基于划分和压缩数据库的改进Apriori算法
2015-01-04胡绿慧任玉兰何振林
胡绿慧,任玉兰,何振林
(成都中医药大学 医学信息工程学院,成都610075)
随着信息技术的发展,医学信息的迅猛增加,而人脑的储存和处理信息的能力又有一定的局限性,因此会对临床问题的思考、信息的判断、寻找解决问题的办法和制定临床治疗方案决策造成困扰。面对跨越千年的文献资料,如何快速、有效地挖掘有价值的信息,获取最佳证据以供临床治疗方案决策所用是目前面临的最大困难和亟待解决的问题。传统的文献研究方法或数理统计方法均无法解决古今针灸文献相关性和规律性问题,而计算机领域发展起来的数据挖掘可以解决这个难题。
数据挖掘是通过发现蕴藏在海量数据中的潜在知识而提高数据价值的技术。关联规则是数据挖掘中的一个主要分支,它主要是通过分析大量数据以挖掘数据之间的依赖关系[1]。其中Apriori算法是关联规则挖掘应用中最常使用的一个算法,但是Apriori算法也存在一些不足,特别是面对大规模数据时,其效率较低。本文针对Apriori算法的不足,提出了一种基于划分和压缩数据库方法的改进方法,通过改进可以将大规模数据集进行有效的划分和压缩,对子数据库进行关联规则挖掘,然后将结果合并。这种方法有效地改变了Apriori算法在面对大规模数据时效率较低的不足。
1 关联规则
1.1 关联规则描述
关联规则(Association Rule)是指从大量数据中发现项集之间有价值的联系,相关关系或因果结构,以及项集的频繁模式。关联规则的目地是找出大量数据中隐藏的关联网,展示属性值频繁地在给定数据集中一起出现的模式[1-3]。
关联规则挖掘有两个步骤:
(1)找出所有频繁项集。根据最小支持度找出数据集D中所有不同长度的、满足用户给定最小支持度的频繁项集。
(2)由频繁项集产生强关联规则,产生的规则必须满足最小支持度和最小置信度。
通过关联规则算法挖掘出属性值的结合模式,结合相关的专业领域知识,可以更有效地挖掘出数据集中隐藏的可利用价值。常用的关联规则挖掘算法主要有 Apriori算法,F-P算法[3]以及Eclat算法。
1.2 Apriori算法描述
Apriori算法是一种使用频繁集的先验知识从而生成关联规则的一种算法,是最有影响的关联规则挖掘算法,采用了逐层搜索的迭代方法寻找频繁项集[2]。即扫描一次事务数据库,找出频繁1-项集的集合L1,基于L1来寻找所有可能的候选2-项集的集合L2,类似上一步,L2用于寻找L3,如此循环,直到不能找到频繁项集。Apriori算法,在寻找频繁项集时是由连接和裁剪这两个步骤构成的。Apriori算法的主要解决步骤如下:
(1)扫描事务数据库。扫描事务数据库D产生频繁一项集L1。
(2)连接。在k(k>1)次扫描事务数据库时,采用递推的连接方法求Lk,通过Lk-1与自己连接产生候选k项集的集合Ck。
(3)裁剪。设Ck∈Lk,即Ck是的超集。根据Apriori任何非频繁的(k-1)项集都不可能是频繁k项集的子集这一性质,如果满足Ck-1∉Lk-1,则该候选项集也不是频繁的,即Ck∉Lk,从而候选k项集Ck可以从候选k项集的Ck中删除。
(4)产生强关联规则。根据所设定的最小置信度min-con遍历整个频繁项集,得出强关联规则,算法结束。
1.3 Apriori算法分析
Apriori算法虽然可以实现在海量数据中挖掘其关联规则,但算法在执行速度和效率上具有一定的局限性,主要表现在:在生成频繁k-项集的过程中,需对事务数据库进行多次扫描。候选集的大小决定了扫描事务数据库的次数,假如候选k-项集Ck的大小为|Ck|,则需要扫描|Ck|次数据库,这就大大增加了I/O负载,也大大降低了Apriori算法的执行效率。
目前,很多文献提出了对Apriori算法的改进[4-8],如基于把 Apriori算法与FP-Tree的结构结合,提出的增量式Apriori算法。
2 改进的Apriori算法
2.1 算法改进的思想
基于Apriori算法在处理大数据集时的不足,结合针灸数据处理特定需求,设计了一个基于划分数据库技术的改进算法。该算法的基本思想:针灸数据表是由(0,1)表示某穴位是否出现在某个案例治疗方案中,所以存在很大一部分治疗案例方案不包含某些穴位,由此引起的数据冗余影响了数据处理的效率。首先依据穴位出现的频率将穴位按照升序存储在临时数组A[N]中;然后按照穴位出现的频率将原始事务数据库D分为几个互不相交的事务数据库,使得子数据库能够容纳在内存中;最后根据每个子数据库计算出的频繁项集计算整个数据库的频繁项集。
2.2 算法描述
数据库划分是指依据各个列属性值把事务数据库中的所有项分成若干份,然后对每个单独的部分生成频繁项集。从数据库中计算出候选频繁项的实际支持度,确定最后的频繁项集。算法的主要依据是把数据库分为若干份,整个数据库上的频繁项集至少在数据库的一个分段上是频繁的;其次,每个分段上的频繁项集的并集就是整个数据库上潜在的频繁项集的集合。因此,基于数据库的划分对Apriori算法的改进可以描述为:
(1)计算每个穴位属性中为1的项的个数,按升序排序于数组A[N]中(i=0);
(2)根据数据库中A[i]是否为1,将数据库D分为两个部分Di,D;
(3)新的数据库D中,A[i]列的属性值都为0,删除该列,i++,返回到步骤(2);
(4)分别对Di求频繁项集,加到候选频繁项集中;
(5)在原始数据库中,计算每个候选频繁项集的支持度,判断是否满足最小阈值,确定最后的频繁项集。
算法伪代码:

为了说明和验证算法的正确性,表1为从原始数据库中提取的部分数据进行划分和压缩之后形成的一个数据库模型,通过计算配伍规律的支持度和置信度来验证这种改进方法的有效性。
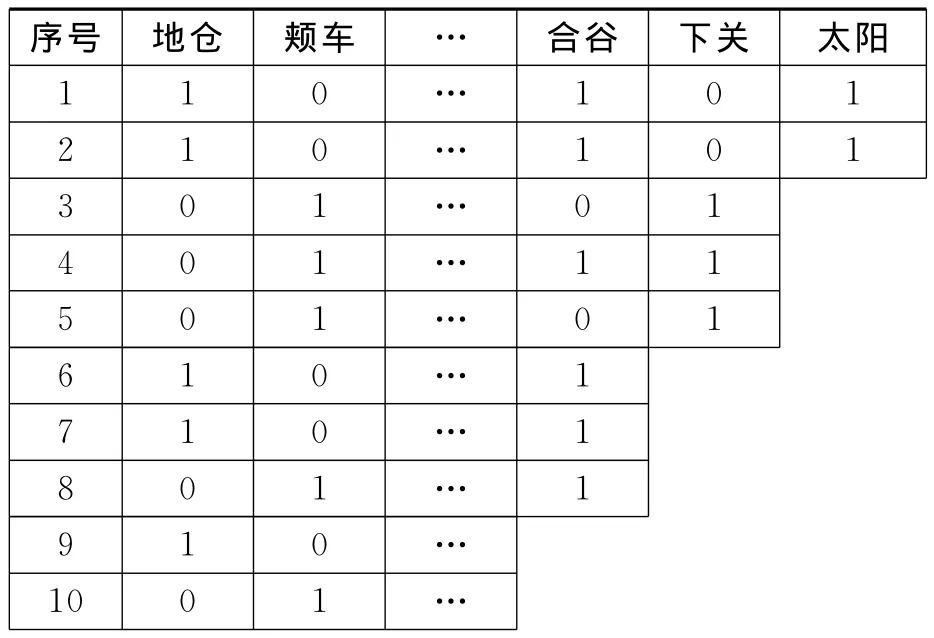
表1 数据库划分模型Table 1 The database partition model
由表1可知,原始数据库依据列属性值划分形成若干子数据库,子数据库的最后一列都为1,通过直接删除数据冗余部分,实现了对子数据库的进一步压缩,使得最后形成若干大小合适、数据冗余度低的子数据库。
例如在表1中,所有与太阳穴正相关的穴位是通过前2条案例数据由关联规则挖掘出来,而与下关穴正相关的穴位是通过前2条数据中挖掘出的配伍规律与之后的3条案例数据挖掘出来的配伍规律加权得到;配伍规律之间的加权值由案例条数所占的比例得到。
例:表1中的13条案例数据中的用穴频率见表2,在计算频繁2-项集时,只需要统计子数据库中A与B同时出现的次数。

表2 划分模型中的用穴频次Table 2 Acupoint frequency in the database partition model
通过表1中的数据可知,案例总数D为13,地仓与太阳穴一起出现的频次是2,地仓与下关一起出现的频次是0,地仓与合谷一起出现的频次是2,根据以下公式即可得到表3的结果。
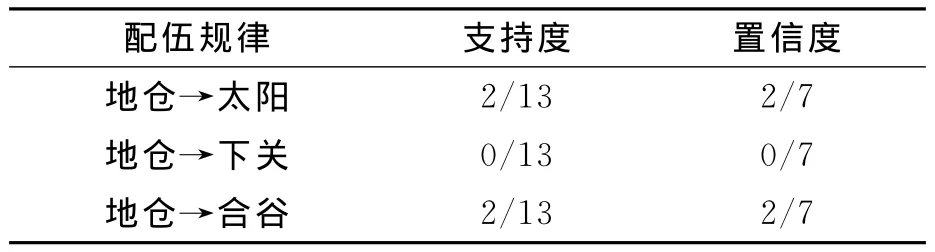
表3 频繁2-项集计算结果Table 3 Results of 2sets of frequent
通过划分数据库计算出的结果与原始的计算方法结果相同,算法改进后,将大数据集划分和压缩为若干个小的子数据库,一方面删除了很多冗余的数据,减少了计算开销;另一方面,可以将数据并发处理。
3 实例分析
将以上算法应用在临床针灸治疗贝尔面瘫用穴规律[9]研究中,数据以针灸疗法治疗贝尔面瘫1 400条医案为例进行数据挖掘。
3.1 数据预处理
收集到的原始病案数据存在有噪声、有缺省、格式不一致等情况,甚至有些病案只有寥寥数语,这在一定程度上加大了数据挖掘的难度。数据挖掘中对数据的规范化、标准化、结构化要求很高,数据的预处理将直接关系到挖掘的结果精确度[5]。数据经过数据集成、数据规约、数据清理、数据变换等预处理之后得到表4所列的格式的数据。
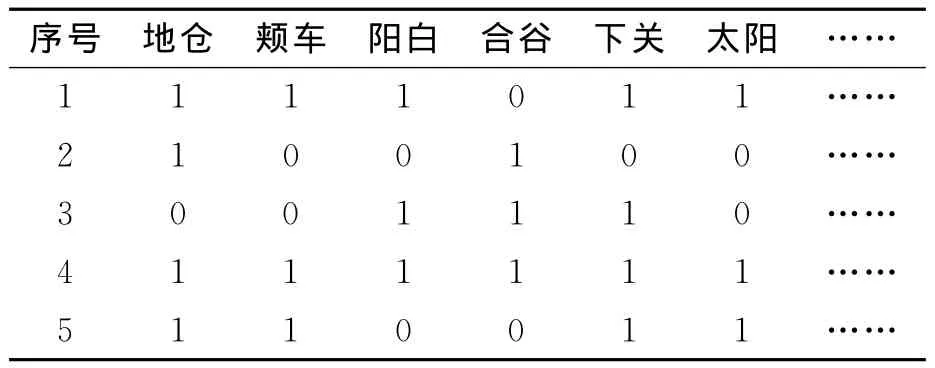
表4 数据格式表Table 4 Data format chart
3.2 结果分析
通过使用关联规则挖掘结果并结合针灸专业知识进行分析,发现针灸治疗面瘫地仓、颊车两穴使用频次最高,疗效最好。其他具体穴位使用频次见表5。针灸治疗面瘫腧穴配伍规律中,颊车与地仓两穴配伍使用最多,它们的支持度和置信度都达到最高。具体配伍、置信度见表6。
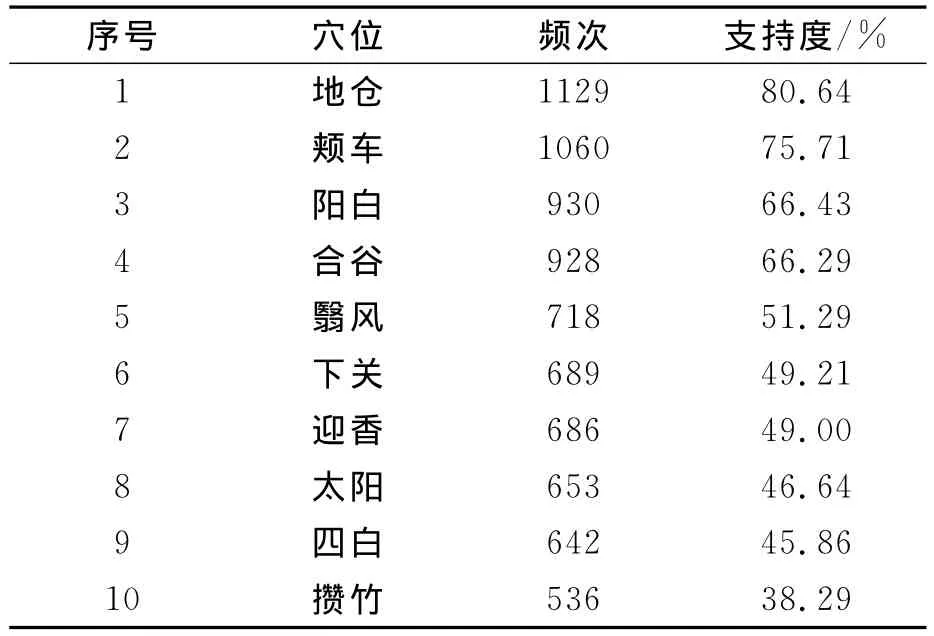
表5 针灸治疗贝尔面瘫腧穴规律分析表Table 5 Analysis of the acupuncture points regularity for curing Baer facial paralysis
对几条关联规则从针灸学角度来解释:针灸治疗贝尔面瘫中经络腧穴的应用具有明显的规律特征,表现为:(1)从腧穴使用频次分析来看,重视局部取穴,地仓、颊车、阳白、合谷、翳风等面部穴位的应用,体现了“腧穴所在,主治所在”的治疗规律;(2)对经脉的选择中,体现了对病因辨证治疗的原则,特别重视翳风、合谷、风池等穴位的应用。通过对所挖掘出的关联规则的分析结果,可以得出循经取穴是针灸治疗的重要原则,特定穴的运用是针灸处方的主要部分,符合针灸理论与临床实践,该方法有助于针灸临床决策。
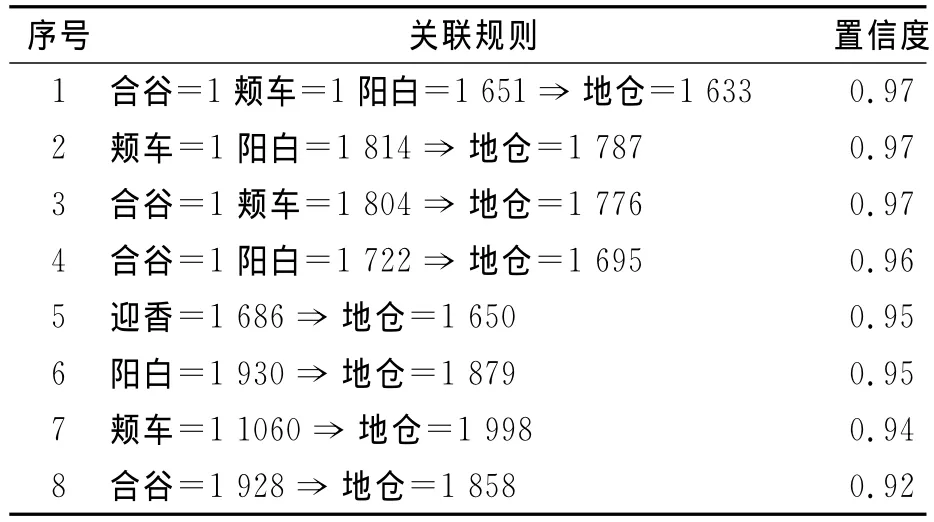
表6 针灸治疗贝尔面瘫腧穴配伍规律分析表Table 6 Analysis of the acupuncture acupoints compatibility regularity for curing Baer facial paralysis
4 结论
本文分析了关联规则挖掘算法,将属性划分和数据库压缩理论引入到经典Apriori算法的改进工作中,很好地解决了大规模数据在处理上的效率问题,有效地解决了数据冗余。实验验证该方法在数据挖掘中有效提高了运行时间复杂度、空间复杂度。在解决实际问题中,取得了很好的效果。
[1]Agrawal R,Mannila H,Srikant R,etal.Fast discovery of association rules[C]//Advances in Knowledge Discovery and Data Mining.Menlo Park:AAAI/MIT Press,1996:307-328.
[2]Han J W,Pei J,Yin Y.Mining frequent patterns,without candidate generation[J].Data Mining and Knowledge Discovery,2004(8):53-87.
[3]Zhang P,Tong Y H,Tang S W,etal.An effective method for frivacy preserving association rule mining[J].Journal of Software,2006,17(8):1764-1774.
[4]Savasere A,Omiecinski E,Navathe S.An efficient algorithm for mining association rules in large databases[C]//Proceedings of the 21st VLDB Conference.Burlington: Morgan Kaufmann Publishers,1995:432-443.
[5]关心,李广原.一种多约束关联挖掘算法[J].计算机应用研究,2012,29(4):1294-1296.Guan X,Li G Y.Efficent algorithm for mining association rules with multiple constraints[J].Application Research of Computers,2012,29(4):1294-1296.(In Chinese)
[6]苗苗苗,王玉英.基于矩阵压缩的Apriori算法改进的研究[J].计算机工程与应用,2013,49(1):159-162.Miao M M,Wang Y Y.Research on improvement of Apriori algorithm based on matrix compression[J].Computer Engineering and Applications,2014,49(1):159-162.(In Chinese)
[7]崔旭,刘小丽.基于粗糙集的改进Apriori算法研究[J].计算机仿真,2013,30(1):329-332.Cui X,Liu X L.Improved Apriori algorithm based on rough set[J].Computer Simulation,2013,30(1):329-332.(In Chinese)
[8]肖光磊,陆建峰,李文林,等.正相关关联规则及其在中医药中的应用[J].计算机工程与应用,2010,46(6):227-230.Xiao G L,Lu J F,Li W L,etal.Positively correlated association rules and its application in traditional Chinese medicine[J].Computer Engineering and Applications,2010,46(6):227-230.(In Chinese)
[9]杨洁,任玉兰,吴曦,等.基于数据挖掘技术的针灸治疗贝尔面瘫RCT文献的用穴规律分析[J].中华中医药杂志,2010,25(3):348-351.Yang J,Ren Y L,Wu X,etal.Data mining-based analysis on rules of acupoints selection in RCT literature of acupuncture treatment of Bell palsy[J].CJTCMP,2010,25(3):348-351.(In Chinese)
