视频网站的数据存储管理优化
2014-12-16郑林熇李亚洲张东方林洪生
郑林熇,李亚洲,张东方,林洪生
(沈阳工程学院a.新能源学院;b.机械学院;c.电力学院;d.基础教学部,辽宁沈阳110136)
视频网站数据存储管理遵循的原则是先存储到DC一定时间之后再按一定的策略逐级分发下去。一般而言,用户在线观看某个视频时,要尽量保证其最大概率地从距离用户最近、网络传输速度最快的VOC机房获得数据,因而需要给出一种高效的文件分发方法及淘汰方法。通常情况下VOC机房的存储容量是有限的,需要决定存储/不存储什么样的文件,以及定时或者动态地淘汰一些已经不是热点的视频数据文件。这就需要用一个快速自动的智能化数据存储策略来完成对用户所搜索的视频文件进行高效的寻找,并同时以最快的速度分配到指定的用户,因而需给出一种优化的存储方案。下面的研究工作主要从减少用户访问某个视频文件的时间,提高人们网上浏览信息的效率,同时在尽可能的为用户提供流畅的视频收看服务的前提下提高网络资源的利用率的角度来开展。
1 网络数据特征的获取
面对大量的数据,一般采用平均分析法来得到数据的一般特征。平均分析法就是利用平均指标对社会经济现象进行分析的方法。平均指标又称平均数,是反映社会经济现象总体和单位在一定时间、地点条件下某一数量特征的一般水平。
平均分析法的特点:①可以比较同类现象之间的本质性差距;②可以对某一现象在不同时间上的水平进行比较,以说明现象的发展趋势及规律;③可以分析现象之间的依存关系;④可进行数量上的推算。
平均分析法又分为算数平均法和加权平均法,所谓算数平均法,就是利用算数平均数进行分析的一种方法,下面将用这种方法来对数据进行处理。
算数平均法的基本公式:
算数平均数=标量总量/单位总量
定义周期为100天,则所阐述的表达式为:
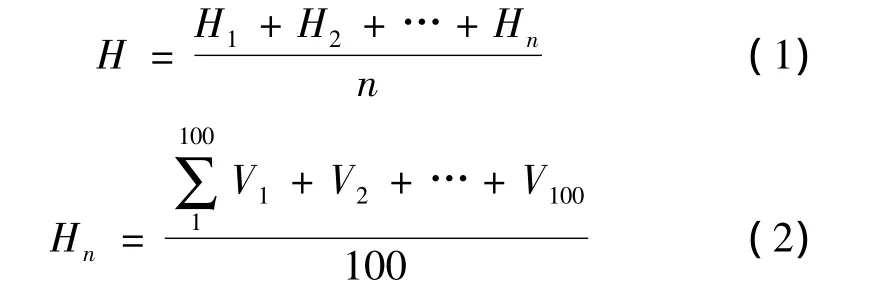
式中,H为热度,V1…V100为1到100天的访问量,n为所选取的文件个体数。
定义全部的访问均值数为文件的访问热度,下面对所给数据进行处理。通过计算可以得到各个文件的访问热度。
根据所给数据运用Matlab得到相关的数据图像,进而分析每类视频文件的一般访问特征。
根据以上图1可以得出,web数据类型的访问特征为:在1个周期之内,其最大的访问次数平均值为4.75次,最小的访问次数平均值为0.83次,总的访问均值为2.34,标准差为0.87。通过图2可以得出music数据类型的访问特征为:在1个周期之内,其最大的访问次数平均值为56次,最小的访问次数平均值为3.77 次,总的访问均值为 21.2 次,标准差为 14.97。

图1 web视频在1个周期内的访问情况
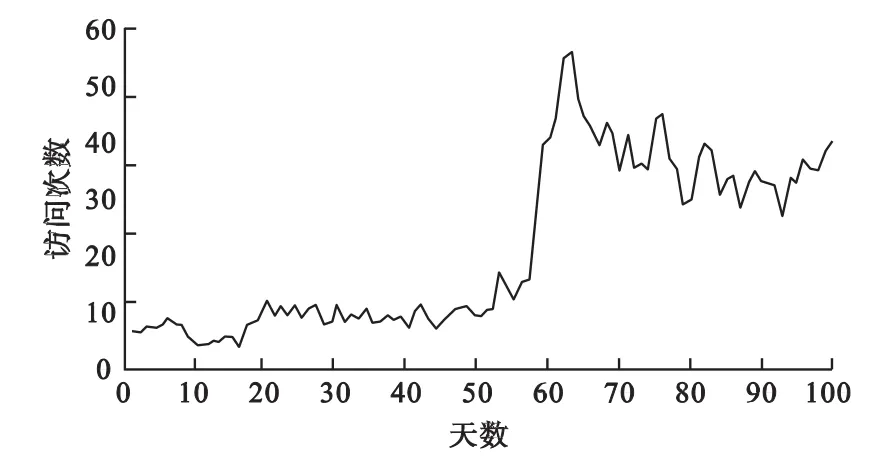
图2 music视频在1个周期内的访问情况
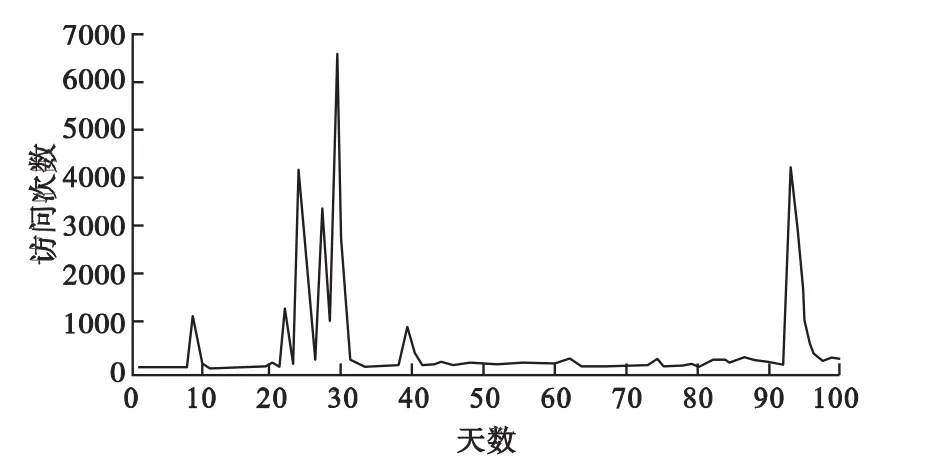
图3 vhot2视频在1个周期内的访问情况
根据图3可以得出vhot2数据类型的访问特征为:在1个周期之内,其最大的访问次数平均值为6 613次,最小的访问次数平均值为6.5次,总的访问均值为384.9次,标准差为1 011。通过图4可以看出vkp数据类型的访问特征为:在1个周期之内,其最大的访问次数平均值为5 384次,最小的访问次数平均值为3.4次,总的访问均值为258次,标准差为876.2。
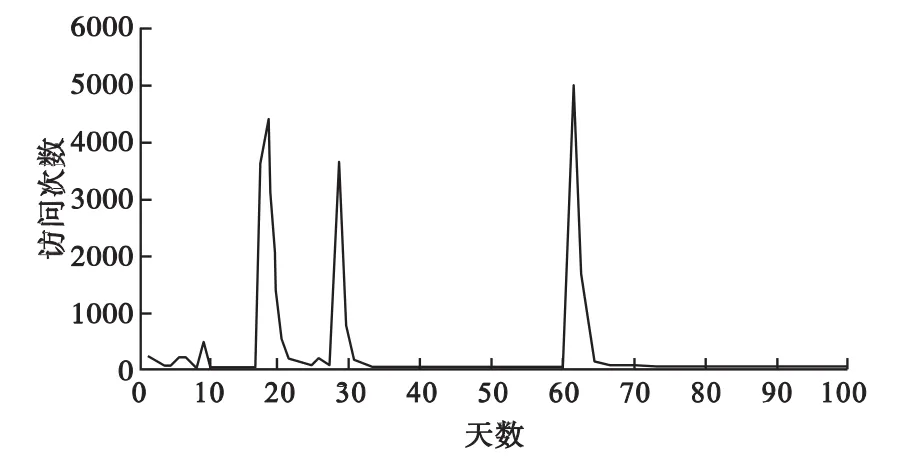
图4 vkp视频在1个周期内的访问情况
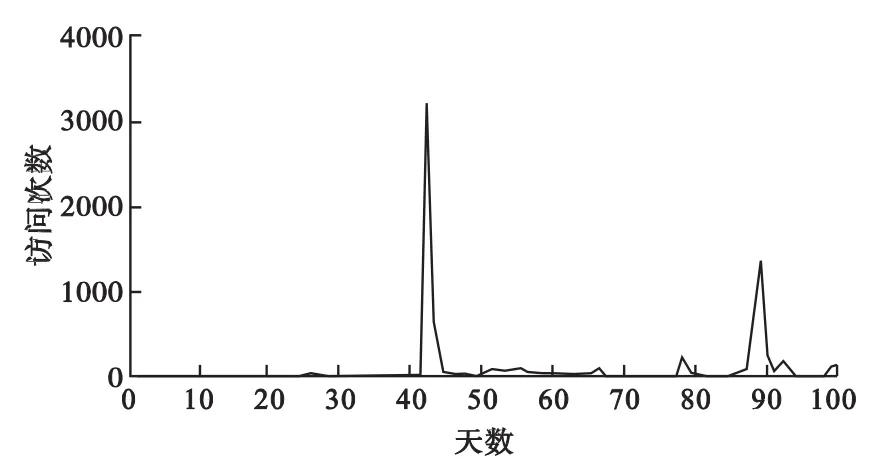
图5 vlive视频在1个周期内的访问情况
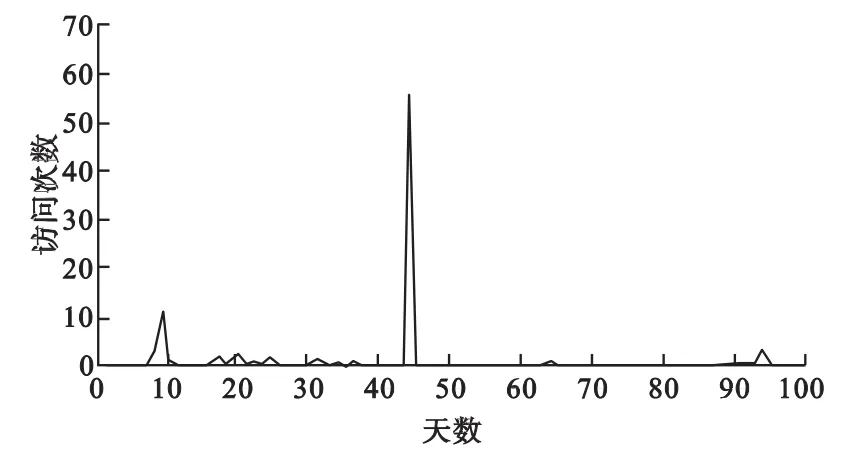
图6 vmb视频在1个周期内的访问情况
根据图5可以得出vlive2数据类型的访问特征为:在1个周期之内,其最大的访问次数平均值为3 530次,最小的访问次数平均值为2.4次,总的访问均值为93.9次,标准差为388.1。通过图6可以看出vmb数据类型的访问特征为:在1个周期之内,其最大的访问次数平均值为60.3次,最小的访问次数平均值为0次,总的访问均值为1次,标准差为6.13。
通过以上图像汇总分析,可以得到下表所示的访问特征。
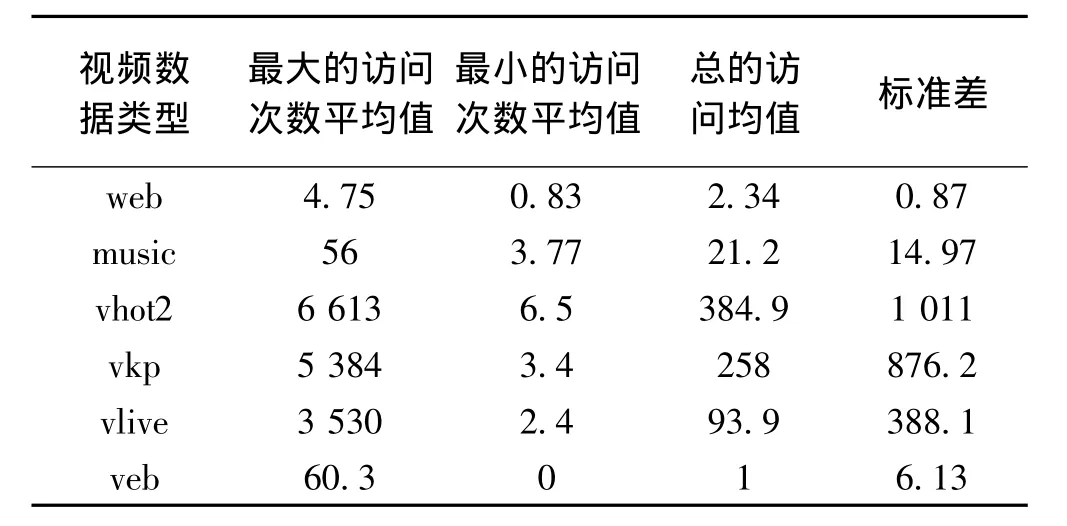
表1 各个文件的一般访问特征
通过上表可以看出,视频文件的访问热度从高到低依次为:
vhot2>vkp>vlive>music>web>vmb
其所占百分比如图7所示。
2 视频文件访问热度的预测
由于是短期的预测,因此采用时间序列预测的方法对未来若干天的视频文件的访问趋势进行分析预测。ARIMA模型又称差分自回归移动平均模型,根据各个数据的访问趋势可知下面通过建立时间序列模型来对未来若干天的访问情况进行分析。
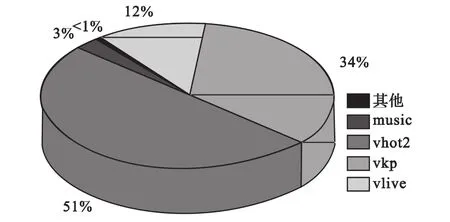
图7 各个类型视频文件访问热度所占百分比
由数据拟合图像可知,由于其预测目标的基本趋势是在某一水平上下波动,所以可以用一次移动平均方法建立预测模型,即
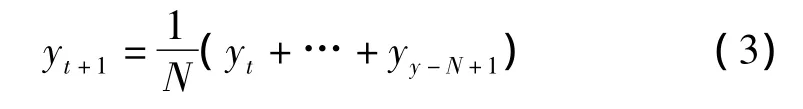
式中,t=N,N+1,…,T
其预测的标准误差为
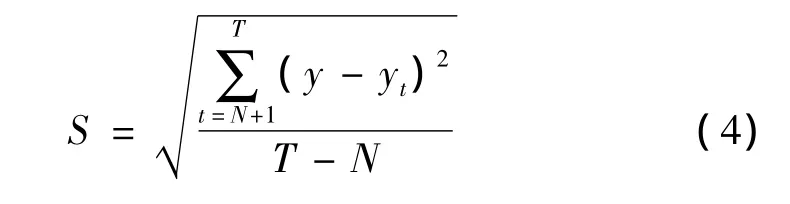
以最近N期序列值的平均值作为未来各期的预测结果。一般N的取值范围:
5≤N≤200
通过上式,利用Matlab软件进行求解,得到各个类型文件未来10天的变化趋势如下表。
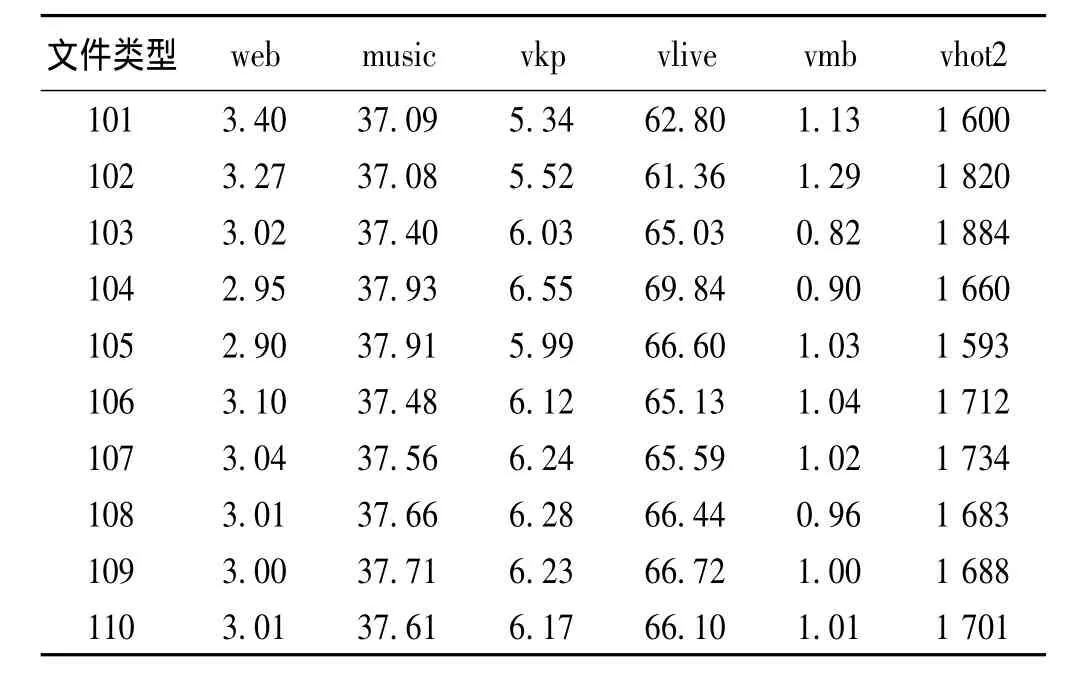
表2 各个类型文件名未来十天的变化趋势
为了建立一个高效的淘汰分发算法,即决定满足什么条件时把什么文件分发到VOC上,什么时候把什么文件删除,要对不同类型的文件进行热度分析,给出文件分发及淘汰的阈值。
首先,计算多个周期内不同类型文件的热度,建立下表。
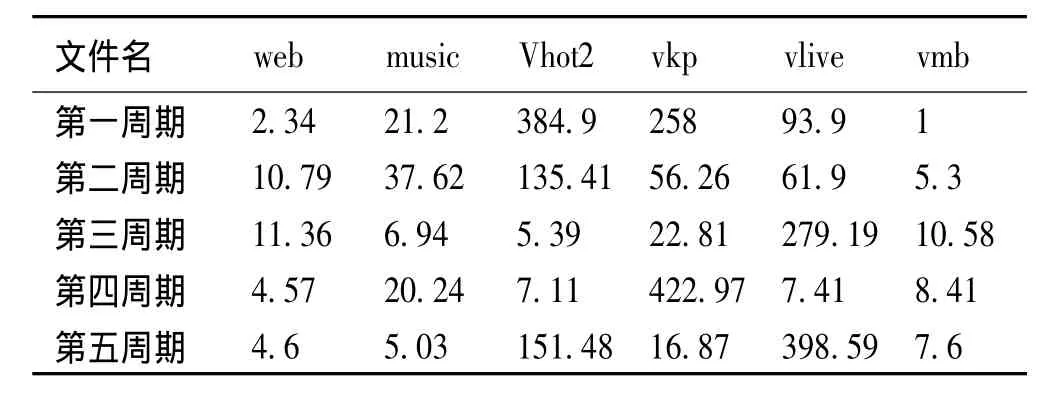
表3 不同周期各个文件的热度
这里,为了更好地满足用户需求,首先定义1个周期内各个文件的淘汰阈值,将这个“淘汰阈值”作为一个判断文件是否淘汰的标准。
为了确定“淘汰阈值”,给出了模糊集和隶属函数的概念。
定义 设论域X到[0,1]闭区间的任意映射
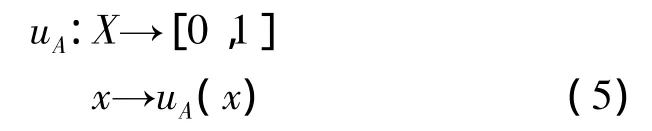
都确定X上的一个模糊集合A,uA叫做A的隶属函数,uA(x)叫做x对A的隶属度,记为
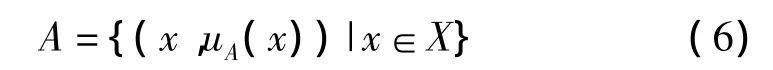
此时,将各个文件的热度作为一个集合,在这个集合里面利用上述方法做出一个淘汰分发算法。针对第一周期,设论域 X={x1(2.34),x2(21.2),x3(384.9),x4(258),x5(93.9),x6(1)},X 上的一个模糊集“高热度”(A)的隶属函数uA(x)可定义为
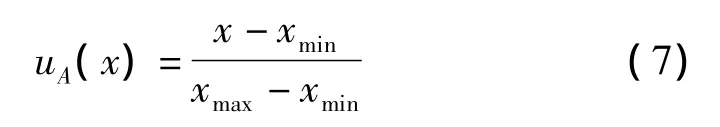
用向量表示法,
A=(0.00350.05261.00000.66940.24200)
uA(x)=0.5的点x0称为模糊集A的过渡点,此点最具模糊性,所以在相应的集合A中,以0.5为分割点,即集合A中超过0.5的被保留,其余小于0.5的将被淘汰。
所以在第一周期内,文件的淘汰阈值为258,同理可以得到其余4个周期文件的淘汰阈值分别为135.41,279.19,422.97,398.59。
据此,可以得出一个动态的淘汰阈值图(见图8)。
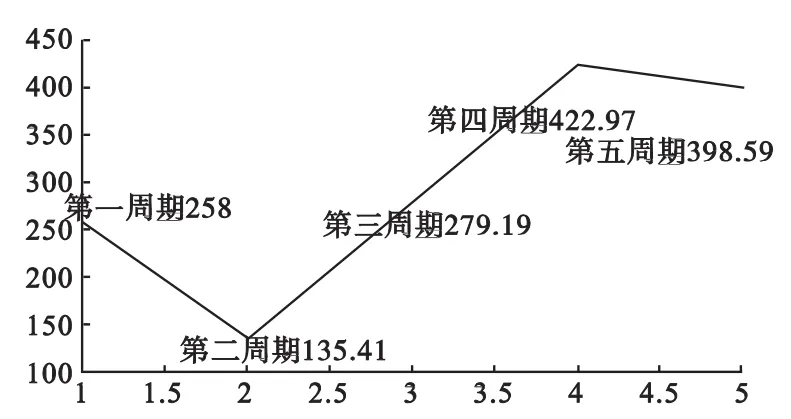
图8 动态淘汰阈值
3 结语
在所提供的数据基础上,抽取其中的部分数据给予分析处理,定义出文件的热度,通过平均分析的方法得出了各类文件的一般访问特征。采用时间序列方法对不同类型文件进行了短期的访问预测,得出了各类文件未来10天的访问情况。最后,利用隶属度函数得出不同周期文件的淘汰阈值,进而可知文件分发淘汰的标准。
[1]孙文颙,张翰相.视频网站数据分析系统设计[J].现代电视技术,2011(9):140-144.
[2]吴宗敏.散乱数据拟合的模型、方法和理论[M].北京:科学出版社,2008.
[3]徐国祥,马俊玲.《统计预测和决策》学习指导与习题[M].上海:上海财经大学出版社,2005.
[4]司守奎.数学建模算法与应用[M].北京:国防工业出版社,2011.
[5]杨纶标,高英仪.模糊数学原理及应用[M].广州:华南理工大学出版社,2004.
