Web服务生态系统中消亡服务的预测方法
2014-12-02夏博飞范玉顺黄科满
夏博飞,范玉顺,黄科满
(清华大学 自动化系,北京 100084)
1 问题的提出
随着Web 服务技术和面向服务架构(Service Oriented Architecture,SOA)标准的成熟,一方面互联网上的Web服务种类和数量都急剧增加;另一方面,Web服务个体以动态集成的方式形成服务组合,进而满足用户大规模、个性化、复杂多变的业务需求。由此,大量异质的、具有复杂关联关系的Web服务在相互竞争、协作的过程中,形成了Web服务生态系统[1]。例如,为了适应未来面向服务的网络制造需要[2-3],越来越多的制造业企业将各自的资源封装成Web 服务(如应用程序接口(Application Programming Interface,API)的形式),以便不同资源间的协同合作,逐渐形成了云制造中的Web服务生态系统。但随着时间的推移,Web服务生态系中满足相同功能需求的服务个体越来越多,这些功能上相似的服务个体之间产生了竞争关系。由于竞争淘汰作用,一些服务个体将从服务生态系统中消亡,使得调用这些服务个体的服务组合失效,并对服务使用者产生影响。
图1 所示为选自ProgrammableWeb 中 Web API生态系统中的一个实例。在该服务生态系统中,服务使用者调用发布在网站上的服务个体(API),以Mashup的形式进行服务组合,完成特定的功能。图1中的服务组合ebay in MSN Messenger调用三个服务个体ebay,Microsoft Bing Maps和MSN Messenger,完成一个基于地理位置的在线购物聊天的功能;服务组合Amazon.com Shopping Together调用两个服务个体Amazon Product Advertising和MSN Messenger,完成一个具有网购功能的聊天工具。随着时间的推移,服务个体MSN Messenger无法继续提供聊天功能的服务,因此服务组合ebay in MSN Messenger和Amazon.com Shopping Together均失效,无法完成其原有功能。这种现象正是由服务生态系统中服务个体的消亡引起的。面对复杂随机的网络环境和日益涌现的海量Web服务,服务使用者在选择服务个体时不仅要满足功能上的需求,还要考虑服务个体的可靠性,从而保证形成的服务组合具有持久可用性。然而,仅针对某一个服务个体很难判断其可靠性。因此,需要把多个服务个体看成一个整体,从服务生态系统的角度研究服务个体的消亡问题。由此,本文的工作主要围绕两方面进行:①识别并提取Web服务生态系统中消亡服务个体的特征;②利用消亡服务个体的特征预测潜在的消亡服务个体,最终为服务使用者提供决策意见。

服务标签(tag)作为Web 2.0时代流行的资源识别和管理方法[4],具有门槛低、易用、操作灵活和互动性强等优点,在互联网上被各行各业广泛应用,如图片分享网站Flickr(www.flickr.com)、网页分享网站Delicious(www.delicous.com)、大众点评网(www.dianping.com)和视频网站youku(www.youku.com)等。近年来,一些Web服务注册机构,如Seekda.com,ProgrammableWeb.com 开始对Web服务标注功能描述性的服务标签。相比一些传统Web服务描述方法,如语义Web服务描述语言(Web Services Description Language-Semantic,WSDL-S)[5]、Web 服务描 述语言注释(Semantic Annotation for Web Service Description Language,SAWSDL)[6]、Web 服务建 模本体(Web Service Modeing Ontology,WSMO)、Web服务本体描述语言(Web Ontology Language for Service,OWLS)[7],服务标签虽然在规范性和完备性上不如服务描述文件,但是可以集中概括Web服务所属范畴和涵盖的功能类型。用户通过搜索被标注特定标签的服务或者利用标签云等方式,可以高效地在大量服务中迅速筛选需要的Web服务。因此含有相同标签的服务在满足特定业务需求时存在竞争关系。每一个服务个体标注了若干服务标签,由此产生了复杂的竞争关系网络。本文利用Web服务标签信息,建立服务相似度网络(Service Similarity Network,SSN),采用网络分析法研究服务竞争关系;首次提出服务特征百分比(Feature Percentage Ranking,FPR),进而构建基于FPR 的Logistic回归模型的服务个体消亡概率预测算法。经过ProgrammableWeb上OpenAPI服务生态系统的实证分析,表明该方法能够有效地筛选消亡服务,提高服务组合的持久可用性。同时,实验表明具有个性化功能的服务具备更高的存活率,因此服务提供者应着力于提供具有个性化功能的服务。
2 相关工作
Web 服务领域近年来得到了大量学者的关注[8-11]。随着各方面技术标准的不断成熟,服务个体与服务提供者、服务使用者和服务组合的关系呈现出类生态特性,被称为Web服务生态系统[1]。随着时间的推移,不断有新的服务个体加入系统,具有相似功能的服务个体之间产生竞争关系,部分服务在激烈的竞争中退出系统。这些退出系统的服务个体将使调用这些服务的服务组合失效,影响了服务组合的长期可用性。该问题是Web服务生态系统发展到一定阶段带来的,并且对系统的发展产生了很大的影响。以全球最大的OpenAPI服务生态系统ProgrammableWeb为例:2005年6月到2013年6月,该服务生态系统中消亡的服务个体约占服务个体总数的19%,这些消亡的服务个体使20.5%的服务组合失效,即影响了20.5%的服务使用者[12]。因此分析服务生态系统中服务消亡的机制,预测服务个体的消亡概率,提高服务组合的长期可用性,对促进服务生态系统的良性发展具有重要的意义,然而这方面的研究却十分缺乏。
近年来,许多学者针对Web服务标签做了大量工作。为了解决Web服务的语义描述效率问题,文献[13]提出一种基于多维度标签的Web服务语义描述策略;文献[14]为了解决人工为Web服务标注标签的繁琐工作,提出一种基于Web服务描述语言(Web Service Distribut Language,WSDL)的自动标注标签方法,并实现了原型系统。在服务发现方面,文献[15]给出利用标签和服务描述文本的系统算法,提高了Web服务发现效率的算法,使用户能够清晰高效地描述服务功能需求,从而提高了搜索返回服务的质量。上述这些研究大都从服务标签本身出发,研究内容包括如何为Web服务标注标签以及利用服务标签提高服务发现、功能描述等。
复杂网络分析作为一种研究手段,在Web服务研究领域得到了广泛应用。通过解析Web服务文件接口,文献[7]给出了Web服务网络的模型,从复杂网络的角度分析了服务网络的性质;文献[16]利用复杂网络工具对Web服务领域中的科学工作流网络进行了建模分析,得到了科学工作流中不同服务节点的性质,给出了提高重用率的建议;文献[17]将复杂网络分析作为主要工具,分析了ProgrammableWeb上Mashup服务生态系统的静态特性以及动态演化机制,挖掘了服务生态系统演化的规律,为进一步的Web服务推荐提供了基础。
本文在前人工作的基础上,进一步探究了Web服务生态系统中消亡服务个体的问题。以Web服务标签信息作为切入点,挖掘服务之间的相似性,再从服务相似性推移到服务竞争关系,利用复杂网络方法对Web服务生态系统中服务个体间的竞争关系进行建模,提出一套基于统计机器学习的消亡服务预测方法,可以为服务使用者提供可靠的参考建议。
3 含权服务相似度网络与服务特征百分比
3.1 含权服务相似度网络SSN
服务个体之间的竞争导致服务个体的消亡,包含相似功能的服务个体之间存在着竞争关系[7]。因此,为了挖掘消亡服务个体的特征,需要构建一个描述服务个体功能相似度的网络。在构建SSN 时遵循如下原则:
原则1 服务标签是对服务个体功能的客观描述,被标注相同服务标签的服务个体之间存在竞争关系。例如,Google Maps服务和Yahoo Maps服务都标注了mapping标签,则认为这两个服务之间存在竞争关系。
原则2 提供相同功能的服务个体越多,服务个体之间的竞争就越激烈。例如,标签ti在所有服务个体中出现了100次,标签tj在所有服务个体中出现了10 次,则认为含有ti功能的服务个体之间的竞争更激烈。
原则3 相似功能的服务可能标注的服务标签不同,需要考虑服务标签模糊性的问题。以英文服务标签为例:两个服务分别标注了photo 和picture,虽然具有不同的服务标签,但两个服务显然都提供了图片相关的功能。
基于以上三个原则,引入复杂网络方法研究服务标签与服务的竞争关系。如图2所示,首先构建“服务—标签”二部图。二部图中的节点分为服务节点和标签节点两种;二部图中的边表示服务个体被标注的服务标签。为了消除服务标签的语义模糊性,需要考察标签语义相似度,对“服务—标签”二部图中语义相近的标签节点进行合并。WordNet是普林斯顿大学开发的一个在线语义知识关系库(wordnet.princeton.edu),自发布以来获得了学术界的广泛认可。利用WordNet可以计算两个服务标签的语义相似度[18],判断是否可以合并标签节点。完成相似标签节点合并后,从“服务—标签”二部图中抽取描述服务个体之间相似度的网络,进一步考虑服务标签的频率,抽取标签出现频率关联网络。获得含权服务的相似度网络,用来刻画服务生态系统中服务个体间的复杂相似关系网络,最终得到含权SNN。该网络中的节点表示服务个体,节点之间边的权重表示服务个体间的相似度大小。
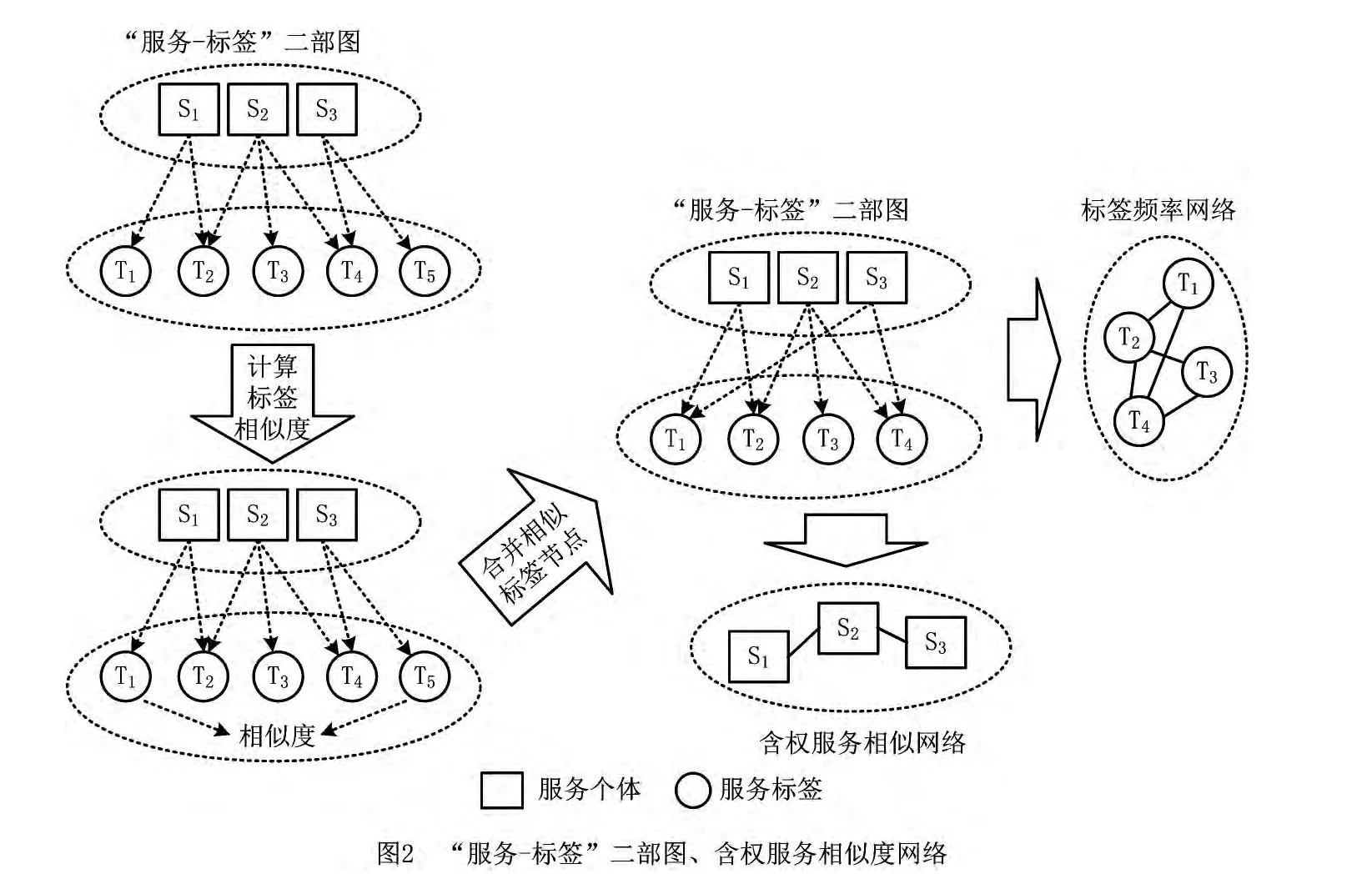
为了规范描述,在文献[16-17]的基础上,给出一种含权SNN 构建算法的矩阵描述,算法流程中涉及三个矩阵,意义如下:
(1)STN=[stnij],0≤i≤N,0≤j≤Index。STN是一个稀疏矩阵,stnij=1表示服务个体i被标注了标签j,stnij=0表示没有被标注标签j,N表示服务个体数,Index表示签数种类数。
(2)TFN=[tfnij],0≤i,j≤Index。TFN是一个对角阵,对角线元素tfnij表示标签i的出现频率。
(3)SSN=[ssnij],0≤i,j≤N。SSN是一个对称阵,ssnij表示服务个体i与服务个体j的相似度,即服务相似度网络中服务节点i与服务节点j之间连边的权值,具体如算法1所示。
算法1 含权服务相似度矩阵SSN的获取算法。
输入:服务、标签二元组集合{〈si,tlisti〉,1≤i≤N}。其中:si表示服务个体i,tlisti表示被标注的标签集合,N表示服务个体总数。
输出:含权服务相似度矩阵SSN。


算法1的基本思路如下:统计所有出现在服务个体中的标签,合并语义近似的服务标签,并为每个标签编号,进而将原始服务标签数据转化成“服务—标签”稀疏矩阵STN;再对STN的列求和,构造服务标签频率矩阵TFN;最终由构造的STN和TFN做矩阵乘法,获得含权服务相似度矩阵SSN。
3.2 服务特征百分比FPR
在获得含权SSN 后,基于该SSN 网络中服务节点的度获取服务的特征,预测服务个体是否消亡。由于在服务生态系统中,服务个体和服务标签的数量均随时间动态变化,即SSN 网络中节点的度也是动态变化的,仅用每个服务节点的度作为特征降低了算法的动态性能。因此,在3.1节的基础上提出FPR 的概念,并给出服务FPR 的获取算法,如算法2所示。
算法2 基于SSN矩阵的服务FPR 提取算法。
输入:含权服务相似度矩阵SSN,N表示SSN矩阵的阶数。
输出:排序含权服务相似度矩阵SSN′。


算法2的基本思想如下:根据每个服务节点在SSN 网络中的相似度之和,对服务节点重新排序编号。由3.1节可知,SSN矩阵是对SSN 网络的一种矩阵描述,其中ssnij代表服务si与sj的相似度且SSN矩阵为对称阵。因此,SSN矩阵的每一行对应一个服务,行号i对应一个服务si。经过矩阵排序算法后,获得SSN 网络的另一种等价矩阵描述SSN′。SSN′也是一个对称阵,矩阵行号对应一个服务,且SSN′是排序后的矩阵,行号i可以作为服务节点si在SSN 网络中的编号。对排名做归一化处理后,定义

为服务si的FPR,每一个加入SSN 网络中的服务节点都有一个FPR。
4 消亡服务个体的预测方法
利用第3章中获取的服务FPR,提出一套基于统计机器学习的Web服务生态系统中消亡服务个体的预测方法。该问题是一个二值分类问题,因此首先用统计学的方法对两类服务个体FPR 的差异性进行假设检验,在判断FPR 差异的显著性后,再设计回归分类算法来预测潜在消亡服务。
4.1 两类服务个体FPR的置换检验
本节通过引入置换检验[19]的方式,量化两类服务个体FPR 值差异的显著性。
服务生态系统中m个消亡服务个体的fpr值为x1,…,xm,均值为;n个非消亡服务个体的fpr值为y1,…,yn,均值为。设检验统计量
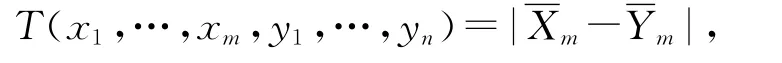
则检验为
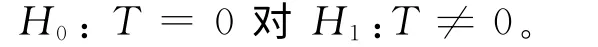
令N=m+n,考虑数据x1,…,xm,y1,…,yn的N!种置换,计算检验统计量T,表示为T1,T2,…,TN。若原假设成立,则T取每个Tj的概率为1/N!。令Tobs表示检验统计量T的观测值,当T很大时拒绝原假设,则p值为

考虑实际Web服务生态系统中的N值较大,计算N!的任务量非常繁重,可以从置换集中随机抽样进而计算p的近似值,计算步骤如下:
步骤1 计算检验统计量观测值Tobs。
步骤2 从N个fpr值中随机抽取m个分配给消亡服务个体,剩下的n个分配给非消亡服务个体。
步骤3 用置换后的数据计算检验统计量。
步骤4 重复步骤1~步骤3K次,令T1,T2,…,TK表示每次结果。
步骤5 近似的p值为
步骤6 由p值判断两类服务FPR 差异的显著性水平。
4.2 Logistic回归模型
Logistic回归是一种经典的二值分类算法,其基本思想是:使用Logit变换作为连接函数,将响应变量的期望与线性自变量相联系[20]。在本文研究中,自变量为SSN 网络中服务个体的FPR 值,响应变量服从Bernoulli分布(规定1 表示潜在消亡服务,0表示非潜在消亡服务)。通过现有SSN 网络中的服务个体训练Logistic回归模型的参数,并计算新加入SSN 网络的服务个体的FPR 值,进而通过模型预测新加入服务生态系统的服务个体是否会潜在消亡。
构建Logistic回归模型如下:定义πi为服务个体si潜消亡的概率,
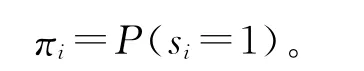
构建Logistic回归方程,其中β0 和β1 为待估参数,
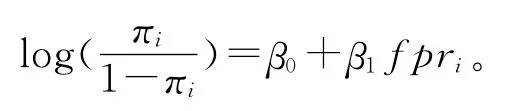
通过回归方程求出πi,
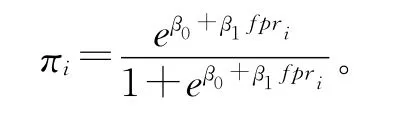
利用现有SSN 网络训练参数β0 和β1。SSN 网络提供的信息包括服务节点si(值为1表示为消亡服务,为0表示为非消亡服务)及其fpri。令N表示训练集构成的SSN 网络中服务节点的个数,采用最大似然估计(Maximum Likelihood Estimation,MLE)方法估计参数β0 和β1。列出似然函数表达式如下:

对似然函数取log对数,可得
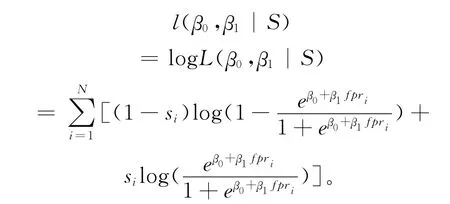
分别对β0 和β1 求偏导数,使其为0,可得方程组
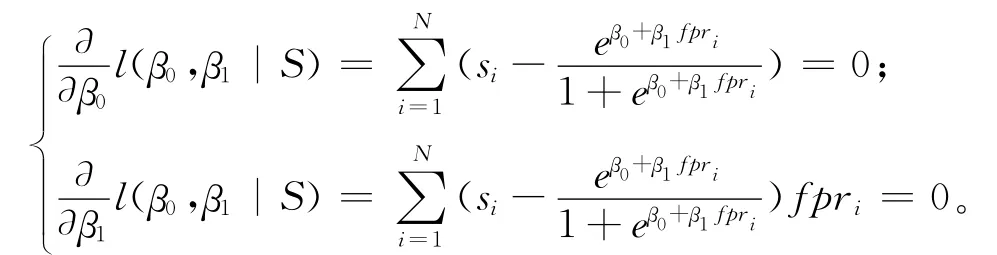
利用Newton-Raphson 数值解法,求出参数的最大似然估计和,完成回归预测模型。给定一个新加入系统的服务个体S,可以求出其特征百分比fpr,进而得到该服务个体潜在消亡的概率π,
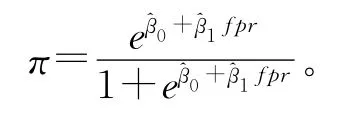
4.3 消亡服务个体的预测算法
在4.1节和4.2节基础上给出完整的潜在消亡服务个体的预测算法,如算法3所示。
算法3 消亡服务个体预测算法。
输入:TagIndex〈tag,index〉(标签编号列表);STN矩阵(行数为N,列数为Index);TFN矩阵(阶数为Index);〈s,tlist〉(待预测服务的服务—标签二元组);(训练数据集得到的Logistic模型参数)。
输出:0-1变量(1表示消亡服务,0表示非消亡服务)。


5 算法验证分析
5.1 实验数据集
本文所用数据集获取自ProgrammableWeb(www.programmableweb.com)——迄今为止最大的在线OpenAPI服务生态系统。在ProgrammableWeb中,服务个体以API的形式被服务提供商发布到网上,使用者调用这些API,并以Mashup的形式将这些API 组合成新的应用。Programma-bleWeb上注册的每个API包括服务提供商信息、在哪些Mashup中出现过,以及服务注册时间和服务消亡时间,并且API都被标注了服务标签。为了研究消亡服务个体对服务组合的影响,对ProgrammableWeb上2005年6月到2012年12月的数据进行整理,清洗掉没有出现在Mashup中的API,筛选出1 176个API,最终得到的数据如表1所示。

表1 ProgrammableWeb数据集
因为预测算法是有监督学习的算法,所以需要按照时间间隔,将ProgrammableWeb 上的数据分为训练集和测试集,如表2所示。
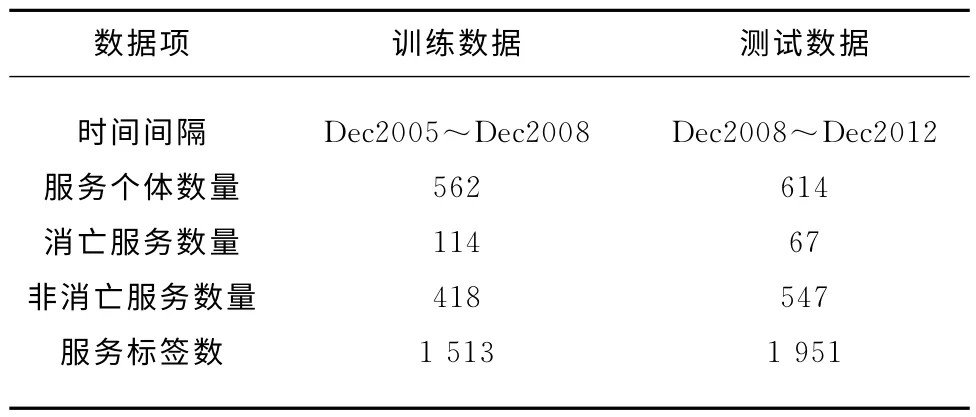
表2 训练数据和测试数据
训练组与测试组的数据包括服务个体、服务标签和服务个体是否消亡的信息。本文利用训练组的数据训练回归模型的参数,预测测试组中的服务个体是否为潜在消亡个体,并与实际数据比对,进而评估预测算法。
5.2 评价指标
利用几个指标检验预测算法的效果。召回率(Recall)和准确率(Precision)[21]是两个最重要的二值分类算法验证指标:在本文中,召回率的意义为算法能够识别全部消亡服务的百分比;准确率的意义为算法能够识别出的消亡服务中有多大比例是真正消亡的服务。二者计算公式如下:
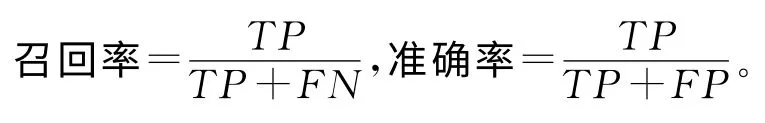
其中TP,FP,TN和FN表示二值分类的四种结果,意义如表3所示。
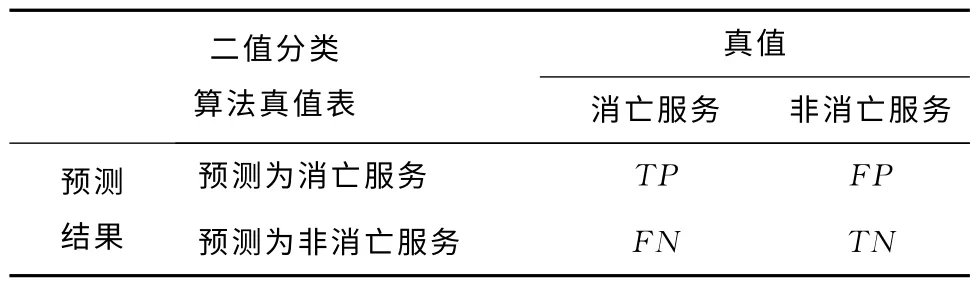
表3 二值分类算法结果
除了准确率和召回率,进一步参考并引入以下几个算法评价指标:
(1)由于准确率和召回率有时是矛盾的,引入F1M(F1-measure)来综合考虑召回率和准确率的效果,当F1M值较大时,测试效果比较好。
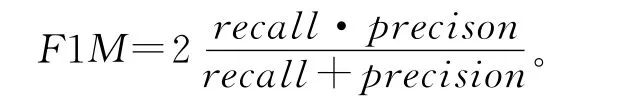
(2)准确率ACC(accuracy)考察了正确预测数占总预测数的比例,当ACC值较大时,预测效果较好。
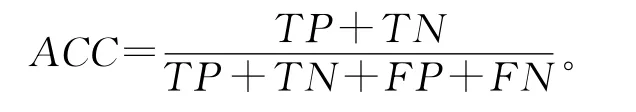
(3)平衡错误率BER(balanced error rate)考察了预测错误数占总预测数的比例,当BER值较小时,算法错误率较低。
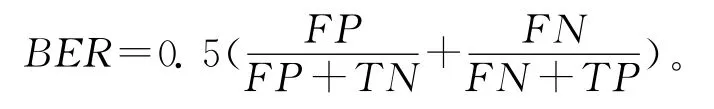
(4)马修相关系数MCC(matthew's correlation coefficient)体现了预测结果与真实数据的相关性,其变化范围为[-1,1]:-1为完全负相关,1为完全正相关。
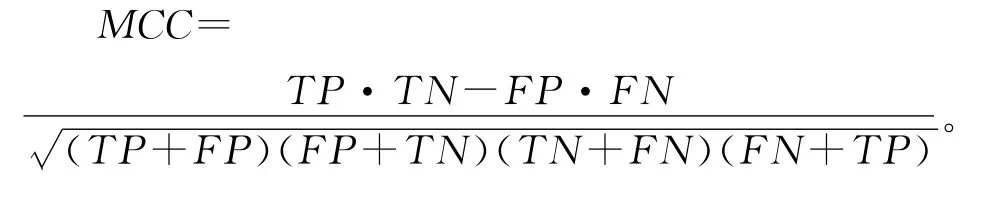
5.3 实验结果
实验中,选用WordNet在Windows平台下最新的版本WordNet 2.1作为服务标签语义相似度判断的词库,并令算法1和算法3中的语义相似度临界值取0.9。首先利用4.1 节中的方法,对两类服务个体FPR 的差异进行显著性检验。检验过程中,取K=10 000,求得p值为0.000 2。即使利用α=0.005的显著性水平,也可以拒绝原假设。检验结果证明消亡与非消亡服务个体间的FPR 值差异显著性很大,FPR 值可以作为区分两类服务的特征。
5.3.1 标签语义模糊对实验结果的影响
首先考虑标签语义模糊对预测算法的影响。将预测算法应用在测试数据集上,考察5.2节中的指标;同时,将没有考虑服务标签语义模糊的算法作为对照组。图3所示为两组测试结果的准确率—召回率曲线及曲线的AUC[23]。
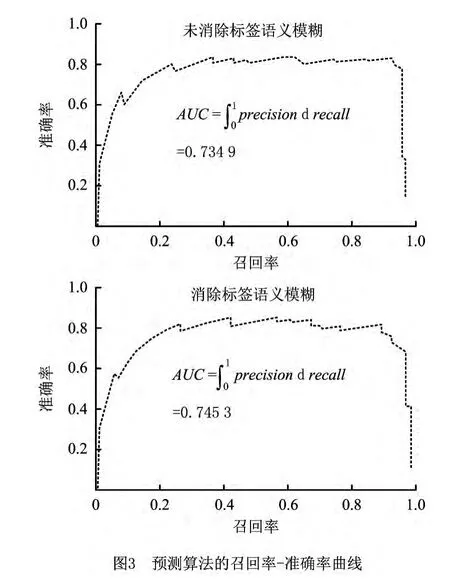
若分类算法召回率—准确率曲线的AUC=0.5,则近似为随机分类,AUC=1则分类算法达到最佳。本文算法的AUC=0.745 3,预测分类算法的综合效果较好。与对照组消除虑服务标签语义模糊的算法相比,AUC高出1.1%。观察召回率—准确率曲线后发现,召回率由0.3增加到0.9的这一段曲线的准确率保持在0.8左右;随着召回率的增大,准确率急剧降低。因此,在保证算法准确率的同时,可以通过改变阈值来提升召回率,从而使算法的准确率和召回率都保持在较高的水平,预测的综合效果更好。
5.3.2 阈值对实验结果的影响
在算法中利用WordNet消除标签语义模糊,再考虑分类算法的阈值对实验结果的影响。令Logistic回归模型中的阈值取不同的值,分别用上述评价指标评估算法,结果如表4所示。从表4中的预测算法评价指标中可以看出,算法召回率随着阈值的增大不断降低,即算法的漏报率升高,但准确率有所提高,即误报率降低。F1M考虑了召回率和准确率的综合效果,其值先随着阈值的增加而增大,当阈值超过一定范围时开始下降;ACC的变化趋势与F1M类似,随着阈值的增加,其值先增大后降低;与ACC对应的BER则先降低再增加;MCC的值随着阈值的增大先上升再下降,表示预测结果与实际数据的相关性先增大后减小。由上述分析,可以根据实际中不同的指标需求来合理选择阈值。
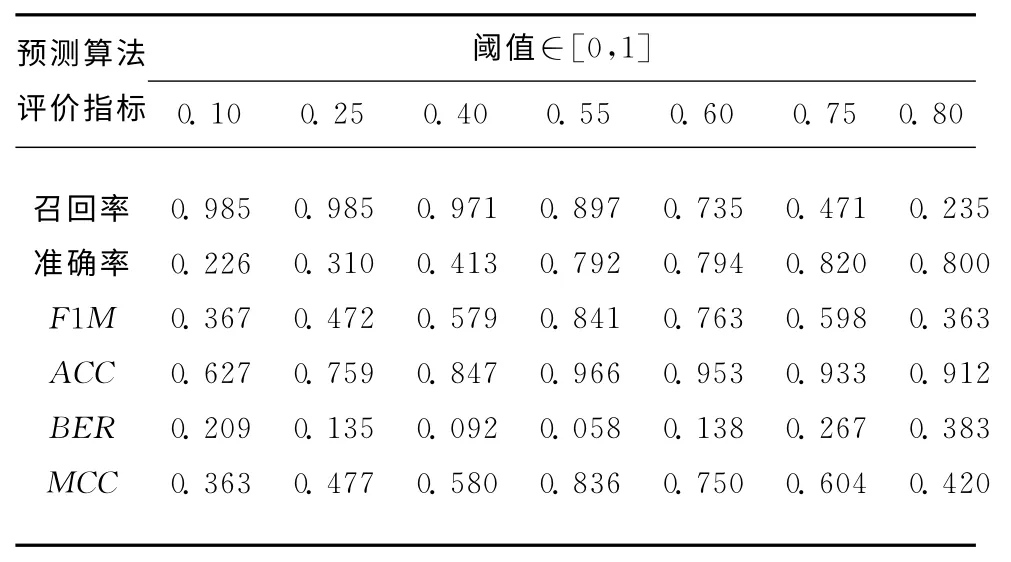
表4 不同阈值下的算法评估结果
5.4 消亡服务特点分析
进一步分析服务生态系统中消亡和非消亡两类服务个体的特点,利用两类服务个体FPR 值的经验分布——累计经验分布(Cumulative Distribution Function,CDF)[19]做定性分析。定义两类服务个体FPR 值的经验分布函数:
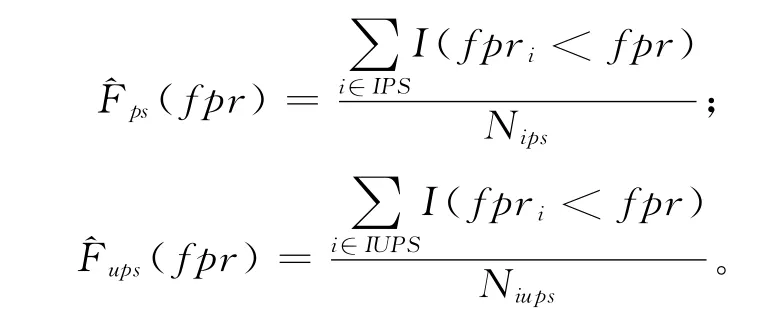
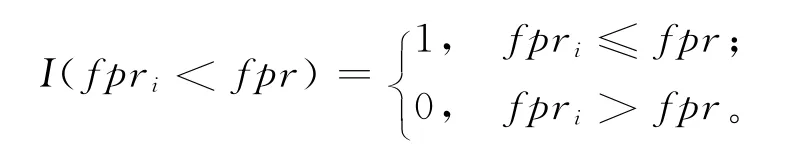
式中:IPS={i|si∈SSN且si为消亡服务个体},表示消亡服务个体在SSN 网络中的编号集合,Nips表示集合IPS中元素的个数;IUPS={i|si∈SSN且si为非消亡服务个体},表示非消亡服务个体在SSN 网络中的编号集合,Niups表示集合IUPS元素的个数。截至2012年12月,统计了两类服务个体FPR 值的经验分布,如图4所示。
图4中的两类服务个体的FPR 经验分布有明显区别:以FPR 的某一个取值为分界点,两种服务个体的FPR 在分界点的两侧近似服从均匀分布,即消亡服务个体的FPR 值偏大,非消亡服务个体的FPR 值偏小。
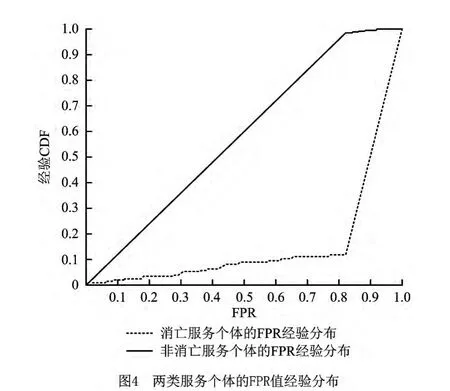
进一步分析SSN 网络中FPR 值大的服务个体的特点。以SSN 网络中的一个服务Gowalla为例,Gowalla 的服务 标签有location,social,mobile,mapping,places,但服务生态系统中提供mapping功能的服务有Google Maps,Bing Maps等,提供location功能的服务有foursquare等,提供social功能的服务有Facebook等。虽然Gowalla服务涉及多个热门领域,但每个领域都有提供相似功能的其他服务个体与其竞争,因此Gowalla最终从服务生态系统中消亡。不但Gowalla服务,而且其他FPR值大的服务个体都具有这种特点:涉及服务生态系统中的多个热门领域,具有大而全的特点,但并没有突出的功能特点;相反,服务生态系统中FPR 值小的服务大多只涉及某一个热门领域,服务功能小而精,因此更容易在服务生态系统中存活下来。
6 结束语
随着Web技术的快速发展和SOA 架构的广泛应用,大量的Web服务被发布到Internet环境中,并在长期的协同竞争过程中形成了服务生态系统。本文从服务生态系统出发,基于Web服务竞争关系研究服务消亡的机制,提出潜在消亡服务的预测算法,分析了服务生态系统中消亡服务个体的特点,并最终为服务使用者和服务提供商提供建议。
具备相似功能的Web服务存在竞争关系,因此本文利用服务标签的相似性刻画服务个体功能的相似性,进而构建含权服务相似度网络,量化服务个体的竞争关系。通过分析含权服务相似度网络中服务个体的FPR,发现消亡和非消亡服务个体的FPR分布呈现明显的差异性:含权服务相似度网络中FPR 大的服务个体所提供的功能大多具有大而全的特点,即提供多个热门功能,但每个功能都不够完善,因此不容易在服务生态系统中生存下来;FPR小的服务个体,所提供的功能大多具有小而精的特点,即只专注某一个方面的功能,并不断完善,因此在服务生态系统中生存的机会更大。
进一步通过置换检验的方式发现消亡和非消亡服务个体间FPR 值的分布差异十分显著。因此,提出基于Logistic回归模型的潜在消亡服务预测算法,利用服务个体的FPR 值训练模型,预测新加入系统的服务个体是否会消亡。基于ProgrammableWeb上OpenAPI数据的实证分析,表明算法的召回率、准确率等指标均在较高的水平,该方法能够有效预测消亡服务,从而给服务使用者提供可靠的建议。
本文只考虑了服务个体之间的相似度关联对消亡服务、服务组合质量的影响。在后续的工作中,将进一步考虑其他服务个体关联对服务组合质量的影响。
[1]BARROS A,DUMAS M.The rise of Web service ecosystems[J].IT Professional,2006,8(5):31-37.
[2]LI Bohu,ZHANG Lin,WANG Shilong,et al.Cloud manufacturing:a new service-oriented networked manufacturing model[J].Computer Integrated Manufacturing Systems,2010,16(1):1-7,16(in Chinese).[李伯虎,张 霖,王时龙,等.云制造——面向服务的网络化制造新模式[J].计算机集成制造系统,2010,16(1):1-7,16.]
[3]LI Bohu,ZHANG Lin,REN Lei,et al.Further discussion on cloud manufacturing[J].Computer Integrated Manufacturing Systems,2011,17(3):449-457(in Chinese).[李伯虎,张霖,任 磊,等.再论云制造[J].计算机集成制造系统,2011,17(3):449-457.]
[4]NING Da,HE Keqing,PENG Rong,et all.An automatic emerging approach for Web service semantics based on social tagging[J].Chinese Journal of Computers,2011,38(12):2414-2426(in Chinese).[宁 达,何克清,彭 蓉,等.基于社会标注的Web 服务语义自动浮现方法[J].计算机学报,2011,38(12):2414-2426.]
[5]NAGARAJAN M,VERMA K,SHETH A P,et al.Semantic interoperability of Web services-challenges and experiences[C]//Proceedings of IEEE International Conference on Web Services.Washington,D.C.,USA:IEEE,2006:373-382.
[6]ZEIN O K,KERMARREC Y,GARLATTI S,et al.A metadata model for Web services applied to index and discover elearning services[C]//Proceedings of the 2nd International Conference on Information and Communication Technologies.Washington,D.C.,USA:IEEE,2006:626-630.
[7]WANG Hui,FENG Zhiyong,SUI Yang,et al.Service network:an infrastructure of Web services[C]//Proceedings of International Conference on Intelligent Computing and Intelligent Systems.Washington,D.C.,USA:IEEE,2009:303-308.
[8]YUN Bensheng,YAN Junwei,LIU Min.Method to optimize Web service composition based on Bayes trust model[J].Computer Integrated Manufacturing Systems,2010,16(5):1103-1110(in Chinese).[云本胜,严隽薇,刘 敏.基于Bayes信任模型的Web服务组合优化方法[J].计算机集成制造系统,2010,16(5):1103-1110.]
[9]ZHENG Jian,JIANG Jianhui.Labeled transition system based decision method for Web service behavior mismatch type[J].Computer Integrated Manufacturing Systems,2011,17(12):2743-2751(in Chinese).[郑 剑,江建慧.基于标签转换系统的Web服务行为失配类型的判定方法[J].计算机集成制造系统,2011,17(12):2743-2751.]
[10]ZHU Xilu,WANG Bai.Web service selection algorithm based on uncertain quality of service[J].Computer Integrated Manufacturing Systems,2011,17(11):2532-2539(in Chinese).[祝希路,王 柏.基于不确定服务质量的Web服务选择算法[J].计算机集成制造系统,2011,17(11):2532-2539.]
[11]FENG Jianzhou,KONG Lingfu,WANG Xiaohuan.Web service automatic composition based on semantic relationship graph [J].Computer Integrated Manufacturing Systems,2012,18(2):427-436(in Chinese).[冯建周,孔令富,王晓寰.基于语义关系图的Web服务自动组合方法[J].计算机集成制造系统,2012,18(2):427-436.]
[12]XIA Bofei,FAN Yushun,HUANG Keman.A method for predicting perishing services in a service ecosystem[C]//Proceedings of the International Conference on Service Science.Washington,D.C.,USA:IEEE,2013:13-17.
[13]NING Da,HE Keqing,PENG Rong,et al.A multi-dimensional social tagging method for semantic Web services[C]//Proceedings of International Conference on Services Computing.Washington,D.C.,USA:IEEE,2011:735-736.
[14]FANG Lu,WANG Lijie,LI Meng,et al.Towards automatic tagging for Web services[C]//Proceedings of the 19th International Conference on Web Services.Washington,D.C.,USA:IEEE,2012:528-535.
[15]CHUKMOL U,BENHARKAT A N,AMGHAR Y.Enhancing Web service discovery by using collaborative tagging system[C]//Proceedings of the 4th International Conference on Next Generation Web Services Practices.Washington,D.C.,USA:IEEE,2008:54-59.
[16]TAN Wei,ZHANG Jia,FOSTER I.Network analysis of scientific workflows:agateway to reuse[J].Computer,2010,43(9):54-61.
[17]HUANG Keman,FAN Yushun,TAN Wei.An empirical study of programmable Web:a network analysis on a servicemashup system[C]//Proceedings of the 19th International Conference on Web Services.Washington,D.C.,USA:IEEE,2012:552-559.
[18]PEDERSEN T,PATWARDHAN S,MICHELIZZI J.WordNet∷similarity-measuring the relatedness of concepts[C]//Boston,Mass.,USA:Association for Computational Linguistics,2004:1024-1025.
[19]WASSERMAN L A.All of statistics[M].ZHANG Bo,LIU Zhonghua,WEI Qiuping,et al.transl.Beijing:SciencePress,2008:74-75,127-129(in Chinese).[L·沃塞曼.统计学完全教程[M].张 波,刘中华,魏秋萍,等,译.北京:科学出版社,2008:74-75,127-129].
[20]PETER D.Introductory statistics with R[M].2nd ed.Berlin,Germany:Springer-Verlag,2008:227-247.
[21]SU L T.The relevance of recall and precision in user evaluation[J].Journal of the American Society for Information Science,1994,45(3):207-217.
[22]YANG Yiming.An evaluation of statistical approaches to text categorization[J].Information Retrieval,1999,1/2(1):69-90.
