一种小波包变换的声纹参数提取方法研究
2015-02-27梅铁民朱向荣
孟 慧,梅铁民,朱向荣
(1.沈阳理工大学 信息科学与工程学院,辽宁 沈阳 110159;2.淄博民通热力有限公司,山东 淄博 255400)
一种小波包变换的声纹参数提取方法研究
孟 慧1,梅铁民1,朱向荣2
(1.沈阳理工大学 信息科学与工程学院,辽宁 沈阳 110159;2.淄博民通热力有限公司,山东 淄博 255400)
在声纹识别系统中,对声纹参数的提取很重要。传统的MFCC参数忽略了语音信号的动态特性,因此提出了一种基于小波包变换的声纹参数提取方法。为了更突出说话人的声纹特征,克服说话内容不同对提取声纹参数的影响,在分帧阶段采用帧长为2560点,增长有效语音段。再结合基于矢量量化(VQ)系统进行说话人识别实验,并通过比较常用的db3、db4、db6、coif3小波函数选取最优基。实验证明,相对于常用的256点帧长,帧长为2560点的识别率较高且提高了运算速率。coif3小波函数为声纹参数提取的最优基。新的WPT参数的识别率优于传统的MFCC参数。
声纹参数;小波包变换;能量;矢量量化;语音信号
随着计算机技术和网络通信的迅猛发展,人们的生活方式也发生了巨大变化。身份鉴别作为信息安全的重要组成部分已成为全球最热门的研究领域之一,在日常生活的每个领域都起着至关重要的作用[1]。传统的密码识别在实际应用中具有很多缺陷,而且随着手机等移动设备的普及,密码丢失导致隐私泄露和被犯罪分子盗取的数量越来越多。在这种情况下,进行声纹识别有重要的意义。因此,研究可靠的声纹识别系统,提高声纹识别的准确率,具有良好的应用前景[2]。声纹识别是一项难度较高的技术,它包括代表说话人特征的声纹的提取和识别两个方面。从声音中提取一组反映说话人特征的声学参数构成一个人的声纹,这是一个复杂的过程,但它也是声纹识别的关键所在。根据语音信号的声学特殊性,已经提出一些有效的声学特征提取方法,如能够充分反映人耳听觉系统的非线性特性的MFCC(Mel-Frequency Cepstral Coefficients)参数[3]。它是将语音信号的频谱通过非线性变换转换为Mel频率,然后再转换到倒谱域上,从而获得MFCC参数。虽然在识别性能和抗噪能力上MFCC参数都具有很好的性能,也是目前应用比较广泛的声纹特征参数,但是MFCC参数并不能很好地反映人耳的听觉特性,此外,该算法需对语音信号进行多步复杂计算,计算量较大,不利于快速语音识别[4]。本文提出了一种基于小波包变换的声纹特征参数(WPT参数)。它既能较好地反映语音信号的动态特性,又能反映人耳的听觉特性。仿真研究表明,相对于MFCC参数,具有较好的抗噪声能力,而且在减少了运算量的同时提高了识别率。
1 小波包变换
小波包变换将信号频带进行多层次划分,即对小波变换没有细分的高频部分进一步分解,并能够根据被分析信号的特征,自适应地选择相应的频带,使之与信号频谱相匹配,从而提高了时频分辨率[5-6]。

(1)
式中,gk=(-1)kh1-k,即两系数也具有正交关系。当n=0时,式(1)直接给出:
(2)
与在多分辨分析中,φ(t)和ψ(t)满足双尺度方程:
(3)

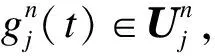
(4)
(5)
(6)
2 基于小波包变换的声纹参数提取方法(WPT法)
为便于比较,首先简单介绍一下MFCC参数提取方法,然后给出基于小波包变换的WPT(Wavelet Packet Transform)声纹参数提取方法。
2.1 MFCC参数提取方法
人类的听觉系统是一个比较特殊的非线性系统,对于不同频率信号响应的灵敏度是不同的。Mel倒谱参数(MFCC)就是一个能够较好反映人耳感知特性的参数。这里的Mel倒谱参数是人耳所感知到的音调的度量单位[7]。Mel频率是对人耳所听到的汉语音调的度量。
Mel频率与线性频率的转换关系如下所示:
fMel=2595lg[1+f/700]
(7)
Mel倒谱参数特征是按照帧计算出来的,提取的过程可以用以下过程来表示:
1)首先确定每一帧语音采样序列的点数,一般取N=256点。对每一帧序列s(n)进行预加重、分帧加窗预处理后,x(n)再经过离散FFT变换,取其模的平方得到离散功率谱X(k)为
(8)
2)将上述频谱通过一组三角带通滤波器组成的Mel滤波器,计算X(k)通过M个Mel滤波器后得到的M个能量Pm(m=0,1,…,M-1)。
3)计算Pm的自然对数能量,得到Lm(m=0,1,…,M-1)。
(9)
4)将,L0,L1,…,LM-1通过离散余弦变换求得Dm,m=0,1,…,M-1。去掉表示直流分量的D0,取D1,D2,…,DL即为MFCC参数
(10)
式中,L为MFCC参数的维数,M为Mel滤波器的个数。
由于在实际声纹识别应用中并不需要取全部维数的MFCC参数,因为最前面几维以及最后面几维的参数对语音的区分性能不大,通常取前16维的MFCC参数即可。
2.2 WPT参数提取方法
2.2.1 语音信号的分帧加窗
语音信号为一种典型的非平稳信号,为了便于分析,语音信号被视为短时间内是平稳的。根据人类的发声机理,语音信号的频谱特性以及某些物理特征参数在10ms至30ms时间内是近似稳定不变的。所以就可以把一段语音信号分成若干稳定小段,每个短时段被称为一帧,相邻两帧之间会有重叠部分,重叠部分被称为帧移,帧移与帧长通常保持0至0.5的比值[8]。通过滑动一个窗函数对语音信号进行加权处理。对语音s(n)加窗,窗函数w(n)乘以s(n)形成加窗语音sw(n),sw(n)=s(n)·w(n)。在声纹识别系统中,汉明窗因其具有较低的旁瓣高度和低通特性被广泛用应用以避免短时语音段的影响,所以本文在分帧加窗步骤采用汉明窗,如下式所示:
(11)
式中N为窗口长度。为更突出说话人的声纹特征,克服说话内容不同对提取声纹参数的影响,在分帧阶段采用帧长为2560点,即N=2560,增长有效语音段。
2.2.2 WPT参数的提取过程
基于小波包变换对声纹特征参数(WPT)的提取过程如下。
1)首先对语音信号在给定尺度上进行小波包分解。如前所述,选取合适的分解尺度和小波包基函数。设一帧语音信号为x(n),帧长为2560。对x(n)进行三层小波包分解,用(i,j)表示第i层的第j+1个结点(i=0,1,2,3;j=0,1,…,15)。比如:代表原始语音信号x(n)的为(0,0)结点,(3,2)结点代表第三层第3个结点的小波包系数。

3)取对数。
S(j)=log(EWPCj)
(12)
4)对S(j)进行离散余变换(DCT),求得WPT参数:
C(j)=DCT(S(j))
(13)
传统的基于小波包的声纹参数提取的分帧通常帧长取为256点,帧移取100点,即是把语音信号假设在短时间内看作是平稳的。这种短帧长的声纹提取比较适合文本识别。对于说话人识别,希望尽量消除文本对所提取声纹的影响。解决这一问题的办法是增加语音帧的长度,从而只突出说话人的特征。在语音活动段,本文将帧长取为2560。这样提取的声纹参数可以更好地克服由于说话内容不同而对声纹参数提取造成的影响。
2.3 选取最优基
在小波包变换中,可以选取不同的小波函数。不同的小波函数会对分析结构产生不同结果,因此涉及到最优小波函数的选取问题。但是,在语音识别中,哪一种小波函数最优并无定论。通常考虑小波函数变换的有效性、通用性和系数的唯一性。为了找到更适合说话人识别声纹参数提取的小波,本文将对常用的db3、db4、db6和coif3小波函数进行实验验证,以便比较这些小波函数在说话人识别中的优劣。
3 基于矢量量化的说话人识别
矢量量化模型在声纹识别系统中的识别过程:
1)从测试语音信号中得到特征矢量;
2)用每个模板依次分别对特征矢量序列进行矢量量化,计算各自的平均量化误差,采用如下公式:
(14)

3)把平均量化误差最小的码本所对应的说话人作为系统的识别结果[9]。
4 实验结果
声纹特征参数提取之前,首先要对语音信号预加重,所用预加重滤波器为H(z)=1-αz-1,其中α取值为0.97。其次采用双门限端点检测算法进行端点检测,目的是找出语音段和无音段并去除无音段。找到语音段之后要对语音信号进行预处理,即进行分帧、加窗处理,本实验采用帧长为2560点的Hamming窗。最后再对每个人的声音文件进行特征参数提取并进行矢量量化。
由上文介绍的WPT参数提取方法可知,提取的WPT参数是经过三层小波包对语音信号分解的,那么得到的是16维度的声纹参数,而在实际的三维空间内,不能够表示出16维的仿真结果图,所以本实验取到第5维度和第6维度的声纹参数进行仿真实验,来表示二维的不同说话人的声纹数据点分布图,如图1所示。其中横轴代表第五维度,纵轴代表第6维度。

图1 不同说话人的声学矢量图
对提取出的声纹参数要进行矢量量化,对于有16个人的声纹识别系统,欧几里德特征空间被这16人的特征码本分成16个有重叠但是有良好的辨别度或者完全不重叠的空间区域,而每一个区域有一个码本,这些码本分别包含这16个人的不同声纹参数。语音信号数据落入的区域会相应生成码字,即语音信号的VQ码本由表示人类声道特征的若干个码字矢量组成。那么将图1所示的语音数据点训练生成相应的VQ码字如图2所示。同样横轴代表第5维度,纵轴代表第6维度。

图2 不同说话人训练后的VQ码字
本文采用自己录制的语音数据,每人被要求在相同的环境下录制10次语音数据,每次朗读不同的汉语句子,前9次用于训练,最后一次用于识别。实验中,共采集16个不同人的声音文件,男女各半,本实验是与文本无关的说话人辨别,所以每人在环境相同的情况下随意录音3s。将所获得的声音文件按顺序编号放到一个文件夹中,并依次对其训练,建立一个简单的语音库。
实验中由统计和应用两部分组成。应用部分建立一个完整的声纹识别系统,可以实现提取上述MFCC参数和WPT参数,进行实时训练和识别。统计部分利用完整的声纹识别系统中已有的训练好的声音文件的特征参数的码本,对所有测试语音文件相对应的某种参数的帧矢量集数据文件做统计,计算出识别率。即随机抽取8个待测语音文件分别进行识别测试,每个声音文件进行8次测试,按照式(15)算出识别率,再由式(16)求平均,求得识别率,得到的各情况的识别结果如表1所示。
(15)
(16)
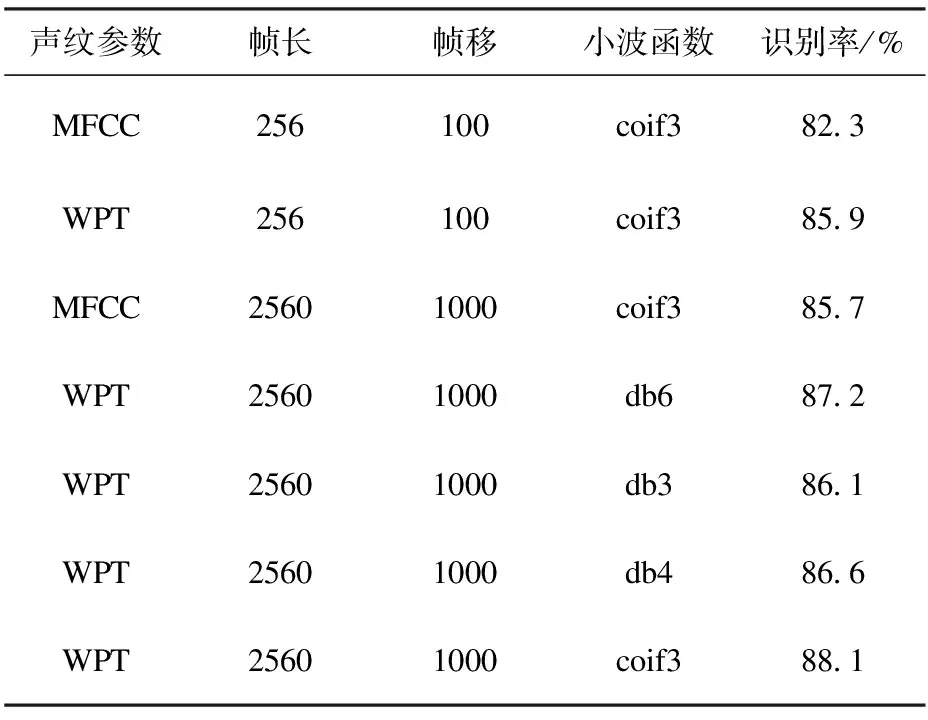
表1 不同声纹参数的识别率
表1给出了两种不同帧长情况下,基于WPT参数的说话人识别结果。说明增加帧长可以提高识别率。这与前述的判断一致,即增加帧长可以有效地消除说话内容对说话人声纹的影响。同时表明,不同小波函数对声纹参数识别率是有影响的。在选用的四个不同小波系中,db3小波的识别率相对最差,coif3小波的识别率最好。因此,在基于小波包变化的说话人识别中,小波系的选择也是关键的一环。恰当地选择小波系有助于提高识别率。
一帧语音信号的WPT参数与MFCC参数的对比图如图3所示。可见16个参数中,只有前面约七、八个值比较明显外,后面的值都非常小,趋于零,不利于刻画说话人的特征。相反,16个WPT参数变化比较大,更有利于描述不同说话人的特征。可见WPT参数特征相比于MFCC参数特征较好地表征了语音特征参量随时间的变化动态特性,从而有利于提高识别率。

图3 一帧语音信号的WPT参数与MFCC参数仿真对比图
为更进一步验证WPT参数的性能,再分别进行16维MFCC和参数WPT参数前10帧仿真实验,如图4所示。其中横轴代表不同维参数,纵轴代表不同维参数所对应的值。由图4可知,前10帧的MFCC参数第5、6、13维处等比较相似。众所周知,特征参数越相似,声纹识别系统在训练与识别时,不同类别的特征参数的分类效率越高,有助于提高系统的识别率。相反,第2、3、7、9维参数的特征曲线有明显的差异,那么这样的MFCC参数不利于改善训练与识别的效果。
明显地发现,通过与MFCC参数仿真图对比,各帧之间WPT参数的形状更相似,即表示的特征更接近。因此WPT参数,再结合表1所给出的统计结果验证了上述结论,WPT参数用于说话人识别时要优于MFCC参数。
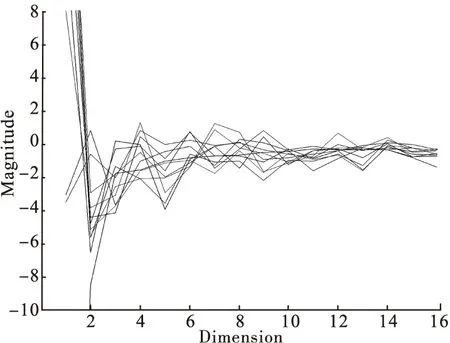
(a)MFCC参数

(b)WPT参数
5 结论
通过对传统的声纹特征参数MFCC的提取过程的分析研究再结合人类语音的动态特性,将小波包变换引入到声纹参数提取中,即提取语音信号的新的特征参数WPT参数。对于文本无关的声纹识别系统,为了更突出说话人的声纹特征,克服说话内容不同对提取声纹参数的影响,在分帧阶段采用加长帧。且对常用的几种小波函数的识别率进行比较以选择最优基。在验证识别率性能时将所提取到的参数分别应用到基于VQ矢量量化的声纹识别系统中进行实验。实验结果表明,相对于常用的256点帧长,帧长为2560点的识别率较高且提高了运算速率。coif3小波函数为声纹参数提取的最优基。相对于传统的MFCC参数,新声纹参数WPT的识别率优于传统的MFCC参数。
[1]Glembek O,Burget L,Dehak N,et al.Comparison of scoring methods used in speakerrecongn-ition with joint factor analysis[C].In Proc.ICASSP,2009.
[2]D.Avic. An expert system for speaker identification using adaptive wavelet sure entropy[J].Expert System with Applications,2009,36(10):6295-6300.
[3]张万里,刘桥.Mel频率倒谱系数提取及其在声纹识别中的作用[J].贵州大学学报,2005,22(2):207-210.
[4]Kajarekar. Phone-based cepstral polynomial SVM system for speakerrecognitiom[C].Procee-dings of Interspeech,2008.
[5]梁学章,何甲兴,王新民,等.小波分析[M].北京:国防工业出版社,2004.
[6]刘雅琴,裘雪红.应用小波包变换提取说话,人识别的特征参数[J].计算机工程与应用,2006,28(9):67-69.
[7]Azzam Sleit,Sami Serhan,Loai Nemir.A histogram based speaker identification technique[C].International Conference on ICADIWT,2008:384-388.
[8]Dehak R,Dehak N,Kenny P,et al.Kernel Combination for SVM Speaker Verification[C].In Odyssey Speaker and Language Recognition Workshop, 2008.
[9]边肇祺,张学工.模式识别[M].北京:清华大学出版社,2000:305-314.
(责任编辑:马金发)
Voiceprint Parameters Extraction Based on Wavelet Packet Transform
MENG Hui1,MEI Tiemin1,ZHU Xiangrong2
(1.Shenyang Ligong University,Shenyang 110159,China;2.Zibo Mintong Heating Co.,Ltd,Zibo 255400,China)
In speaker recognition system,the voice parameters extraction is very important.The traditional MFCC parameter ignores the dynamic characteristics of speech signal,so a method is presented for extracting voice parameters based on wavelet packet transform.Text independent voice recognition system is to voice a more prominent feature of the speaker and overcomes the different speech content effects on the voiceprint parameters extraction.The frame length is adopted to increase effective voice for 2560 points in framing stage.And vector quantization (VQ) is combined with the speaker recognition experiment system,through the comparison of db3、db4、db6、coif3 wavelet function to choose the best basis.Experimental results show that frame length within 2560 points is higher and improves computing speed in comparison with common 256 point of the frame length.The optimal base coif3 wavelet function is taken as voiceprint parameter extraction.The MFCC parameter identification of the WPT parameters of the new rate is better than tradition one.
voiceprint parameter;wavelet transform;energy;vector quantization;speech signal
2014-11-05
孟慧(1989—),女,硕士研究生;通讯作者:梅铁民(1964—),男,教授,研究方向:自适应信号处理.
1003-1251(2015)06-0077-06
TN911
A
