一种针对不完全观测数据的消费者聚类方法
2015-01-01吕晓玲
吕晓玲
(中国人民大学a.应用统计学科研究中心;b.统计学院,北京100872)
一、引 言
一直以来,消费者聚类都是统计学和市场营销学非常热门的研究课题[1-2]。通常利用人口信息、社会学信息、心理学信息、产品使用信息和偏好以及消费者之前的行为将消费者进行聚类。在电视行业,Kim利用电视节目收看信息,提出了一个三步市场分类步骤[3]。Vyncke利用他们设计的问卷实施了聚类分析,问卷内容涉及收看模式和个人特征,在分析不同市场的不同生活方式类型的表现时,利用了Ward’s等级聚类法和非等级聚类法[4]。通过调查随机抽取的1 600个样本,Hara等人通过同质分析与聚类分析相结合的方案对受访者聚类[5]。近年来,随着数据量的增大,带有变量选择功能的聚类方法也被深入研究[6-7]。
现有研究仅聚焦在寻找有意义和代表性的类别和生活方式上。在聚类过程中,需要知道个人行为的全部信息,因此结果只能对调查样本有效,除非进行大规模的调查,才可以应用结论预测新的样本所属的类别,但是从公司的角度出发,不仅需要大量的资源,而且不具有可操作性。如何仅依赖人口统计变量进行类别预测是长期以来困扰着市场研究人员的问题。对于一个城市或国家没有入样的消费者,他们的个人和家庭特征的详细信息很容易从人口普查数据中获得,如果有一种方法,它只依靠人口统计变量,并且可以将未入选样本的个体分配到由样本个体得到的行为方式分类中去,数据不完全的问题就可以得到解决。本文提出三阶段聚类方法,解决该问题并应用于香港电视观众数据分析。
二、三阶段聚类方法
第一阶段:普通聚类分析。即随机抽取一个样本并收集其详细信息,如人口统计变量、社会经济状态、心理状态、购买行为等,并应用聚类算法将全部样本单元分成若干具有某种共性的群体,实际数据分析使用的是K-means聚类方法。
第二阶段:使用人口统计变量建立分类函数。第一阶段的方法可以成功得到对市场营销有意义的行为集群,但由于样本分类是以完备的样本购买行为信息为基础,所以这些发现和应用只能在有全部行为记录的样本中实施,数据要求限制了模型在所有人群中的应用。为了能预测某个未入样的个体属于哪个类别,我们假设对于很多产品和服务来说,第一阶段得到的行为集群与他们的生活方式有关,而生活方式仅基于人口统计特征。这样可以建立因变量是第一阶段聚类结果的类别标签,自变量仅为人口统计变量的多分类模型,从而将人群中未入样个体(没有行为变量的数据)分配到第一阶段得到的行为集群中去。需要强调的是,行为集群与人口统计特征的相关程度依赖于产品或服务的特点,所以检查此方法是否适用于某个特殊的产品或服务非常重要。
本文使用的是SVM方法来建立分类模型,因为它是不规则的和高维数据集分类的一种有效算法,并且在很多领域的研究中得到了成功的应用[8]。
第三阶段:完善和改进。第二阶段的分类函数可以将未入样的个体分到行为集群内,每个类别的分类正确率依赖于其自身的行为特点有所不同。为了进一步提高正确率,需要通过细致检验错分的个体并且识别其错分原因。大多数错误分类的个体都是因为在分类过程中没使用任何行为数据,因此在本阶段利用logistic回归模型寻找到少数几个对错分改进最大的行为变量,并且要求这几个行为变量在新的消费者之中是很容易通过调查收集得到,从而期望应用模型可以预测新的样本类别,并具有较高的预测准确性。
三、实证应用
(一)数据来源和变量选择
本文使用的数据是香港2004年7月19日到2005年7月24日之间的收视仪数据。该数据记录了2 143个香港电视观众的人口统计特征,以及以分钟为单位的收视情况。针对本文的研究,整理出三个数据集:第一是观众个人信息,如性别、年龄和学历。第二是香港主要的四个频道(TVBJ,ATVH,TVBP和 ATVW,分别编码为1,2,3,4)的不同节目时间表。将节目类别分为如下10类:电视剧、新闻、娱乐、音乐、电影、评论、旅行、运动、幼儿和其它。根据这些分类,数据集提供了准确的播放时间和每个类别在以上四个频道的播放时段。第三是每个样本的收看行为,包含开始看电视的时间、收看频道和结束收看的时间。
建立和选择分析变量,包含的步骤为:第一步,在第一个数据集中挑选了12个描述个人特征的变量,分别为:是否为一家之主、是否是购物决策者、工作类别、性别、年龄、学历、家庭的社会地位、婚姻状况、是否为成人、家庭月收入、个人月收入和工作职位。第二步,利用第二个数据集中电视节目安排的信息,将第三个数据集中关于个人收看信息的数据转换为收看行为变量,得到40个关于4个频道10个节目类型的新变量,它们是这4个频道提供并且在一年内被人们收看的10个节目类型的时间。例如,变量Drama1代表一年内收看TVBJ电视剧的总时间,News3代表收看TVBP新闻节目的总时间。另外,将一天分成96个部分,每部分15分钟,对于每个15分钟窗口,计算出每个人全年花费在每个频道上的总时间。另一组变量被定义为CountX,其中X代表频道编码,它代表一年中,每个个体一天中至少连续观看特定频道20分钟的天数,由此得到针对4个频道的4个数值型变量。变量Loyalty测量观众对TVBJ的忠诚度。由于TVBJ是本次研究的合作电视台,我们对影响观众对TVBJ忠诚度的主要因素非常感兴趣。Loyalty是一个二元变量,如果个体全年观看TVBJ超过7 200分钟(每月10小时),则被定义为1,否则为0。另一组变量关于收看总时间,如tvb_morning和tvb_evening分别代表上午(上午6点到中午12点)收看TVBJ频道的总分钟数和下午(下午4点到晚上8点)收看TVBJ频道的总分钟数。由于晚黄金时段电视收视率对于电视台来说非常重要,在此定义两个新变量Suma_day和sumb_day,分别代表观众一年中在晚上7:30到8:30和晚上8:30到9:30收看TVBJ超过30分钟的总天数。
由于收看变量非常多,为了后续的聚类分析,需要筛选出重要变量。为此,将那些与变量Loyalty相关系数大于0.35的变量保留下来。用该方法识别了62个与TVBJ观众观看模式相关的变量。
简单的描述统计显示,在2 143个样本成员中,30~39岁的观众占51%;53%的观众至少接受过中等教育;已婚和未婚观众分别占51%和42%,其余的观众为丧偶或离异;个人月收入多在10 000港币以下;22%为蓝领,例如店员或服务人员;22%为学生,超过16%的为家庭主妇,只有2%的观众为失业;至于观看的电视节目类型,前三位最喜欢的类型为电视剧、新闻和娱乐节目;观众每天平均收看时间分别为1小时、23分钟和12分钟;至于电视频道,TVBJ是最喜爱的频道。相对于英文频道,大多数观众更偏爱中文频道。另外,在收看英文频道的观众中,他们更倾向于收看TVBP。
(二)三阶段聚类
1.第一阶段:根据收看模式进行样本聚类。
个体日常收看电视的行为反映了其每天事项的安排和协调。承载了家庭信息的个人性格特征必然对个人看电视的模式具有显著的影响,比如活跃频率和时段,频道选择等,这些变量相互作用,并且共同构成了具有独特行为特征的群。这个阶段采用K-means聚类方法将个体分类。聚类分析中,决定适当的类别数量非常重要。设定太少的类别,由于群过大,难以识别重要的变量;设定太多的类别,将会形成很多难以定义的小群。基于“尽量多的类别,但没有小于5%样本量的类”原则,设定类数为6。通过K-means聚类分析,得到6个类,基于每个类所选变量的均值,可以对各个群的特征进行解释。
群1:较少看电视的年轻员工。该群的群体数量占所有样本比例为34.4%。从聚类的中心可以发现,这个群的成员是相对年轻的员工,大多数(76.2%)的年龄在15~44岁;婚姻状况方面,60%已婚,33.8%为单身。群内的每个成员都有工作,超过80%的为经理、专家和店员,大多数人(72.3%)的月收入在10 000港币到20 000港币。这个群内的成员收看电视的时间最少,大多数经常在夜晚看,每天收看TVBJ电视剧的平均时间为22分钟,仅为收看时间最多群体的五分之一。这种情况同样发生在娱乐节目上。相对来说,该群体对新闻节目更加感兴趣,收看时间在所有群中不是最低的,各个频道的评论节目、电影和音乐节目也有相似情况。另外,该群成员平均每天收看电视的时间小于2小时(1.9小时)。
群2:对看电视不太感兴趣的中年家庭主妇。该群成员占总数据集的11.5%,该群中的所有个体都是女性,且中年女性占绝对主导。群的绝大多数都是家庭主妇(80.2%)且已婚(87.5%),95.1%年龄大于30岁。该群体月收入大多数(98.4%)低于5 000港币,83%不是家庭的一家之主和家庭购买决策者。群内的成员对看电视、电视剧、音乐节目和体育节目表现出了较少的兴趣,对新闻和儿童节目比较感兴趣。他们每天收看电视的平均时间为将近3小时(2.9小时)。
群3:较少看电视的学生。该群体占比为19.9%,主要由年轻的学生构成,其中一半年龄小于15岁,另一半年龄在15~29岁之间。他们中几乎没有一家之主(0.7%)或者家庭购买的决策者(2.1%)。83.8%为学生,超过四分之三的人(78.4%)接受过中等或以下水平的教育,大多数(98.6%)是单身。群里的成员看电视的时间是最少的,每天平均花1.8个小时看电视,该群体最喜欢的是儿童节目。
群4:经常看电视的人。群的数量占所有数据的13.0%。这个群的构成很复杂,有年轻人、老人、男性、女性、学生、管理者,家庭主妇和其他的人,有已婚的,有单身或者离异的,但该群体共同的特征是都是经常看电视。他们看不同的节目类型及不同频道的时间是六个群里最多的,平均每天6.3个小时看电视,其中2.2个小时看电视剧,0.8个小时看新闻。大约四分之三(73.8%)是女性,41.2%是家庭主妇,41.2%是学生。
群5:高级退休人士对新闻和ATVH感兴趣。这个群的数量占所有调查对象的7%。91.3%是男性,且大部分年龄超过59岁(83.2%)。由于81.9%是退休的,94.0%是没有工作,因此个人月收入低于5 000港币(83.9%)。此外,虽然有86.6%是一家之主,但82.6%并不是购买决策的制定者。与其他的五个群相比,该群大部分对新闻和ATVH感兴趣,平均每天看ATVH超过30分钟,平均每天看新闻的时间是0.8小时,是六个群里最高的。
群6:成人员工对看电视更感兴趣。这个群的数量占所有调查者的14.2%。对比群1,这个群的年纪更大,接近90%的成员年龄超过30岁,大部分都是已婚(72.1%)。少于四分之一的人接受过中等以上的教育。群里所有的成员都有工作,他们是经理、公司职员或企业经营者,大部分收入在10 000~20 000港币之间(78.7%),12.8%的成员每月收入超过20 000。虽然群1和群6大部分是成人员工,但这个群的成员对看电视更感兴趣,每天花1.4个小时看电视剧,花费的时间约是第一个群的三倍。他们也喜欢看新闻,每天花费1.5小时看新闻,纵观整年,平均每天看电视4.4个小时。
六个群代表了香港电视观众不同的观看行为和生活方式,电视台可以考虑发展设计专门的营销策略来针对不同观众群。由于未入样个体的收看行为不可知,本文将利用SVM方法建立仅依赖人口统计特征的分类模型,从而可以将未入样个体分配到已知行为集群内。
2.第二阶段:仅利用人口统计变量分类。
将上一阶段利用K-means聚类法得到的聚类结果作为类别变量,仅利用数据集中个人特征的变量作为解释变量建立一个支持向量机(SVM)分类模型。对于多分类问题,建立6个的二分类SVM模型,模型的预测准确率为80.7%。利用神经网络、决策树和多项Logit模型分析,准确率分别是73.1%,71.5%和64.8%,因此,在本案例中 SVM模型是最优的一个。SVM仅利用人口统计变量,可将样本分到6个类别,并且正确率为80.7%。这个发现的意义是,电视台不需要实施调查收集每个观众的收视行为信息,仅根据SVM建立的模型,利用人口统计变量,可将市民分类,之后就可在不同的群中实施相应的市场营销策略。
研究错误分类的来源仍然很重要。表1展现了基于全部变量的K-means均值聚类的结果(已知类别),和基于人口统计变量的SVM方法的分类结果(预测分类)。仔细观察表1可以看出,有两个主要的错误分类的来源:一是,本应在群4的个体被错误分到了其他群,如群2、群3和群5。二是,本应属于群1的个体被错误分到了群6。进一步考察可以看出,这些错分个体的个人特征和错误群中的成员非常相似。比如,应在群4(经常看电视的人)但被错误分到了群2的个体与群2成员有相近的个体特征,均拥有较高的学历,年龄也相对更大。再如,本属于群6而被错误分到群1的成员,群6和群1成员的个人特征非常相似,都仅由员工组成,并且相对年轻。
以上结果揭示了方法的一个结构性缺点,即由于SVM方法仅利用了人口统计变量,能将看电视行为与生活方式、社会经济地位有紧密联系的个体准确分类,但当个体拥有相似的社会经济地位,看电视模式却有很大差异时,模型中没有行为变量,SVM就不能准确分辨了。下面进一步改进操作,以此来提高SVM方法的分类效果。
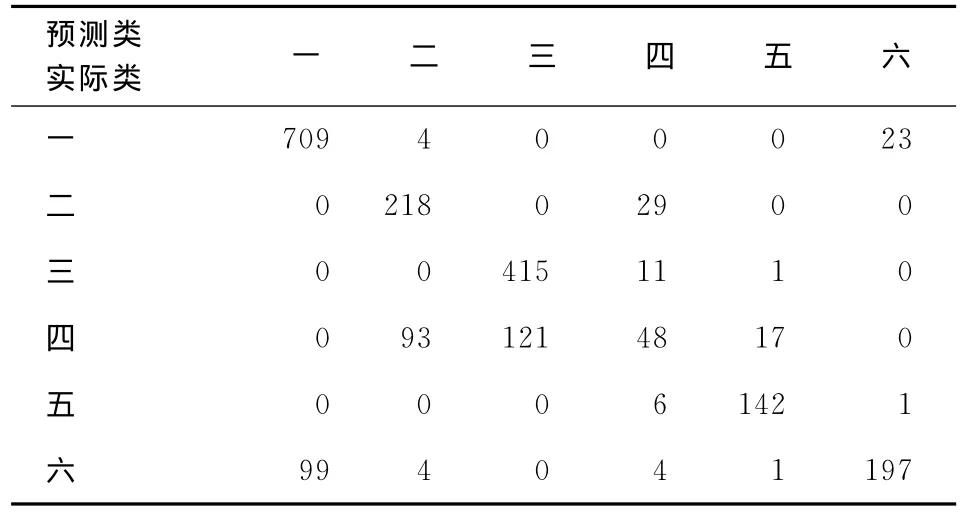
表1 基于SVM的分类结果与K-means聚类结果的对比表
3.第三阶段:利用logistic回归对模型改进。
尽管SVM方法可以产生6个分类,并且正确率达到80.7%,但从对表1的分析可以看出,错误分类的来源是缺乏观看行为信息,如加入收看行为的信息,分类正确率可以进一步提高。在此考虑识别一个与正确分类高度相关的变量,然后利用其将一些个体重新分类。
为了识别重要行为变量,针对每个SVM得到的群选择一个行为变量建立logistic回归模型。如,SVM将808个个体归入了群1,其中99个个体本应该属于群6,logistic回归模型的目的是为了预测一个个体属于群6的可能性。在此利用向前筛选法选择最适合的行为变量,结果是变量sumb_day入选,即代表“一年里,个体在晚8:30到9:30收看TVBJ频道超过30分钟的天数”选入,模型为:
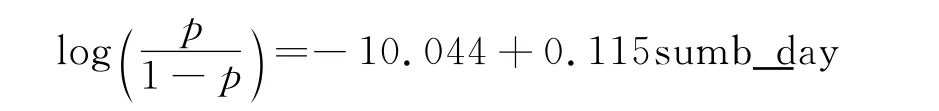
其中p代表一个本属于群6的个体被SVM方法错分到群1的概率。对于群1来说,如果上述logistic回归模型预测某个体不应该属于群1,进一步利用人口统计变量来确定该个体的正确所属群。新的分类正确率为96.5%。
其他群内同样出现了类似的结果。有趣的是,所有群的最有影响力的变量都是sumb_day。值得注意的是,这并不是第三阶段必然出现的结果,每个群都可以有他自己的行为变量,新的分类正确率在93%以上。
尽管上述logistic回归模型可以成功地将SVM得到的6个群内的个体重新分类,但是行为变量sumb_day在调查中很难被获得。如欲将阶段3在全部人群中应用,必需进行调查得到这个重要变量的信息,显然,让个体回想其一年内在晚8:30到9:30收看TVBJ频道超过30分钟的天数几乎不可能。在此,利用相似的新变量来替代,即TVday,代表“一周内,个体在晚8:30到9:30收看电视超过30分钟的天数”,这个数据可以通过电话访问轻松的获得。为了验证新变量的预测作用,利用样本中2 143人的收视仪记录,为每个个体计算了一个TVday的值,再建立并估计logistic回归模型。结果表明,这个简单的行为变量TVday的效果和原有变量sumb_day有同样的效果。
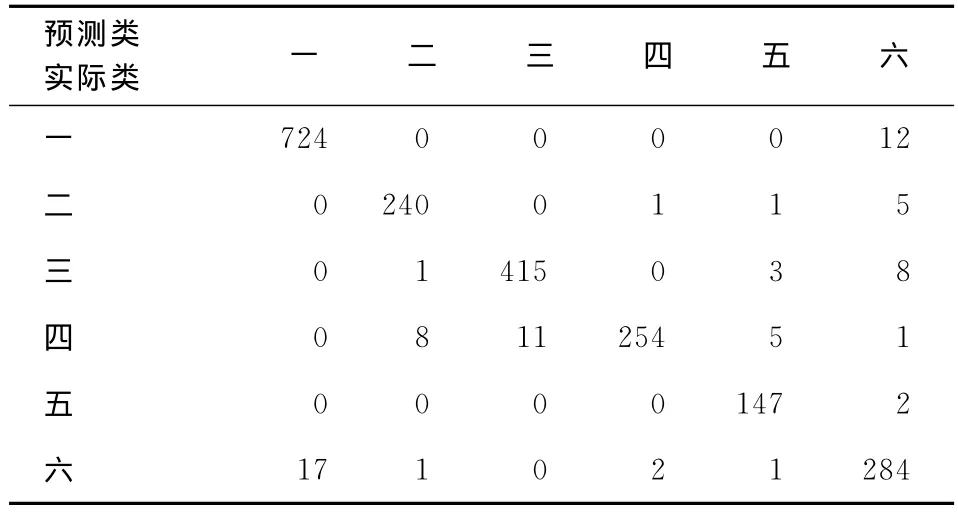
表2 使用SVMLR模型的分类结果表
表2给出了利用SVM和logistic回归方法(SVMLR)的结果。首先利用SVM对其所属群进行预测,再利用logistic回归重新分类。显然,将SVM方法和logistic回归模型结合起来,可以提高预测的稳健性,本例中,分类正确率为96.3%。当然,企业需要收集这个附加的重要变量,可通过提问诸如“在一周的时间里,平均您有多少天在晚8:30和9:30收看电视超过30分钟?”来实现。
四、总 结
对于任何大型商业组织的市场部门,将消费者进行聚类都是加强消费者关系管理的基本步骤,但对不利用行为信息,将未入样个体归入群内的方法较少。本文与现有聚类研究的最大不同和创新是:针对电视行业,对如何在不利用行为模式,或者是选择非常少的行为变量,建立一个可靠的分类函数进行了首次尝试。实际数据分析表明,本文所用方法可以非常有效地将不完全数据的样本进行类别预测。当然,本文所用的方法有待在更多的数据集上进行验证。
[1] Bassi F.Latent Class Factor Models for Market Segmentation:an Application to Pharmaceuticals [J].Statistical Methods and Applications,2007(16).
[2] 谢邦彦,石洋.第三领域保险的高风险客户甄别研究[J].统计与信息论坛,2009(8).
[3] Kim C R.Identifying Viewer Segments for Television Programs[J].Journal of Advertising Research,2002(1).
[4] Vyncke P.Lifestyle Segmentation:from Attitudes,Interests,and Opionions,to Values,Aesthetic Styles,Life Visions and Media Preferences[J].European Journal of Communication,2002(4).
[5] Hara Y,Tomomune Y,Shigemori M.Categorization of Japanese TV Viewers Based on Program Genres They Watch[J].User Modeling and User-Adapted Interactions,2004(1).
[6] Pan W,Shen X.Penalized Model-based Clustering with Application to Variable Selection[J].The Journal of Machine Learning Research,2007(5).
[7] Witten D,Tibshirani R A.Framework for Feature Selection in Clustering [J].Journal of American Statistical Association,2010(490).
[8] Cortes C,Vapnik V.Support-Vector Networks[J].Machine Learning,1995(3).
