ARMv4指令集嵌入式微处理器设计*
2014-12-10陈明敏易清明
陈明敏,易清明,石 敏
(暨南大学 信息科学技术学院,广东 广州 510632)
0 引言
ARM微处理器具有高性能、低功耗特点,市场占有率上ARM微处理器超过了75%,其产品从最初的单核ARM7发展到现在的多核Cortex R系列,相应的指令集从最原始的ARMv1到现在的ARMv8。每一种指令集都是在前一种指令集的基础上增加若干指令用于提升性能,这样微处理器保持了良好的向下兼容特性,用于低端芯片的工程可以完美地移植到高端的芯片上,具有良好的继承性。其中ARMv4是第一次用于商业芯片的指令集,因而ARMv4是ARM微处理器指令发展源泉。对于ARM微处理的研究国内目前主要集中在应用软件上,通过ARM微处理器设计了一段什么样的代码,完成了什么样的功能[1-2],而对于微处理器自身的研究较少。参考文献[3]利用ARMv4指令集加入wishbone总线设计了一款新的32位微控制器,其微处理器结构、流水线运行模式都与原来一样,没有什么变化。参考文献[4]针对ARMv4指令集做了一个仿真平台,主要用于监控微处理器程序运行状态,而对微处理器本身并没有什么改变。参考文献[5]完成了一个指令模拟器,即在一台计算器上模拟一个ARM微处理器,其结构和指令完全都是按照芯片标准设计没有一点变化。中国龙芯处理器以类MIPS指令集为基础,采用自己设计的架构形成国产CPU。本文借鉴龙芯的发展模式,以ARMv4指令集为基础,采用哈佛结构,优化内存访问指令,充分利用资源共享,减少芯片面积,改进后的嵌入式微处理器性能有所提升。
1 嵌入式微处理器模块设计
1.1 结构设计
当前微处理器有两种存储结构,冯·诺依曼结构和哈佛结构,如图1所示。冯·诺依曼结构是一种将程序指令存储器和数据存储器合并在一起的存储器结构。程序指令存储空间和数据存储空间指向同一个存储器的不同物理位置,共用一条数据总线,因而当读取指令时,就必须暂停读取数据,两者只能分别进行操作。这种结构会制约后面流水线的并行操作。当流水线上一条指令访问存储器时,下一条指令必须等待上条指令访问结束才可以访问存储器,期间流水线需要插入NOP指令等待,不能充分发挥流水线优势。哈佛结构是一种将程序指令存储和数据存储分开的存储器结构。微处理器首先从程序指令存储器中读取程序指令内容,解码后得到数据地址,或直接从寄存器中直接获得数据地址,再到相应的数据存储器中读取数据,并进行下一步的操作。由于程序指令存储和数据存储分开,且拥有独立的数据访问总线。因而读取程序和读取数据可以同时进行,这样可以更好发挥流水线优势,本文采用哈佛结构。

图1 微处理器两种存储结构
1.2 单周期32位乘法器设计
乘法器是重要而复杂的一个运算单元,乘法器电路信号传播路径长,电路延时比较大,针对乘法器很多人做了不同优化。参考文献[6]引入流水线乘法器,通过分部计算减少了单次乘法器的运算周期,适用于连续乘法器运算。但单次乘法器运算,使用时钟周期反而随流水线增长而增加,并不适用于微处理器方面。参考文献[7]针对传统Booth编码方式进行了优化,提出新的编码方式。相比传统Booth该方法减少了10%面积。同时优化部分积产生电路如图2所示,在部分积相加阶段采用单独4-2压缩器,相比2个3-2压缩器构成的4-2压缩器减少了门级电路。整个乘法器运算过程如图3所示。
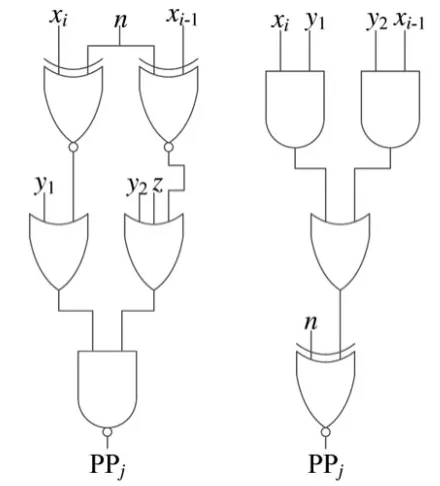
图2 部分积产生电路比较
2 系统优化
2.1 第二操作数获取
ARMv4指令集中数据的运算都是基于寄存器,通常一条指令包括1-3个寄存器,指明源寄存器和目的寄存器。指令中立即数一般会通过逻辑左移、逻辑右移、算术右移、循环右移、带扩展的循环右移1位移位得到原立即数。这样就需要5个32位的移位寄存器,这将增加芯片面积和功耗。通常控制逻辑单元消耗的逻辑资源少于运算单元消耗的资源。通过对数据的前期操作最后使用一个逻辑左移实现上面5种移位功能[8-9],大大减少逻辑资源。逻辑右移转换成逻辑左移的实现过程如下:通过将被移数据补足为64位,然后将右移偏移量取负数,通过左移负数个单位,高位得到的32位结果就是逻辑右移的结果,移位示意图如图4所示。
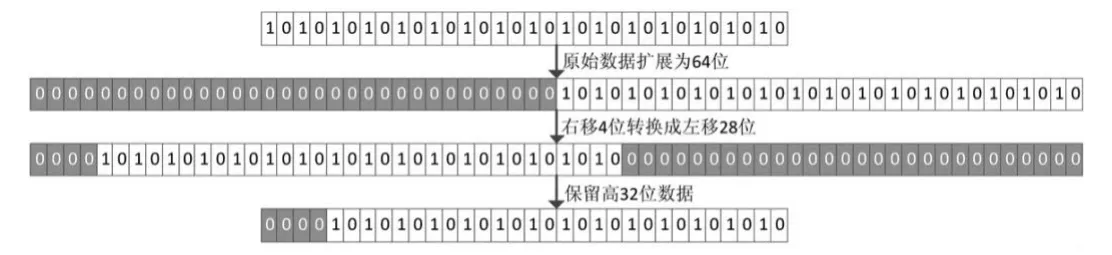
图4 逻辑右移过程
算术右移通过逻辑左移的实现过程如下:通过将被移数据补足为64位,然后判断被移数据的正负性,若为负数则将数据取反,正数无需处理。然后将右移偏移量取负数,通过左移负数个单位,保留高位得到的32位数据结果。根据被移数据的正负性,若为负数则将数据取反,正数保持不变,最后得到的结果就是算术右移的最终结果,移位示意图如图5所示。

图5 算术右移过程
循环右移通过逻辑左移的实现过程如下:通过将被移数据补足为64位,然后将右移偏移量取负数,通过左移负数个单位,将移位后的高32位数据与低32数据进行与运算得到结果即是循环右移的结果,移位示意图如图6所示。
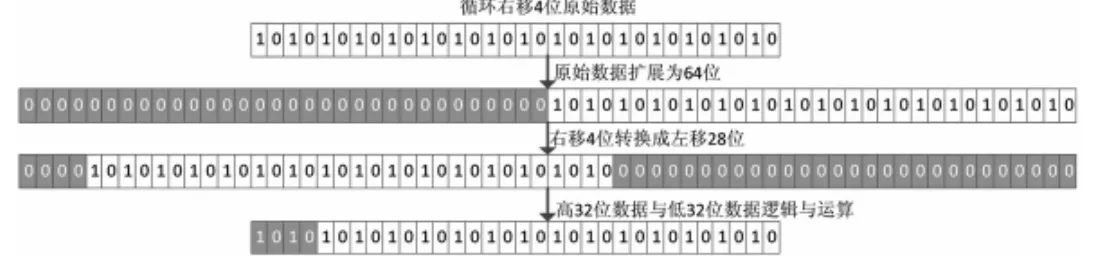
图6 循环右移过程
带扩展的循环右移1位的实现过程如下:由于每次只能移位一个距离单位,只需要保留被移的数据的高31位,然后将进位标志C放在数据的最高位,即可实现带扩展的循环右移1位功能。移位示意图如图7所示。
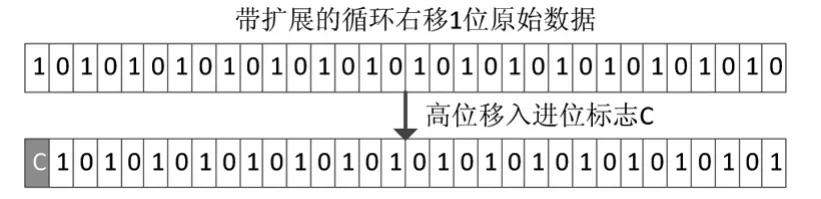
图7 带扩展的循环右移过程
2.2 乘法器和乘加法器指令实现
ARMv4指令集中的乘法运算有32位乘法运算,32位乘加运算,无符号乘法运算,无符号乘加运算、有符号乘法运算、有符号乘加运算6种。通常不同功能乘法器需要不同设计。这样6类乘法需要2个乘法器和2个加法器。如果将有符号数在运算前转换成无符号数,最后将运算结果根据之前的符号位转换成有符号结果,这样就将有符号乘法转换为无符号乘法。对于简单的乘法运算转换为被加数为0的乘加运算,这样所有的乘法和乘加运算都转换为乘加运算。通过上面转换后,6种乘法指令到最后都通过前置数据转换共用一个乘加运算实现,如图8所示。

图8 乘加器原理图
3 FPGA实现和Modelsim验证
实验所用FPGA芯片为Altera EP4CE30F23C7,EP4CE30器件总共有28 848个逻辑单元,器件中分布RAM有107 520 bit。由于芯片具有丰富的RAM,微处理器内部RAM和ROM均采用FPGA内部RAM实现。整个工程采用Verilog语言编写,使用synplify pro 2011进行综合,在Quartus 13.0下进行布局布线。利用Modelsim10.0a进行功能验证和时序分析。设计ROM 32 KB,RAM 16 KB,时钟20 MHz,其中内部 RAM、ROM通过使用 FPGA内部M4K存储单元组成。C语言测试代码使用μVision V4.22编译生成,由于FPGA无法直接初始化32位HEX文件,需要将HEX文件转换为MIF格式。代码转化软件通过VC++6.0编写。通过将转换后将生成的MIF文件下载到ROM中进行测试验证。
3.1 移位寄存器仿真
指令中包含的第二操作常数一般是通过8位常数循环右移得到。因而并不是所有常数都是合法常数。例如 mov r0,#0x1000;是合法指令,0x1000可以通过 0x01循环右移20个单位得到。但是mov r0,#0x1001;就是非法指令,因为0x1001无法通过一个8位数据循环右移得到。上文中通过一个逻辑左移实现4种逻辑运算功能,为了验证其正确性下面将通过4条指令分别测试逻辑左移、逻辑右移、算术右移、循环右移4种功能。测试代码及理论运算结果如下:

Modelsim仿真如图9所示。
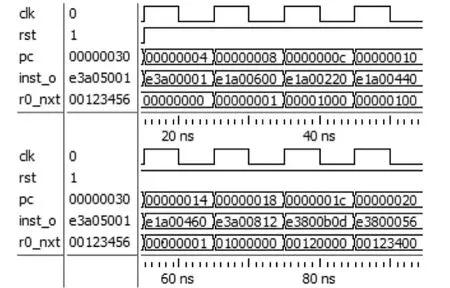
图9 移位指令仿真
从Modelsim仿真结果看出,设计的单个逻辑左移移位寄存器很好的完成了上述4种功能。
3.2 乘法器和乘加法器仿真
经过优化后的乘法指令和乘加指令都通过同一个乘加器实现。为了验证其正确性,分别采用6种乘法指令分析其正确性。测试思路是通过编写指定的代码,进行理论计算,然后对比微处理器运行结果。测试代码及理论运行结果如下:

上面6段代码主要是初始化r0、r1、r5值,运行后 r0为0x123456,r1为0x8000789a,r5为0x01。
mul r4,r0,r1:运算结果为 0x91a33937bcbbc,由于只取 32位结果,r4结果为 0x937bcbbc。
mla r4,r0,r1,r5:运算结果为 0x91a33937bcbbd,由于只取32位结果,r4结果为0x937bcbbd。
umull r4,r5,r0,r1:无符号乘法结果为 0x91a33937bcbbc,r5 结果为 0x91a33,r4 结果为 0x 937bcbbc。
umlal r4,r5,r0,r1:无符号乘发结果为 0x91a33937bcbbc,乘加 r5结果为 0x123467,r4结果为 0x 26f79778。
smull r4,r5,r0,r1:r1最高位为 1有符号运算时先转换为无符号数0x7fff8766,然后计算得到无符号结果0x91a226c843444,转换成有符号后r5结果为0xfff6e5dd,r4结果为 0x 937bcbbc。
smlal r4,r5,r0,r1:r1最高位为1有符号运算时先转换为无符号数0x7fff8766,然后计算得到无符号结果0x91a226c843444,转换成有符号结果为0xfff6e5dd937bcbbc,乘加后 r5结果为 0xffedcbbb,r4结果为 0x26f79778。
Modelsim仿真如图10所示。从仿真结果看出,设计的单个乘加器正确的完成了上述6类指令的功能。
3.3 Dhrystone性能测试
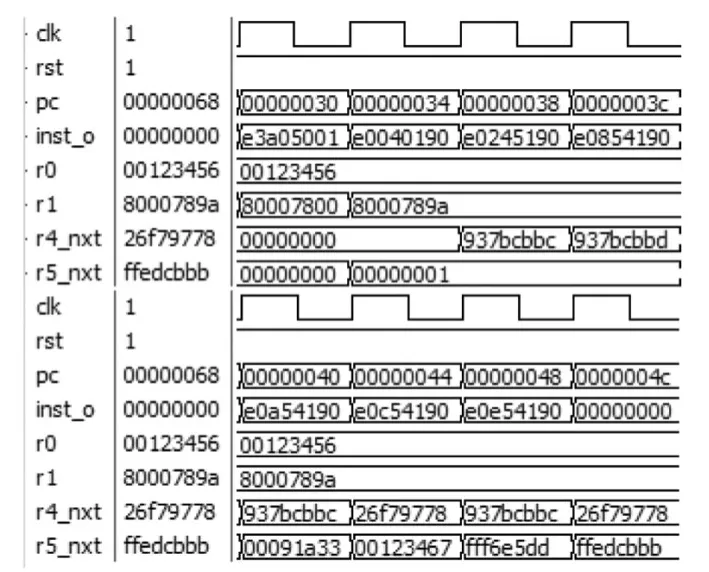
图10 乘法指令仿真
Dhrystone的计量单位为每秒计算多少次Dhrystone,它是一个相对值。程序用C语言编写,能运行在大多数微处理器上,是测试处理器运算能力的最常见基准程序之一。基准程序使用μVision V4.22软件下ARM自带的Dhrystone2.1基准测试程序,去掉全部优化后,将编译好的文件下载到本文设计的微处理器。选用NXP公司的ARM LPC2102微处理器芯片作为对比。LPC2102在ARMv4指令集基础上增加了Thumb指令集,测试时禁用交叉编译只生成32位的ARM指令。结果如表1所示。

表1 Dhrystone2.1基准测试
从表1中可以看出,改进后的微处理器,相比当前市面同种类微处理器性能有近20%提升。
4 结论
当前高性能、高效率的微处理器基本采用哈佛结构。本文以ARMv4指令集为基础,将传统冯·诺依曼结构更改为哈佛结构,拥有独立指令总线和数据总线,其优点是在流水线阶段可以同时进行访问ROM和RAM,避免了单总线引起的资源竞争。采用单周期乘法器,提高微处理器的运算速度。在设计乘法器时,利用资源共享,最终一个乘加器实现了6条指令功能。采用单一逻辑左移移位寄存器实现多种模式移位功能。实验结果表明,本文设计的微处理器能正确运行ARMv4指令集,同等条件下比当前市面同种类芯片性能有20%提高。大多数应用程序在不修改就可以提高20%性能。
[1]董海涛,庄淑君,陈冰,等.基于ARM+DSP+FPGA的可重构 CNC系统[J].华中科技大学学报(自然科学版),2012,40(8):82-87.
[2]竺乐庆,张三元,幸锐.基于 ARM与WinCE的掌纹鉴别系统[J].仪器仪表学报,2009,30(12):2624-2628.
[3]孙永琦.基于 ARMv4指令集的32位 RISC微控制器的设计与实现[D].浙江:浙江理工大学,2012.
[4]徐怀亮,刘晓升,王宜怀,等.一种ARM指令集仿真器的实现与优化[J].苏州大学学报(工科版),2009,29(2):28-31.
[5]贾少波.基于X86平台的ARM指令集模拟器的设计[J].电子设计工程,2013,21(12):164-169.
[6]周怡,李树国.一种改进的基 4-Booth编码流水线大数乘法器设计[J].微电子学与计算机,2014,1(6):60-63.
[7]翟召岳,韩志刚.基于Booth算法的32位流水线型乘法器设计[J].微电子学与计算机,2014,31(3):146-149.
[8]杜慧敏,王明明,沈子杰.32位桶式移位寄存器FPGA实现[J].西安邮电学院学报,2008,13(1):99-102.
[9]陈永强,雷雨.可变长移位寄存器在高速数据采集中的应用与 FPGA实现[J].西华大学学报(自然科学版),2013,32(4):61-63.