重要. 光谱有效特征的提取方法有小波分解[7]、主成分分析[8]、独立成分分析[9]等,这些方法不能减少光谱数据的采集,而且每次分级时还首先需要对数据做相应的处理,额外增加的时间有可能比数据处理后所减少的分级时间还多,适得其反. 基于聚类分析[10]的方法可以将对分级影响不太好的数据有效地剔除掉,减少了原始数据的采集. 基于同样的考虑,本文提出基于BPSO对原始的光谱数据进行特征光谱筛选,通过BPSO的方法从众多优化过的粒子中选择出最好的1组粒子,即“最佳特征组合”作为最后的有用特征光谱,本文采用具有良好推广能力的SVM分类器对烟叶进行分级.
2 特征选择及分级原理
2.1 BPSO原理
粒子群算法(PSO)是最初由Kennedy博士与Eberhart博士提出的进化算法,其概念来源于鸟类寻找食物行为的研究[11],可以用来解决系统优化的问题. 随机选取1组解为系统初始解,通过进化迭代寻找最优解. 假设在搜索空间为α维中,由β个粒子组成的种群X=(x1,…,xi,…,xβ)T,其中第i个粒子的位置为xi=(xi1,xi2,…,xiα)T,其飞行速度为vi=(vi1,vi2,…,viα)T,该粒子当前得到的最优解为pi=(pi1,pi2,…,piα)T,整个种群当前的最优解pg=(pg1,pg2,…,pgα)T. 其迭代过程为

(1)

(2)
其中:i=1,2,…,β表示种群规模;d=1,2,…,α表示粒子群算法解的搜索空间;t为当前进化代数;r1与r2为均匀分布在[0, 1]之间的随机数;c1与c2为学习因子,通常取c1=c2=2;pid为个体极值,pgd为种群极值;w为正数,称为惯性权重,其值描述为粒子保持上一代速度的权重.
BPSO为二进制粒子群,将每一维的xid,pid,pgd限制为0或者1. 对于速度vid不做该限制,用速度的sigmoid函数表示位置状态改变可能性,BPSO模型中,更新速度为(1)式,位置的更新为

(3)
其中sigmoid型函数为

(4)

2.2 BPSO有用特征光谱选择
烟叶的近红外光谱数据具有“线性不可分、维数高”的特征. 在依据烟叶光谱进行分级时,构建分级模型比较复杂并且会出现分级耗时长且难以实现实时分级. 删减不利于分级的光谱(烟叶特征),降低数据维数,提取有利于分级的特征(有用特征光谱)变得非常必要.
BPSO运用于烟叶的光谱特征选择时,每个粒子对应1种光谱特征的组合. 对光谱进行特征选择时,粒子的每维对应1个波长,粒子的某维取值为1时,表示这个光谱的特征被选中在特征集中;取值为0时,表示这一维特征没有被选中. 根据每维对应的取值,可以确定对应的光谱是否为有用特征.
初始随机选择β个粒子,迭代M次,共产生βM个粒子,从中选择最佳粒子P(对应于适应度值最大的粒子),据此得到最佳特征光谱组合(剔除粒子中为0的光谱). 每个粒子的适应度值由适应度函数决定,适应度函数通常与所采用的分级模型有关,根据粒子的适应度值确定分级分类器的样本输入模式,利用训练样本建立分级模型,不同的粒子建立的分级模型不同,能够正确识别样本的数目也不同,即分类器的正确分级率不同. 本文将样本的正确分级率定义为粒子的适应度函数,与粒子相对应的分类器的正确分级率为该粒子的适应度值. 适应度值越高,粒子包含的特征越有用;把适应度值最高的粒子定义为最佳特征组合,所对应的光谱组合为最佳特征光谱. 本文采用SVM作为烟叶分级分类器,SVM网络输出的分类准确率作为评价该粒子优劣的适应度函数.
2.3 SVM分类器
支持向量机是处理高维数据实现小样本多分类的方法,在建立分类器时,不仅仅考虑经验风险最小,而且考虑结构风险最小,具有优秀的推广能力. 核心思想是将向量映射到较高维空间里,在高维空间上构造最优超平面,使不同类别样本的间隔最大. 本文首先将输入模式通过线性核函数实现向量的高维映射,然后在高维空间建立线性分类器,所采用的线性分类器的判决函数为
g(x)=sgn ∑ni=1αidiK(xi,x)+b,
其中K(xi,x)为核函数,完成输入样本的高维映射;xi是训练样本的支持向量,x为待分类的样本,di取值为1或-1,对应输入样本的正确类型.
SVM是两分类器,如果要进行多分类,则需要多个分类器组合完成. 有2种方法可以实现多分类, 第一种是采用树杈结构如图1(a)所示, 每次将1个级别分离出来,N分类则需要建立N-1个SVM二分类器. 如第一级分类器,将A1类和其他类分为2种类型,输出1为A1类,分类结束,输出-1则为其他类,进行第二个分类器分类,第二个分类器则将A2类和剩余其他类分开,以此类推. 如果输入的样本属于第N-1类或第N类,则需要通过所有N-1个分类器才能得到最后的分类结果.
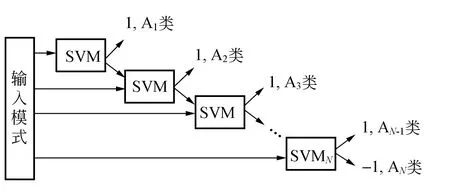
(a)树杈式SVM分类器

(b)全并行投票式分类器图1 2种分类器
第二个构成方法如图1(b)所示,首先每2类建立1个SVM分类器,N类则需要建立N(N-1)/2个SVM分类器,然后将前级SVM分类器的输出给予正确的标签,最后根据标签由投票表决器决定输出类型.
3 实现结果及分析
烟叶样本来源于郑州市烟草公司(共642片),其中XL组163片、XF组173片、CF组84片、CL组103片、BF组119片. 采用岛津公司生产的UV-3600型号分光光度计采集每片烟叶波长范围为1 500 ~2 400 nm,采集不同采样间隔的反射光谱. 为了减小基线漂移带来的误差,对数据进行下面预处理:
yi=xi-min (xi)max (xi)-min (xi) ,
(5)
其中xi为预处理前的反射光谱数据.
X2L和C2L预处理前后烟叶反射光谱如图2所示. 由图2得知,光谱数据在1 400 nm处存在较大吸峰,2 500 nm后波动范围很大. 选取1 500~2 400 nm光谱之间数据作为实验数据.
分别将采样间隔为2,4,6,8,10 nm 烟叶反射光谱的数据作为初始数据,基于BPSO联合SVM分类器进行特征光谱选择. 初始随机选择20个粒子,利用这20个粒子确定相应的样本输入模式,然后通过训练样本建立20个SVM分类器,本文选择投票式结构分类器. 根据测试样本的正确分级率确定每个粒子的适应度值,粒子的每次迭代遵循式(1)和(3), 迭代50次,共产生1 000个粒子,从中选择最佳粒子P(对应于适应度值最大的粒子),据此得到最佳特征光谱的组合(剔除粒子中为0的光谱).
选择642片中的一半左右的样本作为训练样本,其余的作为测试样本. 特征选择前后分级的吻合率、特征数目和分级耗时如表1所示. 表中的吻合率为测试样本的正确分级率.

(b)X2L级别预处理后的反射光谱
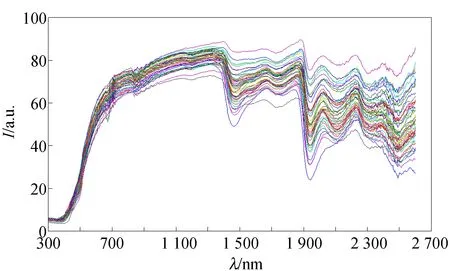
(c)C2L级别的原始反射光谱
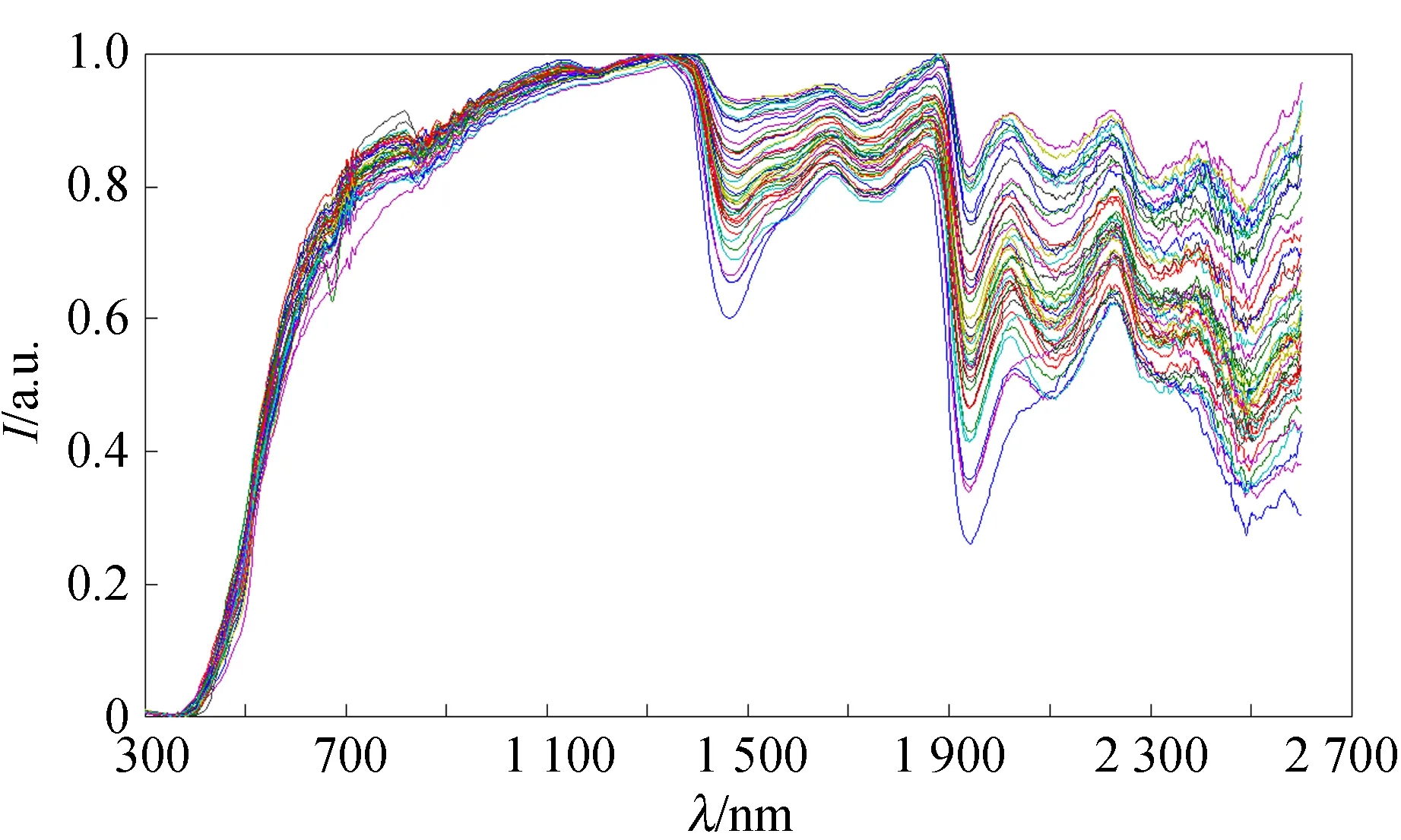
(d)C2L级别预处理后的反射光谱
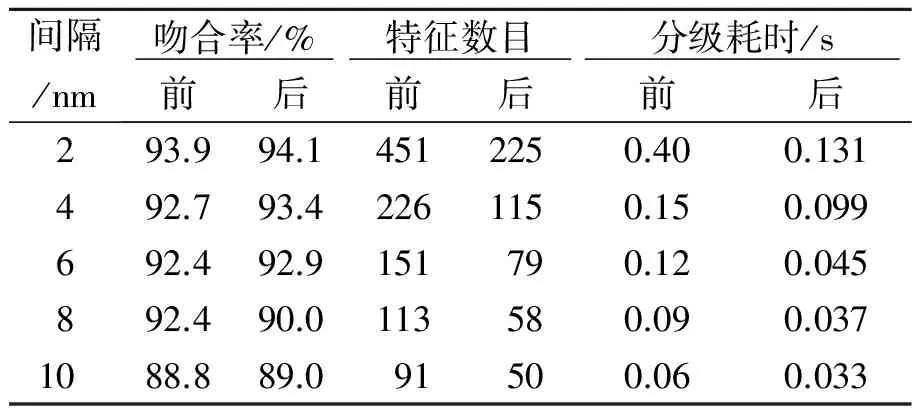
间隔/nm吻合率/% 特征数目 分级耗时/s 前后前后前后293.994.14512250.400.131492.793.42261150.150.099692.492.9151790.120.045892.490.0113580.090.0371088.889.091500.060.033
从表1可以得出:
1)用BPSO方法选择的最优光谱特征的分级准确率比原始全光谱数据情况下有一定的提高(除间隔8 nm时). 所以从正确分级率来看基于BPSO进行光谱数据的有用特征选择是正确可行的.
2)从SVM分级消耗时间来看,随着光谱特征数目的减少,SVM网络所需要分级的时间也减少,少则短1/3,多则短2/3.
3)不论原始数据采用多大间隔,在不影响正确分级率的前提下,利用BPSO都可剔除近一半的数据. 原始数据越多,可剔除的比例越大.
4 结论与展望
通过以上工作可以得出以下结论:
1)烟叶近红外光谱可以作为烟叶自动分级的特征;
2)投票式SVM分类器是一个很不错烟叶分级模型;
3)利用BPSO可以选择对分级有用的光谱,选择后的光谱数据减少近一半,不仅可以减少SVM的分级计算量,使得分级占用时间减少1/3以上,而且可以有效地减少光谱的采集时间. 当采用的设备为串行获取光谱数据时,减少数据采集量可极大地提高烟叶的分级效率,从而使得对烟叶的实时分级有了实用的可能.
还有很多其他的特征选择方法和分级方法,烟叶的图像特征主要包括有宽度、长度、长宽比、周长、面积、破损率、圆形度及RGB和HSI分量. 试想可以融合烟叶的图像特征和光谱特征,两者相结合尽可能的选择出不影响正确分级率的最少特征数目,以及同时考虑正确分级率和分级速度的分级模型,为设计可实用的烟叶自动分级设备奠定基础.
[1] 王东丹,秦西云,赵立红,等. 应用近红外光谱技术分析烟丝总糖和还原糖的研究[J]. 分析实验室,2007,26(5):30-32.
[2] 杜阅光,崔登科,程小东,等. 声光可调近红外光谱技术用于打叶复烤片烟化学成分[J]. 红外技术,2012,34(10):614-618.
[3] 张建平,陈江华,束茹欣,等. 近红外信息用于烟叶风格识别及卷烟配方研究的初步探索[J]. 中国烟草学报,2007,13(5):1-5.
[4] 章英,贺立源. 基于近红外光谱的烤烟烟叶自动分组方法[J]. 农业工程学报,2011,27(4):350-354.
[5] 张乐明,申金媛,刘剑君,等. 概率神经网络在烟叶自动分级中的运用[J]. 农机化研究,2011(12):32-35.
[6] 彭丹青,申金媛,刘剑君,等. 基于径向基网络的烟叶光谱分级[J]. 农机化研究,2009(10):15-18.
[7] 田高友,袁洪福,刘慧颖,等. 小波变换在近红外光谱分析中的应用进展[J]. 光谱学与光谱分析,2003,23(6):1111-1114.
[8] 郭文川,王铭海,岳绒. 基于近红外漫反射光谱的损伤猕猴桃早期识别[J]. 农机机械学报,2013,44(2):142-146.
[9] 侯振雨,王伟,蔡文生,等. 基于独立成分的局部建模方法及其在近红外光谱分析中的应用研究[J]. 计算机与应用化学,2006,23(3):224-226.
[10] 赵海东,申金媛,刘润杰,等. 基于聚类的烟叶近红外光谱有效特征的筛选方法[J]. 红外技术,2013,35(10):659-664.
[11] Kennedy J, Eberhart R. Particle swarm optimization [A]. Proceedings of IEEE International Conference on Neural Networks [C]. Perth, Australia, 1995:1942-1948.
[责任编辑:任德香]
Screening the effective features in the near-infrared spectroscopy of tobacco leaf based on BPSO and SVM
LI Hang1, ZHAO Hai-dong1, SHEN Jin-yuan1,
LIU Run-jie1, LIU Jian-jun2, MU Xiao-min1(1. School of Information Engineering, Zhengzhou University, Zhengzhou 450001, China;2. Zhengzhou City Tobacco Monopoly Bureau, Zhengzhou 450006, China)
To improve the classification efficiency of tobacco leaves based on near-infrared spectroscopy, the BPSO and SVM methods were applied to screening the effective features from the original spectra. The BPSO method was used to get rid of some features that had bad effect or no effect on the classification, and then the levels of the tobacco leaves were recognized by SVM. The experimental results showed that BPSO method could greatly reduce the number of characteristic spectral data and improve the recognition efficiency. For the same spectrum range, after screening, large sampling interval could reduce the numbers of characteristic spectral data. Moreover BPSO could effectively reduce the size of spectrum data collection and the computational complexity of the hierarchical model, thus greatly improve the classification speed.
near-infrared spectrum; BPSO; SVM; tobacco grade
2015-01-07;修改日期:2015-04-11
河南省烟草公司科技计划项目(No.M201335)
李 航(1989-),男,河南开封人,郑州大学信息工程学院2014级硕士研究生,研究方向为近红外光谱分析和图像处理.
指导教师:申金媛(1966-),女,山西晋中人,郑州大学信息工程学院教授,博士,研究方向为数字图像处理、光电信号与信息处理及应用、模式识别.
TN219
A
1005-4642(2015)06-0008-05
