一种基于领域优化的集成交叉覆盖神经网络
2014-12-31李晓丽
孙 冰, 李晓丽
(南京工业大学 电子与信息工程学院,江苏 南京 210009)
神经网络伴随着其理论和技术的不断发展,已成功应用于模式识别、函数逼近、智能控制、数据挖掘及知识发现等多个领域。在实际运用中,泛化能力即为神经网络识别训练数据集之外样本的能力,被认为是衡量神经网络性能的最重要指标,因此,如何有效地提高其能力已成为最受关注的问题之一。
神经网络集成[1-3]是用有限个神经网络学习同一个问题,集成在某个输入示例下的输出由构成集成的各神经网络在该示例下的输出共同决定。集成的构建通常包括2个步骤,首先是利用基分类器训练出多个版本,然后将这些分类器进行结合。文献[4-5]提出的Boosting算法已经证明了集成学习能有效地提高学习系统的泛化能力。本文采用集成的交叉覆盖神经网络,通过在集成过程中加入覆盖领域优化算法(coverage areas optimization algorithm,简称CAOA)以降低集成系统的泛化误差,从而进一步提高集成系统的识别效果。
1 交叉覆盖算法的基本思想
覆盖算法是基于MP神经元模型[6]的几何意义所给出的一种神经网络分类器的设计方法。覆盖算法的基本思想是假定训练样本或待识别样本为n维向量,构造型神经网络将所有的训练样本投影变换到n+1维的超球面上,从而模式识别问题被转化为在n+1维的超球面上的覆盖问题。通过在超球面上寻找可以对训练样本集进行正确分类的较优覆盖,实现对样本空间的划分,并根据得到的覆盖判断待识别样本的类别[7]。
设给定一输入集K={x1,x2,…,xk}(K是n维欧式空间的点集),设K分为s个子集,K1={x1,x2,…,xm(1)},…,Ks={xm(x-1)+1,…,xk}。用一个3层网络N构造分类器,即等价于求出一组领域,这组领域将不同类的点分隔开,使属于Ki点的输出均为yi=(0,…,1,0,…,0),即其第i个分量为1,其余分量为0的向量,i=1,2,…,s[8]。
交叉覆盖的思想实际上是用领域进行交替覆盖,具体训练算法步骤如下:
(1)任取一个第i类尚未被覆盖的点ai。
(2)判断训练集中是否存在与ai异类的样本点,若存在则计算与ai最近的异类样本点到ai的距离d1;若不存在异类样本点,直接转入步骤(3)。
(3)找出训练集中离ai最远且距离小于d1的同类点c,两者距离为d2;当没有异类点时,d1和d2都取最大距离。
(4)覆盖领域的半径r=(d1+d2)/2。
(5)构造以ai为中心,阈值为r的覆盖领域C(ai),找出所有属于C(ai)的样本,并从训练样本中删除被此领域覆盖的样本。
(6)判断训练集中是否还有样本点,如果有则找到离ai最近的样本点,从步骤(2)重复;若没有样本点则训练过程结束。
2 交叉覆盖算法泛化性能分析
根据文献[9]平面螺旋线识别问题中所得结果,该算法对学习样本的识别率为100%,但对螺旋线上的非学习样本点,则不能达到100%的识别率,特别是在测试样本有一定随机扰动时,识别率下降很多。泛化能力不理想的主要原因是由于覆盖领域的边界接近另外一类,即在求以ai为中心的领域C(ai)时[9],C(ai)对应的权和阈值按下式求得:

由(1)~(3)式可知,当d1(i)≈d2(i)时,d(i)≈d2(i),会发生如图1所示的情况,图中圆形区域为覆盖领域C(ai),当领域C(ai)极其接近K2中的点时,会产生测试样本中K2类的点的误识情况。
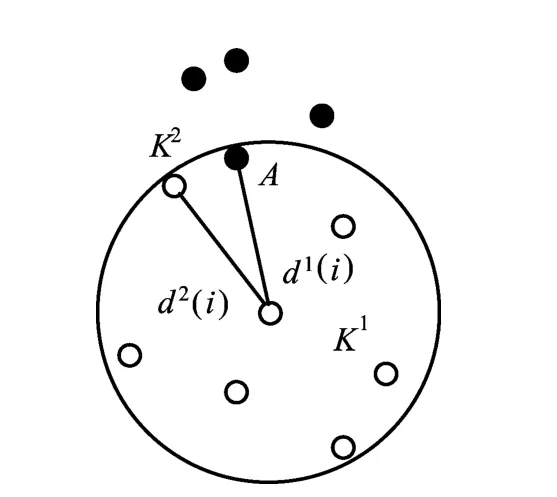
图1 误识情况示例
其中,○表示K1类的样本点,●表示K2类的样本点,点A表示K2类的测试样本误识为K1类的情况。K2中点的吸引域与覆盖领域C(ai)的交集非空,因而在测试时造成样本误识,而正是上述情况导致了误差的出现。为直观计,将公式中的内积直接表示成距离,实际含义是相同的。但是,该种情况并非不可区分[10]。
引理1 设任意一个覆盖领域C(ai)的中心为ai(ai∈K1),半径为R,与其相邻的最接近的K2类点是a,则点a的吸引域侵入覆盖领域C(ai)部分的侵入距离r<R/2。

实际上,由于R具有单调增加趋势,而r+r′固定不变,因此r相对R/2而言是很小的量,则可能出错域是一个外径为R、内径为R-r的一个超圆环域。由引理1可得定理1。
定理1 设逼近的目标函数为f:Rn→{-1,+1},且样本集按分布p(x)随机抽取,则基于覆盖的单个神经元的泛化误差E的上限可以估计为:
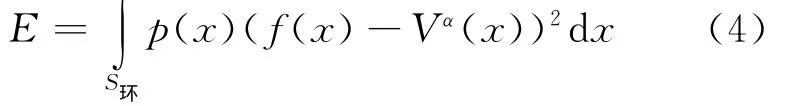
由此可见,交叉覆盖中单个神经元的误差区间为最大半径和最小半径之间存在的环域,如图2所示。
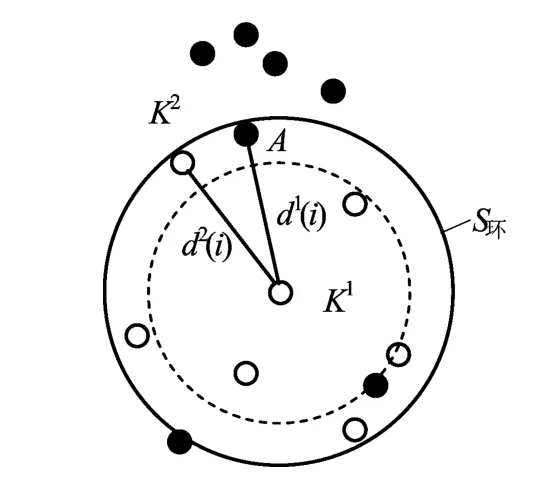
图2 S环示例
因此,若想提高神经网络集成后系统的泛化误差,降低系统的误识率,关键是降低神经网络集成后系统中各个神经元误差区域的交集,即减小集成后各个神经元的S环交集区域。所以,在集成过程中,需要对产生的覆盖领域进行优化处理,以生成合适的神经元。
3 基于领域优化的交叉覆盖神经网络
在构造网络集成中的每个个体网络过程中,采用如下方法。
(1)第1个神经网络的构造过程同一般的交叉覆盖算法。
(2)设第n个网络已经构造完成,则第n+1个网络的构造方法是在原有的交叉覆盖算法基础上,加入覆盖领域优化算法CAOA。在生成新的覆盖领域C(ai)时,检查与所有已经生成的覆盖领域的交集:① 如果存在C(aj),使
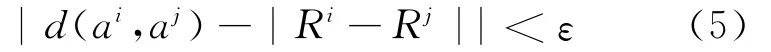
则将覆盖领域C(ai)平移,生成覆盖领域C′(ai),使其不满足(5)式,否则减小C(ai)的半径r,使其不满足(5)式;② 如果存在C(aj),使

则将覆盖领域C(ai)平移,生成覆盖领域C′(ai),使其不满足(6)式,否则减小C(ai)的半径r,使其不满足(6)式。
在完成n个神经网络构造之后,每一个神经网络都对各个类别有着与其他n-1个神经网络不同的新划分,在待识别的样本点落入神经网络模型中时,n个网络分别独立进行识别,最后对结果进行投票,当有多数网络将待测样本识别为同一个类时,则输出多数网络支持的识别结果。
4 神经网络泛化性能分析
由上述分析知,覆盖领域的中心部分基本没有误差,绝大多数误差发生在覆盖领域的边界部分,即覆盖外侧的环形区域内。在网络集成中,由于各个子网络的差异性,对于K1类的样本识别时,产生的覆盖领域如图3所示,其中阴影部分即为系统发生误识的区域。

图3 神经网络集成后的误识区域
由图3可见,通过神经网络集成,原来在最大半径和最小半径之间存在的环域中的误差区域,已经被新的3个环域的交集所取代,可能发生识别误差的范围显著缩小,仅仅存在于3个环域的6个交集中,而测试样本点刚好落在这些区域内的可能性非常小,因此识别率会明显提高。
假设1 学习任务是利用N个神经网络组成的集成对f:Rn→{0,1}进行近似,集成采用相对多数投票法。
假设2 样本集按分布p(x)随机抽取,网络α对输入X的输出为Vα(X),根据引理1,则单个神经网络α的泛化误差Eα为:

其中,∪S环为神经网络α中所有神经元S环的并集。
定理2 满足假设1、假设2的神经网络集成的泛化误差上限可估计为:
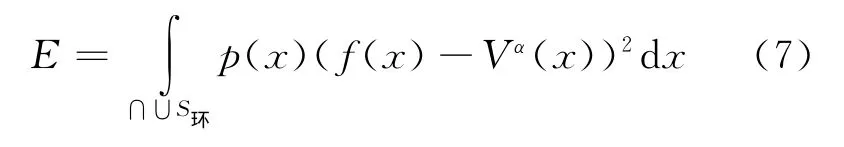
其中,∩∪S环为相对多数个∪S环的交集。
在子网络的生成过程中,加入领域优化算法CAOA,不断监视覆盖领域的生成情况,并对生成的覆盖领域进行优化处理,尽量减少覆盖领域重合、内切和外切的情况发生,如图4所示,以提高集成后系统的泛化性能。

图4 覆盖领域的重合、内切和外切状态
5 应用实例
采用3个神经网络进行集成,3个网络分别独立进行识别,对得到的结果进行投票,将输出多数网络支持的识别结果作为系统最终识别结果,集成后生成覆盖领域的个数为3个子网络覆盖领域数的平均值。
例1 电离层数据分类。Ionosphere电离层数据库是收集于加拿大的Goose Bay和Labrador的雷达信号数据,它包含17个脉冲信号,每个脉冲有2个属性,信号分为“好”和“坏”2种,“好”是指可反映电离层的结构,而“坏”是指信号穿过电离层,不能反映电离层的结构,即数据库共有35个属性。该数据库的前200个样本中“好”和“坏”各占50%,后150个样本中,“好”的有123个。实验中随机抽取75%的数据为训练样本,其余25%的数据为测试样本。
Ionosphere数据识别结果见表1所列,其中,方法1为交叉覆盖算法(50次平均);方法2为标准交叉覆盖神经网络集成;方法3为基于CAOA的交叉覆盖神经网络集成。基于CAOA的交叉覆盖神经神经网络集成中各个子网络识别结果,见表2所列。
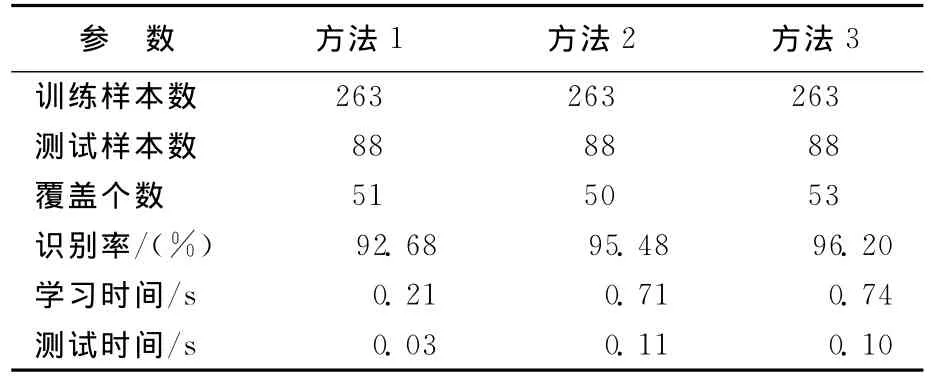
表1 Ionosphere数据识别结果
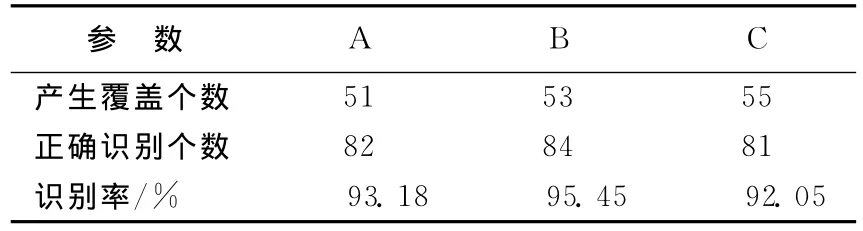
表2 采用方法3A、B、C子网络对例1识别结果
例2 玻璃识别数据集分类。Glass数据集提供了6种玻璃数据的分类信息,共有9种属性。其中,对于第1类有70条数据记录,第2类有76条数据记录,第3类有17条数据记录,第4类有13条数据记录,第5类有9条数据记录,第6类有29条数据记录。实验中随机抽取75%的数据为训练样本,其余25%的数据为测试样本,实验结果见表3、表4所列。其中,方法1~方法3同表1。
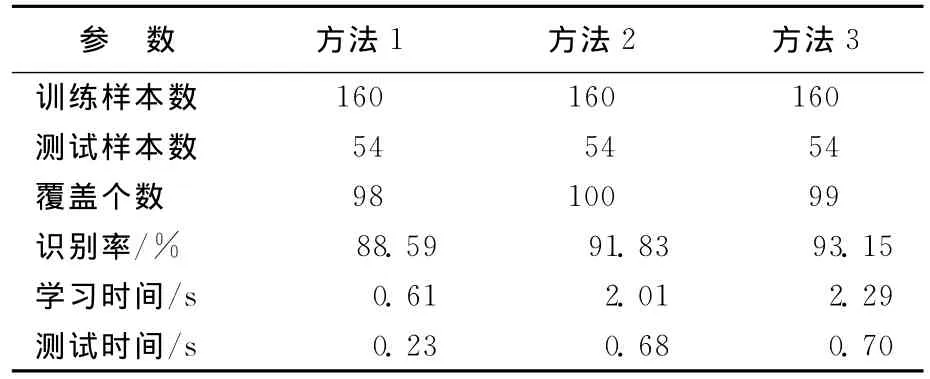
表3 Glass数据识别结果
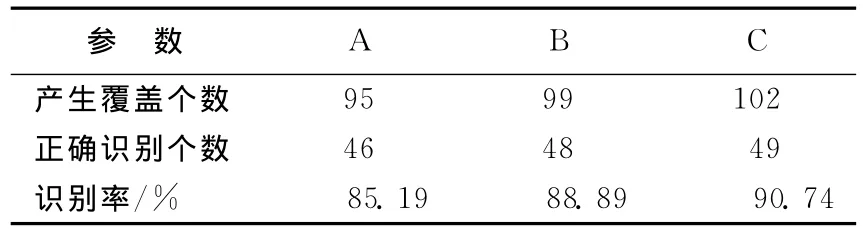
表4 采用方法3A、B、C子网络对例2识别结果
以上数据显示,从识别效果上看,神经网络集成可以大大提高系统的识别能力,领域优化算法CAOA使集成过程中获得较优的覆盖,从而进一步提高系统识别率。从执行时间上看,由于神经网络集成要训练若干的独立的子网络,识别过程中也需要各子网络独立给出识别结果,因此,训练和测试时间都有所延长。加入算法CAOA,使系统在集成时对生成的覆盖有所选择,因此会影响训练时间,但影响并不十分明显。在测试阶段,标准交叉覆盖神经网络集成与加入算法CAOA的神经网络集成所用时间并无明显差别。
6 结束语
本文在对交叉覆盖算法的基本思想及泛化性能分析的基础上,提出了一种集成的交叉覆盖神经网络构造方法,在子网络的生成过程中加入领域优化算法CAOA,对生成的覆盖领域进行优化处理,以降低集成系统的误识区域,增强识别效果。实例证明,该神经网络集成构造方法有效。在实际应用过程中,应充分考虑数据集本身的分布特征,并综合考虑网络规模和时间消耗。
[1] Hansen L K,Salamon P.Neural network ensembles[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,1990,12(10):993-1001.
[2] Zhou Z H,Wu J X,Tang W.Ensembling neural networks:Many could be better than all[J].Artificial Intelligence,2002,137(1/2):239-263.
[3] 丁亚明,王树忠,张志红,等.基于改进神经网络的模糊聚类算法[J].合肥工业大学学报:自然科学版,2007,30(8):934-938.
[4] 周志华,陈世福.神经网络集成[J].计算机学报,2002,25(1):1-8.
[5] 姚敏锋,李心广,黄文涛.一种k均值和神经网络集成的语音识别方法[J].计算机工程与应 用,2012,48(12):144-147.
[6] 刘政怡,吴建国,李 炜.基于交叉覆盖算法的中文分词[J].计算机工程与设计,2010,31(6):1355-1361.
[7] 贾瑞玉,李永顺.基于覆盖算法的分类器的设计与应用[J].安徽大学学报:自然科学版,2011,35(2):28-32.
[8] 刘政怡,龚建成,吴建国.基于交叉覆盖算法的中文文本分类[J].计算机工程,2006,32(19):183-184.
[9] 张 玲,张 钹,殷海风.多层前向网络的交叉覆盖设计算法[J].软件学报,1999,10(7):737-742.
[10] 宋茂斌,宫宁生.基于改进交叉覆盖设计算法的鲁棒性[J].计算机工程与应用,2007,43(22):71-72.
