半监督分类中的噪声控制及相关算法
2015-02-21詹永照
姜 震,詹永照
(江苏大学计算机科学与通信工程学院,江苏镇江 212013)
半监督学习能同时利用有标签样本和无标签样本进行学习,有效缓解标签瓶颈问题,近年来一直是机器学习领域的研究热点.大多数半监督分类算法,如基于生成式模型的方法、基于低密度划分的方法和基于图的半监督学习方法[1-2]等,通过将无标签样本的分布信息结合到原有的模型假设中来实现对无标签样本的利用.但是如果模型关于数据分布的假设和实际不一致,可能反而会降低学习性能[1-2].
作为半监督学习的另一分支,self-training类算法[3-4]、co-training 类算法[5-7]、tri-training[8]以及半监督集成学习[9-11]等算法,直接利用当前分类器的预测结果(伪标签样本)进行迭代训练,不需要额外的先验知识进行模型假设,高效易行.但是由于伪标签样本可能预测错误,即存在分类噪声;另一方面,伪标签样本不是独立随机抽取的,因此还会存在分布噪声.如何控制伪标签样本中的噪声,是这类算法成功的关键.
现有的大多数算法[3-11]通过选择信任度高的预测结果作为伪标签样本来减少分类噪声,但忽略了伪标签样本不是独立随机抽取而带来的分布噪声;也有少部分算法[2,10]选择将所有预测结果都加入训练集来降低分布噪声,但是这种做法是以降低伪标签样本的准确率为代价的.笔者在前期关于多分类器协同训练的工作中[12],考虑兼顾降低分类噪声和分布噪声.但是仅通过伪标签样本的类别比例来估算和控制分布噪声的方法较为简单.
文中拟提出一种利用混合高斯模型来表示样本分布,进而估算分布噪声的方法;并基于分类噪声和分布噪声下的算法可学习性和泛化误差分析[12],提出一种可回溯的利用伪标签样本的迭代训练策略,而且将其进一步与集成学习相结合,提出一种ensemble self-learning(ESL)算法;最后在文献[13]所用到的6个文本数据集上进行试验验证.
1 ensemble self-learning算法
1.1 泛化误差与伪标签样本的噪声分析
如何选择高质量的伪标签样本是本类算法的关键.文献[12]给出了利用伪标签样本训练时噪声影响的相关理论分析.
定理1 对于弱分类器h1,如果向h1提供的伪标签样本满足分类噪声β<l/2,分布噪声 η≤ε+1/q(l+p,1/ε,1/(1-2β),1/δ),那么h1是可学习的,且有下式成立:
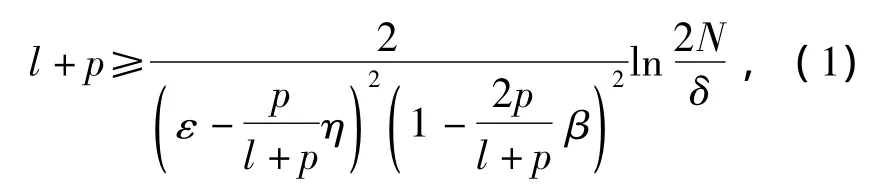
式中:l和p分别为有标签样本和伪标签样本的数量;N为假设空间的规模.取μ为令式(1)取等值的量,则式(1)可改写为
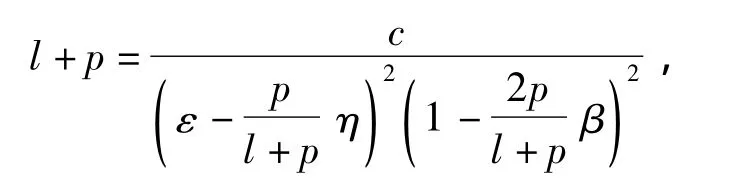
进而有

根据上述定理,如果能估算出训练集中的分类噪声和分布噪声,就可以根据样本数量推断出在一定信任度下的泛化误差.这提供了评估迭代训练中分类器性能的准则,从而可以有效防止“差”的伪标签样本加入带来的性能下降.
分类噪声的估算:文中定义了一个伪验证集V,由L和伪标签样本中信任度最高的30%组成,令AV(hi)表示hi在V上的准确率,则1-AV(hi)用于估算分类噪声hi.
分布噪声的估算:假设有个K类别,文中采用K个高斯混合分布P(A)来模拟样本空间的分布,其参数μ,σ2可以由初始的训练样本来估计.当K足够大的时候,高斯混合模型可以逼近任意分布[14],因此分布噪声可以由P(A)与加入伪标签样本后的高斯混合分布Q(A)来估算[15]:
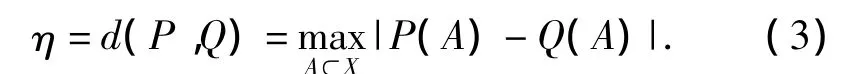
1.2 算法表示
假设L,U分别为有标签样本集和无标签样本集,h为给定的基分类器,P为其伪标签样本集,M为每次迭代训练加入的伪标签样本的数量,H为迭代训练中生成的分类器集合.则ensemble self-learning算法如下:
输入:L,U,并给定最大迭代次数T.
步骤:初始化j=N=0;H=P=Φ;V=L.
在L上训练初始分类器h(0).
Repeat tillj<Torh不再变化.
1)将当前分类器h(j)加入H(j)中.
2)用H(j)分类U中的数据.
3)按照类别比例和置信度从U中选择个N预测结果并加入到临时伪标签数据集Pi’中.
4)令P(j+1)=P'∪P(j).
5)在L∪P(j+1)上重新训练h(j+1).
6)若噪声超过临界值或根据公式(2)估算的泛化误差上升,则令Pi(j+1)=Pi(j),hi(j+1)=h(j).
7)令Pi'=Φ并更新伪验证集V.
8)N=N+m;j=j+1.
输出:H=combine(h(0),h(1),…,h(j)).
为了降低伪标签样本带来的噪声,所提出算法中主要采取了如下3种策略.
1)利用迭代训练中生成的分类器构成的集合来预测样本标签,从而将自训练方法和集成学习结合起来,以提高伪标签的准确率.
2)在算法中按照类别比例(可以从L上估计)来添加伪标签样本.当原始样本存在严重的类别不平衡时,有可能会导致预测结果向大类别倾斜,造成某些小类的伪标签样本不足.这时候可以利用重采样技术对小类别的训练样本过采样,来控制类别比例,从而减少分布噪声.
3)根据定理1和所提出的噪声量化方法,评估当前噪声下的分类器的性能.据此及时移除有可能造成分类性能下降的伪标签样本,实现迭代训练的可回溯机制.
2 试验结果及分析
在6个有代表性的数据集上给出了ESL算法的试验结果,并与2种先进的半监督集成学习算法CoBC[12]和 MCSSB[13]进行了比较.
2.1 试验设置
采用支持向量机(support vector machine,SVM)作为基分类器,并参照Co-EM SVM中的策略,计算SVM的预测结果的信任度;采用SVMlight[16]来实现,并使用其默认参数和线性核函数.
试验数据集有如下6个:①movie(24 841个特征,2个类),把来自于IMDB的电影评论划分为正面和负面的,共包含2 000个样本;②webkb(22 824个特征,4个类),把来自大学的网页划分为学生、课程、院系、项目4类,共包含4 200个样本;③sraa(77 494个特征,4个类),把新闻组中的消息划分为模拟飞行、现实飞行、模拟驾驶和真实驾驶,包含19 684个样本;④sector(22 835个特征,38个类),把网页划分到特定的工业部门,共4 582个样本;⑤blogs(95 583个特征,4个类),根据博客内容划分其发布者的年龄段,包含8 864个样本;⑥ner(60 502个特征,9个类),来自CoNLL 2003数据集,包含48 622个样本.
文中随机选取10组有标签样本作为初始训练集,每组随机选取2 000个当成无标签样本加以利用,最后取其运行结果的平均值.试验时算法中的最大迭代次数T设置为50,m设置为100.
2.2 试验结果及分析
表1给出了各个算法的分类准确率,括号中的值代表有标签样本的总数量.

表1 分类准确率 %
由表1可见,对于同样的算法,增加有标签数据的数量时,得到的准确率都有明显提高.当利用无标签数据辅助训练的时候,可发现绝大多数情况下,各个半监督算法相对于基分类器,在平均准确率上都取得了不同程度的提高.特别是在movie(20)和sraa(40)上,绝大多数半监督算法的准确率甚至还高于其基分类器在movie(50)和sraa(100)上的准确度,这说明半监督学习中使用无标签数据的确有利于提高分类器的准确性.
但是无标签数据的使用并非总是有利的,在某些情况下,可发现伪标签数据反而会降低基分类器的性能,比如在sector数据集上,具体情况可分析图1.图1给出了3个半监督算法及其基分类器分别在webkb(100)和sector(380)上准确率的迭代变化.
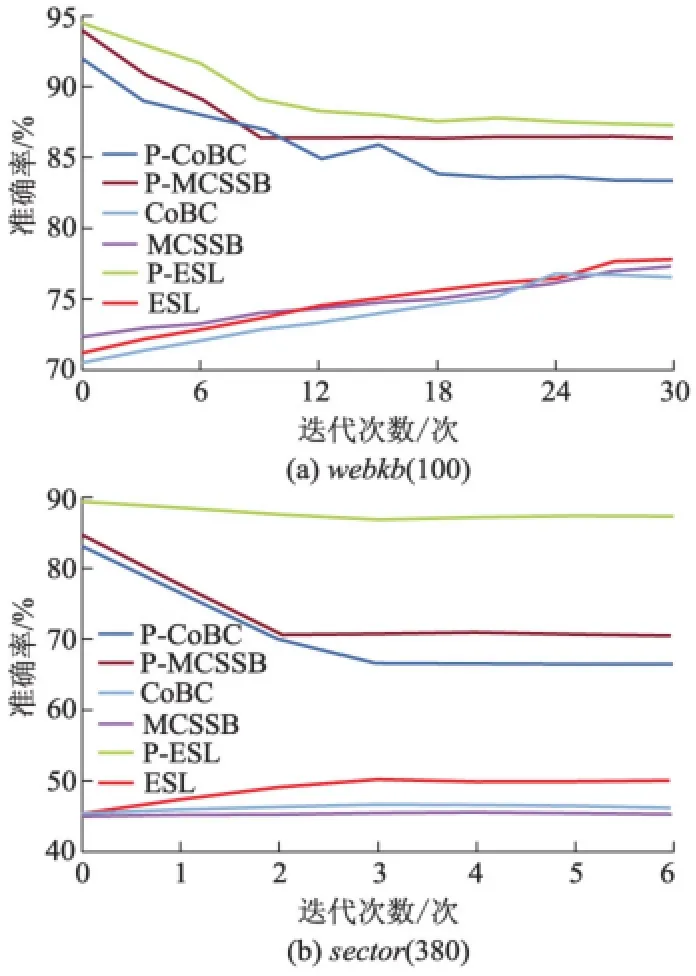
图1 迭代训练中的准确率变化
由图1可见,在结构良好、容易划分的webkb(100)数据集上,随着迭代过程的进行,3个算法的准确率都在提升;而在结构复杂的sector上,由于伪标签样本的准确率较低,相应地,CoBC和MCSSB的准确率都有不同程度的下降.
CoBC和MCSSB在使用伪标签样本时,都没有采用对噪声进行过滤的措施;文中提出的算法不仅利用信任度递增地添加伪标签样本,还能够把不好的伪标签样本及时从训练集中移除,因此获得了总体上更好的分类效果.
3 结论
文中提出的算法在75%的试验数据集上都取得了最好的准确性以及最高的平均准确率.相关试验表明该算法能有效控制伪标签样本中的噪声,从而提高半监督分类算法的泛化性能.随着伪标签样本的加入,迭代训练产生的中间分类器的差异逐渐缩小,导致其集成的效果存在局限性.在今后的工作中,笔者将在集成方法上开展进一步的研究.
References)
[1]Mohamed Farouk Abdel Hady,Friedhelm Schwenker.Semi-supervised learning[J].Handbook on Neural Information Processing Intelligent Systems Reference Library,2013,49:215-239.
[2]Jiang Zhen,Zhang Shiyong,Zeng Jianping.A hybrid generative/discriminativemethod forsemi-supervised classification [J].Knowledge-Based Systems,2013,37(2):137-145.
[3]Hu Wei,Chen Jianfeng,Qu Yuzhong.A self-training approach for resolving object coreference on the semantic web[C]∥Proceedings of the20th International Conference on World Wide Web.Hyderabad,India:ACM,2011:87-96.
[4]He Yulan,Zhou Deyu.Self-training from labeled features for sentiment analysis[J].Information Processing and Management,2011,47(4):606-616.
[5]Yaslan Y,Cataltepe Z.Co-training with relevant random subspaces[J].Neurocomputing,2010,73(10/11/12):1652-1661.
[6]Sun Shiliang,Jin Feng.Robust co-training[J].International Journal of Pattern Recognition and Artificial Intel-ligence,2011,25(7):1113-1126.
[7]Zhang Minling,Zhou Zhihua.CoTrade:confident cotraining with data editing[J].IEEE Transactions on Systems,Man,and Cybernetics,Part B:Cybernetics,2011,41(6):1612-1626.
[8]Abdel Hady M F,Schwenker F,Palm G.Semi-supervised learning for tree-structured ensembles of RBF networks with co-training[J].Neural Networks,2010,23(4):497-509.
[9]Zhang Minling,Zhou Zhihua.Exploiting unlabeled data to enhance ensemble diversity[J].Data Mining and Knowledge Discovery,2013,26(1):98-129.
[10]Chen Ke,Wang Shihai.Semi-supervised learning via regularized boosting working on multiple semi-supervised assumptions[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2011,33(1):129-143.
[11]Li Yufeng,Zhou Zhihua.Towards making unlabeled data never hurt[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2015,37(1):175-188.
[12]Jiang Zhen,Zeng Jianping,Zhang Shiyong.Inter-training:exploiting unlabeled data in multi-classifier systems[J].Knowledge-Based Systems,2013,45(3):8-19.
[13]Druck G,Pal C,McCallum A,et al.Semi-supervised classification with hybrid generative/discriminative methods[C]∥Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.San Jose,USA:ACM,2007:280-289.
[14]张晓娜,何 仁,刘志强,等.基于空间信息高斯混合模型的运动车辆检测[J].江苏大学学报:自然科学版,2011,32(4):385-388.
Zhang Xiaona,He Ren,Liu Zhiqiang,et al.Moving vehicle detection method based on Gaussian mixture model of spatial information[J].Journal of Jiangsu University:Natural Science Edition,2011,32(4):385-388.(in Chinese)
[15]Decatur S E.Statistical queries and faulty PAC oracles[C]∥Proceedings of the6th Annual ACM Conference on Computational Learning Theory.Santa Cruz,USA:ACM,1993:262-268.
[16]Joachims T.Making large-scale SVM learning practical[J].General Information,1998,8(3):169-184.
