一种基于LBS 的用户锚点区域混淆隐私保护方案
2015-01-15王智明
王智明
(莆田学院 信息工程学院,福建 莆田351100)
随着21 世纪空间定位技术,尤其是GPS 和基站定位技术的飞速发展,给人们的生活方式带来了深刻的影响,通过便携设备可以轻易地获得关于个人位置的各种服务。面对巨大商机,各大厂商和电信移动公司更是不甘落后,从传统的电信、移动公司,到国内外IT 业界巨头如腾讯、Google、Facebook 等纷纷推出各种基于位置的服务LBS。典型的LBS 应用如寻找周围街区顾客口碑好的咖啡店、从当前地点到某旅游点的最佳路线、给商户周边500 m 内的用户发送打折信息等[1]。
在体验LBS 服务带来巨大便利的同时,用户个人隐私的泄露成为越来越严重的社会问题,泄露的主要途径有:(1)用户发往服务器的LBS 查询中途被截取;(2)服务器被攻破,黑客获取用户的LBS 查询;(3)不良的中间服务提供商或个人将用户信息出售获利。利用这些被泄露的信息,就可获知用户活动规律,推断用户个人兴趣、活动习惯、宗教信仰、疾病就诊历史等这些用户本不愿公开的隐私[2]。随着LBS 服务的深入发展,位置隐私保护问题日益引起人们的重视,学术界提出来不少关于个人位置隐私的保护方法,除了部分是对用户标识符、查询内容本身的保护[3],大部分还是侧重于对用户位置信息的保护。
1998 年,P.Samarati 和L.Sweeney 为了阻止连接攻击,提出k-匿名隐私保护模型[4],规定匿名区域必须至少有k 个用户,而攻击者不能从这k 个用户中识别出真正的用户。而后Gruteser 等[5]将k-匿名技术引入到LBS 隐私保护中,通过对用户的真实位置进行概化处理,模糊用户的空间位置,达到隐私保护的目的。在Gruteser 之后,为减小匿名区域,提高查询服务质量,先后有学者提出一些新的匿名方 案:如 New Casper[6],NNC(Nearest Neighbor Cloak)[7],HC(Hilbert Cloak)[7],ANNC(Adaptive Nearest Neighborhood Cloaking)[8]等等。这些方案都采用了中心服务器的系统结构,即匿名区域的构建任务交由可信的第三方匿名服务器来完成。
除了以上基于k-匿名技术的隐私保护模型,在LBS 查询服务中,还有一些隐私保护是采用假位置[9],即移动用户通过假位置,向服务器发起查询请求,这样即便查询相关数据被攻击者截获,也无法获知真实的用户位置。如文献[9]提出的基于LBS 的隐私区域感知虚拟生成算法,通过选取一些基于虚拟圆或网格方法的候选用户,并将这些候选用户位置模糊处理,形成基于熵隐私度量的虚拟位置。文献[10]提出的逆向增量近邻查询算法,通过设定取代真实位置的锚点,逐步获取兴趣点候选集并计算出查询结果,增加匿名隐私效果的同时提高了查询结果的准确性。又如SpaceTwist[11]算法也是基于假位置的算法,用户随机选取附近的某个点作为锚点[7,10],通过此锚点向LBS 服务器发出增量近邻查询[11]。以用户真实位置U 为圆心,已发现的第k个近邻为半径画圆,形成的区域称为需求空间;类似的以锚点U' 为圆心画圆[10],将LBS 服务器返回的近邻结果统统包含其中,此区域称作供应空间。算法开始时,初始化供应空间为空集,需求空间为整个空间,随着算法进行,供应空间不断扩大,需求空间不断缩减,直到需求空间完全覆盖供应空间时SpaceTwist 算法结束。
文中分别选取基于k-匿名和假位置的位置隐私保护的典型算法NNC(Nearest Neighbor Cloak)、SpaceTwist 进行分析:
1)基于k-匿名的NNC 算法,其本质是一种以服务质量换取隐私保护的技术。此算法有两个不足:(1)用户最终获得的并非精确的查询结果,而是一个模糊的值;(2)把用户所在的具体位置一个点,使用一个区域来替换,会导致候选结果集大量增加,从而带来更大的系统计算和通信量。
2)基于假位置技术的SpaceTwist 算法,虽然没有k-匿名那么高的计算量和通信量,但由于缺少用户间的协作[10],没能实现k-匿名,故隐私保护功能较差。通过用户查询请求的分析,攻击者就能将用户锁定于在某个区域范围,而此时若该区域只有一个查询用户,攻击者就很容易鉴别出用户。此外SpaceTwist 算法中,每次查询服务会返回一个包含k个目标节点信息的TCP 包,当算法结束时此TCP 包中,仅有1 个目标节点信息是有效的,其余k - 1 个节点构成了数据冗余,增加了系统的开销[9]。
基于上述存在的问题,文中提出了一种基于LBS 的用户锚点区域混淆隐私保护方案即ARCS(Anchor Region Confusing Scheme),首先选取用户锚点,并利用锚点构建的区域进行位置混淆,提高了抗攻击能力,同时ARCS 也降低通信开销和查询时间开销,提高了查询效率。
1 面向位置服务的匿名隐私保护方案模型
文中ARCS 方案基于以下假定:(1)攻击者只能监听位置匿名服务器与LBS 服务器之间的数据包内容,攻击者不能篡改或破坏数据;(2)查询用户所在位置周围的移动节点是均匀分布的,用户位置空间分布的越均匀空间信息熵就越大,相应地用户能得到更好的隐私保护[10]。
1.1 ARCS 方案模型
文中ARCS 方案基于服务器结构如图1 所示,它是由移动用户、位置匿名服务器、LBS 服务器3 部分构成。

图1 ARCS 方案服务器结构Fig.1 ARCS scheme server structure
1.1.1 移动用户 指使用便携设备(如PDA、手机、全球定位系统GPS 等)发出有关位置查询请求的用户,便携设备特点是体积小便于随身携带,但数据存储与处理能力较弱。
1.1.2 位置匿名服务器 该服务器主要功能包括实现位置的匿名处理,将用户准确的位置信息处理成为一片匿名的区域(当前能够处理的匿名区域一般是矩形或圆形);存储用户高频率的查询请求以及相对应的候选结果集[11];对用户的查询进行匹配处理,共享候选结果集,以提高系统效率。
1.1.3 位置访问LBS 服务器 作为ISP (Internet Service Provider)为终端用户提供k 近邻查询和其他相关位置的服务。
ARCS 方案模型具体工作流程:移动用户将查询内容与隐私要求,通过文件的形式发送到位置匿名服务器,位置匿名服务器首先在查询日志表中查询是否存在该用户、是否有符合该用户的候选结果集,若有的话将该结果直接共享给用户,提高查询系统效率;若没有则退而查找是否有符合该用户的匿名区域,有的话就共享该匿名区域。如果匹配的匿名区域也不存在,通过ARCS 方案算法产生新的匿名区域,完整走一遍ARCS 方案算法,直到得到用户所需查询结果(见图1)。
1.2 ARCS 方案的位置匿名与邻近节点处理过程
ARCS 方案模型如图2 所示。实现位置隐私查询的具体步骤:
1)以用户U 的实际地理位置为坐标中心。由给定的角度θ(相对于x 坐标)按照用户隐私要求确定锚点 U',用户 U 与锚点 U' 之间距离记作dist(U,U')。
2)在用户U 与锚点U'的延长线上取点O,其中OU'长度为r,以O 为圆心做半径为r 的圆形匿名区域(半径r 的大小作为参数,根据匿名程度和节点密度情况设置)。
3)位置匿名服务器分别将圆形匿名区域内的节点q1,q2,… qn的范围查询请求,发送到LBS 服务器,LBS 服务器将处理产生的候选结果集,返回给位置匿名服务器。
4)位置匿名服务器对步骤3)中得到的结果集进一步筛选,并将最终结果集交给用户U,完成ARCS 算法。

图2 ARCS 方案模型Fig.2 ARCS scheme model
下面讨论在ARCS 方案算法中匿名区域内的节点查找范围U'K 的相关取值情况。
如图3 所示,U 是查询用户U 所在点,UM 是用户查询范围参数,大小由查询用户给出,当U'K <dist(U,U')时,即匿名区域内的节点查找半径小于用户U 与匿名区域内锚点U'的距离,LBS 服务器处理得到的结果集,只包含小部分用户U 查询需求范围,大部分查询结果都被遗漏,故无法得到满意的查询结果[12]。
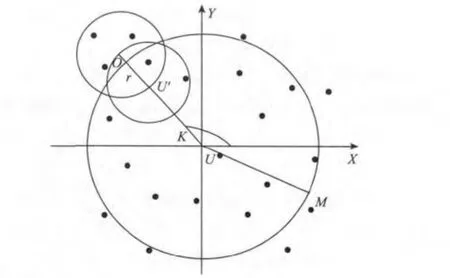
图3 U'K <dist(U,U')情况Fig.3 U'K <dist(U,U')case
如图4 所示,当U'K = dist(U,U')时,匿名区域内的节点查找半径等于用户U 与匿名区域内锚点U' 的距离,匿名区域内的节点查询范围U'K,正好覆盖查询用户U 所在的位置,即U 与K 两点重合,此时LBS 服务器处理得到的结果集能包含较多用户U 所需要的结果,故查询结果基本能令用户满意。

图4 U'K = dist(U,U')情况Fig.4 U'K = dist(U,U')case
如图5 所示,当U'K = dist(U,U')+ UK,这时用户U 的查找半径加上用户U 与锚点U'间的距离,正好等于匿名区域内的节点查找半径,U'K 正好覆盖了用户U 的查找半径UK,LBS 服务器处理得到的结果集能包含用户U 所需要的全部结果,此时用户能得到满意的查询结果。

图5 U'K = dist(U,U')+ UK 情况Fig.5 U'K = dist(U,U')+ UK case
综合以上3 种情况,在ARCS 方案算法中,为了让用户得到较理想的查询结果,规定U'K 的取值范围定在dist(U,U')与dist(U,U')+ UK 之间,记作

公式(1)中,用户U 的查找半径UK 由用户提出,在UK 值一定时,当dist(U,U')越小,匿名区域节点的查询范围U'K 就越小,相应LBS 服务器需要的查询处理开销也就越少。但dist(U,U')的减小会造成隐私保护有效性降低,因此,需要根据用户的匿名要求,平衡系统查询开销与隐私保护的有效性,选取合理的锚点U'。
2 ARCS 方案性能分析
关于ARCS 方案的性能,主要从查询结果误差率、查询时间开销和匿名性3 个方面来衡量。
2.1 查询误差率
查询误差率是衡量LBS 服务器查询处理的一个有效指标,误差率W 可以表示为用户查询漏选目标在用户查询范围内目标集中所占的比例。
设任意匿名区域内有移动节点p1,p2,p3,…,pn,各节点进行范围查询处理所对应的区域分别记做C1,C2,C3,…,Cn,则LBS 服务器返回的结果集记作Pc= {p| ∀p ∈C},其中C = C1∪C2∪C3…∪Cn,即C =;设用户U 查询的范围区域为CU,则该区域内目标集用PU表示,记作PU= {p | ∀p ∈CU},则LBS 服务器查询处理的误差率W 可以记作

由式(2)可以看出,当PU∩PC的结果集变少,查询误差率变大,系统开销变小。理论上当匿名区域各节点返回的查询结果集Pc能覆盖用户U 的查询范围区域结果集PU时,用户的查询误差率能够达到0%,即完全无误差状态。当然要达到该状态,需消耗较大的系统开销。
2.2 查询时间开销
查询时间开销主要包含匿名处理、筛选结果集、产生候选集、数据通信方面的开销。
1)匿名处理时间开销:用户提交查询要求后,位置匿名服务器进行匿名处理所耗费时间的,记为Tanony(p,q)。Tanony(p,q)值的大小,取决于用户隐私程度的要求p 和匿名区节点密度q 的情况,隐私要求程度p 越高,节点密度q 越高,匿名处理时间开销Tanony (p,q)就越大。
2)筛选结果集:位置匿名服务器需要对LBS 服务器返回的查询结果集筛选处理,去除那些与用户相距较远的匿名区域节点,筛查出与用户U 邻近的节点,整个筛选过程的时间开销记为Tfilter。
3)产生候选集:LBS 服务器对匿名区域节点的查询处理生成候选结果集需要耗费时间,记为Tcandi。
4)数据通信:包括位置匿名服务器将匿名区域传递给LBS 服务器,LBS 将候选查询结果集传输给位置匿名服务器需要消耗的时间,以及用户U 与位置匿名服务器间通信,总耗费时间记为Tcomm。综上几个主要因素,查询总时间开销可记为

从公式(3)看出,LBS 服务器通过用户锚点U'的合理选取,位置匿名服务器候选结果集进行筛选处理减少结果集,优化了系统通信流量,也缩短了查询处理的时间。另外,对于频率高的查询服务,位置匿名服务器将其保存于共享数据库中,便于有类似查询需求的用户共享,进一步减少了查询时间开销Tcost。
2.3 匿名性
攻击者通过截取匿名服务器与LBS 服务器间的数据通信,可以推断出用户所在区域范围:(r +dist(U,U'))2。由公式(1)

进一步可得
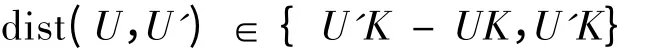
故攻击者可推断出用户所在区域范围:

根据隐私保护的需要,只要增加锚点的距离即dist(U,U'),由公式(1)可知匿名区域节点的查询范围U'K 相应增大,攻击者推断出用户所在区域范围{(r + U'K - UK)2,(r + U'K)2}也成平方级增加,大大降低了用户位置暴露的风险。
3 实验结果与分析
3.1 实验环境
实验运行环境为Intel Core2 Duo,2.13GHZ,2G RAM,Windows XP 的PC 机,算法采用Java 语言。实验中所有的移动对象是由基于网络的移动对象生成器产生(Network-based Generator of Moving Objects),生成器的输入端为德国城市古登堡Oldenburg 的交通路网,区域面积:23.572 km*26.915 km。
分别研究节点密集度、用户与锚点距离dist(U,U')不同取值情况下,ARCS、NNC 和SpaceTwist 算法在查询误差率、查询时间开销和匿名性方面的表现。实验所用参数:节点密集度通过Oldenburg 市节点个数来衡量,参数取值(1 000,2 000,4 000,6 000,8 000,10 000,20 000,40 000,60 000,80 000,100 000,120 000)、用户与锚点距离dist(U,U')以米为单位,参数取值(50,100,150,200,250,300)。
3.2 查询误差的比较
图6 是用户与锚点距离dist(U,U')取值不同情况下,3 种算法在查询准确率上的表现。从图6 可以看到,NNC 算法对于dist(U,U')不敏感,随着dist(U,U')取值50 ~500 的变化,该算法的查询准确率始终趋近1,也就是查询误差率保持为0;而SpaceTwist 算法(其算法查询过程见图7)和ARCS算法的查询准确率与dist(U,U')参数相关性较大,随着dist(U,U')的值增加,两算法查询准确率都出现一定程度下降,查询误差率越来越大。

图6 不同dist(U,U')取值下3 种算法查询准确率对照Fig.6 Comparison results of the query accuracy of the three algorithms using the different dist(U,U')
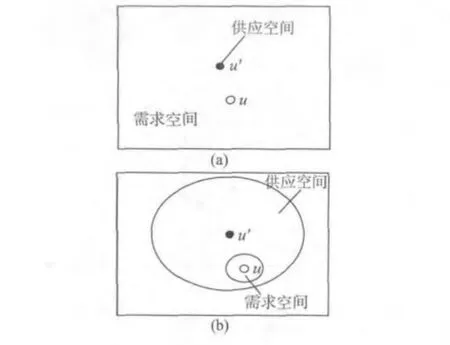
图7 SpaceTwist 算法查询过程Fig.7 SpaceTwist algorithm query process
dist(U,U')取值50 ~150 时,ARCS 算法查询误差率略小于SpaceTwist 算法,而当dist(U,U')取值200 ~300 时,SpaceTwist 算法查询误差率略小。这是因为SpaceTwist 算法需要不断向LBS 服务器请求最近的兴趣点POI,直到用户得到满意结果为止,虽然这样能达到较低的误差率,但不断向服务器发送请求也导致了通信开销的加大。而由公式(2)知,当匿名区域各节点返回的查询区域集PC覆盖用户U 的查询范围区域PU时,ARCS 算法能达到100%的查询准确率,即实现零查询误差率。
3.3 查询时间开销比较
实验结果如图8 所示。NNC 和ARCS 2 种算法的查询时间开销都受到匿名区间节点密度的影响,随着匿名区间节点数变大,两种算法的系统消耗时间均明显增加。NNC 算法和ARCS 算法在不同节点数测试中,没有哪个算法在查询时间开销上明显占优势,当用户U 周边的节点密度大于锚点U',即P(U)>P(U')时,ARCS 算法通信消耗时间稍优于NNC 算法;而当P(U)<P(U')时,NNC 算法则稍占优于ARCS 算法。综合来看,在实验的6 种节点数情况下,NNC 算法平均耗时1.898 s,ARCS 算法平均耗时1.847 s,ARCS 算法时间开销稍好于NNC 算法。这主要是由于ARCS 算法中位置匿名服务器对查询结果集进行优化处理,剔除了远离用户的那些节点,很大程度上减小了服务器间的通信量。
如图9 实验结果所示,SpaceTwist 算法的通信时间开销同样受到匿名区间节点的密度影响明显,随着匿名区间节点数变大,两种算法的系统通信消耗时间都明显增加,但ARCS 算法相比SpaceTwist算法,在查询时间消耗上有一定的优势。这主要是因为SpaceTwist 算法需要不断地向LBS 服务器发出请求,获取最近的兴趣点POI,因而增加了通信量开销。

图8 不同节点数下NNC 和ARCS 算法的时间开销比较Fig.8 Time cost comparison of the ARCS and NNC algorithms for different nodes
4 结 语

图9 不同节点数下SpaceTwist 和ARCS 算法时间开销比较Fig.9 Time cost comparison of the ARCS and SpaceTwist algorithms for different nodes
随着人们对基于位置的服务质量要求越来越高,个人位置隐私日益受到重视。在对当前位置隐私保护技术进行较全面了解的基础上,通过对NNC、SpaceTwist 两种算法的分析和改进,文中提出了一种面向位置服务的匿名隐私保护方案ARCS,并通过了理论分析和实验验证。该方案选取与用户有一定距离的假地址来产生匿名区域,隐藏了用户的真实位置,提高了算法的安全性。另外,通过候选结果集筛选处理和查询结果共享,提高了系统整体查询效率。
[1]Wemke Mariiis,Durr Frank,Rothennel Kurt. PShare:position sharing for location privacybased on multi-secret sharing[C]//Proceedings of the 10th IEEE International Conference on Pervasive Computing and Communications. Lugano,Switzerland:Computer Society,2012.
[2]Talukder N,Ahamed S I. Preventing multi-query attack in location-based services[C]//Proceedings of the Third ACM Conference on Wireless Network Security (WiSec).New York:2010:25-26.
[3]Samarati P.Protecting respondents identities in microdata release[J]. IEEE Transactions on Knowledge and Data Engineering,2001,13(6):1010-1027.
[4]Samarati P,Sweeney L.Generalizing data to provide anonymity when disclosing information(abstract)[C]//Proceedings of the 17th ACM SIGACT-SIGMODSIGART Symposium on Principles of Database Systems.New York:ACM Press,1998.
[5]Gruteser M,Grunwald D.Anonymous usage of location-based services through spatial and temporal cloaking[C]//Proceedings of the 1st International Conference on Mobile Systems,Applications And Services.New York:ACM Press,2003.
[6]Mokbel M F,Chow Chi-Yin,Aref W G. The new Casper:query processing for location services without compromising privacy[C]//Proceedings of the 32nd International Conference on Very Large Data Bases(VLDB’06).New York:ACM Press,2006.
[7]Kalnis P,Ghinita G,Mouratidis K,et al. Preventing location-based identity inference in anonymous spatial queries[J]. IEEE Transaction on Knowledge and Data Engineering,2007,19(12):1719-1733.
[8]Talukder N,Ahamed S I. Preventing multi-query attack in location-based services[C]//Proceedings of the 3rd ACM Conference on Wireless Network Security.New York:ACM Press,2010.
[9]NIU B,ZHANG Z,LI X,et al. Privacy-area aware dummy generation algorithms for Location-Based Services[C]//Communications (ICC),2014 IEEE International Conference on.Sydney,Australia:IEEE,2014:957-962.
[10]马春光,周长利,杨松涛,等.基于Voronoi 图预划分的LBS 位置隐私保护方法[J].通信学报,2015(5):5-16.
MA Chunguang,ZHOU Changli,YANG Songtao,et al.LBS location privacy preserving method based on voronoi graph partitioning[J].Journal on Communications,2015(5):5-16.(in Chinese)
[11]YIU M L,Jensen C S,HUANG X,et al.SpaceTwist:managing the trade-offs among location privacy,query performance,and query accuracy in mobile services[C]// Proceedings of the IEEE International Conference on Data Engineering(ICDE.08).Cancun,Mexico:IEEE,2008.
[12]Kim Yong-Ki,Hossain Amina,Hossain Al-Amin,et al. Hilbert-order based spatial cloaking algorithm in road network[J].Concurrency and Computation:Practice and Experience,2013,25(1):81-88.
