语义Web中本体概念的语义匹配分离方法
2014-12-20唐郑熠李均涛
唐郑熠,韦 立,李均涛,万 良
(1.福建工程学院 信息科学与工程学院,福建 福州350118;2.贵州师范大学数学与计算机科学学院,贵州 贵阳550001;3.贵州财经大学 信息学院,贵州 贵阳550004;4.贵州大学 计算机科学与技术学院,贵州 贵阳550025)
0 引 言
Web服务是目前最有希望实现面向服务的计算与体系架构 (SOC&SOA)的技术,但由于服务之间所存在的“语义鸿沟”[1],使得服务的功能与内涵难以被准确表示,从而给服务发现、匹配、组合、验证等各个环节都带来了困难。因此,学术界和工业界提出了一系列包含语义的Web服务描述标准 (OWL-S、WSMO、SWSO 等)。本体是语义Web技术的基础与核心,能够很好地表达服务的语义信息。在SOC&SOA 的多个环节中,都是以本体概念的语义匹配为基础进行的。例如,服务发现需要匹配发现请求与候选服务的输入输出;服务组合需要匹配前驱服务与后继服务的输入输出;服务验证也需要通过语义匹配来判定组合结果与组合需求的一致性。
目前认可度较高的一类本体概念匹配度定义方法,是基于本体概念之间的等价和包含关系的。这种方法能有效提高语义匹配的查准率和查全率,且易于实现和集成,因此被许多研究工作采用[2-7]。得益于相关领域学者的工作,目前能够对本体进行可满足、包含、等价和不相交的推理,且有相应的推理机 (Pellet、RACER、FaCT++等)实现推理过程的自动化。通过推理机预留的外部接口,可将其集成到Web服务组合系统中,承担语义匹配的任务。但是推理机执行推理任务的时间代价较高,会大大降低那些需要频繁进行语义匹配环节 (例如服务发现和组合)的效率。虽然推理机的推理算法在不断改进,但在短期内难以有显著改善。
本文的研究工作尝试从另一个角度来解决这个问题:依据本体概念之间匹配关系的性质,得到组织本体概念的方法,提出了公共本体概念库的概念,从而能够通过编码保存概念之间的匹配度信息,把语义匹配从其它环节中分离出来。耗时的语义匹配工作被提前到服务发布阶段,可以提高其它环节的效率,并增强用户体验。同时也给出了对公共本体概念库进行更新的算法,以满足本体概念增加、删除及修改的动态需求。基于公共本体概念库,可以实现本体概念的交互式注册,服务提供者可以在这个过程中发现已存在的等价或相近概念,从而改进本体概念的设计。
1 公共本体概念库
公共本体概念库保存了本体概念的记录,并根据本体概念间的匹配度进行分层组织及编码。由于编码保存了本体概念的匹配度信息,可以在需要时从中快速提取,因此不会影响到其它环节的效率。同时,编码中的信息也可以有效减少语义匹配的次数。
1.1 本体概念的组织结构
保存匹配度信息的直观方法是将本体概念间的匹配度作为元素构成矩阵[8],但这种方法没有利用匹配度之间的关联来减少匹配次数,也不利于对本体概念进行更改。文献 [6]提出了分层的组织方法,但它只在服务的层级上进行,不能把语义匹配彻底分离。而文献 [7]提出的方法虽然是在概念层级上进行分层,但没有考虑到本体概念等价的情况,也没有给出更新的方法,不适合本体概念的动态性。
由于等价与包含关系具有传递性,以此为基础的匹配度定义也具有传递性,例如CMU 的M.Paolucci等人提出的被广泛使用的四级匹配度[2]:
定义1 本体概念的四级匹配度:对于本体概念c1和c2:若c1与c2等 价 (记 为c1≡c2),则 匹 配 度Mat(c1,c2)=Exact;若c1为c2的子概念 (c2包含但不等价于c1,记为c1∝c2),则匹配度Mat(c1,c2)=Plug-in;若c2为c1的子概念 (c1包含但不等价于c2,记为c2∝c1),则匹配度Mat(c1,c2)=Subsume;若不满足上述情况,则匹配度Mat(c1,c2)=Fail。且:Exact>Plug-in>Subsume>Fail。
显然有:对于本体概念c1、c2和c3,存在Mat(c1,c2)=Mat (c2,c3)=Exact/Plug-in/Subsume Mat(c1,c3)=Exact/Plug-in/Subsume。
在树形结构中,节点也有类似的传递性:subof(n1,n2)表示n1位于以n2为根节点的树上,则subof(n1,n2)∧ (subof (n2,n3) subof (n1,n3)。因 此,可 以 依 据这种性质将本体概念组织为层次清晰、上下位关系明确的树形结构,以保存本体概念间的匹配度信息。该结构的优点在于,无论是构建还是更新,都可以通过传递性来减少语义匹配的次数。在下一节的定理1中,将表明这一点。
1.2 公共本体概念库的构成
公共本体概念库 (public ontology concept depot)由2个部分组成:概念描述子库 (concept description depot)和语义关联子库 (semantic association depot)。前者用于存放本体概念的具体描述及索引信息,而后者则根据匹配度对本体概念进行分层组织。
定义2 公共本体概念库:一个公共本体概念库POCD= (CDD,SAD),其中:CDD 是概念描述子库,SAD 是语义关联子库。
概念描述子库不仅仅是本体概念的具体描述,还包含一些索引信息,概念描述子库的定义如下:
定义3 概念描述子库:一个概念描述子库CDD={cr= (cd,id,NIDS)},是概念记录cr的集合,其中:
(1)cd 是一个具体的本体概念,每个本体概念只能在一条概念记录中出现。
(2)id 是cd 的唯一标识。
(3)NIDS是后文所述的语义关联树的节点标识集合,表明这个概念被包含在哪些节点中 (可能不止一个)。
为每个本体概念赋予唯一标识,是为了避免重复保存本体概念的具体描述,以减小数据冗余度;而节点标识集合则是为了利用节点的位置编码,以避免重复的进行概念包含和等价的判定。
本文把语义关联子库定义为一棵语义关联树:
定义4 语义关联子库:一个语义关联子库SAD=SAT。
定义5 语义关联树:一棵语义关联树SAT= (NS,root,PCR),其中:
(1)NS= {(id,ECIDS,CNIDS,locCode)}为节点集合,节点是一个四元组,其中:id 是节点标识;ECIDS是等价概念标识集合,其元素所对应的概念互相等价;CNIDS是子节点标识集合;locCode是该节点的位置编码,是一个先进先出的整数队列。
(2)root= (0, {0},CNIDS,<>)∈NS为根节点,即:根节点的标识为0 (本文使用整数做节点标识);根节点只包含一个元概念 (meta concept),记为mc, 概念c:c∝mc;根节点的位置编码是一个空队列。
(3)PCR= {(n,m)|n,m∈NS}是节点的父子关系集合,(n,m)表示节点n 是节点m 的父节点。对于id∈n。ECIDS对应的概念c,称节点n 包含概念c,记为c∈′n。对于 (n,m), c∈′n和 c′∈′m,满足c′∝c。
节点的位置编码包含了它的位置信息,可以避免语义包含与等价的重复判定。
定义6 位置编码:节点的位置编码locCode=<m1,m2,…mk>是一个先入先出的队列,是从根节点到达该节点的路径编码,队列中的每个值都保存了节点的一个祖先节点的信息。通过mi的值可以确定节点在第i 层 (设根节点处在第0层)的祖先节点。
由包含关系和等价关系的传递性,可以得到以下结论:
定理1 在一棵语义关联树SAT 中,对于任意本体概念c和c′,及包含c的节点n (记为c∈′n)和包含c′的节点n′,存在:subof(n,n′) c∝c′(c是c′的子概念)。
证明:已知subof(n,n′),则存在一条由节点构成的从n′到达n 的路径:<n′,n1,n2,…nk,n>,且满足(n′,n1)∈SAT.PCR∧(nk,n)∈SAT.PCR∧ 1≤i≤k:(ni,ni+1)∈SAT.PCR。
又由定义5 可知:对于 (n,m)∈SAT.PCR,若cn∈′n且cm∈′m,则cm∝cn。
在<n′,n1,n2,…nk,n>中,取ci∈′ni(1≤i≤k),可得:c1∝c∈∧c2∝c1∧…∧ck∝ck-1∧ck∝ck-1∧c∝ck。
由于∝关系满足传递性,则有c∝c′。
证毕。
因此,通过比较本体概念所处节点的位置,就可判定本体概念间的等价或包含关系,从而得到匹配度。而位置比较可以通过比较节点的位置编码在线性时间内完成,对其它环节的效率几乎没有影响。同时,若判定本体概念c是c′的子概念,则c的所有等价概念及子概念也都是c′的子概念,而不必再一一进行判定,因此可有效减少匹配次数。
1.3 公共本体概念库的创建
对于一个给定的本体概念集合,可以创建一个对应的公共本体概念库。创建过程分为3个部分:
(1)创建一个初始的概念描述子库,为每个概念创建一条概念记录,并赋予唯一标识,但所属节点标识集合先置为空 (但元概念可直接确定)。其过程比较简单,本文不赘述。
(2)根据初始的概念描述子库,创建语义关联子库(即一棵语义关联树),但位置编码先置为空,由后述的算法1实现。
(3)根据语义关联子库,计算每个节点的位置编码,由后述的算法2实现。
以下的算法描述中用到了几个函数:i2c (id)函数的作用是根据概念标识id,返回对应的概念;i2n (id)函数的作用是根据节点标识id,返回对应的节点;len (queue)函数的作用是返回队列queue的长度。
算法1:ESAD (establish semantic association depot)
输入:An initialized concept description depot CDD。
输出:A semantic association depot SAD,a complete concept description CDD。


算法1用于创建初始的语义关联子库,实质上是将所有的本体概念依次插入到语义关联树的某个节点中。每一个待插入的本体概念cr.cd 都从根节点开始判断插入位置,节点队列waitVstNode用于存放待访问的节点,初始时只有根节点。对于从waitVstNode中弹出的节点n,cr.cd 一定是n 所包含概念的子概念,因为在算法1中只把这类节点放入waitVstNode中,如下文所述。cr.cd 与n 的子节点m 所包含的概念有4种可能的关系:
(1)cr.cd 与m 所包含的概念等价,则把m 放入集合EqC 中,cr.cd 会被并入这类子节点。
(2)cr.cd 是m 所包含概念的子概念,则把m 放入集合ConC 中,这类子节点将被放入waitVstNode中,等待进一步向下访问。
(3)m 所包含的概念是cr.cd 的子概念,则把m 放入集合BeConC 中,并且最后将创建一个包含cr.cd 的新节点t,插入到n与这类子节点之间。
(4)两者没有包含或等价关系,则不做任何操作。
当对n的所有子节点都进行完上述判定后,如果EqC、ConC、BeConC 这3个集合都为空,则需要创建一个新的节点t并包含cr.cd,作为n的一个新的子节点。
算法2:CLC (cmput location code)
输入:A semantic association depot SAD,the starting location sn。
输出:A semantic association depot SAD with new location code。

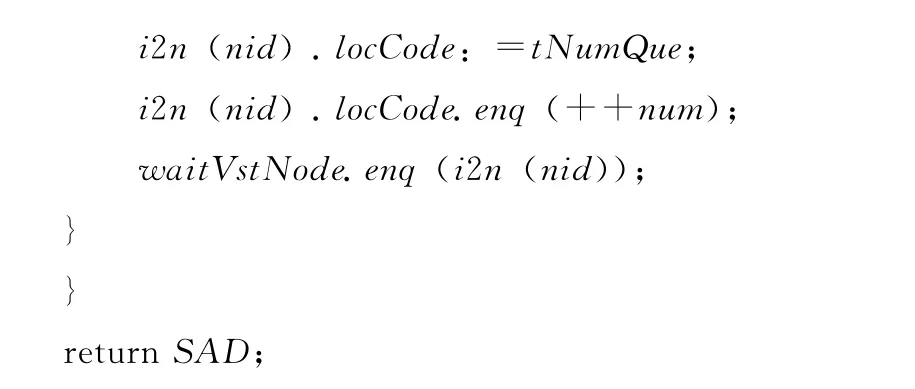
算法2通过广度优先的策略遍历语义关联树,并为每个节点进行编码,节点的位置编码是数字队列,每一个节点的位置编码,都是在其父节点的位置编码尾部增加该节点自身的数字编号,但根节点的位置编码为空队列。为了后续的更新操作的需要,算法2添加了一个参数:计算的起始节点。因此准确地说,算法2是用于计算以起始节点为根节点的子树中,除了根节点以外的所有节点的位置编码。如果要计算整棵树的所有节点的位置编码,只需要把起始节点设为根节点即可。
2 公共本体概念库的更新
在公共本体概念库建立之后,可能会因为开发的需求、对事物认识的改变、外界的新发现等原因,需要修改、添加和删除某些概念。在这种情况下,就需要相应地更新公共本体概念库。由于某个本体概念被修改后,与其它本体概念的包含及等价关系可能会发生变化,需要重新判定其在语义关联树中的位置,因此对于本体概念的修改操作,可以通过将要修改的概念删除,然后将修改后的概念作为新的概念添加来实现。因此,只需要提供2 种更新操作,即本体概念的添加和删除。
2.1 本体概念的添加
本体概念的添加操作分为两个部分:①在概念描述子库中创建一条新的概念记录;②将新建概念插入语义关联子库中。其中第一部分只是在库中新增一条记录,其过程比较简单。而算法1创建语义关联子库的过程,实质上就是依次向语义关联树插入多个新概念,因此第2部分插入单个概念的方法可参照算法1进行,不再赘述。新概念插入完成后,再使用算法2 更新整棵语义关联树节点的位置编码。
更新过程可进行以下优化:在插入一个概念时,如果创建了新节点,则需要更新语义关联树节点的位置编码,但并不是整棵树的所有节点都需要更新。如图1(a)所示。当插入概念y 时,需要创建一个新的节点,即图1 (a)中标识为102 且用虚线框起的节点。此时,只有以标识为50 的节点为根节点的子树,需要更新位置编码 (但该子树的根节点不用更新)。所以可以直接使用算法2,以标识为50的节点作为起始节点,更新计算位置编码。因此,插入新概念的算法应有一个返回值:当创建了新节点时,将新节点的父节点作为返回值返回,作为算法2的计算起始节点;否则返回一个特定的值,说明没有创建新节点。
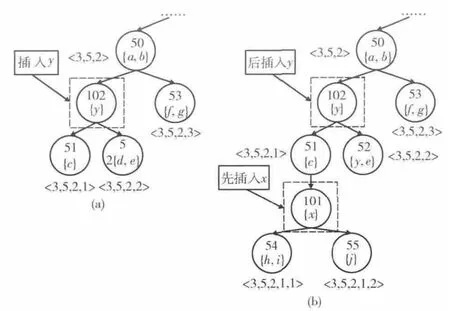
图1 添加节点后的两种情况
在某些时候,用户会向公用本体概念库中插入多个概念。如果每插入一个概念就更新一次语义关联库,可能会造成某些节点的重复更新。如图1 (b)所示:如果待更新的两棵语义关联子树的根节点具有祖孙关系,则会造成节点位置编码的重复更新。
2.2 本体概念的删除
本体概念的删除方法是:首先在概念描述子库中找到对应的概念记录cr,再由cr.NIDS找到包含此概念的节点n (可能不止一个),从n 的等价概念标识集 (n.ECIDS)中删除此概念的标识;最后在概念描述子库中删除对应的概念记录。其过程比较简单,本文不赘述。
需要注意的是:当从节点的等价概念标识集中删除概念标识后,可能会使节点的等价概念标识集合为空,此时该节点已没有存在的必要,应予以删除。如图2所示。
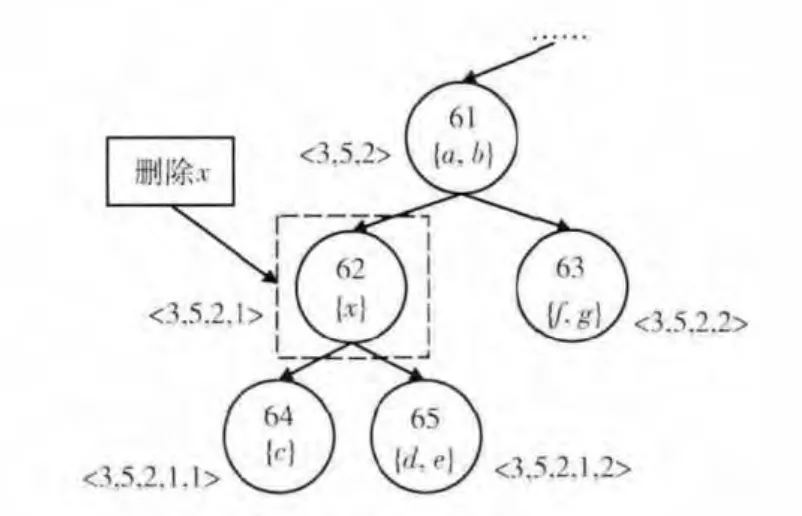
图2 删除节点
图2中删除概念x 后,62 号节点已无存在的必要,因此可以删除。删除后,它的所有子节点作为61号节点的子节点。但以61号节点作为根节点的子树需要重新计算位置编码。因此,删除概念时若发生了节点删除,应使用算法2来更新语义关联树节点的位置编码。同样,当一次有多个节点被删除时,也应注意避免节点位置编码的重复更新。
3 本体概念的交互式注册
在SOA 中,包含服务请求者、服务提供者和服务注册中心3种角色。服务提供者将服务发布到服务注册中心,服务请求者从中发现所需服务,并根据相应的信息与服务提供者进行绑定,从而使用其所提供的服务[9]。公共本体概念库设置在服务注册中心,与服务注册中心的其它组件互不影响。当服务提供者发布服务时,应同时将本体概念注册到公共本体概念库中 (即本体概念的添加操作)。
在传统的服务发布模式中,一个服务独占一组本体概念。因此当多个服务的输入输出出现重合时,会造成数据冗余。同时由于同一概念可能有多种不同的表达形式,不同的本体概念也可能是等价的。由于服务发布并不是提供具体的数据或资源,而只是公开服务的描述,因此将多个相同或等价的本体概念合并,不会影响服务发布的准确性。但由于服务开发者的观念差异等原因,等价的本体概念未必可以互相取代。因此在公共本体概念库的基础上,将本体概念的注册方法改进为交互式,如图3所示。
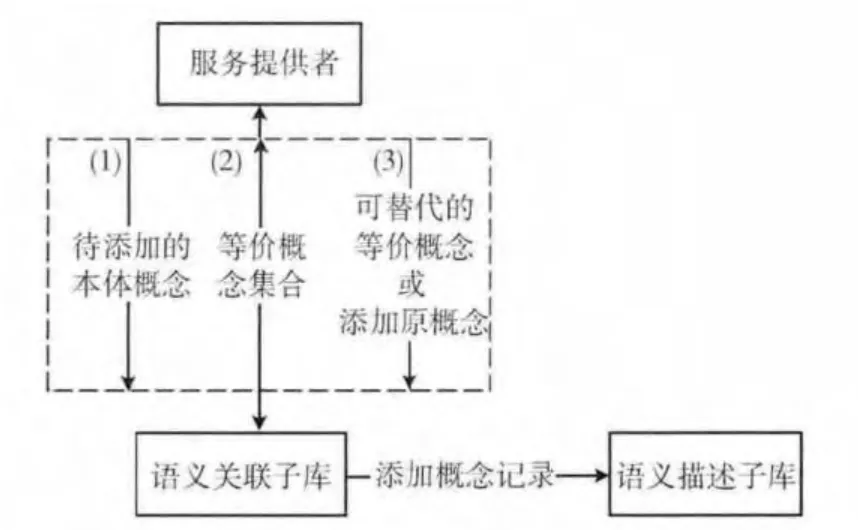
图3 本体概念的交互式注册
交互的过程如下:
(1)将待添加的本体概念传递给语义关联子库。
(2)如果添加过程中找到了等价的本体概念,则返回给服务提供者,否则完成添加操作 (包括语义关联子库和语义描述子库)。
(3)如果服务提供者从等价概念集合中发现了合适的等价概念,则可用该等价概念来取代原本的概念,从而避免添加多余的概念;如果服务提供者认为已存在的等价概念不能代替原本的概念,也可令系统依然将原本的概念添加到公共本体概念库中。
与传统的服务发布模式相比,本体概念的交互式注册不仅可以减少数据的冗余,而且可以让服务发布者根据已存在的相似描述,来改进本体概念的设计。
4 实验及结果分析
公共本体概念库的主要作用是提高语义匹配的效率,因此可以改进任何语义匹配占大比重的技术环节的效率。模拟实验以服务匹配作为实验对象,它是典型的完全基于语义匹配的环节,其定义如下[2]:
定义7 服务匹配:服务请求SR= (Ir,Or),服务S= (I,O),Ir、Or、I、O 都是本体概念集合,t为匹配度阈值。对于SR 和S,若 i∈I:-i′∈Ir:Mat(i′,i)≥t,且 o′∈Or:-o∈O:Mat(o,o′)≥t,则称服务S匹配服务请求SR,记为SSR。
模拟实验运行在CPU 主频2.2G、内存2G 的计算机上,以C语言作为开发语言。以Ka、People、Wine这3个规模不同的本体概念集[10-12]作为候选服务参数集,共包含316个概念,推理机使用Pellet。服务与服务请求从概念集中随机选取概念生成,每个服务或服务请求的输入和输出参数都是2~15个。
模拟实验分为5 组,针对5 个不同规模 (分别包含100、500、1000、1500、2000个服务)的服务库,以检验服务库规模的扩大对效率的影响。每组实验都随机生成100个服务匹配请求,分别用直接使用推理机 (Method_A)的方法与基于公共本体概念库 (Method_B)的方法进行测试,从匹配效率与匹配性能2个方法进行测试与比较。
4.1 匹配效率的测试与比较
在进行服务匹配之前,需要先进行服务发布。Method_A 只需要消耗加载本体的时间,约耗时5165ms;而Method_B还需要消耗建库的时间,约耗时40853 ms。由于服务发布过程是在用户提交匹配请求之前进行的,因此建库过程不会对请求响应速度产生影响,也不会降低用户体验。5组实验的平均请求响应速度如图4所示。
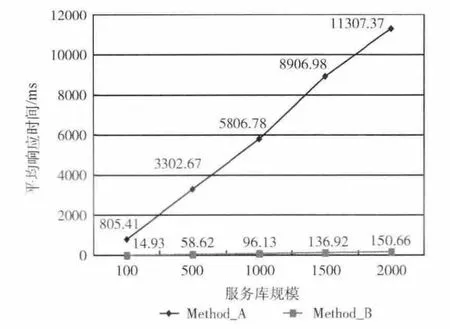
图4 服务匹配效率比较
可以看到,基于公共本体概念库的方法大幅提高了请求响应的速度,并且随着服务库规模的扩大,请求响应速度也没有急剧下降,优势明显。其原因在于,通过对本体概念的分层组织保存了概念之间的匹配度信息,因此在响应用户请求时无需进行概念匹配,从而能在线性时间内完成响应。同时,还有效避免了对概念的重复匹配。虽然建立公共本体概念库会导致服务发布时间大幅增加,但这代价显然是十分值得的。
4.2 匹配性能的测试与比较
由于服务匹配的过程类似于信息检索,因此采用信息检索领域的两个重要性能指标:召回率 (recall)和准确率(precision)来进行测试与比较。两者的定义如下[13]:
定义8 召回率:服务匹配返回的结果中,正确匹配的服务数量与服务库中满足匹配请求的服务数量的比值。
定义9 准确率:服务匹配返回的结果中,正确匹配的服务数量所占的比值。
在5组实验中,取100次匹配结果的平均值进行比较,结果如图5和图6所示。

图5 服务匹配性能 (召回率)比较

图6 服务匹配性能 (准确率)比较
从实验结果可知,两种方法在匹配性能上几乎没有差别,这是因为两种方法采用了相同的匹配规则。由该结果可表明,基于公共本体概念库的语义匹配方法,不会对语义匹配的性能产生影响。
5 结束语
语义匹配是SOC&SOA 的基础技术之一,在服务发现、匹配、组合及验证等多个环节都会涉及,并增大了技术实现的难度。本文的研究工作从分离语义匹配的角度展开,通过对语义匹配关系的研究,提出建立公共本体概念库,保存本体概念及匹配度信息,从而实现了语义匹配的分离。这种方法不会因为顾及与其它环节的融合,而影响语义表达和匹配的准确性,同时也不会因为语义匹配的时间消耗而影响其它环节的效率。
进一步的研究工作包括:①研究本体概念之间的可替换性;②通过理论分析与实验两种手段,找寻合适的本体概念推理机完成建库过程;③研究基于其它理论基础 (如信息论、语义距离)的语义匹配技术的分离方法。
[1]Ishikawa F,Katafuchi S,Wagner F,et al.Bridging the gap between semantic Web service composition and common implementation architectures[C]//Proc of the International Conference on Services Computing,2011:152-159.
[2]Martino BD.Semantic Web Services discovery based on structural ontology matching [J].International Journal of Web and Grid Services,2009,5 (1):46-65.
[3]Klusch M,Kaufer F.WSMO-MX:A hybrid semantic Web service matchmaker[J].Web Intelligence and Agent Systems,2009,7 (1):23-42.
[4]Pukkasenung P,Sophatsathit P,Lursinsap C.An efficient semantic Web service discovery using hybrid matching [C]//Proc of the International Conference on Knowledge and Smart Technologies,2010:49-53.
[5]Mye Sohn,Young Min Kwon,Hyun Jung Lee.Context-based hybrid semantic matching framework for e-mentoring system[C]//Proc of the International Conference on Network-Based Information Systems,2012:691-696.
[6]YANG Yanping.Research on key technologies of automatic Web services composition [D].Changsha:National University of Defense Technology,2007:30-42 (in Chinese).[杨艳萍.自动服务组合关键技术研究 [D].长沙:国防科技大学,2007:30-42.]
[7]Xie Lingli,Chen Fuzan,Kou Jisong.Ontology-based semantic Web services clustering [C]//Proc of the International Conference on Industrial Engineering and Engineering Management,2011:2075-2079.
[8]CHEN Ke,WANG Jiayao,XIE Mingxia,et al.Research on geo spatial Web services classification based on manifold learning[J].Geomatics and Information Science of Wuhan University,2013,38 (8):324-328 (in Chinese). [陈科,王家耀,谢明霞,等.利用流形学习进行空间信息服务分类 [J].武汉大学学报信息科学版,2013,38 (8):324-328.]
[9]Papazoglou MP.Web service:Principles and technology [M].London:Prentice Hall,2008.
[10]Stanford Center for Biomedical Informatics Research.OWL concepts file [EB/OL]. [2012-11-16].http://protege.cim3.net/file/pub/ontologies/.
[11]Sean Bechhofer.OWL concepts file [EB/OL]. [2012-11-16].http://owl.man.ac.uk/2006/07/sssw.
[12]W3C.OWL concepts file [EB/OL] .[2012-11-16].http://www.w3.org/TR/owl-guide/.
[13]JIN Yan,WANG Zhihua.Research on semantic Web retrieval model based on reasoning and key technologies [J].Computer Engineering and Design,2013,34 (7):2585-2589 (in Chinese).[金燕,王志华.基于推理的语义网检索模型及关键技术研究[J].计算机工程与设计,2013,34 (7):2585-2589.]
