决策树C4.5算法在客户分类中的应用研究
2014-12-18杜丽英
杜丽英
(吉林建筑大学 计算机科学与工程学院,长春 130118)
0 引言
随着数据库技术的广泛应用和数据库管理系统的普及,现在各行业使用的信息系统尤其是国内金融部门使用的大多数业务处理系统都是基于数据库的,能够实现业务数据的录入、查询、更新、统计等功能,并将与业务相关的数据存储在数据库中。数据库存储中的这些大量数据往往隐含着重要信息,如果对其进行深入的分析,挖掘数据背后隐藏的信息,发现大量客户数据中潜在的关联和规则,以此对未来的发展趋势做出预测,从而在企业的管理和决策中发挥重要作用。数据挖掘就是从大量的数据中提取出隐藏在其中的,有应用价值的信息和规则的过程。
客户关系管理(Customer Relationship Management,CRM)是一种以客户为核心的经营理念,通过不断完善客户的服务来实现企业利润的增长。即通过客户信息的分析处理,不断改进客户业务流程,满足客户需求,为客户提供所需要的服务等手段来实现客户和企业利润的增加,提高对客户的营销能力,从而实现客户和企业的相互的利益满足。客户分类是CRM中一个重要方面,而决策树方法是分类分析的常用工具。
决策树是数据挖掘技术中常用的分类方法,将挖掘的结果以树形结构的图形方式体现出来,具有结构简单,易于理解,效率高等优点。决策树分类挖掘技术广泛应用于各行业的客户关系管理系统中,通过对客户相关信息的分析,对客户所属的类别进行预测,从而采取相应的措施和服务策略,提高服务水平和工作效率,从而得到较大的收益。
1 决策树C4.5算法
1.1 C4.5算法
决策树在数据挖掘领域因其分类预测的准确率较高、直观易于理解等特点,广泛应用在各领域。决策树算法比较多,不同算法创建的决策树的性能也各有所不同,ID3和C4.5算法是决策树方法中最有影响力的算法,主要进行数据分类划分的处理。C4.5算法是ID3算法的改进和扩充。ID3算法只能对连续型属性数据进行处理,而C4.5算法既可以处理离散型属性数据,也能够对连续性属性数据进行处理。
C4.5算法构造决策树时选择分支节点属性的依据是信息增益率。ID3算法中节点属性的选择标准是信息增益的大小,因为有较多取值的属性具有较大的信息增益的特点,ID3算法节点属性的选择侧重于取值较多的属性[1]。而C4.5算法以信息增益率为属性节点的选择依据,克服了ID3算法的倾向于选择取值较多的属性的不足。
1.2 C4.5算法的处理过程
C4.5算法的详细步骤如下:
步骤1:若数据集中的有连续型属性,需要离散化处理。进行离散化数据预处理后,进行根节点属性的选择。计算数据集中所有属性的信息增益率,选择其中的最大值的属性作为根节点属性。
1)计算数据集分类的信息期望I。设S为有n个实例的数据集合,依据实例所属的类别,集合S有m种划分{S1,S2,…,Si,…Sm},每种划分的实例数目为ni,pi=ni/n是Si类出现的概率。将集合S划分为m个类别的信息熵或信息期望[2]为:

2)计算非类别属性A的信息期望I(A=aj),j=1,2,…,v,即属性A有v个取值,将S划分为v个子集{D1,D2,…,Dv},Dj为A=aj时的子集,Dj的实例数为dj,Dj子集中属于Si类的实例数为dij,属于第i类的概率为pij,pij=dij/ dj,信息期望I(A=aj)为:

当A=aj时的概率为pj=dj/n,利用属性A的取值进行划分子集的期望信息,即A的熵为:
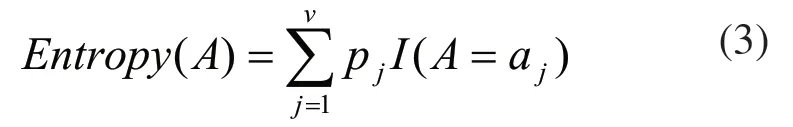
属性A在进行分类划分时提供的信息量,称作属性A的信息增益,记为Gain(A):

3)属性A的信息增益率:
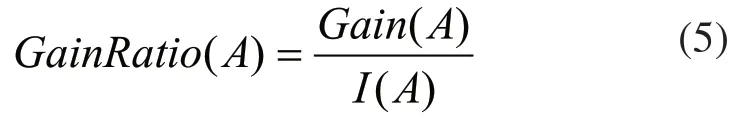
其中I(A)为属性A的取值划分集合S的信息期望的比值
步骤2:确定节点属性后,根据节点属性不同取值建立不同的分支,而属性值的不同取值对应不同的数据子集。依此类推,对各数据子集,仍然以信息增益率最大值的属性作为作为子节点属性的选择标准[3],直到各子集的实例都属于同一类别为止,由此就能构造一棵决策树。
步骤3:提取决策规则。生成决策树后,就可以依据各分支上属性的取值获取决策规则,新数据集就可以根据决策规则进行分类预测。
1.3 C4.5算法对连续属性的处理
C4.5算法既能处理离散型属性数据,也能够对连续性属性数据进行处理[4]。若数据集中有连续型属性时,需要对连续属性的值进行离散化处理,选择分支节点属性以信息增益率作为标准。
如果某节点中数据集合T的实例中有连续型属性A,C4.5算法需进行离散化处理[5]。首先可对连续属性值进行排序,确定连续属性的最大值和最小值,采用一定的算法将整个区间划分成多个相等的子区间或以排序后的连续型属性的相邻值的均值设定子区间,然后计算该属性的信息增益率,以信息增益率的最大值为标准找到连续属性的分割点,对连续型属性的实际取值进行顺序查找确定实际的分割点[6]。具体步骤如下:
1)对节点对应的T集合上的所有实例中连续型描述属性的取值,按从小到大的顺序进行排列,得到属性A的取值的顺序排列{a1,a2,…,av}。
2)计算信息增益率。属性A的取值ai,其中1≤i≤v-1,按值a=(ai+ai+1)/2将集合T划分为两个子集:T1={ai| ai≤a}和T2={aj| aj>a},然后计算属性A按照a值划分的信息增益率。a值用区间[a1,ai],[ai,ai+1]来描述属性A的取值。
3)确定连续属性的分割点。属性A的每个v-1种划分,ai和ai+1都可看作该连续属性的2个离散取值的情况进行处理,计算每种a值划分的信息增益率,选择v-1种划分中具有信息增益率最大值的a作为连续属性的分割点。
4)确定实际分割点。在属性A的取值序列{a1,a2,…,av}中找出最接近分割点a,但又不超过它的属性A的取值ai,将ai作为属性A的实际分割点,完成对连续型属性A的离散化处理。
2 连续属性处理过程的改进
将数据集合T以属性A的值按照升序排序后,在离散化的处理过程中进行信息增益率的计算时,可将通过比较得到的信息增益率最大值和对应的分割点的序列值分别保存到变量GainMax和IndexMax中,变量的初值可设为零。当计算完所有的v-1个区间的信息增益率值时,就得到了GainMax和IndexMax值,这样能够提高效率,节省运算时间,也省略了多次顺序查找,因为如果在计算出的v-1个信息增益率中找出最大的信息增益率,又在连续型属性取值中查找最接近但又不超过属性分割点的属性A的取值ai,多次的查找会使算法的执行效率降低。
当数据集较大且连续属性值比较多时,在离散化处理时,对所有划分计算信息增益率会占用较多的时间,如何快速找到最佳划分点,即属性分割点成为解决问题的关键。根据Fayyad的研究,无论数据集类别有多少种,连续型属性所属类别分布如何,最佳划分点总是在类别边界点处,实际的分割点总是出现在边界处,因此对离散化方法可做进一步优化。具体步骤如下:
1)将该节点上的数据集合按照连续型属性的取值从小到大进行顺序排列,即A属性的取值的顺序序列{a1,a2,…,av}。
2)计算信息增益率。假设数据集合T分成两个类别,以A属性ai为边界处,即分割点,其中1≤i≤v-1,得到两个子集:T1={aj|1≤j≤i}和T2={aj| i<j≤v},计算按ai划分的信息增益率。
3)确定连续属性的分割点。假设数据集合T分成多个类别,通过类别边界处找到分割点。这里分割点可选为相邻不同类别的两个属性值中较小的一个。例如,当排序后的实例属性值为(a1,a2,…,a8),其中前2个属于类别1,中间3个属于类别2,最后3个属于类别3,a2与a3分别属于类别1与类别2,边界点在a2与a3之间,选择属性值较小的a2为分割点,因此只需考察两个分割点a2与a5而无需检查其余6个分割点。
4)确定实际分割点。计算按照属性分割点的值划分得到的信息增益率,选择信息增益率最大的属性值作为最佳分割点。
3 改进的处理过程与原处理过程的分析比较
在处理连续属性的离散化时,需要将数据集合T以连续属性A的值从小到大排序,减少了后续处理过程中排序和查找的次数,提高了确定分割点的效率。在原C4.5算法中数据集合T中属性A的值为ai(1≤i≤v-1),按值a=(ai+ai+1)/2将T划分为两个子样本集,改进的C4.5算法中直接用ai将T划分为两个子样本集,由于{a1,a1,…,av}是有序序列,用ai将T划分为两个子样本集与用a划分的效果相同。同样在计算信息增益率的过程中得到最大信息增益率和分割点序号,节省了两次顺序查找的时间,因此改进后的C4.5算法并没有改变原C4.5算法构造的决策树性质。
改进的分割点选择方法可以有效地减少信息增益率的计算次数,从而提高效率,当属性的取值越多,而所属的类别越少,性能会有明显的提高。当属性的每个取值都属于一种类别这种极端的情况出现时,改进算法与未改进算法运行次数相同,运行效率也不会降低。在未改进的算法中,需要计算所有划分的信息增益率,而在改进后的算法中,只计算边界点处的属性值的信息增益率,降低了计算复杂度。当连续型属性所属的类别较少时如只有2种类别时,改进后的算法计算效率有明显提高。当遇到极端情况时,每个属性值分别属于不同类别,改进算法的与C4.5的计算复杂度相同。
4 实验分析对比
选取UCI机器学习库中的有14条记录的weather数据集创建决策树,根据天气的情况判断是否适合打球(yes为适合,no为不适合),使用C4.5算法和改进的C4.5算法构造的决策树相同(如图1),由此可知,改进的C4.5算法与原算法有大致相同的准确率。

图1 C4.5算法与C4.5改进算法构造的决策树
在UCI机器学习库中选取4个数据集,这4个数据集中都有连续型属性值,通过数据集的测试将改进前后的算法在运算时间上进行分析比较。其中各数据集如表1所示。
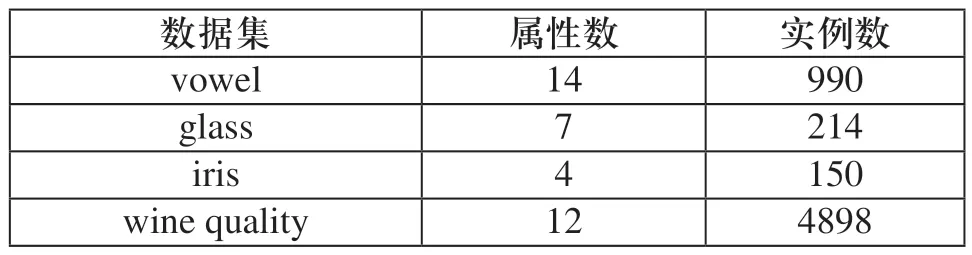
表1 数据集的属性及实例数
C4.5算法与改进的C4.5算法运算时间的对比如图2所示。
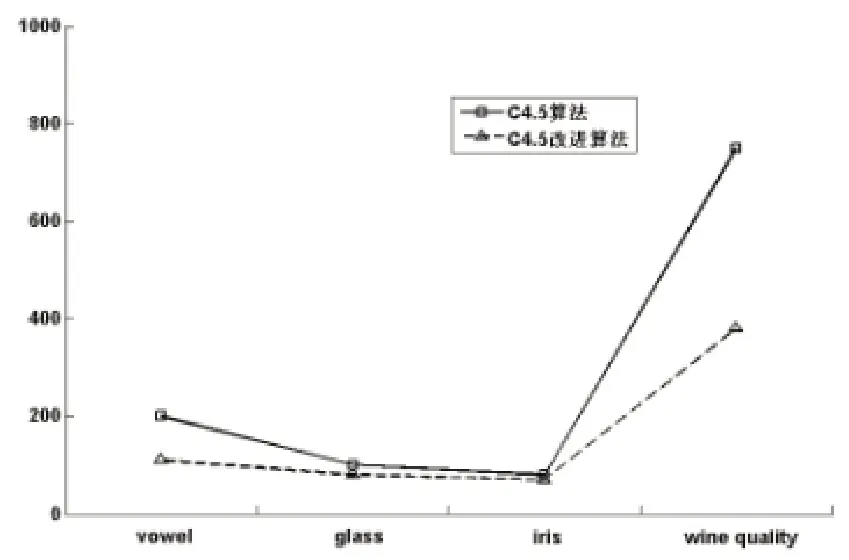
图2 C4.5算法与C4.5改进算法运算时间比较
使用数据集构造决策树所用时间,与数据集的大小及连续型属性值的多少有关。通过上述4个数据集进行测试的结果可以看出,使用改进的C4.5算法构造决策树所用的时间比未改进的算法要快,尤其在数据量较大时较为明显,对相同规模的数据集,改进的C4.5算法构造决策树所用的时间较少。
5 结束语
本文详细的分析了决策树分类算法C4.5,针对C4.5算法的连续属性离散化处理过程中需要处理所有划分情况的特点,根据Fayyad边界点判别定理,提出了尽快找到最佳划分的改进方法,算法运算速度得到了提高,改进的C4.5算法与原算法相比,在构造决策树时具有相同的准确率和较高的计算速度。
[1]姚亚夫,邢留涛.决策树C 4.5 连续属性分割阈值算法改进及其应用[J].中南大学学报(自然科学版),2011,42(12):3772-3776.
[2]黄文.决策树的经典算法:ID3与C4.5 [J].四川文理学院学报(自然科学),2007,17(5):16-18.
[3]刘耀男.C4.5算法的分析及应用[J].东莞理工学院学报,2012,19(5):47-52.
[4]冯帆,徐俊刚.C4.5决策树改进算法研究[J].电子技术,2012,39(6):1-4.
[5]乔曾伟,孙卫祥.C4.5算法的两点改进[J].江苏工业学院学报,2008,20(4):56-59.
[6]李慧慧,万武族.决策树分类算法C4.5中连续属性过程处理的改进[J].计算机与现代化,2010(8):8-10.
