Lucene在应急预案检索中的应用
2015-01-27许洪敏凌卫青
许洪敏,凌卫青
(同济大学 CIMS 研究中心,上海 201804)
0 引言
传统的安全生产系统中,对应急预案的查询仅局限于对文件名的查询,即将文件名作为数据库字段中的内容,利用like 关键字对文件名模糊查询,但是like 往往会导致全表扫描,数据量很大的时候,搜索速度会很慢,而且传统的这种方式不能实现对文件内容的模糊查询。Lucene 是实现全文检索一种很有必要的开源工具包,它不仅提供了检索所必须的建立文件索引,实现文件模糊查询,对索引的文本进行分析等架构,而且还提供了丰富的实现检索所必须的API 接口像各种分词算法等,但是它不是像百度或者谷歌那样现成的搜索引擎直接可以拿来用,所以通过研究其内部丰富的接口或在此基础上建立自己的检索引擎架构即可实现全文检索功能[4]。
Lucene 具有如下突出优点:①建立索引时产生的索引文件其格式不受平台影响,因此无需考虑平台或系统的影响,索引只要建立好就可使用;②是面向对象的开源架构,对用户来讲,使用和理解起来更加的方便,而且若Lucene 内部的功能不能够满足用户需求,用户还可对新功能进行扩展;③Lucene 内部封装了比较成熟和完善的查询引擎,因此,使用起来相当的方便,绝大多数情况下不需要用户去实现查询功能。
本文将简述在应急预案管理中利用Lucene 实现对关键字模糊查询的过程。
1 应急预案信息简介
应急预案是针对可能发生的重大事件(如火灾等)或灾害(如地震等),为了使事故的损失降低到最低,使救援行动能够有条不紊迅速快捷安全有效的开展而事先制定的解决方案,该解决方案很清楚的表述了制定方案的目地是什么,根据是什么,在什么情况下使用,谁来启动,预警条件是什么,怎么上报而且还明确了整个事故的前期后后,谁需要做什么,怎么做,做到什么程度,根据事故情况的不同应对方法也不一样(这里有现场处置在里面),有多少人力,物力财力可以调用等[2]。应急预案按照种类分为自然类和事件类,在灾害类中又分为自然灾害类和事故灾害类,在事件类中又分为公共卫生事件类和社会安全事件类。当然,为了更有效的提高应急效率,应急预案也要时常的进行更新。由于应急预案内容的丰富性,仅仅对文件名进行模糊搜索是远远不够的,由于Lucene 能够实现全文检索的功能,所以对应急预案的模糊搜索是通过Lucene 来完成的。由于应急管理具有及时型和紧迫型,提高信息检索的效率准确度,以及信息的全面性,对提高应急响应很有帮助。
2 预案检索的实现过程
对于文档建立索引的过程,由于文档的保存形式大多为PDF 格式和Word 格式,所以要预选对文档做处理和加工,使其符合调用Lucene 接口的规范,然后调用Lucene 相应的API 接口,将分词后的索引信息和文档信息保存的索引库中,接下来就是查询的过程,对要查询的信息经过分析以后给相应的接口,使其从索引库中检索出用户想要的信息。
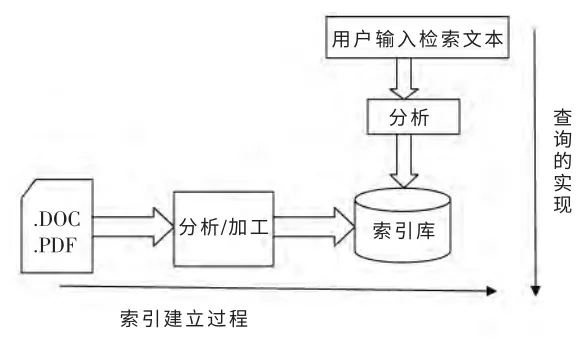
图1 检索过程Fig.1 Retrieval process
2.1 提取文档内容
对于应急管理中的文档的保存形式并不是纯文本的形式,应急管理中文件的储存形式大多都是Adobe 公司PDF 和MicroSoft 公司的word。所以在建立索引的时候,不是简单的读取文件信息,因为对于Lucene 来讲,使用它的接口是有规范的,简单的读取是读取不出来的,而是要根据文件格式的不同采取不同的办法,把文件内容提取出来转化成Lucene 能够识别的形式。PDF 是Adobe 公司开发的一种电子文件的存储格式,其文件格式将文字、格式、颜色及独立于设备和分辨率的图形和图像等封装在一个文件中。如果要得到其中的文本信息,需要对文件格式进行解析。目前最常用的解析PDF的工具是PDFBox(这里不做详细讲解),使用PDFBox 提供的API,就可以从PDF 文件中的内容转化成文本的形式,从而提取出文件内容。对于Word 中内容的提取,.net 自带的Microsoft.Office.Interop.Word.dll,C# 通过引进dll 文件和调用相应的接口函数(这里不做详细讲解),就可将Word 中的内容转化成纯文本的形式,从而提取出文件内容。这两种类型的文件格式转化成纯文本以后,就可以调用Lucene 中的接口实现接下来的操作。
2.2 建立索引的执行过程
Lucene 最核心的特征就是其索引结构的特殊性,这种特殊的索引结构可以大大的提高检索效率。那么Lucene 索引结构的特殊性表现在哪里呢?Lucene 使用的是倒排文件索引结构,倒排文件索引是通过属性的值来查找对应的内容,即它关键词、关键词在文中出现次数、关键词在文中的位置分别作为词典文件、频率文件、位置文件保存;同时,为了能够快速查找到关键词,Lucene 对关键词的存储采用了一定的顺序;另外,Lucene 引入Field 的概念来定义文件的属性,根据文本中的具体信息,可将文本分成多Field,比如可将文件名放入一个Field,作者放入一个Field 等;每次创建新的索引文件,Lucene 不会马上将这些新创建的索引文件合并到原先的索引中,而是对其进行定期处理,方便了文件的维护[5]。Lucene 建立索引过程归结起来就是首先获取数据,然后通过索引规则建立索引,最后将这些索引文件写入磁盘或内存中。具体过程是由File 对象获取待索引的文件,然后根据具体属性信息比如文件名、作者、上传人等信息构造出多个Field 对象,这些Field 对象的集合构成了Document,然后调用索引器IndexWriter对象的addDocument(doc)方法将Document 加入索引库中,此时索引对象IndexWriter 会对文档进行分词,过滤的处理,接下来Lucene 会把文档存放在索引库中,并自动指定一个内部编号,用来标识这条数据另一方面更新词库,把文本中的词找到并放在词汇表中,建立与文档的对应关系。具体的流程如图2 所示。
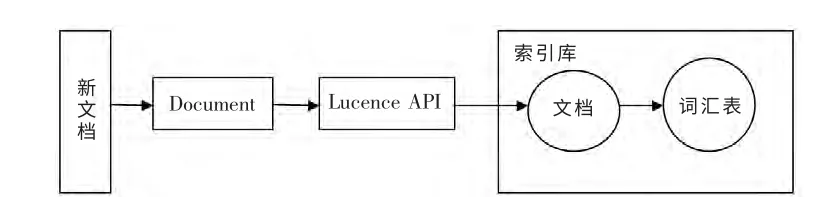
图2 索引建立过程Fig.2 Process of establishing index
2.3 查询过程
首先把要查询的字符串转化成Query 对象,查询字符串也要先经过Analyzer,要求搜索时使用的Analyzer要与建立索引时使用的Analyzer 要一致,当然这里包括分词方法要一致,否则可能搜不出结果,比如按照一元分词建立的索引,在查询将查询的字符串按照二元分词来进行切分的,肯定找不到结果,调用其API 设计具体的检索器,包括默认域、索引库位置的指定,以及将关键词通过布尔逻辑运算符连接起来形成复杂的查询语句。随后将正确解析的检索表达式传给IndexSerarch.search()进行查询,系统通过检索器对索引文件执行查询操作,然后进行去重、合并检索结果集,排序,最后将检索结果集提交给用户。
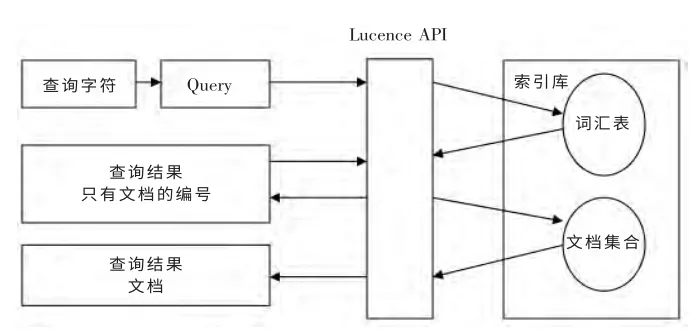
图3 查询的实现Fig.3 Implementation of search
查询功能可以根据建立索引库时定义的可检索项提供多条检索途径,除了可检索如文件名、上传人、关键词等进本信息外,还可检索根据详细的信息如全文等。查询功能各个检索项之间提供了逻辑“与”、“或”、“非”关系的任意一种组合形式,对于要查询的信息可以采用布尔表达式,自然语言,字段表达等多种方式的表达形式,可模糊查询出用户想用的信息。
2.4 盘古分词
分词是全文检索的前提和核心。Lucene 处理分词大致提供了了两类方法,一类方法是建立一个丰富完备的词汇库,该词汇库能够清晰的表达所有的关键词,虽然这种方法可以大大的提高检索的效率但是其代价太大可行性不高;另一种方法是通过简单的算法进行切分,Lucene 中采用以某几个词进行切分,但是这种方法缺乏灵活性,虽然此方法在实际运用中成本低但在实际运用中,可行性不高。盘古分词是一种多元分词算法,它是基于.net 平台的开发的一款开源中文分词组件,其思想是采用字典和统计结合相结合的方法,在总体效果上相对来说优于前两种方法。盘古分词对相对复杂的分词提出了0~3 级冗余和0~5 权重[3]。冗余是分词效果上来界定的,权重是分词性能上来界定的,比如,设定冗余为0代表可得到最佳的分词组合,若设定冗余为1 即代表此为最佳的组合,以此类推,根据实际情况可以自己设定,而权重的不同分词性能是不同的。比如设定“咖啡”的权重大于“咖”或“啡”的权重,那么包括“咖啡”的记录就会优于“咖”或“啡”的记录搜索到。
3 检索界面设计与功能实现
3.1 检索界面
查询系统要做的事情就是简单方便的查找出用户所需要的信息[1]。同时在符合简单易用的基础上,也要考虑检索要求,于是设计出了如图4 所示的界面,该界面符合预案库管理中对文档的检索要求和用户使用习惯。

图4 输入界面Fig.4 Input Interface
检索界面中的“请输入…”是提醒用户输入要查询的关键字,这里的关键字可以查文件名中的关键字,也可查上传人中的关键字,最重要的是可以查询文件内容中的关键字,这里的查询是“或”的查询方式,输入了关键字以后,会在文件名,上传人以及文件内容中进行查找,只要有一个域里面含有关键字,就会将该文档显示出来,这样设计更加的合理,而且不会疏漏信息。
3.2 显示界面
对于显示界面,一方面要考虑显示的信息要尽量多,另一方面还靠考虑布局和排版,给用户一种清爽简洁的感觉,因此,考虑这两种因素,设计出了图5 所示的界面。
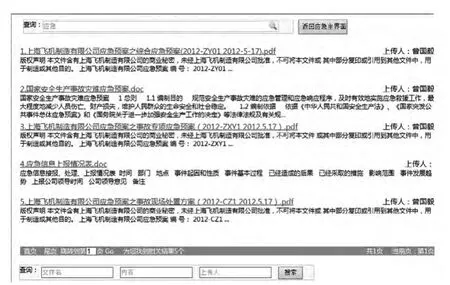
图5 显示界面Fig.5 Display Interface
在该显示界面中,查询框中的文字是从图4 的检索输入界面带入过来的,目的是方面用户的操作,使用户不用担心忘记刚刚查询的信息。当然,可将查询框中的文字删除,重新检索,检索原理和检索输入界面一致。考虑到易用性,该页面的排版与当今主流的搜索引擎网站保持一致,对文档信息选择只显示两三行,若要了解详细信息,可点击文件名。
考虑到用户对文件名,上传人,文件内容了解的比较深,也可使用检索显示界面下方的检索,该检索是一个“与”检索,是一种比较精细的查找方法,可实现单一搜索,组合搜索,检索起来将更加方便和高效。
4 结论
利用Lucene 这个开源软件实现了检索功能的开发,实践证明了Lucene 是一款很好的全文检索软件,将会极大的推动全文检索技术在各个行业或领域中的应用。但是值得注意的是,在大信息量的环境下,如何安全的存储索引文件即可以节省空间又可以提高检索的速度,这是值得注意的问题。
[1]李焱,路莹.基于Lucene 的医学文献检索系统[J].中华医学图书情报杂志,2010,9.
[2]陈安,陈宁,等.现代应急管理理论与方法[M].科学出版社,2009.
[3]彭哲,陈敬之. Lucene 全文检索的应用及检索效率测试研究[J].图书馆学研究,2009,2.
[4]金玉玲.基于Lucene 的全文检索系统的研究与应用[D].大连理工大学,2005.
[5]Lucene 工作原理之倒排引.http://blog.csdn.net/chichengit/article/details/9235157,2013-07-03.
