两种学术不端检测系统的差异性及问题讨论
2014-12-10青岛科技大学图书馆山东青岛266061
●徐 仲(青岛科技大学 图书馆,山东 青岛 266061)
国际上有关学术不端的行为屡禁不止,如近年来,德国国防部部长古滕贝格、教育和科研部部长沙范、欧州议会副议长梅林、北莱茵—威斯特法伦州议会议员迪特·亚斯珀、自民党政客查奇马卡吉斯、柏林的基督教民主联盟议会主席格拉夫等因博士论文抄袭问题相继辞职或颜面扫地。[1]我国学者学术不端现象近期来也逐年增多。一场针对学术不端而引发的讨论和事件处理已经引起教育、科研等管理部门的高度重视。为了防止学术不端现象的发生,目前在论文发表、学位论文提交、职称评定、职务晋升、人物评选、人才引进等过程中已相继开展论文相似性检测。
国内不同的文献情报服务机构开发了多个论文相似性检测服务平台,其中最常用的是万方数据知识服务平台的论文相似性检测系统和CNKI科研诚信管理系统研究中心的学术不端文献检测系统。本文就CNKI与万方这两种论文相似性检测服务的差异性进行比较讨论。
1 检测范围
CNKI科研诚信管理系统研究中心开发的学术不端检测系统分为“学术不端文献检测系统4.0版”和“科研诚信管理系统(人事版)”两部分。其中“学术不端文献检测系统4.0版”包括科技期刊学术不端文献检测系统、社科期刊学术不端文献检测系统、学位论文学术不端行为检测系统、学术不端文献(期刊)检测系统、大学生论文抄袭检测系统;“科研诚信管理系统(人事版)”包括英文检测系统和中英文对照检测系统。每个检测系统功能范围不同,如学位论文学术不端行为检测系统专门为研究生院提供检测服务,仅限检测研究生毕业论文;学术不端文献(期刊)检测系统主要为人事部门在职称评选、人物评优、先进评选、人才引进等活动中提供辅助审核手段,提供科学、准确、客观的线索与依据。CNKI学术不端检测系统的检测范围包括中国学术期刊网络出版总库、中国博士学位论文全文数据库、中国优秀硕士学位论文全文数据库、中国重要会议论文全文数据库、中国重要报纸全文数据库、中国专利全文数据库、互联网资源、英文数据库(涵盖期刊、博硕、会议的英文数据以及德国Springer、英国Taylor&Francis期刊数据库等)、港澳台学术文献库、优先出版文献库、互联网文档资源、个人比对库。
万方数据知识服务平台的论文相似性检测服务没有对不同要求的文献检索进行分类,检测语种仅限中文。该系统包括2个入口,一个是“检测已发表论文”,主要针对送检论文之前发表的全部文献,适用于对职称论文等进行检测;另一入口是“检测新论文”,适用于对毕业论文、新投稿论文等进行检测。万方相似性检测系统检测范围包括中国学术期刊数据库(CSPD)、中国学位论文全文数据库(CDDB)、中国学术会议论文数据库(CCPD)和中国学术网页数据库(CSWD)。
从CNKI和万方论文相似性检测系统的检索范围可以看出,均包括了主要中文学术资源,但是CNKI学术不端文献检测系统包含的中文学术资源更加丰富,更重要的是CNKI还特别涵盖了港澳台学术文献库和大量的英文数据库(涵盖期刊、博硕、会议的英文数据以及德国Springer、英国Taylor&Francis期刊数据库等),因此其检测范围要比万方数据库更全、更广。
正是由于检索范围的差别,导致这两个检索系统的检索结果差别很大。如2012年山东省对参评职称晋升人员提交的3件成果开展学术不端检测,其中一件成果利用万方论文相似性检测系统检测,其查重率为12.81%;利用CNKI学术不端文献检测系统,其查重结果达到36.12%。
然而,CNKI学术不端检测系统和万方论文相似性检测系统都有其检索局限性,即涉及英文论文的检索。万方数据知识服务平台本身没有外文检索库;CNKI学术不端文献检测系统,虽然拥有英文数据库,但仍有大量的英文数据库没有被涵盖,其检索范围是不全的。而且从长远来看,外文的查重检索会日益重要,因此,国内的论文相似性检测服务平台应积极应对,扩大检索范围,克服其检索局限。
2 文献引证检测与重复率表征
万方数据知识服务平台的文献引证检测与重复率表征相对简洁,一般在总体结论中,只给出“总相似比”、“参考文献相似比”和“排除参考文献相似比”。在相似片段分布中用绿色区域表征参考文献相似部分的位置,红色区域为与其他未被引用的论文相似部分,并列出相似论文作者和典型相似论文及其典型片段总相似比。总体表征比较客观,不对论文做出结论性评价。
CNKI学术不端文献检测系统的文献引证检测与重复率表征相对复杂,在总体结论中,给出总文字复制比、去除引用文献复制比、去除本人已发表文献复制比和单篇最大文字复制比,用红色文字表示文字复制部分,黄色文字表示引用部分,并将剽窃文字进行详细表述。根据与自己已发表文献复制比,明确指出是自我剽窃、一稿多投还是重复发表;根据引用文献复制比、单篇最大文字复制比确定论文是否过度引用、剽窃观点或整体剽窃等结论。从重复率检测结论中观之,要求作者在论文撰写过程中严格文献引证,即使是引用自己已发表的论文,也要用参考文献进行引证,否则会出现自我剽窃的后果;而且,对于文献的引证,不宜过度引用,否则有一稿多投(过度引用自己论文)和剽窃(过度引用他人论文)之嫌。
显然,不论是万方论文相似性检测系统还是CNKI学术不端文献检测系统,只要尊重知识产权、尊重他人成果,严格文献引用,且做到不过度引用,其论文即使总文字复制比较高,也不会导致论文出现学术不端问题,因为多数情况下,检测结论都要考虑“去除引用文献复制比”。然而实际上,在一些综述性或述评性论文中,可能需要对文献的观点、数据、图表、方法、结果等进行反复讨论,即使每篇文献的引用重复率很低,但因引用文献数量巨大(少则三四十篇、多则百余篇),也可能导致总文字复制比较高,甚至超过30%,但是这种论文撰写方式却是合理的。
尽管万方论文相似性检测系统和CNKI学术不端文献检测系统在文献引证检测和重复率表征方面存在差异,但是它们在文献重复率检测过程中都存在一个共同的问题,就是很难将章节中的文献与正文文字进行区别。检测中发现,当参考文献列于论文最后,此时的参考文献表可以被检测系统当作“文献引证”识别;然而当学位论文以独立的章节为结构单元,每章结尾列出该章参考文献,此时将整篇学位论文拷贝至检测系统,检测系统只将最后一章的参考文献当作“文献引证”进行识别,而将文章其他章节中列出的文献当成正文进行处理。这样带来的后果就是,当该学位论文与第三方论文同时引用某篇或某些文献时,检测系统将该学位论文中的文献作为重复字段计算相似比(如表1所示),这样一方面导致总文字复制比偏高,另一方面也可能导致结论性错误,认为该论文存在剽窃现象。显然,这样检测既不准确也不合理。为了避免该现象的发生,只能将学位论文逐章检测,并根据各章的检测报告,重新计算整篇学位论文的总相似比(如表2所示)。
由表2可以看出,在整体检测中,由于检测系统仅仅对最后一章的参考文献进行了识别,而对第1~5章所列参考文献视为正文进行处理,导致所属各章文字复制比明显偏高,总文字复制比高达34.42%。而采用分章检测后,每章所列参考文献均被检测系统识别,其文字复制比大幅降低,总文字复制比下降至8.92%。显然分章检测结果更加合理。
3 图表相似性检测
图表作为科技论文的组成部分,在原始创新、表征特性、揭示规律等方面具有特别重要的指示意义,很多原始科技数据也都隐含在图表中。然而,在对论文进行相似性检测时,不论是万方论文相似性检测系统还是CNKI学术不端文献检测系统,对图表的检测均显得力不从心。其中,万方论文相似性检测系统没有图表的检测;CNKI学术不端文献检测系统对数据表的识别率很低,而且目前没有图件识别功能。

表1 对某学位论文检测报告的表述片断
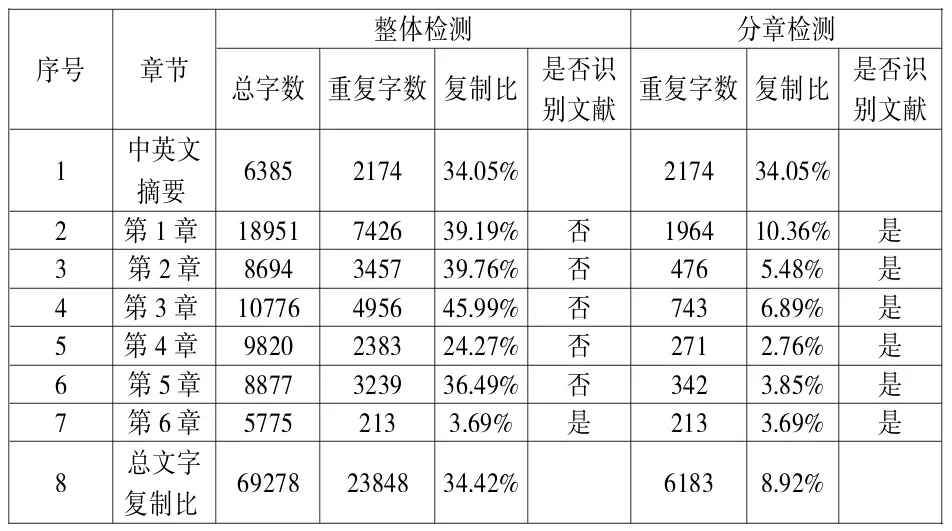
表2 某学位论文整体检测与分章检测结果对比
由于检测系统的局限性,特别是相似图件识别功能的缺乏,导致某些论文作者在检测过程中投机取巧,特别是学位论文。现在学位论文撰写模式已比较固定,多按照中英文摘要、目录、前言、文献综述、实验部分、结果与讨论、结论(或结语)、参考文献等顺序编排;其中,最易出现高重复率的部分是文献综述和实验部分。为了降低重复比,目前有的网站上已经出现了如何使论文在检测过程中“过关”的技巧,如建议将文献综述和实验部分的文字编辑成图片,以蒙混过关。
然而,国外期刊对图表的相似性检测则非常严格,一旦发现其图表具有相似性,一般需采取更正、道歉的方式予以解决,严重的可直接撤消已发表的论文。自2000年以来,我国每年都有类似论文被国际期刊撤消,近几年有增无减。为了更好地对研究者的态度进行正确引导,因此尽快在论文相似性检测系统中增设完善的图表识别功能显得尤为重要和迫切。
论文相似性检测服务是防止学术不端的重要手段,尽管万方论文相似性检测系统和CNKI学术不端文献检测系统都还存在一定问题,但已经为我国教育和科技领域原始知识创新做出了重要贡献。为了弥补其不足,应尽快升级文献引证识别功能、开发图表识别技术,并不断完善检索范围中的文献数据,相信论文相似性检测服务能为检索目标提供更迅速、准确和有价值的评判。
[1]叶铁桥,高四维.德国多名高官因学术不端落马[N].中国青年报,2013-04-10(7).
