基于本体知识推理的QoS区分服务策略精化方法
2014-12-23黄寥若沈庆国张高明贾连祥
黄寥若,沈庆国,张高明,贾连祥
(1.解放军理工大学 通信工程学院,江苏 南京210007;2.中国人民解放军66287部队,河北 易县074200)
0 引 言
在基于策略网络系统 (policy-based network system)中,如何将高层近自然语言描述的策略,精化分解为底层可执行策略,一直是研究的热点之一。其中比较受到认可的方法有,基于目标需求分解的精化方法、专家系统方法等。在目前的研究成果中,策略精化方法普遍缺少自动推理机制,仍然需要较多的人工干预,大大制约了策略精化的自动化水平。部分学者提出将本体知识系统引入策略网络管理,利用本体良好的语义表达能力和知识推理能力实现策略的自动精化,然而,如何设计并实现本体驱动的策略精化机制却始终未能得到解决。本文在以往研究成果的基础上,针对QoS区分服务的具体应用环境,对策略元素进行了语义描述,利用本体知识推理实现了策略的精化过程,并利用实验对该方法进行了验证,表明了该方法的有效性。
1 背景知识介绍
策略精化是指:为了满足策略的可执行性,将近自然语言描述的高级策略,自动分解和细化为设备可执行的底层策略,从而对设备进行管理的方法。如何自动化的实现策略精化,减少管理员的干预,一直是基于策略网络系统领域的研究热点之一,也是制约该系统广泛应用的主要因素之一。2004年,Bandara和Lupu等提出了基于目标需求分解 (KAOS)的策略精化方法,之后部分学者提出利用线性时态逻辑 (linear temporal logic)和事件积分 (event calculus)来实现目标和事件的形式化描述[1],使得该方法成为了传统方法中使用较为广泛的一种。但是,该方法在目标分解阶段需要较多的专家知识,实现起来比较复杂和繁琐,并且缺少工具支持,制约了该方法的实用性。Antonio Guerrero等人在文献 [2]中提出了将本体引入策略精化过程的方法,阐述了使用本体知识推理实现策略精化的优势和基本思路。但是,作者并没有给出通用的网络本体模型,也没有描述如何实现本体驱动的策略精化机制。之后,Cataldo Basile等在文献 [3,4]中对本体精化机制进行了研究,在安全管理领域,实现了对于安全管理策略的本体精化。但是作者提出的本体模型和实现机制均是基于安全管理域的特定知识,很难应用于其他场景。而Farhad Mardukhi等学者则在文献 [5]中提出了利用策略精化机制实现动态服务的方法,研究了本体精化机制如何在面向服务的系统中工作。至于使用本体对其他领域策略的精化方法研究,例如在QoS 中的策略精化,则未受到广泛的关注。
实现策略精化的难点主要在于,首先,缺少一种统一的知识表示方法,使得系统和系统用户对网络知识缺少准确一致的认识,限制了策略作用的范围,割裂了不同层次间策略之间的联系;其次,高层策略与底层策略之间缺少映射和推理机制,使得策略的精化过程需要较多的人工干预。将本体引入策略控制系统,可以在一定程度上解决上述问题,本体是共享概念模型的明确的形式化规范说明[6],它不仅可以为系统知识提供统一,规范的形式化描述,还能够对知识之间的关系和约束等隐性关系进行刻画,从而使系统知识具备丰富的语义。本体知识推理,是在本体知识的基础上,借助相应的推理规则,在推理引擎的帮助下,推理出新的本体知识,并对原本体进行更新的过程。网页本体语言 (Web ontology language,OWL)是目前广泛使用的本体描述语言,能够在语义Web 规则描述语言 (semantic Web rule language,SWRL)的配合下,进行基于概念和规则的推理。
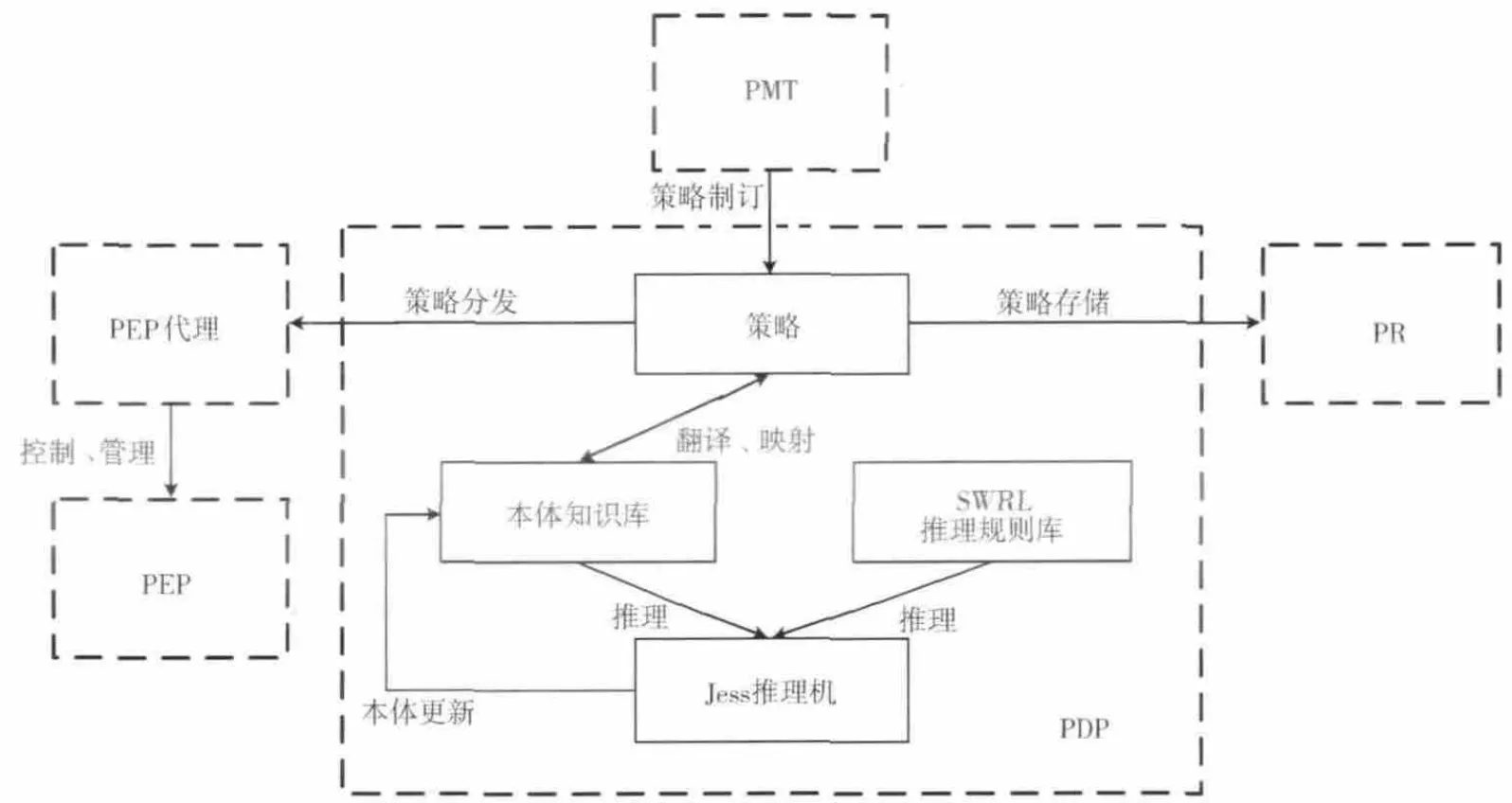
图1 本体知识推理的总体框架
通过对之前研究成果的对比和总结,本文提出了一种基于本体知识推理实现策略精化的方法。该方法利用本体对策略行为进行语义刻画,使得策略行为具备执行的前提与效果,使得行为可以根据目前的环境条件决定是否执行,而环境可以根据行为的执行结果进行更新,从而可以根据系统状态和高层抽象行为,确定底层可执行行为。这种方法与之前的方法相比,通过本体知识推理,提供了一种高层策略到底层策略的自动映射机制,提高了自动化程度;同时,由于对于策略行为的语义刻画是分布式的,不需要系统的设计者具备完备的领域知识,而是可以通过多个专家或团体的协作,来完成知识库的构建,减少了对于领域专家知识的依赖。
2 系统总体设计
IETF和DMTF提出了PBNM 的基本模型,这一模型由策略决策点 (policy decision point,PDP),策略执行代理 (policy enforcement point agent),策略执行点 (policy enforcement point,PEP),策略管理工具 (policy management tool,PMT),策略库 (policy repository,PR)和连接以上各个部分的通信协议组成。本文所利用的本体模型主要存在于PDP中,研究的策略精化机制,也主要在PDP中实现,在本文的研究过程中,我们利用protégé进行本体建模,利用Jess推理机进行知识推理。其中,protégé是由斯坦福大学开发的本体建模工具,Jess是由美国Sandia国家实验室开发,利用Java编写的SWRL 推理机。系统的总体框架如1所示。
用户在PMT 中生成策略之后,高层策略首先被映射到本体知识库,其中本体知识库是对系统知识及策略知识的本体建模,然后根据SWRL 推理规则库中预先定义的策略精化规则,在Jess推理机的帮助下进行知识推理,得到新的本体知识,从而更新本体,然后将新的策略本体翻译为底层可执行策略,进行策略存储和策略分发。本文研究的重点在于,如何建立合适的规则,在PDP中推理机制的帮助下,实现策略的自动精化过程。
3 对策略行为进行语义描述
策略精化过程的关键在于找到一组合适的底层行为集,使之执行的结果能够满足高层策略的需求[7]。然而,在不同的应用层次上,对于策略行为的理解往往是不同的。例如在业务层次上,高层策略的形式往往是以用户需求的形式表达的,如SLS,策略行为则是蕴含了具体服务指标的抽象行为,而在IP承载层次上,策略行为是具体的、能够被网络设备识别和执行的具体操作。因此,在本文的研究中,主要对底层策略行为进行语义描述。
根据上述要求,对策略行为的语义刻画主要包括3个方面:“行为作用类”(ReactClass),“执行条件”(PreCondition)与 “执行效果”(PostCondtion)。
其中行为作用类指示的是策略行为作用于哪种对象,如数据流,数据包,被管设备等,指示了策略行为的作用粒度。执行条件指示的是,策略动作能够被执行的必要条件,通过对动作执行条件的定义,使得系统能够从当前状态和目标状态2个方面,判断一个动作能否被执行,以及在何时被执行,确保了底层策略动作执行顺序的正确性。执行效果指示的是,策略行为在执行之后,系统或者服务对象的属性及状态变化,通过对执行效果的定义,使得可以通过评估动作的执行效果,来判断高层策略是否被满足,以及是否有新的动作被触发。通过对执行条件和效果的定义,可以据此判断不同动作间的组合、分解、关联等关系。需要注意的是,执行条件和执行效果是基于网络管理领域的基本知识与基本机制,与策略客体和服务对象的具体状态无关,因此在对策略行为进行语义刻画时,不涉及具体的参数和数值。由于SWRL 具有良好的逻辑表达能力,并能在本体知识推理过程中作为规则匹配,因此本文中采用SWRL对策略行为进行描述。
SWRL规则的一般形式是 “前提→结论”,其中前提是若干个一元谓词和二元谓词的和,当所有的谓词判断为真时前提才为真,同时结论为真。SWRL 规则中的谓词,均来源于本体模型中定义的类和属性,形式为class(?c)和property(?c,?p),其中class和property分别为类名和属性名,“?c”代表的是某个非确定实例,当利用该规则进行推理时,则推理机将对所有实例分别匹配该规则。例如对setDSCP行为的语义描述如下:

这条SWRL 规则的意义是:如果数据包的类型和某PHB适用的类型相同,则为数据包打上该PHB 的标记。在以上例子中,并不涉及具体的PHB,也不涉及数据包具体的类别,只是对它们之间的关联关系进行了描述,因此这条规则实际上是对setDSCP 动作的抽象和总结。在实际推理中,系统将遍历所有的系统实例,根据实际的需求,生成具体的数值,因此,策略行为的语义描述规则将对策略行为的定性分析和定量分析区分开来,使得描述规则可以在策略精化系统中得到重用。
4 策略精化的实现机制
进行高层策略的精化,首先需要将策略行为分解和细化为设备可以理解和执行的底层行为,然后,需要根据高层策略的要求和服务对象的属性,确定使用哪些底层行为。通过对相应的行为编辑正确的执行前提与效果,可以建立对象属性和采取动作之间的联系,因此,可以在推理的过程中,自动匹配出需要执行的正确行为。
4.1 策略动作的分解
通过定义策略动作的执行条件和执行效果,为策略动作之间的比较和关联创造了条件,由以上的例子可以看出,对于一个底层动作的语义定义主要包含3 个部分,因此,可以将底层动作表示为以下逻辑表达式
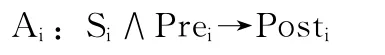
其中Ai表示策略行为,Si表示行为作用类的谓词表达式,Prei和Posti为若干谓词表达式的集合,其中 “∧”表示谓词表达式的与,“→”表示逻辑推出。
在此我们有如下定义:
定义1 动作的并行执行:若有Ai:Si∧Prei→Posti,Ai:Si∧Prei→Posti,且有Si∧Sj∧Prei∧Prej→Posti∧Postj,则称2个动作Ai和Aj可以并行执行,以符号 “∪”表示。
该定义的意义是:如果2个动作可以并行执行,那么2个动作的执行条件为它们执行条件的和,执行效果为它们执行效果的和。
定义2 动作的串行执行:若有Ai:Si∧Prei→Posti,Ai:Si∧Prei→Posti,且Si∧Sj∧Prei→Postj,则称2个动作Ai和Aj可以串行执行,以符号 “∩”表示2个动作的串行执行,
该定义的意义是:如果2个动作可以串行执行,那么2个动作的执行条件为其中一个动作的执行条件,执行效果为另一个动作的执行效果。
此外还需要对谓词逻辑表达式间的关系进行定义:
定义4 行为作用类间的关系:以符号 “∈”表示2个行为作用类的关系,有2个行为作用类Ci,Cj;当且仅当Ci为Cj的子类时,Ci∈Cj。
由定义4可以得出如下定义:
定理 若有Ai:Si∧Prei→Posti,若有Si∈Sj,则Sj∧Prei→Posti亦成立。
该定义的意义是:如果一个动作作用在某个类上,那么它一定也作用在该类的父类上。
根据以上定义,若有3 个不同的策略行为A1,A2,A3,则可得到以下动作细化规则。
规则1:S1∈S3,S2∈S3,Pre1,Pre2,Post1,Post2两两没有包含关系,且有Pre3=Pre1∧Pre2,Post3=Post1∧Post2,则有A3=A1∪A2。
证明:由对动作的定义可得A1:S1∧Pre1→Post1,A2:S2∧Pre2→Post2,又因为Pre1,Pre2,Post1,Post2两两没有包含关系,所以A1∪A2:S1∧S2∧Pre1∧Pre2→Post1∧Post2(*)成立;又因为S1∈S3,S2∈S3,所以S1∧S2∈S3;又有Pre3=Pre1∧Pre2,Post3=Post1∧Post2,所以由定理5,(*)式即为S3∧Pre3→Post3,即A3=A1∪A2,证毕。规则1的有向图如图2所示。
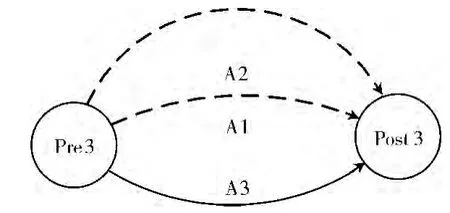
图2 规则1有向图
该规则的意义为,某个高层动作可以分解为若干个并行执行的底层动作,例如在访问控制策略中,当高层策略为 “禁止外部用户访问服务器”,则该策略可以分解为底层的若干条具体的访问控制策略,如 “禁止源地址在10.1.1.0/24网段的用户访问服务器”等,这些策略中的动作通过并行执行,达到高层的策略的访问控制目标。
规则2:S1∈S3,S2∈S3,且有Pre3=Pre1,Post3=Post2,Pre2Post1,则有A3=A1∩A2。
证明:因为A1:S1∧Pre1→Post1,所以S1∧S2∧Pre1→Post1∧S2,因为Pre2Post1,则可得Post1∧S2→Pre2∧S2→Post2,即A1∩A2:S1∧S2∧Pre1→Post2(*)成立;又S1∈S3,S2∈S3,所以S1∧S2∈S3;又因为Pre3=Pre1,Post3=Post2,则 (*)即为S3∧Pre3→Post3,即A3=A1∩A2,证毕。规则2的有向图如图3所示。
该规则的意义为某个高层动作,可以分解为若干个串行执行的底层动作,例如在QoS服务策略中,高层策略为“保证语音流量F的吞吐量不少于520kbps”,则该策略可以分解为底层的标记策略和资源分配策略,如 “将语音流F标记为EF”, “为目标流F分配520kbps带宽”等。这些策略中的动作通过顺序执行,达到高层策略的性能目标。
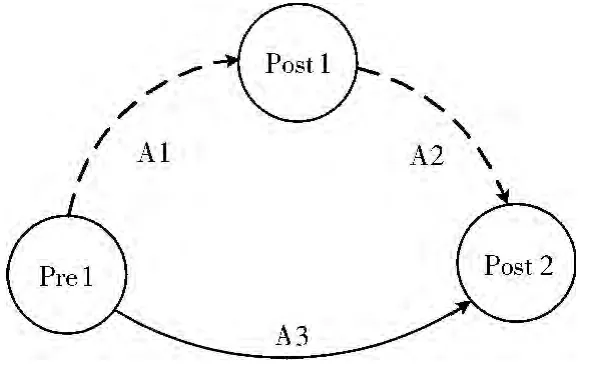
图3 规则2有向图
通过以上2条规则,可以基本完成对于系统中策略动作的细化,但是为了满足高层策略的需求,如SLS等,则还需要对细化后的动作进行筛选,从而组织正确的底层动作序列,使之执行的效果,能够满足高层策略的需求。
4.2 策略动作的筛选
将策略动作进行细化之后,则需要根据服务的属性和流量的需求,挑选正确的动作,利用SWRL 规则进行策略精化的核心在于,根据高层用户需求和服务属性,与行为规则的前提进行匹配和推理,从而筛选出正确底层行为的过程。策略精化算法流程如图4所示。
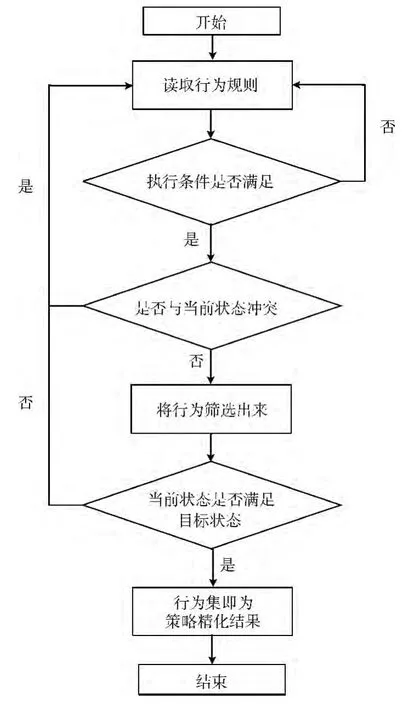
图4 策略精化算法流程
在策略精化的过程中,输入行为规则,根据当前的系统状态,资源需求,对象属性等,筛选可以被执行,并且不与当前系统状态相冲突的行为,并根据行为的执行结果,对系统状态和对象状态进行更新,进而判断选取的行为集是否满足用户需求,直到所有可执行的策略行为被挑选出来之后,策略精化过程结束。
通过4.1的行为分解,确保了挑选出来的策略行为都是可以被底层设备理解和执行的,则可设如下集合,其中集合中的元素是包含了具体对象实例和数值的谓词表达式:系统状态集合S (S1,S2,…,Sn),其中Si为系统的某个属性,如可用资源,用户数量等;对象属性集合F (F1,F2,…,Fn),其中Fi为服务对象的某个属性,如应用类别,服务端口等;用户需求集合R (R1,R2,…,Rn),其中Ri为SLA 中规定的资源和需求,如带宽供应,突发速率等;底层动作集合A (A1,A2,…,An),其中Ai为4.1中经过分解和细化的底层行为;对象状态集合P (P1,P2,…,Pn),其中Pi为服务对象的当前状态,如流量的标记,被分配的资源等;目标行为集合 A* (A1,A2,…,An),其中Ai为筛选出来,可以满足高层策略需求的底层行为。各个集合中的元素为在本体中定义的对象实例或具体数值,可以代入谓词表达式中进行判断。
定义5 若有Sj,Fj,Rj满足Prej,使得Aj:Prej∧Sj→Postj成立,则Aj被筛选出来,Pj为Postj中推理得出的对象属性值,则Pj∈P。
该定义的意义是:若存在集合S、F、R 中的元素,使得Aj的执行前提为真,则Ai被加入集合A*,同时Posti中的PJ被加入集合P。
定义6 若对于状态集合P 均为真时,用户需求R 可以被满足,则称P能满足R,记为P→R;
该定义的意义是:当P能满足R 时,若对象的属性与P中的元素一致时,对服务对象的服务水平可以满足用户需求。
则根据定义5和定义6,可以得到以下结论:
结论:若存在一个行为集合A’,通过执行A’中的所有行为,可以使得P能满足R,则必有A’A*;
该结论的意义是:若存在一个行为集合可以满足用户需求,那么一定包含在算法选出的行为集A*中。
证明:设行为集合A+=A-A*,则根据定义5,A+中的行为在当前状态下不具备执行的条件,或与系统参数和状态冲突。则假设存在A’,使得P能满足R,同时至少存在Ak∈A’,同时Ak∈A+且AkA*,则根据算法,Ak不能被执行,因此与题设矛盾,假设不成立。
通过以上结论可以得出,若存在行为集合能够满足用户的目标,则必可以通过该算法找出该行为集合。
4.3 策略执行主体的确定
在本文的研究过程中,我们将某个设备在网络中所处的位置和所起的作用,抽象为 “角色”概念,通过角色概念,一方面可以向系统屏蔽具体的被管对象的细节,使得对于系统的管控更加方便;另一方面,可以在具体的策略行为执行主体和策略行为之间建立联系。在对于策略行为的语义描述过程中,还需要将策略行为与行为的执行角色之间建立联系,这一联系的依据是某个行为是由某一类设备执行的,例如QoS的标记行为,则通常是由边界节点执行的,则可以在标记行为和边界节点之间建立联系,从而在策略精化的过程中,确定策略的执行主体。
确定策略执行主体的过程如图5所示。
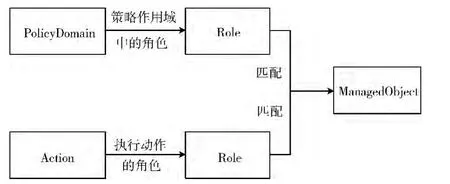
图5 主体确定方法
该过程表示了,对于某个行为,我们可以找到它的执行角色。在策略作用域中,由于设备所处的不同位置,或发挥的不同作用,可以确定某个设备的角色。将两者匹配,则可以通过策略行为,找到具体的被管对象,以及它的引址或IP地址。
5 本体知识库的建立
本文应用OWL语言进行本体建模,在OWL 中共定义了以下几种概念:类,属性,实例,约束。其中类是对某个对象的抽象描述,使用owl:Class来定义一个类。属性有2种,一种为对象属性,描述的是2 个类之间的关系,使用owl:ObjectProperty来定义对象属性;另一种为数据类型属性,描述的是一个类与某个具体数值的关系,使用owl:DatatypeProperty来定义数据类型属性。约束有属性约束、个数约束等,它用来描述类的具有个数或属性的约束条件,定义形式有owl:allValuesFrom,owl:maxCardinality等。下文利用UML图对本体模型进行描述,需要指出的是,为了简单起见下文仅对骨干类别和属性进行了描述,在实际使用中,需要根据具体的应用对模型进行扩展和细化。
在文献 [8]中,对于ECA 策略的建模方法及内容进行了研究。本文依据该建模方法,将本体模型分为3个部分:策略模型、环境模型、领域模型。策略建模依据的是PCIM 及PCIMe策略模型,对策略,策略规则,策略构件和策略组等进行了描述,定义了策略的基本结构和组成方式,其中不包含任何特定域的知识,从而使得策略知识可以在多个应用场景中得到重用。
策略本体模型如图6所示。
环境建模依据的是实际应用场景中的网络元素、概念、事件等,对网络环境中的具体概念,逻辑实体,被管对象等进行了描述,定义了网络的上下文信息,是整个本体知识库的基础部分,其中的概念,可以被其他模型作为组件调用。
环境本体模如图7所示。

图6 策略本体模型
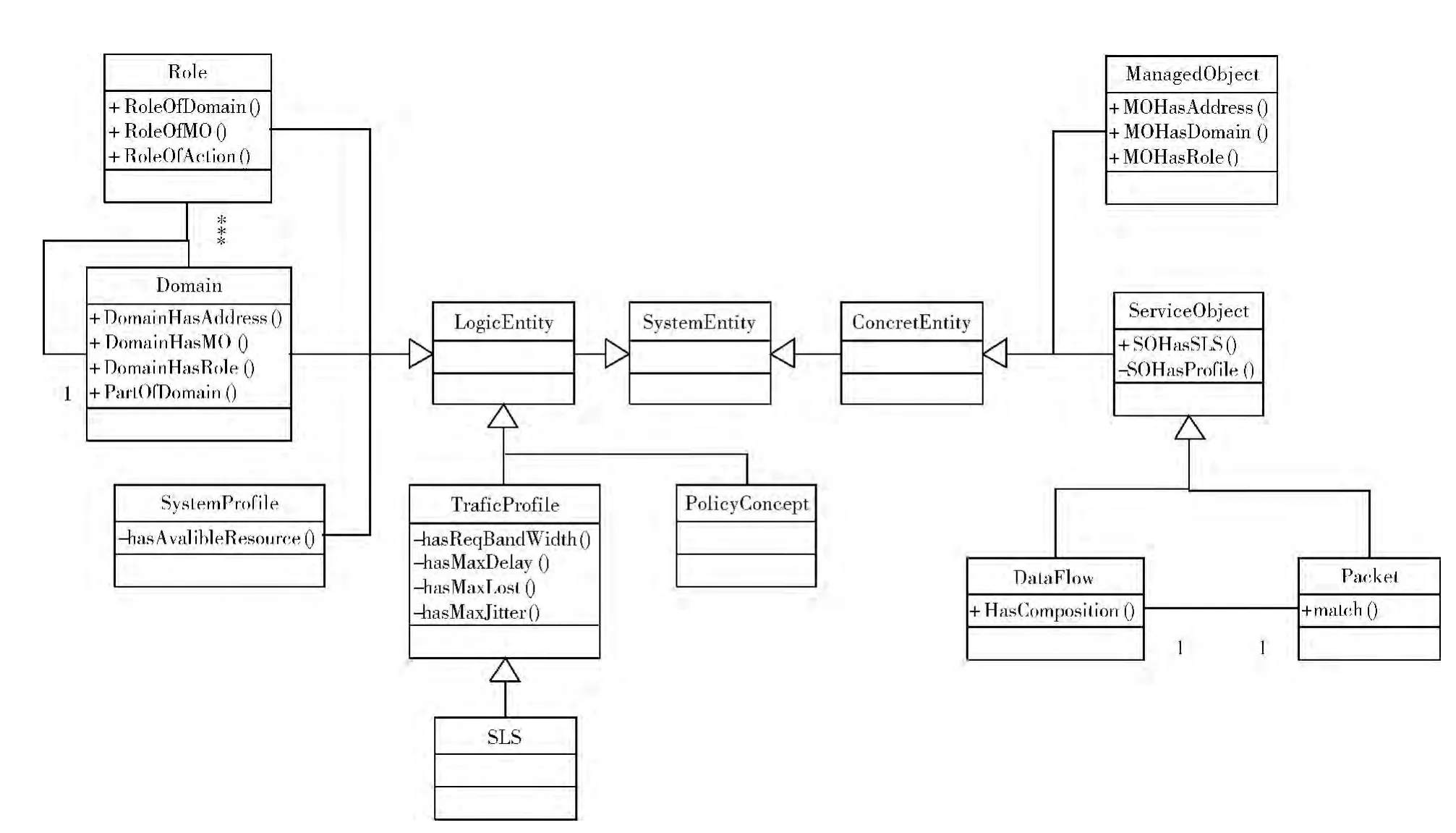
图7 环境本体模型
其中领域建模依据是QoS区分服务的领域知识以及QPIM 模型,根据QoS应用场景中的具体知识,刻画了在QoS区分服务领域内的知识[9],如QoS 的需求,行为,事件等,领域模型可以看作是前2 个模型的继承与扩充。
领域本体模型如图8所示。

图8 领域本体模型
在实际的使用中,需要将以上3个模型相互融合和链接,形成一个统一的本体知识库,从而在具体的环境中得到使用。
6 实验验证
对于上述策略精化机制,利用JAVA 在eclipse中进行了软件实现,利用protegeAPI基本实现了设计的功能,并编写了相应的测试环境,测试了该精化方法的执行效率。在实验中,以实时语音业务的QoS 策略为例,对签订的SLS高层策略进行了策略精化[10]。
在实验中,为了简单起见,仅对SLS中的吞吐量,丢包率,时延等指标进行了体现。以下是一个高层SLS策略的例子:

PolicyName:HighLevel_SLS ServiceObjectAttribute:SourceIP:1.1.1.1 DestinIP:2.2.2.2 SourcePort:21 DestinPort:22 Protocol:UDP ValidTime:12:00<currentTime<23:00 Application:VoIP ServiceIndex:Throughput:>=4000000bps Delay:<=0.1s Lost:<=0.1%
通过改变SLS中的指标要求,生成多条高层策略,并将这些策略导入如下策略精化测试环境中。策略精化的测试环境为Intel Core Q8400 2.66Ghz,3G 内存计算机,并利用路由器搭建简易网络,对底层策略的正确性和可执行性进行了验证。
软件测试环境如图9所示。

图9 软件测试环境
由高层SLS策略生成的底层可执行策略首先存储在本体知识库中,作为本体知识的一部分,可以利用protégé等工具进行查看,修改和调用,并能够以PonderTalk 等策略描述语言的形式输出。策略精化过程结束后,可以通过查看本体中ServiceObject类的属性,确定对于服务对象的资源分配是否满足要求,从而确定策略求精的结果是否正确,同时,将生成的策略应用与搭建的简单网络中,证明了策略精化结果的正确性,说明了本文研究的精化方法满足了策略精化过程,对于“保证策略精化正确性可检验”的要求。
策略精化效率如图10、图11所示。
通过实验,可以证明本文设计的策略精化算法,首先,可以通过本体知识推理得到正确的底层策略;其次,策略精化过程的效率能够满足大多数应用的需求;最后,生成的底层策略可以以多种形式输出,具有较好的灵活性。
7 结束语

图10 策略精化总体用时

图11 策略精化平均用时
本文研究的策略精化方法,在对策略和网络知识进行统一定义的基础上,利用知识推理机制,使得策略精化过程实现了自动化,基本满足了策略精化的实际需求。
在利用规则进行知识推理的过程中,需要对全体规则库中的规则进行一一匹配,这样的机制导致了不必要的计算开销,下一步的研究过程中,可以对规则推理过程进行一定的筛选,减少系统的算法复杂度。同时,为了使策略系统能够在较广泛的应用领域中得到应用,一个完备的本体知识库是必不可少的,因此,本体知识库还需要进一步的补充和完善。
[1]Rubio-Loyola J,Serrat J,Charalambides M,et al.A functional solution for goal-oriented policy refinement [C]//Seventh IEEE International Workshop on Policies for Distributed Systems and Networks.IEEE,2006:133-144.
[2]Guerrero A,Villagra VA,de Vergara JEL,et al.Ontologybased policy refinement using SWRL rules for management information definitions in OWL [G].LNCS 4269:Large Scale Management of Distributed Systems.Berlin:Springer Berlin Heidelberg,2006:227-232.
[3]Basile C,Lioy A,Scozzi S,et al.Ontology-based security policy translation [J].Journal of Information Assurance and Security,2010,5:437-445.
[4]Basile C,Lioy A,Scozzi S,et al.Ontology-based policy translation[C]//Computational Intelligence in Security for Information Systems.Springer Berlin Heidelberg,2009:117-126.
[5]Mardukhi F,Nematbakhsh N,Zamanifar K.An adaptive service choreography approach based on ontology-driven policy refinement [J].International Journal of Web & Semantic Technology,2011,2 (2):59-76.
[6]Hu H,Ahn GJ,Kulkarni K.Ontology-based policy anomaly management for autonomic computing [C]//7th International Conference on Collaborative Computing:Networking,Applications and Worksharing (CollaborateCom),2011:487-494.
[7]Rubio-Loyola J,Serrat J,Charalambides M,et al.A methodological approach toward the refinement problem in policybased management systems [J].Communications Magazine,2006,44 (10):60-68.
[8]Romeikat R,Bauer B,Sanneck H.Modeling of domain-specific ECA policies[C]//23rd International Conference on Software Engineering and Knowledge Engineering,2011:52-58.
[9]Bandara AK,Lupu EC,Russo A,et al.Policy refinement for IP differentiated services quality of service management [J].IEEE Transactions on Network and Service Management,2006,3 (2):2-13.
[10]Djarallah NB,Pouyllau H.Algorithms for SLA composition to provide inter-domain services [C]//IFIP/IEEE International Symposium on Integrated Network Management,2009:460-467.
