基于鲁棒估计的最大前缀RFID防碰撞算法
2015-01-06唐小虎张莉涓杨瑞琴
王 勇,唐小虎,张莉涓,杨瑞琴
(1.西南交通大学a.物理科学与技术学院;b.信息科学与技术学院,成都610031; 2.中国石油四川成都销售分公司,成都610072)
基于鲁棒估计的最大前缀RFID防碰撞算法
王 勇1a,1b,唐小虎1b,张莉涓1b,杨瑞琴2
(1.西南交通大学a.物理科学与技术学院;b.信息科学与技术学院,成都610031; 2.中国石油四川成都销售分公司,成都610072)
针对射频识别(RFID)系统中标签数量未知的情况,采用传统ALOHA算法进行标签估计,在标签数量较大而初始帧长度较小造成估计误差较大时,初始帧长度为固定值,通过改变响应标签数量的方式,达到准确估计标签的目的。研究标签鲁棒估计算法和随机前缀查找树(PRQT)防碰撞算法,在此基础上提出基于鲁棒估计的自适应最大前缀查找树(PMQT)防碰撞算法。理论分析和仿真结果表明,该算法系统效率可达50%以上。PMQT算法比PRQT算系统效率提高18%~30%,对标签估计偏差具有较高的鲁棒性。
射频识别;标签识别;标签估计;防碰撞算法;鲁棒性;自适应
1 概述
防碰撞算法要求高效可靠地识别标签,这对于射频识别(Radio Frequency Identification,RFID)系统工程应用是一个现实的问题。在Reader-Talk-First模式中,阅读器首先发出查询命令,其查询范围内的标签将返回存储的信息。因为所有的标签是共享信道方式和阅读器通信,所以不可避免地导致互相干扰(碰撞),造成多标签传输时系统性能的下降。
防碰撞问题与经典的多址通信相似,解决方案有树型协议、ALOHA协议和载波侦听多路访问(Carrier Sense Multiple Access,CSMA)等。然而防碰撞算法极大地受限于标签本身的弱计算能力和小内存,同时无源标签无法检测信道情况,所以CSMA在RFID防碰撞算法中无法使用。目前的防碰撞算法主要集中在基于分时的方式:树型[1]或者ALOHA算法[2]。
本文提出最大前缀查找树(Prefix Maximized Query Tree,PMQT)算法,根据修改的Park的标签估计算法,自适应选择最大查询前缀长度,同时引入曼彻斯特编码提高算法性能。因为有高效和高精确的估计算法,PMQT算法可以迅速地将大量标签划分成小组。同时,进一步利用曼彻斯特编码精确的检测冲突比特,从而达到自适应最大化查询前缀的目的。
2 背景介绍
在树型协议中,阅读器发出查询请求,标签基于ID进行响应。树型协议有多个变种,经典的轮询方案在标签数量太多的情况下有延时过大的问题。除此之外,标签的分布及ID的长度也极大地影响识别效率。例如传统的查找树(Query Tree,QT)算法虽然简单,但其最差时间复杂度很大[3]。
对于ALOHA协议,标签响应阅读器以随机时隙方式实现,不受标签分布和ID长度的限制。其也有很多变种[4],在这些协议族中,DFSA是理论研究和实际应用较多的防碰撞算法。然而系统效率有36.8%的理论上限[5],并且在标签数量未知的情况下,不能保证所有标签被识别。
在树型协议族中[6],随机前缀查找树(Prefix Randomized Query Tree,PRQT)算法系统效率可达42%,是目前最好的防碰撞协议之一。通过随机地选择查询前缀长度而非基于ID的逐位搜索方式,可以避免标签分布和ID长度的限制。然而,PRQT协议是根据预定义的优化参数表来选择前缀长度,其本身没有标签估计阶段,而标签数量在识别前一般是无法预知的,没有标签估计就无法确定查询前缀的长度,所以这种方法在实践中是不可行的。
3 PMQT算法
PMQT算法分为标签估计阶段和标签识别阶段。
标签估计阶段伪代码如下:


在标签估计阶段,在Park标签估计的基础上做了一点修改[7]。Park利用具有固定帧长Lest的帧时隙ALOHA协议,参数fd位掩膜方式控制响应标签的数量,直到冲突的概率Pcoll不大于阈值Pcoll_th。n代表准确的标签数量,nest代表估计标签的数量。通过解式(1),得到Pcoll_th所对应的阈值标签数nth:
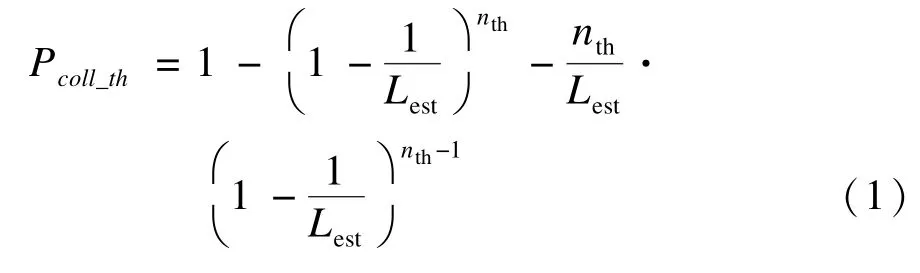
由位掩膜fd的控制反馈标签的数量,则第2次估计的标签数:,第3次估计的标签数:,同理,第i次估计标签数:,那么当满足下式时:
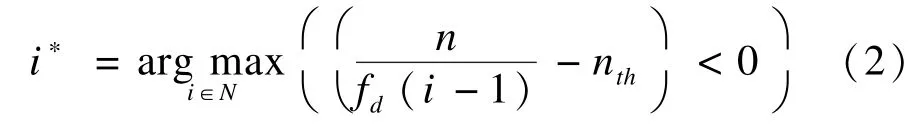
此时的i即为完成标签估计过程需要的总帧数i∗。N属于自然数集合,在帧,估计的标签数量为:
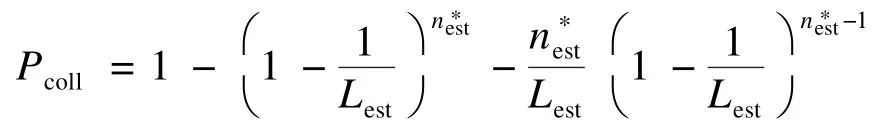

假设总共使用估计的帧数i∗=2时,总的标签数估计值nest为:
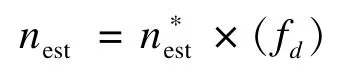
同理,假设总共使用估计的帧数i∗=3时,总的标签数估计值nest为:
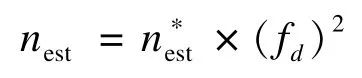
那么,当总共使用估计帧数为i∗时,总的标签数估计值nest即为式(3)。
这里,有:

其中,c0,c1,ck分别表示阅读器在前一帧测量得到空闲时隙数,可读时隙数和冲突时隙数;是有r个标签时的数学期望,其数学定义为:

区别于Park的方法,其nest仅与Pcoll=ck/Lest有关,而与c0和c1无关。而本文算法与这3个测量值〈c0,c1,ck〉均有关,这样估计值更精确。
曼彻斯特编码比特级的冲突检测能力已被广泛接受[9]。在标签识别阶段,采用曼彻斯特编码提高PRQT算法性能。利用曼彻斯特编码可以寻找精确的冲突位,使得自适应地查询前缀达到最大。
推导过程中所用公式参数及含义如表1所示。

表1 公式参数
最后,举例说明PMQT标签识别算法:假设有6个标签,分别为{1001,1010,1011,1100,1101, 1110},如表2所示。

表2 PMQT实例
4 系统效率分析
对PMQT算法,标签识别过程递归应用相同的原则,实际就是N-trees问题,其树节点数量就是识别完可查询区域内所有标签需要的时隙。
假设:标签ID服从均匀分布同时标签估计是精确的,可以达到理想状态,即估计的标签数量nest和实际的标签数量n相等,nest=n=L。
让Pk代表k个标签选择同一前缀的概率。Pk服从二项分布:
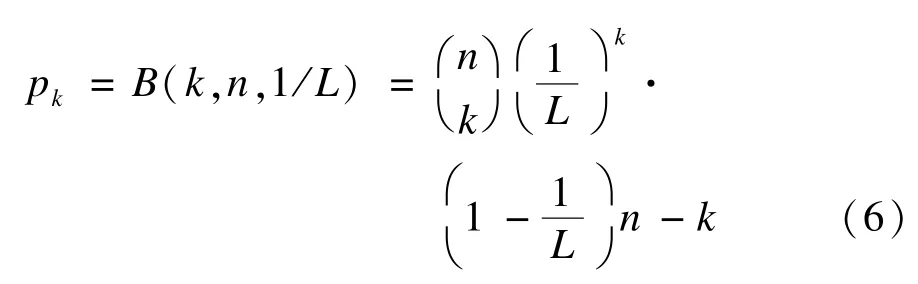
用t(n)代表识别n个标签平均需要的时隙(除根节点)。t(k)代表有k个标签的子树的大小。t(n)等于所有子树的和。



显然有t(0)=t(1)=1,t(2)≤3和t(3)≤6。
设K(n)=t(n)/n,那么系统效率定义为1/K(n)。因此有:

将式(8)代入式(9),得:

容易得到, ,所以有:

因此K(n)≤2,即系统效率1/K(n)至少高于50%,证明PMQT算法是目前较为高效的算法。
5 性能评估
在仿真中,设定Lest=128,Pcoll_th=0.9,fd=4。每一个仿真点代表1000次仿真的平均值,如表3所示。

表3 仿真参数取值情况
当测量的冲突概率变大时,Vogt标签估计算法估计结果将变得不准确[10]。如果在PMQT中直接使用Vogt估计算法,Vogt估计算法将失效。因为计算表明:当标签数大于847时,冲突的概率大于99%。首先测试标签估计算法的性能。标签数量由100~5 000变化,评估其精度与效率。图1表明,当标签数量小于200时,最大偏差达到39%,最大的平均偏差为9%,比单纯使用Park算法提高3%。Pcoll_th分别为70%,80%,90%。同时,仿真表明:当标签数为6 000时,只需3帧就可完成标签估计过程。

图1 标签估计结果
在图2中,比较了PMQT,QT,PRQT,其中,K= 64。QT算法和PRQT算法平均系统效率为36%和42%。仿真结果表明,PMQT系统效率在大多数情况下高于50%。在最差情况下,即标签估计误差过大时,PMQT退化成PRQT,例如A点。为了分析各种因素对PRQT算法的影响,比较了4种复合情况: PRQT与纯Park估计(P)、修改的估计算法(V)、曼彻斯特编码(M)组合,即PRQT+P,PRQT+V, PRQT+P+M,PRQT+V+M。曲线PRQT+V和PRQT+P表明,PRQT在修改的估计算法下比单纯的Park算法系统效率要好。曲线PRQT+V+M和PRQT+P+M表明,曼彻斯特编码能提高10%的系统效率。

图2 系统效率比较
作为一个鲁棒的防碰撞算法,标签估计有轻微偏差时,系统效率不应受太大影响[11]。图1中当冲突概率Pcoll_th分别为70%,80%和90%时,估计的结果受轻微影响。对于PMQT算法,系统效率的最大偏差为22%,最大平均偏差3%,均小于标签估计时的误差。这说明PMQT算法是鲁棒的。不同标签估计条件下系统效率比较如图3所示,K=64。

图3 不同标签估计条件下系统效率比较
6 结束语
本文提出一种射频识别系统PMQT协议,用于解决冲突问题,并研究标签估计的准确性和标签识别效率。理论分析和仿真结果表明,在标签数量从稀疏到密集的情景下,PMQT协议在平均和最坏情况下的时间复杂度两方面均优于PRQT协议。
在下一步工作中,将针对如何简化标签估计过程及标签估计的准确性进行深入研究,同时合理优化查询前缀的长度和阅读器与标签交换信息的长度,进一步提高系统的效率。
[1] ISO/IEC.ISO/IEC18000-6-2004Information Technology——RadioFrequencyIdentificationforItem Management-Part6:ParametersforAirInterface Communications at 860MHz to 960 MHz[S].2004.
[2] EPCglobal.EPCTMRadio-frequency Identity Protocols Class-1Generation-2 UHF RFID Protocol for Communications at 860 MHz-960 MHz[Z].2008.
[3] Law C,Lee K,Siu K.Efficient Memory Less Protocol for Tag Identification[C]//Proceedings of the 4th International Workshop on Discrete Algorithms and Methods for Mobile Computing and Communications. Boston,USA:[s.n.],2000:75-84.
[4] Wang Junyu,Li Bo.Efficient Anti-collision Algorithm Utilizing the Capture Effect for ISO18000-6C RFID Protocol[J].IEEECommunicationLetters,2011, 15(3):352-354.
[5] Shin W J,Kim J G.A Capture-aware Access Control Method for Enhanced RFID Anti-collision Performance[J].IEEE Communication Letters,2009,13(5): 354-356.
[6] Chiang K W,Hua Cunqing,Yum T P.Prefix-randomized Query-tree Protocol for RFID Systems[C]//Proceedings of IEEE International Conference on Communication. [S.l.]:IEEE Press,2006:1653-1657.
[7] Park J,Chung M Y,Lee T J.Identification of RFID Tags in Framed-slotted ALOHA with Robust Estimation and Binary Selection[J].IEEE Communication Letters, 2007,11(5):452-454.
[8] Vogt H.MultipleObjectIdentificationwithPassive RFID Tags[C]//Proceedings of International Conference on Man and Cybernetics.[S.l.]:IEEE Press, 2002:6-13.
[9] Yang Ching-Nung,He Jyun-Yan.An Effective16-bit Random number Aided Query Tree Algorithm for RFID Tag Anti-collision[J].IEEE Communication Letters, 2011,15(5):539-541.
[10] Park J,Lee T J.Error Resilient Estimation and Adaptive Binary Selection for Fast and Reliable Identification of RFIDTagsinError-proneChannel[J].IEEE Transactions on Mobile Computing,2011,11(6):1-28.
[11] Bonuccelli M A,Lonetti F,Martelli F.Tree Slotted ALOHA:A New Protocol for Tag Identification in RFID Networks[C]//ProceedingsofIEEEInternational Symposium onaWorldofWireless,Mobileand Multimedia.[S.l.]:IEEE Press,2006:603-608.
编辑 顾逸斐
Maximized Prefix Anti-collision Algorithm for RFID Based on Robust Estimation
WANG Yong1a,1b,TANG Xiaohu1b,ZHANG Lijuan1b,YANG Ruiqin2
(1a.School of Physical Science and Technology,1b.School of Information Science and Technology, Southwest Jiaotong University,Chengdu 610031,China;
2.Chengdu Sales Branch in Sichuan,China National Petroleum Corporation,Chengdu 610072,China)
In the research of Radio Frequency Identification(RFID)system,when the number of unknown tags is estimated by using the traditional ALOHA algorithm,the large number of tags and the smaller initial frame length will cause large error.Using the initial fixed length of the frame,reader changes the response method to achieve an accurate tag number estimation.This paper studies a robust tag estimation method and the Prefix Randomized Query Tree(PRQT) algorithm,and then proposes Prefix Maximized Query Tree(PMQT)tag anti-collision protocol.The theoretic analysis shows that the system efficiency is more than 50%.The simulation result demonstrates that PMQT outperforms PRQT by about18%~30%with respect to the system efficiency.In addition,PMQT algorithm has tolerance to the inaccuracy of tag estimation.
Radio Frequency Identification(RFID);tag identification;tag estimation;anti-collision algorithm; robustness;self-adaptive
王 勇,唐小虎,张莉涓,等.基于鲁棒估计的最大前缀RFID防碰撞算法[J].计算机工程,2015, 41(2):303-307.
英文引用格式:Wang Yong,Tang Xiaohu,Zhang Lijuan,et al.Maximized Prefix Anti-collision Algorithm for RFID Based on Robust Estimation[J].Computer Engineering,2015,41(2):303-307.
1000-3428(2015)02-0303-05
:A
:TN911
10.3969/j.issn.1000-3428.2015.02.058
中央高校基本科研业务费专项基金资助项目(SWJTU09BR246);四川省科技创新苗子工程基金资助项目(2010-016)。
王 勇(1974-),男,讲师,主研方向:射频识别,嵌入式系统;唐小虎,教授、博士生导师;张莉涓,博士研究生;杨瑞琴,工程师。
2013-12-30
:2014-04-09E-mail:wangyonga@swjtu.edu.cn
