基于玉米胚部特征参数优化的玉米品种识别研究
2014-12-27史智兴李亚南尹辉娟
程 洪 史智兴 冯 娟 李亚南 尹辉娟
(河北农业大学信息科学与技术学院1,保定 071001)(中国农业大学信息与电气工程学院2,北京 100083)
基于玉米胚部特征参数优化的玉米品种识别研究
程 洪1,2史智兴1冯 娟1李亚南1尹辉娟1
(河北农业大学信息科学与技术学院1,保定 071001)(中国农业大学信息与电气工程学院2,北京 100083)
为了提高玉米品种自动识别的可靠性,本文对表征品种的胚部特征参数进行了优化研究。采用区域生长法从玉米种子图像中分割出胚部区域,提取该区域的8个形状、6个颜色和6个纹理特征参数;定义了这些特征的类间和类内差异度计算公式,以便量化特征参数的有效性;结合改进的K-均值聚类算法,获得胚部形态的最优特征参数集。通过5个玉米品种各180粒的识别结果得知:玉米胚部特征参数在品种识别中作用显著,单纯基于胚部的优化特征参数集就可使其平均识别率达88%。本研究成果可为玉米品种自动识别开辟一条新思路。
胚部特征 参数优化 自动识别 K-均值聚类
利用机器视觉进行农作物种子品种自动识别可以实现快速、无损检测,易应用于种子流通和种植现场,对于保护农民利益、保障粮食安全意义重大。国内外学者在基于数字图像处理的玉米品种自动识别方面进行了大量研究[1-14],多数是以玉米种子整体作为研究对象。基于玉米种子整体形态特征的玉米品种自动识别存在以下问题:由于玉米棒上顶部、中部、底部的玉米种子形状差异较大,影响了玉米品种自动识别的鲁棒性。
由于玉米种子胚部受部位影响较小且同一品种的玉米种子胚部特性趋于一致。前期针对玉米种子胚部的研究,重点解决了胚部区域的分割问题,但未深入研究胚部特征对于识别有效性的问题。本试验提取胚部区域形状、颜色、纹理特征参数,对它们的品种识别有效性进行分析,并确定了用于识别的最优特征参数集。
1 试验材料和图像获取
以先玉335、农大4967、辽单565、金秋963与京科25共5个品种的玉米种子为研究对象,各随机选取样本180粒。设计了专用的图像采集装置如图1所示,其中载种台面为磨砂玻璃,载种盒内铺有黑橡胶板;拍摄照明可以采用反射光、也可采用透射光,使用反射光时种子放置在载种盒上,使用透射光时将种子放在载种台面;升架用来调节拍摄设备与种子间的距离;遮光布用来阻挡环境光的干扰。本研究中拍摄设备采用佳能600D数码照相机,照明采用反射光(白炽灯)照射,将玉米种子胚部所在面朝上放置在载物盒上,获得其RGB图像,图像格式为.jpg。

图1 图像采集装置
2 胚部特征提取
玉米品种自动识别研究流程如图2。获取图像后,采用Ostu法将载物盒背板部分置0以去除背景;采用区域生长法分割出玉米种子胚部;分别提取胚部基于RGB与HSI 模型的颜色特征、刻画其形状的特征与基于统计的纹理特征;分析胚部形态特征参数的均值与标准差,定义特征差异度用以分析特征的有效性;K-均值聚类算法结合特征类间类内差异度,得到最优特征参数集,对玉米种子品种进行识别。

图2 研究流程图
2.1 玉米胚部检测
在R、G、B色彩辨别方面,玉米粒胚部区域与非胚部区域之间的B值差异最大,G值次之,而R值的差异则最小。采用基于玉米种子RGB图像的区域生长法[7]分割出玉米种子胚部。分割效果如图3所示。

图3 各品种的胚部区域
2.2 胚部特征提取
由图3可以看出,5个品种的玉米种子胚部颜色非常接近,因此本研究中除采用人眼最为敏感的RGB颜色模型外,加入了更符合人眼对色彩的感知机理HSI颜色模型,由红(R)、绿(G)、蓝(B)、色度(H)、饱和度(S)、亮度(I)6个量来刻画胚部的颜色。对每粒种胚均提取以上6个颜色特征值。这6个特征值分别是每粒种胚所有像素点的R、G、B、H、S、I的平均值。因为本研究采集的图像是RGB图像,采用公式(1)~(4)实现RGB到HSI的彩色坐标变换。
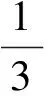
(1)
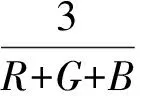
(2)
(3)

(4)
由图3可见,5个玉米品种的种胚大小不一、形状各异,本文提取面积(S1)、周长(S2)、圆形度(S3)、椭圆短长轴比(S4)、矩形度(S5)、离心率(S6)、外接矩形长宽比(S7)、外接多边形面积比(S8)8个参数,来刻画胚部的形状特征。S1即胚部区域像素的个数;S2即胚部区域的边缘像素个数;S5即胚部区域的面积/包围该连通域的最小矩形面积;S3 = 4×pi×S1/(S2)2;S4是与胚部区域具有相同标准二阶中心矩的椭圆的短轴与长轴的比值;S6是具有相同标准二阶中心矩的椭圆的离心率。
纹理是相邻像素的灰度或彩色的空间相关性的视觉表现[15]。纹理分析方法大致分为结构分析方法与统计分析方法2类。统计分析方法并不刻意去精确描述纹理的结构。从统计学的角度来看,纹理图像是一些复杂的模式,可以通过获得的统计特征集来描述这些模式。考虑到研究对象形状的不规则性,本研究采用基于区域亮度直方图的统计方法来描述玉米种子胚部的纹理特征[16]。
由于种子胚部图像中,背景占了比较大的比例,在计算纹理特征时要消除背景的影响,所以要在亮度直方图中去除灰度值为0的像素,纹理特征的计算公式分别为:

(5)
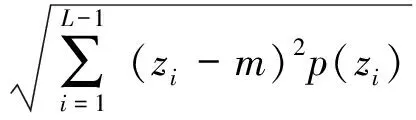
(6)
平滑度RS=1-1/(1+σ2);
(7)
三阶矩μ3=∑(zi-m)3p(zi);
(8)

(9)

(10)
式中:zi为亮度的随机变量;p(zi)为一个区域中灰度级的直方图;L为灰度级数。
3 特征数据分析
由于种胚颜色、形状、纹理特征数据量纲有差异,为了方便分析将提取的数据按照公式(11)标准化,公式如下:

(11)
式中:l为某一个特征;ailx为第i个品种的第x个样本的l特征标准化后的值;bilx为第i个品种的第x个样本的l特征标准化前的值;bilmax与bilmin分别是第i个品种的180个样本中的l特征的最大值与最小值。
3.1 特征类间类内差异度计算公式定义
(12)
式中:Dl为l特征类间类内差异度,Dl≥1 ;k为品种个数;n为品种样本数;averil为第i个品种n个样本的l特征均值。
由式(12)可以看出,Dl越大品种间的l特征差异度越大,品种内l特征差异越小,l特征可用于识别玉米品种的可能性越大;Dl越接近1,品种间的l特征差异度越小,品种内l特征差异越大,l特征可用于识别玉米品种的可能性越小。利用上述公式计算每个特征的类间类内差异度,并按差异度排序,结果如表1所示:顺序为形状特征、颜色特征(除饱和度)、纹理特征。形状参数的差异值均在1.7以上,颜色特征中S分量差异值最大,为1.85,H分量的差异值最小,纹理特征的差异值均在1.35以下。
3.2 特征参数值分布图分析
图4给出了5个玉米品种样本的面积(S1)、外接矩形长宽比(S7)、色度(H)3个特征参数值的分布情况。这3个特征参数的特征类间类内差异值分别为3.06、2.10、1.05,具有一定的代表性。为了方便观察,每个品种随机取60个样本。
从图4中S1值分布图可见,玉米被明显的分为2大类:京科25、先玉335为一类,其余3个品种为一类。前一类中京科25胚部面积略大,后一类中金秋963略大。从整体看S7值由大到小可分为:农大4967、先玉335、金秋963、京科25、辽单565,其中第1种的值基本处于0.7以上,最后2种的值基本处于0.7以下。对于H值,不仅每个品种样本间的差异较大,而且不同品种没有明显差异,用于识别分类已没有显著意义。由此可知,特征参数值的直观分布图所反映出的特征参数有效性与式(12)计算得到的量化值有很好的对应关系。本研究中特征类间类内差异度值在2以上的均可用来识别玉米品种。

表1 各特征的类间类内差异度
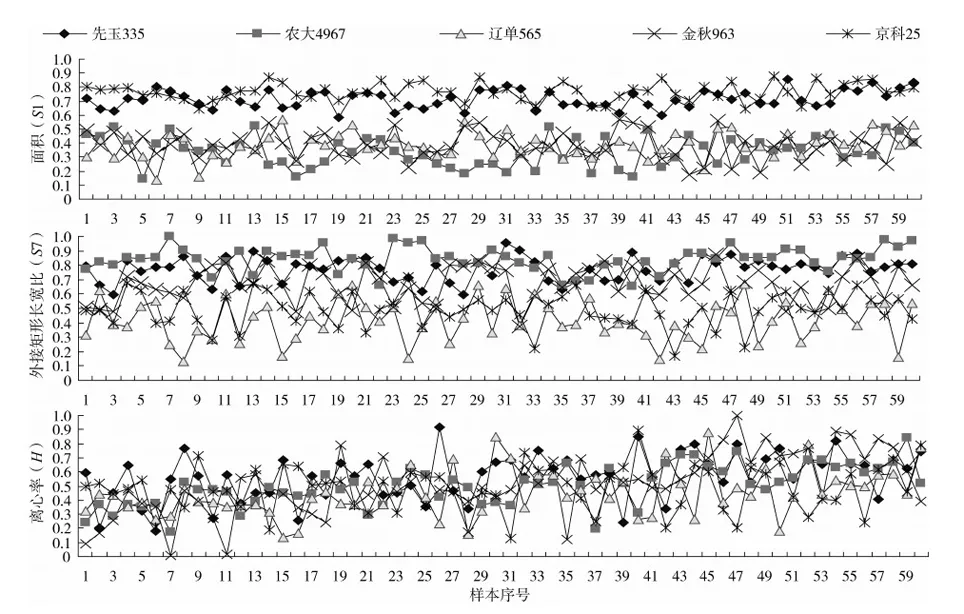
图4 特征参数值分布图
4 采用改进K-均值聚类算法进行玉米品种识别
本研究提取了玉米种胚众多的形态特征,如果把所有的特征都作为最终的分类特征送往分类器,不同品种间差异小的特征会影响分类的正确率。因此为达到用于玉米品种识别的胚部信息最优,要从初步选定的特征参数中,筛选能实现正确分类率最大化的最优特征参数集(能达到识别率高且包含特征数目最少)。
筛选方法:先以差异值大于2的特征组成特征参数集,K-均值聚类算法进行识别,计算平均识别率;根据特征类内类间差异值将其他特征逐个加入到特征参数集,识别,分别计算平均识别率,对识别率进行比较;使5个玉米品种的平均识别率最高特征集为得到的最优特征参数集。
4.1 改进的K-means算法的基本概念
传统的K-means算法对初始聚类中心的选取比较敏感,因此选取的随机性直接影响聚类结果的准确性和稳定性。本研究基于密度聚类方法的思想,采用了基于密度的初始中心的优化方法[17-19]。
有关密度的几个基本定义如下:
定义1 不同玉米种胚x,y之间的距离公式

(13)
式中:d(x,y)为x,y间距离;xi、yi分别是x、y的第i个特征值。
对于具有900个样本,可得相似度矩阵S:

定义2 玉米种胚间的平均距离公式
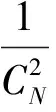
(14)
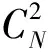
定义3 种胚x的邻域:对于任意种胚x,以x为中心,以dA为半径的圆形区域。
δx={y|0 (15) 式中:δx为种胚x的邻域。 定义4 种胚x的分布密度 p(x)=Number(δx) (16) 式中:p(x)为种胚x的分布密度,定义为除x外的x邻域内种胚的数目。 1)以相似矩阵为基础,在所有种胚中,选择密度最大的点作为第1个初始中心点,然后删去该点及其邻域内的所有对象。 2)按1)中方法确定第2个初始中心点,循环执行直到初始中心点集C中有5个点: 3)以C为初始聚类中心,令k=1 采用上述筛选方法得到包含S1、S2、S3、S4、S5、S6、S7、S8与颜色特征中的S分量9个参数的最优特征集。 采用改进的K-均值聚类算法基于胚部特征进行品种识别的结果如表2所示。采用文中提取的所有特征(共20个)进行分类识别,平均识别率为78.44%,采用最优特征集进行识别,平均识别率为88%。 表2 玉米品种识别结果 5.1 本研究通过特征类间类内差异度与改进的K-means算法结合,得到可用于玉米品种识别的9个胚部特征参数,其有效性由大到小依次为:面积、外接多边形面积比、周长、离心率、外接矩形长宽比、椭圆短长轴比、饱和度、矩形度、圆形度。 5.2 通过5个玉米品种的识别试验结果表明,利用胚部特征对5个玉米品种的平均识别率可达88%,说明胚部特征对玉米品种的自动识别起着十分重要的作用,可以作为研究玉米品种自动识别的新思路。 5.3 本研究定义的特征类间类内差异度计算公式,不仅可以用于分析玉米种子胚部特征,也可用于其他分析对象特征有效性的场合。 此外根据胚部褶皱情况,寻找新的有效特征参数来描述胚部纹理特性,有进一步研究价值。 [1]Liu J,Paulsen M R. Corn whiteness measurement and classification using machine vision[J]. Transactions of the ASAE,2000,43(3):757-763 [2]Yang W, Winter P, Sokhansanj S,et al. Discrimination of hard-to-pop popcorn kernels by machine vision and neural networks[J]. Biosystems Engineering, 2005, 91(1): 1-8 [3]Hausmann Nel J, Abdaie Tabare E, Cooper Mark, et al. Method and System for Digital Image Analysis of Maize[P].International: WO2009023110(A1), 2009-2-19 [4]Jiang Jingtao, Wang Yanyao, Yang Ranbing. Variety identification of corn seed based on Bregman Split method [J]. Transactions of the Chinese Society of Agricultural Engineering,2012,28(Supp.2):248-252 [5]宋鹏,吴科斌,张俊雄,等. 玉米单倍体籽粒特征提取及识别[J].农业机械学报,2012,43(3):168-172 [6]刘双喜,王盼,张春庆,等. 基于优化DBSCAN算法的玉米种子纯度识别[J].农业机械学报,2012,43(4):188-192 [7]史智兴,程洪,李江涛,等. 图像处理识别玉米品种的特征参数研究[J].农业工程学报, 2008,24(6):193-195 [8]郝建平,杨锦忠,杜天庆,等.基于图像处理的玉米品种的种子形态分析及其分类研究[J].中国农业科学,2008,41(4):994-1002 [9]张海艳,董树亭,高荣岐,等.玉米籽粒品质性状及其相互关系分析[J].中国粮油学报,2005(6):19-24 [10]程洪,史智兴,么炜,等. 基于支持向量机的玉米品种识别[J].农业机械学报,2009,40(3):180-183 [11]郑小东,王杰. 机器视觉在玉米籽粒品质检测中的应用研究[J].中国粮油学报,2013(4):124-128 [12]权龙哲,祝荣欣,雷溥,等. 基于K-L变换与LS-SVM的玉米品种识别方法[J].农业机械学报,2010,41(4):168-172 [13]万鹏,孙钟雷,宗力. 基于计算机视觉的玉米粒形检测方法[J].中国粮油学报,2011(5):107-110 [14]韩仲志,杨锦忠,李言照. 玉米品种图像识别中的影响因素研究[J].中国粮油学报,2012(10):98-103 [15]张海艳,董树亭,高荣岐,等.玉米籽粒品质性状及其相互关系分析[J].中国粮油学报,2005(6):19-24 [16]冈萨雷斯,著.数字图像处理:MATLAB版[M]. 阮秋琦,译.北京:电子工业出版社,2006 [17]汪中,刘贵全,陈恩红.一种优化初始中心点的K-means算法[J].模式识别与人工智能,2009,22(2):299-304 [18]周炜奔,石跃祥. 基于密度的K-means聚类中心选取的优化算法[J].计算机应用研究,2012,29(5):1726-1728 [19]李伟雄. 基于密度的聚类算法研究[D].长沙:湖南大学,2010. Corn Embryo Parameters Optimization and Varieties Identification Research Cheng Hong1,2Shi Zhixing1Feng Juan1Li Yanan1Yin Huijuan1 In the paper, a method for automatic identification corn varieties has been proposed. The method was K-means clustering algorithm combined degree of difference of characteristic based on corn kernel embryo morphology. It extracted the embryo region adopting region growing algorithm; extract characteristics of embryo region: eight shape features, six color features and six texture features. In order to select the most effective features of the embryo for identification of corn varieties, difference degrees of inter-class and intra-class of different feature for measure the effectiveness of features have been defined. K-means clustering algorithm with the characteristic difference degree has been used to find the optimal portray embryo morphology feature subset to recognize corn varieties. Five corn varieties were selected as the research object, 180 kernels respectively. The average recognition rate was 88% after researched by K-means algorithm with the feature subset. characteristics of embryo, parameters optimization, automatic recognition, K-means cluster algorithm TP391.41 A 1003-0174(2014)06-0022-05 “十二五”农村领域国家科技计划(2011BAD16B08-3),河北农业大学理工基金 (LG20110601),保定市科学研究与发展计划(13ZN010) 2013-07-08 程洪,女,1981年出生,讲师,数字图像处理4.2 改进K-means算法的运行步骤


5 结论
(College of Information Science and Technology, Agricultural University of Hebei1, Baoding 071001)(College of Information and Electrical Engineering, China Agriculture University2, Beijing 100083)
