基于约束的序列模式关联规则挖掘算法
2015-03-03刘玉文
张 钰,刘玉文
(蚌埠医学院,安徽 蚌埠 233000)
基于约束的序列模式关联规则挖掘算法
张 钰,刘玉文
(蚌埠医学院,安徽 蚌埠 233000)
约束关联规则是数据挖掘的一个主要方向,可以根据用户给定的约束条件针对性的挖掘.目前大多数的研究都集中在约束频繁项集挖掘方面,很少进行序列模式的约束关联挖掘.本文把序列模式和约束进行结合,提出一种基于约束的序列模式关联规则挖掘算法.它同时处理两类约束:反单调性约束和单调性约束.可以根据约束条件挖掘数据间的因果关联关系.通过实验验证,该算法在运行效率上达到了较好效果.
序列;单调性约束;反单调性约束;约束频繁项集;序列关联规则
1 预备知识
序列模式关联规则[1]主要描述数据之间的前后或因果关系,要求各事件按照发生时间的先后次序进行登记,形成一个事件序列
文献[2]提出了一个序列模式正负关联规则挖掘算法,讨论了序列模式关联规则的挖掘过程.文献[3]提出了一种基于约束的关联规则挖掘算法,该算法给出了一个基于FP-Growth约束处理方法,FP-Growth不产生候选项集,提高了挖掘效率,但在序列模式频繁项集挖掘方面FP-Growth显得无能为力.文献[4]给出了一种松散的反单调性约束,并在Apriori基础上实现了算法,但是由于Apriori的固有缺陷,导致算法效率不高.文献[5]提出了一个带通配符和One-Off条件的序列模式挖掘算法,该算法设计了一种有效的带有通配符的模式挖掘算法,模式在序列中的出现满足One-Off条件,使得模式的任意两次出现都不共享序列中同一位置的字符.
2 基本概念和定义
定义1[2](序列)指按发生时间先后排成一列的对象或事件.
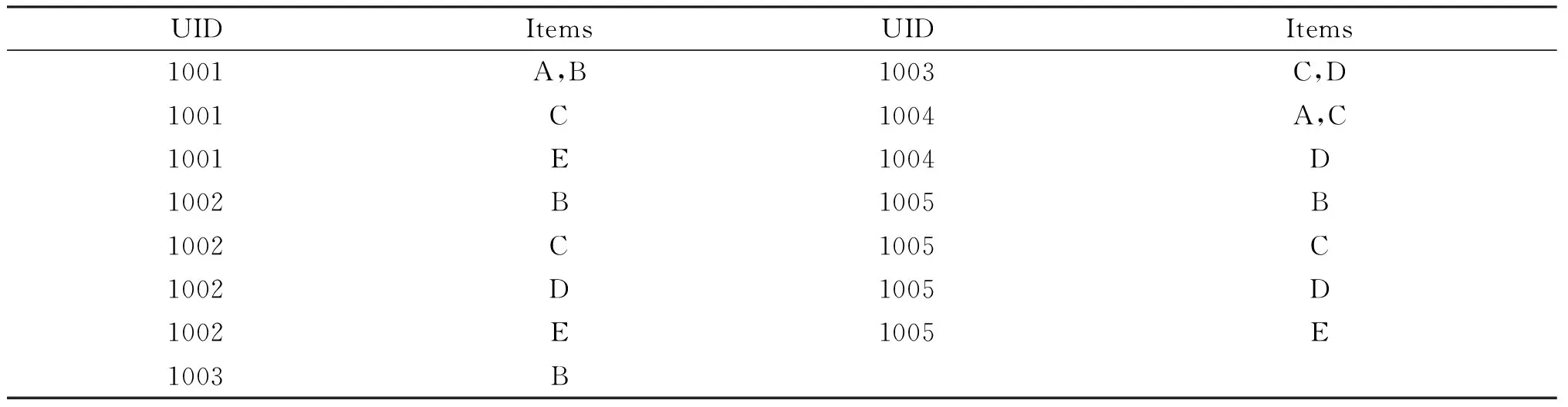
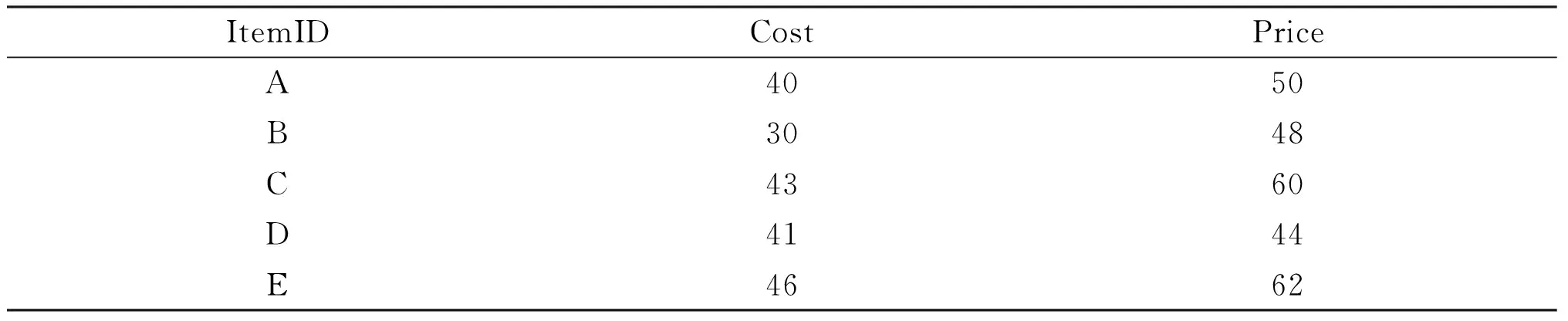
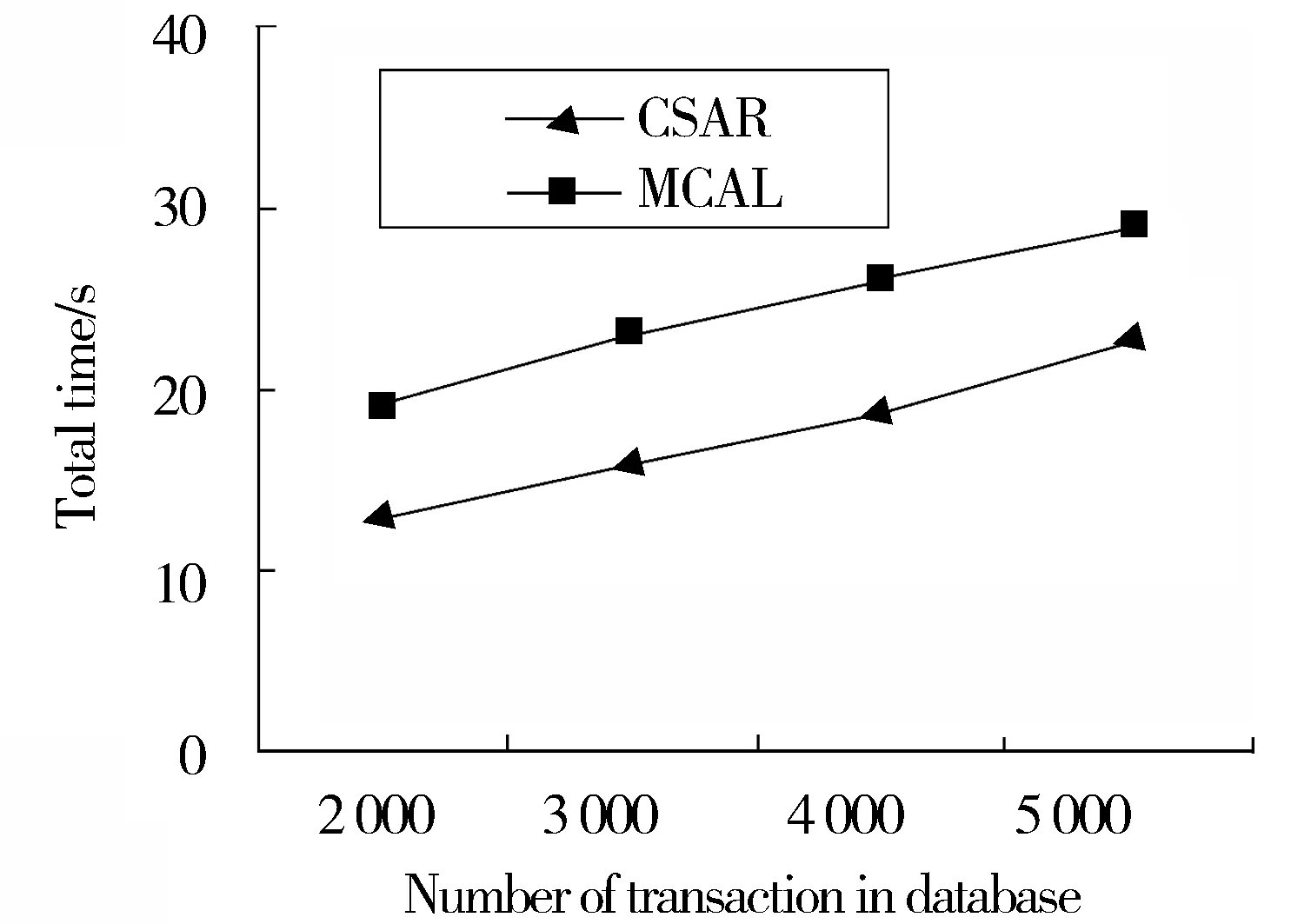
设I是事件的集合,I={i1,i2,…,in},in表示事件称为项.由k个项组成的序列称为k-序列.设序列a Supp(S)≥min-sup,则称S为频繁序列.频繁序列中满足最小置信度的关联规则称为序列模式关联规则. 定义2[3](约束)作用于项I的约束可以看成一个谓词,表示为C:2I→{True,False}.一个序列X满足约束C,当且仅当C(X)=True. 定义3 (约束集)指由n个约束组成的集合,表示为SC={C1,C2,…,Cn}.一个序列X满足约束集SC(即:SC(X)=True),当且仅当C1(X)∧C2(X)∧…∧Cn(X)=True. 定义4 (多维约束)指作用于多维属性上的约束. 多维属性是指一个项有多个属性.比如把一个商品看成是一个项,该商品有若干个属性,如成本、价格等. 定义5[3](反单调性约束)给定一个约束C,如果序列X不满足C,X的任一超集也不满足C,则称C为反单调性约束. 定义6[3](单调性约束)给定一个约束C,如果序列X满足C,X的任一超集也满足C,则称C为单调性约束. 定义7 (约束频繁序列)给定一个约束集SC,对于序列X,如果SC(X)=True,且支持度大于最小支持度阈值,则称X为约束频繁序列. 3.1 算法的基本思想 本算法同时处理两类约束,即反单调性约束和单调性约束.首先把数据库转换成序列模式事务数据库,然后产生序列模式约束频繁项集,最后产生规则.以表1和表2所列的数据为例来说明算法思想. 表1 事务数据库D 表2 事务数据库D中的项及其属性 事务数据库D是以UID为关键字,并按时间先后登记的数据集合,首先要把它转换成序列模式事务数据库.另外,我们考虑两类具体的约束形式:(1)max(S.cost)≤min(S.price);(2)total(S.price)≥100.其中S是序列,cost和price是S中项的两个属性.max(S.cost)指在S中属性cost最大的项.min(S.price)指S中属性price最小的项.显然,第(1)个约束是反单调性约束,第(2)个约束是单调性约束.用C1代表约束max(S.cost)≤min(S.price),用C2代表约束total(S.price)≥100,则约束集SC={C1,C2}.算法的结果是输出符合约束集SC的频繁序列. 引理1 设序列X和Y,Y⊆X,C1为反单调性约束,如果C1(Y)=False,则C1(X)=False. 证明:由于Y⊆X,而C1为反单调性约束,由反单调性约束的定义可以得到结论. 引理2 设序列X和Y,Y⊆X,C1为反单调性约束,如果C1(X)=True,则C1(Y)=True. 引理2的证明和引理1相似. 引理3 设序列X和Y,Y⊆X,C2为单调性约束,如果C2(Y)=True,则C2(X)=True. 证明:由于Y⊆X,而C2为单调性约束,由单调性约束的定义可以得到结论. 引理4 设序列X和Y,Y⊆X,C2为单调性约束,如果C2(X)=False,则C2(Y)=False. 引理4的证明和引理3相似. 定理1 设X,Y是两序列,Y⊆X,C1和C2分别为反单调性约束和单调性约束.(1)如果C1(Y)=False,则C1(X)∧C2(X)=False.(2)如果C1(Y)=True,则可能存在C1(X)∧C2(X)=True. 证明:(1)因为Y⊆X,由引理1可知C1(X)=False,所以C1(X)∧C2(X)=False.(2)因为Y⊆X,如果C1(Y)=True,且C1为反单调性约束,所以可能存在C1(X)=True;又因为C2为单调性约束,也可能存在C2(X)=True,所以可能存在C1(X)∧C2(X)=True. 利用定理1可以有效地减少候选序列的产生. 例如,序列ABC和序列ABD,如果C1(ABC)∧C1(ABD)∧C1(CD)=True,则序列ABCD可能满足C1(ABCD)=True. 产生候选序列是本文算法的主要的步骤之一,很多文献对候选序列的产生提出了改进方法.本文采用文献[6]的方法,首先把频繁(k-1)-序列按照字典顺序排序,对2个频繁(k-1)-序列X和Y(X 3.2 算法描述 基于约束的序列模式关联规则挖掘算法的核心是约束频繁序列的挖掘,其挖掘步骤如下: Step1 产生频繁1-项集. Step2 客户序列转换成序列模式事务数据库. Step3 产生频繁1-序列. Step4 调用算法2产生满足约束C1的候选k-序列. Step5 计算每个候选k-序列的支持度,如果大于最小支持度阈值,则为满足约束C1的频繁k-序列,并入Sk. Step6 把Sk中满足约束C2的k-序列并入SPk中. Step7 跳转到Step4,直到无法产生候选序列为止. Step8 合并SPk得到所有满足约束C1和C2的频繁序列SP. 算法1 输入:数据库D,最小支持度min-sup,反单调性约束C1:max(S.cost)≤min(S.price),单调性约束C2:total(S.price)≥100. 输出:所有同时满足C1和C2的频繁序列. (1)S1=frequent 1-sequences (2)For(k=2;Sk-1≠0;k++)Do begin (3)Ck=Apriori-gen(Sk-1,C1,min-sup)//调用算法2产生候选k-序列 (4)For each custormer-sequence t∈D Do begin (5)Ct=subset(Ck,t) (6)For each candidate c∈Ct (7)c.count++ (8)End For (9)Sk={c∈Ck|c.count≥min-sup} (10)SPk={s∈Sk|C2(s)=True}//得到满足C1和C2的频繁k-序列 (11)End For (12)Answer=UkSPk 算法2 (1)Function Aprori-gen(Sk-1,C1,min-sup) (2)For each lx∈Sk-1Do begin (3)For each ly∈Sk-1∧ly>lxDo begin (4)If lx[1]=ly[1]∧lx[2]=ly[2]∧…∧lx[k-2]=ly[k-2]∧lx[k-1] (5)If C1(lx[k-1]∞ly[k-1])=True Then (6)c=lx∞ly (7)If(C1(c)=True) Then Ck=c∪Ck//lx和ly满足C1,根据推论1仅需判断c是否满足C1. (8)End If (9)else Break//lx与ly后面的序列都不能连接,跳出此次循环. (10)End If (11)End for (12)End for (13)Return Ck; (14)End Function 3.3 例题分析 以表1提供的数据库为例,反单调性约束C1:max(S.cost)≤min(S.price),单调性约束C2:total(S.price)≥100,最小支持度为20%. (1)求出频繁1-项集.L1={A,B,C,D,E}. (2)产生序列模式事务数据库. 以UID为关键字产生用户的序列模式事务数据库SD,表3所示. 表3 序列模式事务数据库SD 方括号[]表示序列的一个项,其包含的子项表示在同一时间内产生的事件.比如[(A),(B),(A,B)]表示用户在一次购买中,同时买了A和B. (3)产生频繁1-序列 扫描序列模式事务数据库SD得到频繁1-序列S1={(A),(B),(C),(D),(E)}. (4)产生约束频繁2-序列 根据S1,求得频繁序列S2={(BC),(BD), (BE),(CD),(CE),(DE)},由于C1(DE)=False,所以删除DE得到S2={(BC),(BD),(BE),(CD),(CE)},其中除BD之外均满足C2,得到满足约束集SC={C1,C2}的约束频繁序列SP2={(BC),(BE),(CD),(CE)}. (5)产生约束频繁3-序列 根据S2和推论1,由于C1(DE)=False,所以BD和BE及CD和CE均不满足链接条件,最后得到候选3-序列C3={(BCD), (BCE)},扫描事务数据库,求得频繁序列S3={(BCD),(BCE)},又因为C1(BCD)∧C2(BCD)=True及C1(BCE)∧C2(BCE)=True,所以得到约束频繁3-序列SP3={(BCD),(BCE)}. (6)产生约束频繁4-序列 根据S3和推论1,由于C1(DE)=False,所以BCD和BCE不满足链接条件. (7)最后,得到满足约束集SC={C1,C2}的所有约束频繁序列SP={(BC),(BE),(CD),(CE),(BCD),(BCE)}. 为了测试算法性能,测试数据选择文献[5]提供的数据,并选择文献[3]中的MCAL算法作为比较对象.在AMDathlon64 8000MHz,2GRAM,WinXP,C#环境下实现了本文算法和MCAL算法.为了表达方便,本文算法用CSAR表示.二者比较如下: 支持度设为20%时,图1显示随着交易数量的增加,两者挖掘时间也随之增加,但CSAR算法要明显优于MCAL算法,因为MCAL算法在频繁项集链接时产生大量候选项集,而且计算频繁项集时多次扫描数据库,浪费了运行时间.而CSAR算法对候选项集进行了有效剪枝,提高了运行效率. 图1 随着交易数量的增加两种算法运行时间对比 图2 随着最小支持度的变化两种算法运行时间对比 图2显示当最小支持度大于32%时,CSAR的运算时间多于MCAL,但当最小支持度小于32%时CSAR的挖掘时间要明显小于MCAL,这是因为随着支持度的减小,频繁项集的数量就会增加,从而会挖掘出大量长项集.因此在长项集挖掘方面CSAR要优于MCAL. 本文给出了约束和序列模式的基本概念,并将两者结合应用在关联规则挖掘过程中,可以根据用约束条件针对性的挖掘数据间之间的因果关联关系.通过实验分析,该算法在运行效率上有较好的性能.但在异构数据,多关系、分布式数据的约束挖掘是今后研究的一个主要方向. [1] Agrawal R, Imielinski T, Swami A. Mining Association Rules between Sets of Items in Large Database[C]//Proceedings of the ACM SIGMOD Conference on Management of Data. Washington, USA: ACM Press, 1993 [2] 郭跃斌,翟延富,董祥军,等.基于序列模式的正负关联规则研究[J].山东大学学报(理学版),2007,42 (9): 88-90 [3] 李广原,杨炳儒,周如旗.一种基于约束的关联规则挖掘算法[J].计算机科学,2012,39(1):244-247 [4] bonchi F,Lucchese C.Trasarti R.Pushing tougher constraints in frequent pattern mining[C]//9th Pacific-Asia Conference on Knowledge Discovery and data Mining.Hanoi,Vietnam,May 2005 [5] 吴信东,谢 飞,黄咏明,等.带通配符和One-Off条件的序列模式挖掘[J].软件学报, 2013,24(8):1804-1815[6] 催贯勋,李 梁,王柯柯,等.关联规则挖掘中Apriori算法的研究与改进[J].计算机应用,2010,30(11):2952-2955 [7] 宋余庆,朱玉全,孙志挥,等.基于FP-tree的最大频繁项目集挖掘及更新算法[J].软件学报,2003,14(9):1586-1592 [8] Anthony J,Lin Wan-chuen.Mining association rules with multi-dimensional constraints[J].The Journal of Systems and Software,2006(79):79-92 Sequential Pattern Algorithm of Association Rules Based on Constraint Zhang Yu, Liu Yuwen (Computer Department,Bengbu Medical College,Bengbu 233000,China) Constrained association rules is a major aspect of data mining, According to the constraint conditions can be mining user given targeted. Most of the studies are concentrated in the constrained frequent itemsets mining, very few mining constrained association sequence pattern. Proposes a sequential pattern mining algorithm of association rules based on constraint, It also deals with two constraint: anti monotonicity constraints and monotonicity constraint. According to constraint conditions for mining causal correlation between data. Through experimental verification, The algorithm has good effect on the running time and scalability. sequence;monotonicity constraint;anti-monotonicity constraints;constrained frequent itemsets;sequential association rules 2014-12-11 基金项目:安徽省高等教育省级振兴计划项目(2013zytz037),安徽省教育厅自然科学研究项目(kj2013z211);安徽省教育厅教学研究项目(2013jyxm120);蚌埠医学院教学研究项目(jyxm1307);国家级大学生创新创业训练计划项目(201210367022). 张 钰(1979-),女,安徽蚌埠人,硕士,蚌埠医学院讲师,主要从事数据挖掘、虚拟现实技术研究. 1672-2027(2015)01-0044-05 TP311 A3 基于约束的序列模式关联规则挖掘算法


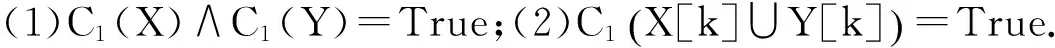

4 实验分析

5 结语
