数据挖掘技术在员工流失问题上的应用——以H 集团零售连锁门店员工数据为例*
2014-12-13瞿晓理
瞿晓理
(苏州经贸职业技术学院 工商系,江苏 苏州 215009)
1 研究背景
所谓员工流失,是指企业不愿意而员工个人却愿意的自愿流出[1]。这种流出方式对企业来讲是被动员工流失,特别是我国产业升级转型期,新生代劳动力的素质不断提升,员工流失成为企业人力资源管理中最为棘手的问题之一,它将给企业带来特殊的损失,增加企业的经营成本。据相关统计,一个员工流失给企业带来的直接经济损失大致是这个员工在这家企业一年的薪酬所得[2];此外,他们的流失还会间接性地影响企业其他员工的士气,造成不可估量的无形损失。
所以,员工流失问题一直是近年来管理界研究的重点之一。在我国,自2000 年以来,有大量关于员工流失的研究文献与报道[3],归结其研究视点基本集中在以下几个方面:员工忠诚度、工作满意度、心理契约、组织承诺、工作倦怠及薪酬激励制度等;基于这些研究基础,很多企业也相应调整各类管理制度和优化企业文化,以期望能降低企业员工的流失状况。
但是,综合过往企业员工流失原因及对策的研究,也从中发现一些研究疑点。例如,过往研究基本集中于“企业核心员工”群体,但是在当今新经济“用工荒”形势下,企业的主要人力成本已从原先的“核心员工”扩展到“一线员工”[4];而过往对企业员工离职倾向的评价指标——员工忠诚度、工作满意度、心理契约、组织承诺及工作倦怠等,由于“一线员工”的数量庞大和文化素质偏低等原因,在其范围内实施均存在实际操作的困难。因此,寻求企业“一线员工”流失倾向的预测指标,建立一套与其相对应的“一线员工”流失管控机制,将大大降低企业的人力成本,有利于提高其市场竞争力。
2 研究对象
针对上述员工流失问题中的疑点,研究将以H集团零售连锁门店员工的信息数据为例,探讨企业一线员工流失的预测和控制问题。H 集团是一家老牌央企,旗下业务呈多元化经营态势,其中为公众较为熟知的为零售连锁超市业,它是中国最具规模的零售连锁企业集团之一,旗下员工共计约35 万名。H 集团拥有较为成熟的企业文化,对员工管理也形成一套较为完善的机制,其员工的平均薪酬水平比市场同行同工种一般要高出15%-20%。但是尽管如此,H 集团零售门店的一线员工流失多年来均要达到15%-20%左右,而在近年来在“用工荒”的经济大背景下,经济较为发达的华北、华东及华南区域门店员工流失情况更为凸显,以2012 年该集团华东区人力资源部统计数据显示,旗下各区连锁门店员工流失率均超20%[5]。
3 研究方法
3.1 数据挖掘简介
数据挖掘(Data mining),又译为资料探勘、数据采矿。它是数据库知识发现(Knowledge-Discovery in Databases,简称:KDD)中的一个步骤[6]。
3.2 数据挖掘算法的选择
算法是数据挖掘工具的核心部份,主要算法有:聚类分析、分类分析、统计分析、关联分析、相关分析、时间序列和值预测等。对于数据挖掘来说,一般最常用的算法就是值预测(比如预测个人收入、客户贡献度、股票价格等)、分类算法(比如用于风险评级、产品购买概率预测、客户流失预测等)以及聚类分析(比如用于客户分割、内幕交易监测等)[7]。因此,依据分类算法的应用特性,对H 集团门店员工的流失率实施挖掘研究。
4 研究过程
4.1 数据的准备
研究采用的数据来源于H 集团人力资源部提供的苏南某市在2013 年1 月-2013 年12 月间所有门店员工信息,共计5 277 名,包括其个人基本信息(姓名、性别、年龄、民族、文化水平、婚姻状况、政治面貌、家庭住址、国籍、籍贯、所在门店位置等)、员工绩效信息(夜班次数、岗位出错额)、员工薪酬信息(每月的基本工资、津贴补助、工资扣款额及总收入)及其他信息(入职时间、离职时间)。
4.2 数据的预处理
4.2.1 数据的集成
依据上述信息,将这5 277 位离职员工录入统计软件SAS9.3,集成原始数据库。
4.2.2 数据的归约
在所有门店员工17 个信息项中,首先通过特征归约,删除“姓名”、“国籍”、“民族”、“婚姻状况”、“政治面貌”这五项无关维度。其次,由于每位员工的在职时间不同,导致他们“绩效”和“薪酬”上的信息因时间长短而参差不齐,因此,研究将他们的“绩效”和“薪酬”实施平均化,即依据每位员工的每个月的薪酬绩效信息和他们的在职时间,计算出“月均绩效”、“月均夜班次数”、“月均岗位出错额”、“月均基本工资”及“月均津贴补助”。再者,由于“入职时间”和“离职时间”均为时点变量,无法参与模型计算,因此研究设置新特征变量“在职时间”,以月为单位。此外,研究发现,“夜班次数”与“津贴补助”呈显性相关,相关系数r=0.356***;“岗位出错额”与“工资扣款额”呈显性相关,相关系数r=0.417***。“每月工资总额”=“月基本工资+津贴补助-工资扣款额”,其中所有门店“月基本工资”区间范围为(1 370,1 430),浮动率<5%;“工资扣款额”空缺项>30%,且区间范围为(0,2 500),其中仅一人某月扣款额为2 476 元,扣除此异常点,区间为(0,50),max(0,50)<工资总额的3%。因此,将“夜班次数”、“津贴补助”、“岗位出错额”、“工资扣款额”、“基本工资”定位冗余维度,以与删除。最后,利用百度地图APP 功能,依据“家庭住址”与“门店位置”,计算出每位员工的“上班距离”,以公里为单位。
4.2.3 数据的清理
由于5 277 位门店人员信息相对繁多,个别信息为空缺,在整个数据库削减过程中,我们将信息空缺项超总信息项20%的人员删除,其余空缺项,则跟据集合的出现规律来补齐。得到有效数据库成员信息共有5 066 位,其中选取4 000 位员工为挖掘样本,1 066 位员工为模型验证样本。
4.2.4 数据的转换
为了便于数据模型的计算,研究将员工的信息特征变量实施属性值转换。依据数据分布状况,对一些连续变量特征的数据实施离散化处理,①年龄(岁):分为“18-30”、“31-40”、“40-50”“50 以上”;②月均工资总额(元):“1 500 以下”、“1 500-2 500”、“2 500 以上”;③在职时间(月):“1 以下”、“2-3”、“4-6”、“6-12”、“12 以上”;④上班距离(公里):“3 以下”、“3-10”、“10 以上”。
综合上述数据预处理工作,研究工作采集了H集团4 000 名门店员工的“性别、年龄、籍贯、上班距离、月均工资总额及在职时间”等6 项特征为挖掘字段,形成数据样本集。
4.3 数据的挖掘
研究的数据挖掘采用决策树C4.5 算法,其核心算法是ID3 算法。ID3 算法中在决策树各级结点上选择属性时,用信息增益(information gain)作为属性的选择标准,以使得在每一个非叶结点进行测试时,能获得关于被测试记录最大的类别信息。C4.5 算法继承了ID3 算法的优点,且采用了多重分支技术和剪枝技术对ID3 算法进行了改进,是当前最流行的一种决策树算法[8]。
依据C4.5 算法,在整个数据挖掘中,我们将X设为H 集团4 000 位门店员工各特征样本xi的集合;设门店员工每一个特征属性具有k 个不同的值,又设k 个不同类别的特征项Aj,则Aj(j=1,…,k),其中xij是Aj中的样本数[9]。因此,研究可以对一个给定的样本分类所需的期望信息为pi=xij/xi,即不同类别门店员工的流失人数与总人数之比。依据ID3 算法,信息量大小的度量计算为[6,9]:
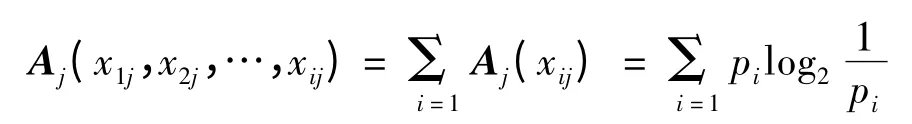
在这个假设之下,如果由A 划分成子集的熵值越小,则子集的纯度越高,也就意味着该类型员工的流动的可能性越低。在已知的4 000 位门店员工信息中,在2012 年整年间,总流失员工与未流失员工之比为843/3 166,流失员工占样本总数的21.08%;经计算处理后得到门店员工是否流失的决策树模型,如图1 所示。
依据以上决策树模型,我们得到H 集团门店员工流失概率较高的6 条规律,总结见表1。
4.4 数据的验证
研究在数据库准备之初,就设立了一个与挖掘数据库不重复的1 066 位H 集团门店员工信息,作为验证数据库,对该决策树模型实施误差估计。在1 066 位门店员工中,有216 位流失,占20.26%。依照挖掘模型得出的规律,我们分别计算出验证数据库6 类特征员工的流失概率,与挖掘数据库作对比,实施百分数差异检验,详见表2。
这6 条规律流失的员工为679 人,占总员工流失人数的80.54%。

表1 门店员工流失特征规律集合表
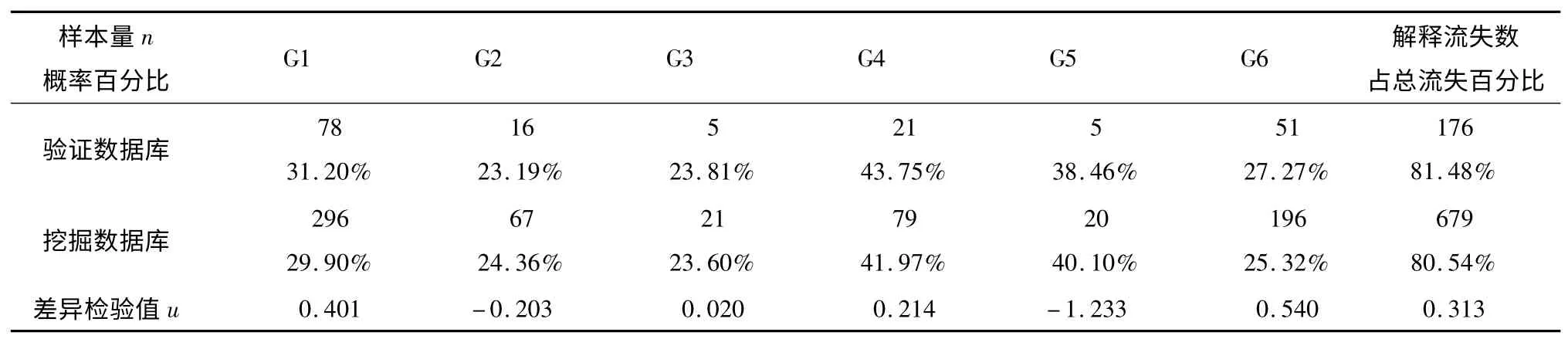
表2 “挖掘-验证”数据库的员工流失概率比较
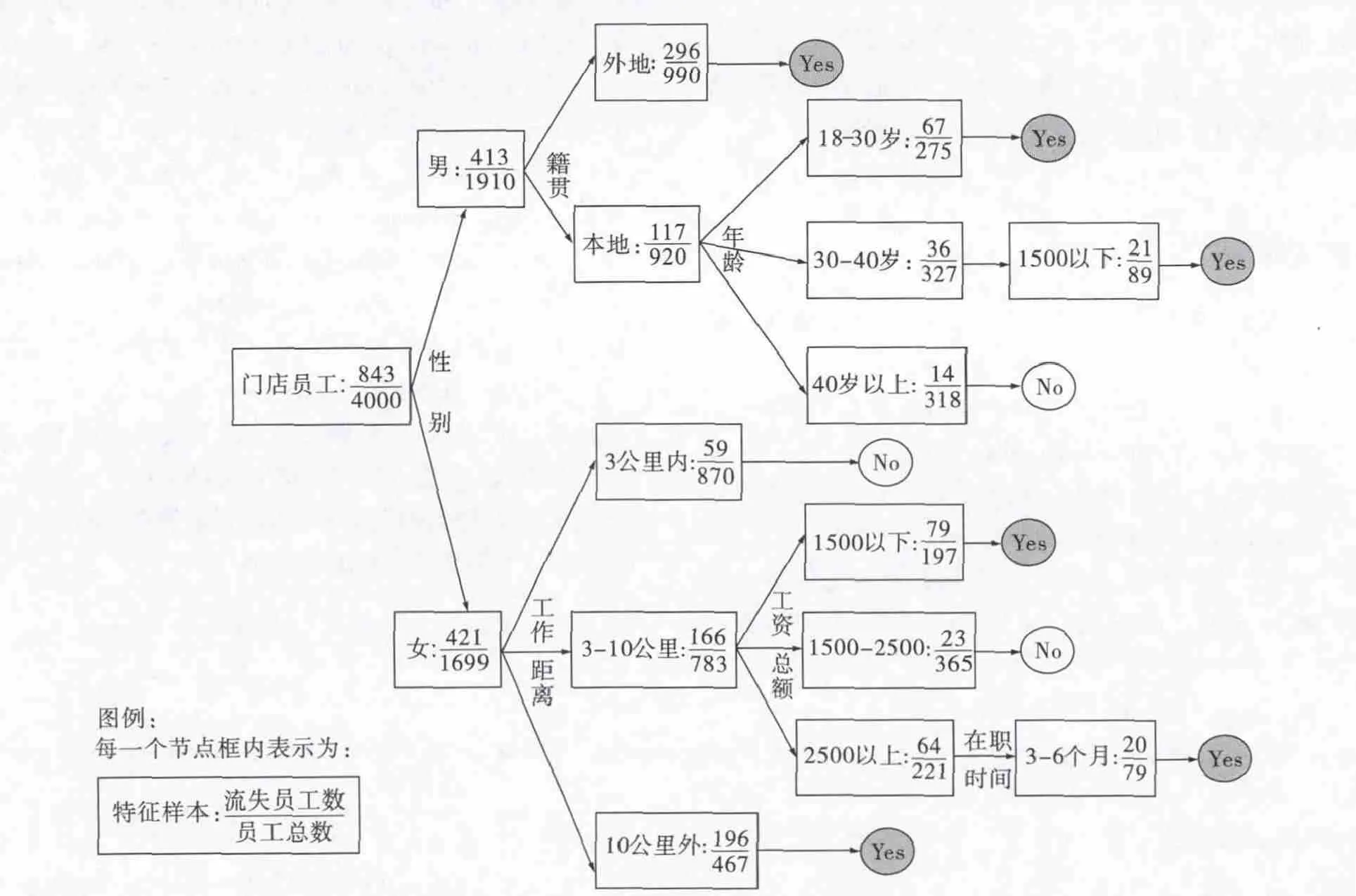
图1 门店员工是否流失的决策树模型
从两个数据库的百分数差异检验值u 来看,6条规律及总解释数均未达到显著差异水平,拟合水平高于一般数据模型检验拟合标准[10],因此,研究的决策模型具备较理想的准确率。
5 研究结果与讨论
从对H 集团零售连锁门店员工的数据挖掘结果来看,首先,大部分流失规律还是合乎常理,但是也有个别规律在意料之外,如G6,女性员工工作距离在3-10 公里范围,月均收入2 500 以上的,在职时间3-6 个月阶段的流失率较高。探究其中原因,不难发现,员工的收入差异主要来自与津贴补助,而一线员工每月的津贴补助主要来自于当月值守夜班的次数;如果说,这个员工收入越高,则说明她值守夜班的次数较多;而对于女性来说,工作距离并不是离家很近,值守夜班的次数较多的话,很容易在工作3 个月后出现倦怠感[11],因此离职流失人数比例也会较高。
其次,通过决策树C4.5 算法挖掘出来的6 条一线员工流失规律,其解释的流失人数占总流失人数的80%以上,说明通过研究挖掘的员工日常信息,已经较好地能说明大部分流失员工的特征,无需再通过调查“工作满意度”、“职业倦怠感”等隐形信息来预测员工流失状况。这可以大大减轻人力资源部工作人员在一线员工流失问题上的工作量,今后,他们只需构建员工特征集G1、G2、G3、G4、G5 和G6,一旦有员工归属这些集合,则可标记为“流失率高风险员工”,对他们日常一线员工的招聘、配置及工作量安排等问题都有一定的指导意义。
最后,通过H 集团苏南某市门店一线员工的样本数据挖掘案例,对于一些一线员工流失率较高的企业,如生产、服务及零售性行业,提供借鉴经验,利用当前有效数据的分析结果管控员工的流失状况,降低企业人力成本。
总而言之,本次研究的过程、方法和结论给人力资源相关工作者带来较新的工作思路,作为掌握员工大量基本数据信息的人力资源部门,可以进一步利用数据挖掘的其他技术——聚类分析、关联分析、相关分析、时间序列和神经网络分析等[12-13],探索和解决企业人力资源管理中的规划、招聘、绩效、薪酬、培训等相关问题,提高管理质量和效率。
[1]沈新民.新人力资源管理[M].北京:中央编译出版社,2002.
[2]无优商务网.企业员工流失率分析报告[DB/OL].2011,http://www.5ucom.com/
[3]高福霞,李 婷,李 志.我国企业员工忠诚度研究述评[J].经济师,2006(1):192-193.
[4]李宝元,王泽强.中国经济发展方式转变的历史契机——关于近年来“民工(技工)荒”现象的劳动经济学分析[J].天津行政学院学报,2009(3):64-67.
[5]H 集团门店人员(华东区)2013 年度统计报告[R].企业内部资料,2014.
[6]Jiawei Han,Micheline Kamber.数据挖掘:概念与技术[M].范 明,孟小峰,译.北京:机械工业出版社,2001.
[7]刘君强.数据挖掘技术在企业经营中的应用研究[J].商业经济与管理,2003(6):27-29.
[8]Rastogi R,Shim K.A decision tree classifier that integrates building and pruning[C]//In Proc.1998 Int.Conf.Very Large Data Bases(VLDB'98),New York:1998.
[9]David Hand Heikki Manila Padhraic Smyth.数据挖掘原理[M].张银奎,译.北京:机械工业出版社,2003.
[10]Frank R,Giordano Maurice D,Weir William P Fox.A first course in mathematical modeling(Third Edition)[M].New York:Brooks/Cole,2004.
[11]王 虹,程剑辉,吴 菁.员工流失分析与研究[J].商业经济与管理,2001(5):36-40.
[12]王 庆,郑汉超.数据挖掘在人力资源管理中的应用及展望[J].企业活力,2010(4):68-71.
[13]朱近贤.数据挖掘技术在人力资源管理中的应用研究[J].计算机与信息技术,2008(10):7-9.
