矩阵与前缀树方法挖掘频繁项集
2015-02-27丁邦旭黄永青
丁邦旭,黄永青
铜陵学院 数学与计算机学院,安徽 铜陵 244000
1 引言
关联规则挖掘是数据挖掘领域中的重要方面,其反映出相关数据项之间的关联或相关联系。频繁项集挖掘是关联规则挖掘中的主要步骤。作为知识发现KDD的一项重要研究课题,频繁项集挖掘最初是由事务库中发现关联规则,由Agrawal等人首先提出[1]。数据挖掘应用于诸多领域,其主要工作是发现频繁项集。近年来,研究学者先后提出了Apriori,FP-growth,ECLAT等数据挖掘算法及其改进算法。(1)Apriori算法采用逐层迭代方式,从候选项集中产生频繁项集,需多次扫描数据库,算法的时间与空间效率都很低,不适用于处理大量数据集[1-3];(2)FP-growth算法只需扫描数据库2次,采用模式增长方式,不产生候选项集,但算法的数据存储FP-Tree树维护复杂,挖掘时需要递归创建FP-Tree,时空效率不高[3-4];(3)ECLAT算法仅需扫描一遍数据库,采用矩阵形式存储TID项集,其计算项集的支持数较快,但算法遇到TID项集很长时,自连接的交运算消耗大量时间,算法占用空间迅速增大,运行效率降低[3,5-6]。因而改进挖掘算法,提高算法的效率对数据挖掘具有重要意义。
本文提出一种基于矩阵(Matrix)与前缀树(Prefixtree)的频繁项集挖掘新算法MPFI。该算法扫描事务数据库一次,构建二进制向量矩阵,得到二进制位数组记录的频繁项集信息,并采用新的数据结构前缀树压缩存储频繁项的相关信息,采用深度优先的策略挖掘频繁模式,不产生候选项集,将有效地提高算法的时间与空间效率。
2 问题定义和描述
2.1 问题定义
定义1设I={I1,I2,…,In}是一给定数据项全集,Ii为第i个项 (1≤i≤n)。项集X是集合I的子集(X⊆I),含有K个数据项的项集X称为K-项集[1]。
定义2 由表达式∀X,Y:(X⊆Y)⇒s(X)≥s(Y)可知:如果一个项集是频繁的,那么它的所有非空子集都是频繁的[1]。
定义3事务数据库D中所有包含项集X的事务个数称为项集X的支持数,记为Sup(X)。设最小支持度为minsup,对于项集X,若Sup(X)≥minsup·|D|(|D|为D的事务数),则称项集X是频繁项集[1]。
定义4事务数据库D={T1,T2,…,Tm},事务Tj(k=1,2,…,m)中含有若干个数据项,Tj由<TID,Items>来表示。经f:T→R转换为布尔型0-1矩阵BR=f(T)=(rij)(i=1,2,…,n;j=1,2,…,m),rij表示数据项Ii在事务Tj中是否出现,1表示Ii∈Tj,否则表示为0[3,7-8]。
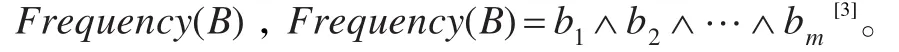
定义6数据划分:对(K-1)-频繁项集进行分割,在各个分割上继续与其他的项集相并运算,得到K-频繁项集。在BR的二进制矩阵中,执行布尔向量的“与”运算。
定义7前缀树为哈希树的一种变种,结构为多叉树。以字符串公共前缀压缩存储空间,并能提高检索效率,其时间复杂度仅为O(n)。按照项集格遍历的等价类划分方式,采用前缀树数据存储结构形式挖掘并存储频繁项集[9-10]。
2.2 数据描述
为了实现算法对事务数据库D的频繁项集挖掘,把D转换为二进制的布尔型矩阵,利用二进制向量运算提高算法效率,可大幅降低挖掘频繁项的时间复杂度。构建事务二进制位矩阵,只需扫描D一次,从该二进制矩阵中得到1-频繁项集,按照相应规则继续挖掘高维频繁项集[11]。在挖掘过程中只需存储二进制位串数据,空间开销相对很小。
数据项Ii由包含它的事务表示,如果该项包含于某个事务中,则对应的二进制位为1,否则为0,即每个数据项以二进制向量表示,最终构成一个二进制事务矩阵,如表1所示[12-14]。
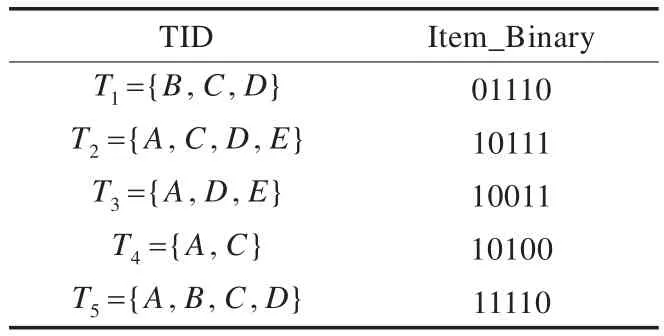
表1 二进制事务矩阵
假设给定一事务数据库D,项集为{A,B,C,D,E}。表1为D按事务水平方向构建二进制位向量矩阵,但不便于频繁项挖掘;对事务二进制矩阵改进,表示为表2的形式:按事务垂直方向构建布尔向量矩阵。运算规则:项Ii和Ij(i≠j),取出Ii和Ij对应的布尔向量,将该两数据项的布尔向量进行“与”运算,得到二进制位向量,若位的值为1,则事务中存在项集{Ii,Ij},否则该事务中不存在项集{Ii,Ij}[15-17]。

表2 二进制项集矩阵
对表2的矩阵按行向量执行布尔向量的“与”运算,得到相应项集的二进制位数组,其频度计数即为该项集的支持数[18]。
3 算法描述
3.1 算法基本思想
MPFI算法根据定义3、定义 4、定义 5、定义 6、定义7,进行了以下改进:
(1)基于定义4,按事务垂直方向构建布尔型向量矩阵,得到以二进制位数组表示的1-频繁项集,如表3所示。
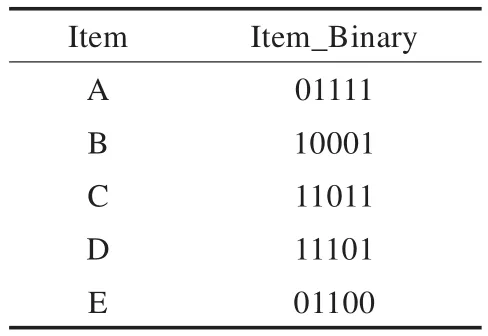
表3 1-频繁项集
(2)基于定义6、定义7,按照项集格遍历的等价类划分方式,利用前缀树实现存储频繁项集,并以深度优先的搜索方式进行遍历,得到所有频繁项集,如图1所示。
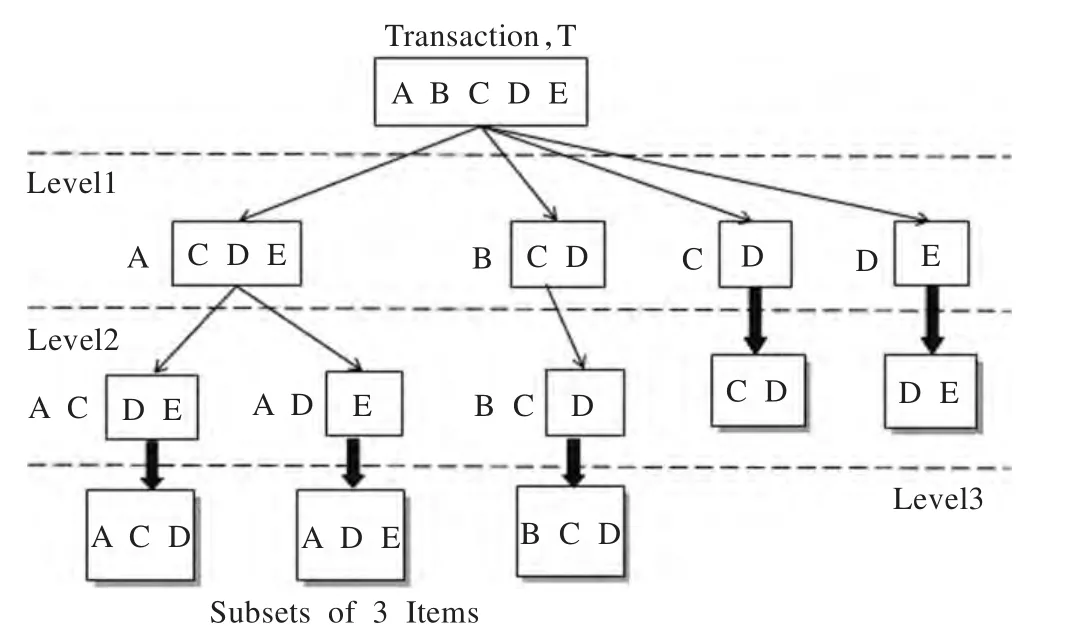
图1 数据划分
算法结合前缀树Prefix-tree结构,以1-频繁项的二进制位向量与(K-1)-频繁项集的二进制位向量按位“与”运算,产生K-项集的方法挖掘事务矩阵中的频繁项集,如图2所示。并且在产生K-项集的过程中对1-频繁项集中不在(K-1)-频繁项集中出现的项集进行剪枝,提高了算法效率,降低了算法的空间复杂度。
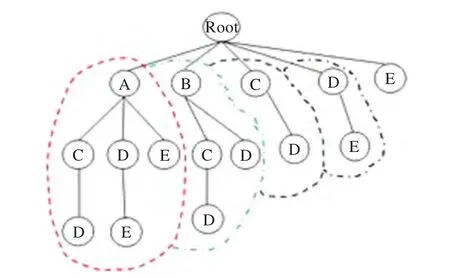
图2 前缀树Prefix-tree
算法的具体执行过程为:
(1)扫描事务库D,构建二进制矩阵。
(2)根据用户设定的最小支持度,产生频繁1-项集L1,即:计算数据项的二进制位向量的频度计数,若Frequency(Ii)不小于最小支持数,则该项为频繁项。
(3)释放二进制矩阵存储空间,并以1-频繁项集构建Prefix-tree。
(4)按照对应规则,计算项集的频度计数,循环创建Prefix-tree的下一层结点,从而产生频繁项集L2,L3,…,Lk。
(5)深度遍历Prefix-tree,L1∪L2∪…∪Lk,输出结果,算法结束。
设最小支持度为minsup=40%,按照本算法的基本思想,对上述事务数据库D进行运算,得到1-频繁项集;取项“A”的二进制位序列01111,“B”的二进制位序列10001相“与”运算,得项集{A,B}二进制位序列00001,Frequency({A,B})=1<2,即该项集不频繁。
3.2 数据存储
算法程序采用面向对象的程序设计思想,将频繁项集定义为类的形式,采用Java语言编写程序,其类的定义如下:


本算法采用二进制位序列保存频繁项挖掘的信息,记录该频繁项集在哪些事务中出现,其二进制位的存储空间为:1/(4×8)字节,对系统存储空间的开销很小;采用如图2所示改进结构的前缀树Prefix-tree挖掘并记录所有的频繁项集,记录K-频繁项集的信息只需要一个数据项的结点存储空间,其前k-1个项集无需存储,按照深度遍历的方式即可得到K-频繁项集,大大降低了算法的空间存储代价。
3.3 MPFI算法
MPFI算法采用二进制位向量表示数据项,利用前缀树存储频繁项挖掘数据,利用项集对应的二进制位向量“与”运算产生频繁模式。
算法:MPFI


4 实验结果与分析
MPFI算法采用java语言实现,实验环境为Windows7操作系统,双核2.2 GHz处理器,内存大小为4 GB,实验所需的数据采用两个标准数据集:T10I4D100K.dat与mushroom.dat数据集(下载自http://fimi.ua.ac.be/data/)。公式δ=t/(m×n)为事务矩阵的稀疏因子,数据集T10I4D100K.dat的稀疏因子为0.01,比较稀疏;数据集mushroom.dat的稀疏因子为0.191,相对稠密。
为了验证该算法的理论分析及其实际性能,基于上述实验环境,相比较的ECLAT算法、FP-growth算法和MPFI算法均采用Java语言实现。在不同的最小支持度下,对上述两个数据集进行挖掘,得到ECLAT算法、FP-growth算法和MPFI算法的运行时间,以图表的形式对这几种算法的运行效率进行比较。
图3为挖掘数据集T10I4D100K.dat时随支持度变化的运行时间比较。T10I4D100K.dat为IBM购物篮分析的人工事务数据库,其事务平均长度为10,事务模式较短。从实验数据对比可知,在对稀疏数据挖掘时,FP-growth算法优于ECLAT算法(垂直记录方式实现),MPFI算法的时间性能更好。
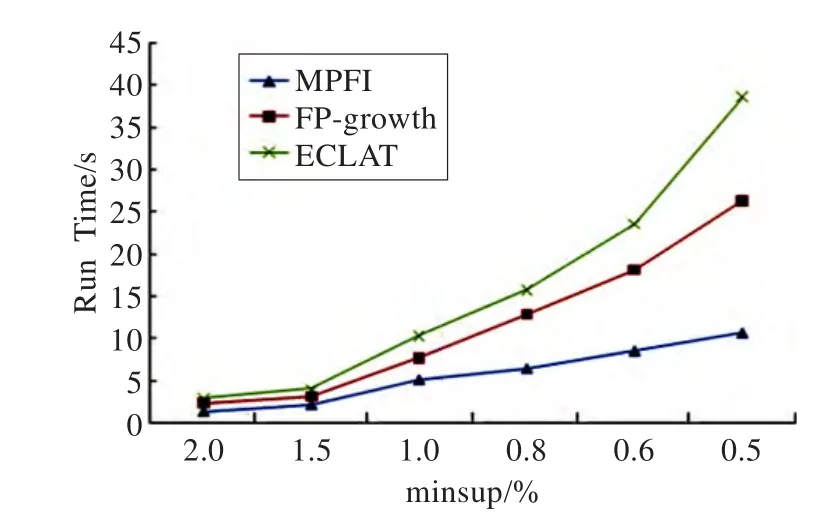
图3 挖掘T10I4D100K.dat运行时间比较
图4是挖掘数据集mushroom.dat时随支持度变化的运行时间比较。该数据集包含描述的假设样本对应于23种双孢蘑菇的物理特征,对蘑菇进行分类:有毒或食用;其事务平均长度为23,数据集相对较稠密。从实验数据对比可知,对交稠密的数据集挖掘时FP-growth算法需要花费较多时间建FP-tree树,ECLAT算法略优于FP-growth算法,MPFI算法的执行效率最好。
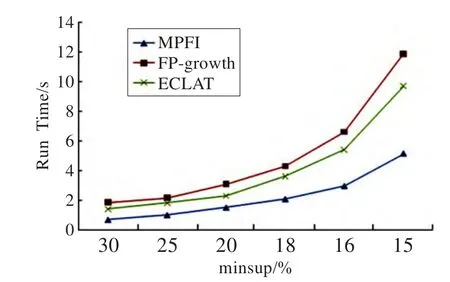
图4 挖掘mushroom.dat运行时间比较
5 结束语
本文提出了一种基于矩阵与前缀树的频繁项集挖掘MPFI算法,能快速地挖掘事务数据库中的频繁项集。本算法将事务序列采用垂直方向的二进制位向量矩阵表示,以二进制位数组与前缀树Prefix-tree形式保存挖掘数据,降低了算法的空间开销;MPFI算法先得到1-频繁项集,再以1-频繁项集构建前缀树,同时挖掘出频繁项集,有效地提高了算法执行的效率。实验证明,MPFI算法具有较好的频繁项集挖掘执行效率。
本算法的数据挖掘功能有限,后续改进的研究方向为:(1)结合闭合项集格改进算法,挖掘频繁闭项集(Frequent Closed Itemsets);(2)挖掘流式数据频繁模式。
[1]Agrawal R.Database mining:a performance perspective[J].IEEE Trans on Knowledge and Data Engineering,1993,5(6).
[2]Agrawal R,Imielinski T,Swami A.Mining association rules between sets of items in large databases[C]//Proceedings of the ACM SIGMOD International Conference Management of Date,Washington,1993:207-216.
[3]闫珍,皮德常,吴文昊.高维稀疏数据频繁项集挖掘算法的研究[J].计算机科学,2011,38(6):183-186.
[4]宋余庆,朱玉全,孙志挥,等.基于FP-Tree的最大频繁项目集挖掘及更新算法[J].软件学报,2003,14(9):1586-1592.
[5]张毅,杨颖,陆瑞兴.一种新的频繁项集挖掘算法DS_ECLAT[J].广西科学院学报,2010,26(1):19-22.
[6]Han J,Pei J,Yin Y.Mining Frequent Patterns Without Candiate Generation[C]//Proc of SIGMOD,Dallas,2000,29(2):1-12.
[7]张忠平,李岩,杨静.基于矩阵的频繁项集挖掘算法[J].计算机工程,2009,35(1):84-86.
[8]王柏盛,刘寒冰,靳书和.基于矩阵的关联规则挖掘算法[J].微计算机信息,2007,24(5):143-145.
[9]Liu Guimei,Lu Hongjun,XuYabo,et al.Ascending frequency ordered prefix tree:Efficient mining of frequent patterns[C]//Prco of 8th Database Systems for Advanced Applications(DASFAA’03),2003.
[10]朱光喜,吴伟民,阮幼林,等.一种基于前缀树的频繁模式挖掘算法[J].计算机科学,2005,32(4):34-36.
[11]徐嘉莉,陈佳,胡庆,等.基于向量的数据流滑动窗口中最大频繁项集挖掘[J].计算机应用研究,2012,29(3):837-840.
[12]Zaki M J.Fast vertical mining using diffsets,Technical Report 01-1[R].Rensselaer Polytechnic Institute,Troy,New York,2001.
[13]熊忠阳,耿晓斐,张玉芳.一种新的频繁项集挖掘算法[J].计算机科学,2009,36(4a):42-44.
[14]王磊,黄志球,朱小栋,等.数据流中基于矩阵的频繁项集挖掘[J].计算机科学与探索,2008,2(3):330-336.
[15]徐建民,郝丽维,王煜.数据流频繁项集的快速挖掘方法[J].计算机工程与应用,2009,44(34):142-144.
[16]严海兵,卞福荃.一种基于布尔向量的Apriori改进算法[J].苏州科技学院学报:自然科学版,2008,25(1):67-70.
[17]李志林,戴娟,刘以安.基于布尔向量运算的Apriori算法[J].江南大学学报:自然科学版,2010,9(3):270-273.
[18]张月琴.滑动窗口中数据流频繁项集挖掘方法[J].计算机工程与应用,2010,46(16):132-134.
