一种语音识别的可定制云计算方法*
2014-12-02贾玉辉张志楠
张 巍,贾玉辉,张志楠
(中国海洋大学信息科学与工程学院,山东 青岛 266100)
语音识别始于1950年代初,当时,贝尔实验室的Davis等人研究成功了第一个可识别10个英文数字的语音识别系统-Adudry。1980年代末,美国卡内基·梅隆大学用VQ/HMM方法实现了世界上第一个高性能的非特定人、大字表、连续语音识别系统—SPHINX[1]。在此期间语音识别处于实验室研究阶段,市场上没有成型的产品。直到1990年代初,随着在系统的自适应性、参数提取及优化等技术上取得了一些关键性的进展,语音识别技术进一步成熟,并开始向市场提供产品[2]。从此语音识别开始从实验室逐步走向实用。并且,在一些应用领域,它正迅速地成为一个关键的、而且具有竞争力的技术。
从产品的实现平台上来看,当前市场上的语音识别系统主要分为3种:嵌入式的语音识别系统、服务器模式的语音识别系统及云计算模式的语音识别系统。嵌入式语音识别系统[3]是指应用各种先进的的微处理器在板级或是芯片级用软件或硬件实现语音识别技术。由于嵌入式平台存储资源少、性能低、实时性要求高,嵌入式语音识别系统只适合做算法要求相对简单,对资源的需求较少的语音识别,比如中小词汇量的命令词识别等。在服务器模式的语音识别系统中,终端只负责收集和传导语音信号,由服务器负责完成识别。这种模式可以做高性能的大词汇量连续语音识别。并且对于大规模、多用户和有大量识别需求的系统,服务器模式提供了较为有效的解决方法。在一般情况下,服务器都选择价格昂贵的巨型机或者大型机来充当,当用户访问量较少时,传统的服务器模式,完全可以应对。但随着用户访问量的增加,所需服务器数量也会相应增加,在这种情况下,公司的运营成本就会急剧攀升。随着服务器数量的增加,服务器的管理就会变得非常复杂,并且服务器数目扩充到一定数目,就可能会达到性能瓶颈,使得单纯的增加服务器,对系统性能提升收效甚微。云计算模式的语音识别系统和服务器模式的语音识别系统类似,主要是有云端负责完成识别。相对于传统的服务器架构,云[4]具有更好的扩展性,成本更加低廉,并且可以具有超大规模,给用户提供前所未有的计算能力。且不难得知,用来学习、训练的样本数据集越大,语音识别系统的性能越好。这就需要解决大数据存储及处理的问题。而云计算恰好能很好的解决这2个问题。云计算技术和语音识别相融合是1种新的趋势。但现在基于云计算的语音识别技术正处于发展初期,技术仍未成熟,并且市场上的产品只提供面向通用领域的语音识别服务。无法对语音识别服务进行定制。
由上可知,嵌入式的语音识别系统功能极其简单,并且应用范围较窄;服务器模式的语音识别系统能提供较为复杂的功能,且可以应对较多用户的请求,但面对海量用户请求却无能为力;云计算模式的语音识别系统可以应对海量用户请求,且可以利用海量用户数据优化语音识别系统的性能,但由于其尚处于发展初期,基于云的语音识别服务提供商尚未提供可定制的语音识别服务,他们的语音识别模型不能按照用户的需求而更改,用户不可根据自己的实际情况对语音识别模型进行定制。如果模型可以定制,就可以提供针对特定领域的语音识别服务,而无需关注其他领域,显然这样更容易获取高识别率,更容易满足特定用户。针对以上情形,本文提出了1种面向特定领域的云计算方法,并简单实现了1个云计算架构的语音识别系统(Speech Recognition System Based on Cloud Computing,SRSCC),可以对这些领域的用户提供可定制的语音识别服务,满足用户的个性化需求,改善用户的使用体验。
本文首先研究了MapReduce模型,并给出了语音识别的MapReduce流程。然后通过使用开源的流式MapReduce工具-Sector/Sphere[6-8]及主要用于语音识别研究的HTK[9]工具包,实现了语音识别技术与云计算技术的融合,即SRSCC系统。并在此基础之上,给出了语音识别的可定制性方法,使得该系统能为特定领域的用户提供可定制的服务。最后,通过实验评估了系统的性能及系统的可扩展性。
1 MapReduce编程模型
1.1 模型介绍
MapReduce[5]是 Google提出的1个编程模型,主要用于大规模数据的并行运算,通过将MapReduce模型应用到语音识别系统,能加快系统对用户请求的处理速度。MapReduce是1种处理大规模数据集的编程模型,同时它也是1种高效的任务调度模型,它主要有“Map(映射)”和“Reduce(化简)”2个过程组成,这2个过程构成了运算基本单元[10-11]。Map函数用来指定对各分块数据的每一个元素所进行的操作,而reduce函数用来对各分块数据处理的中间结果进行归约。用户在设计分布式程序时,只要实现map和reduce 2个函数,至于其他细节,比如如何将输入的数据分块、任务调度、机器容错以及节点间通信的管理等,都可交由MapReduce框架处理。
MapReduce模型具有具有极强的容错性。集群中的每个worker节点会周期性的把完成的工作及状态的更新报告发给master节点,如果1个worker节点保持沉默超过1个预设的时间间隔,master节点就会把这个节点的状态改为死亡,并把该worker节点上执行的程序及数据迁移到其他worker节点上重新执行。而当master节点出错时,可以根据最近的1个检查点重新选择1个节点作为master,并由此检查点位置继续运行。
1.2 语音识别的MapReduce过程
随着语音识别技术的广泛应用,语音识别必然会面临海量请求所带来的挑战。比如面对亿万用户的请求如何更快的进行处理、响应;如何存储海量用户数据;如何使语音识别模型能处理更大的训练集,以获得更高的识别率等等。MapReduce是1个可靠地容易进行编程操作的大数据并行计算模型。如果把MapReduce模型应用到语音识别上面,则可以轻松应对这些挑战。
图1给出了语音识别的1种MapReduce处理过程,图中的wav11是用户一上传的第一个语音文件,wav12是用户一上传的第二个语音文件,result11和result22分别是2个语音文件对应的识别结果,user1是用户一,其他的雷同。这个处理过程显示的是不同用户上传文件,通过MapReduce过程,生成该用户所上传语音的结果集,然后把这个结果集返给用户。单个语音的识别结果在映射这一环节得出,然后在化简环节,按照语音文件识别结果所对应的用户进行规约,最终得到各个用户所上传语音的识别结果集。
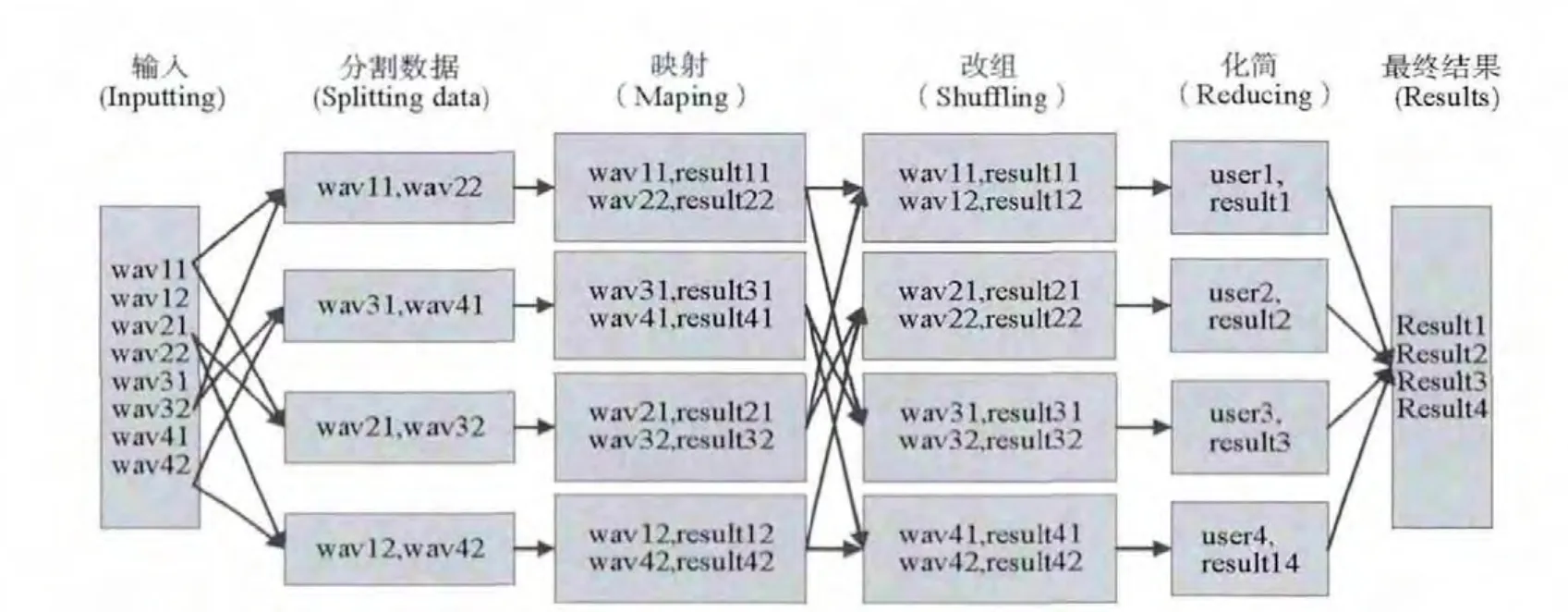
图1 语音识别的MapReduce处理过程Fig.1 MapReduce process of speech recognition
2 SRSCC语音识别系统
2.1 系统组成
SRSCC云端系统架构主要包括3个部分:安全服务器、管理服务器、及奴隶节点。安全服务器主要负责维护用户账号、密码、以及对每个文件或目录的操作权限等。它也维护了1个IP地址列表,用来指出哪些奴隶节点可以加入系统,从而使非法节点无法访问和干扰系统,保证整个系统的安全性。管理服务器主要主要负责维护存储文件的元数据以及控制所有奴隶节点的运行并且对用户的请求作出响应。管理服务器可以直接与安全服务器进行通信,从而验证奴隶节点和用户的合法性。奴隶节点上部署有语音识别环境,用户上传的录音文件存储在奴隶节点上,并且奴隶节点负责识别这些文件,生成识别结果。
2.2 语音识别的Sphere处理流程
Sphere被用来设计执行用户自定义函数。这些函数并行的以1种流的方式来处理Sector管理的数据。这意味着同一个用户自定义函数会应用到1个数据集的每一个数据记录。这个过程是并行的,并且对数据集的每一段数据记录的处理是独立完成的(假若有足够的处理器可以用)。
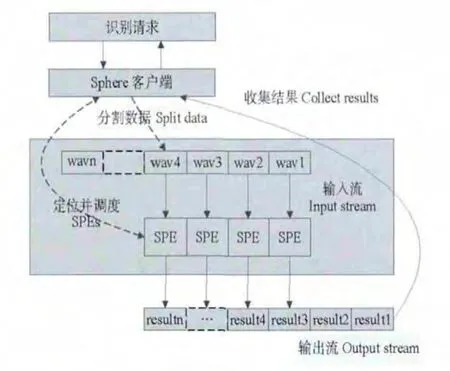
图2 语音识别的Sphere计算范式Fig.2 Computing paradigm of speech recognition
语音识别的Sphere计算范式见图2,识别请求和Sphere客户端进行通信,Sphere客户端首先收集有关输入流的信息,包括总的大小,文件的数目等等。其次Sphere客户端通过寻找和处理函数同名的动态链接库文件的方式定位所需服务的提供者,或者SPEs(Sphere Process Engines,SPE数据处理逻辑单位,可以处理1个数据段,1组数据或者整个文件)。语音识别的动态链接库文件也存放在Sector系统中。基于这些信息,Sphere客户端把输入流分割成数据段(本文中整个语音文件作为1个数据段来处理)。通常情况下数据段的数目要远大于SPEs的数目。在开始的作业中,给每一个SPE分配1个数据段并开始进行处理。一旦处理过程完成,得出结果,再给这个SPE分配一个新的数据片段来处理。这个结果流(输出数据)或者返回给用户,或者写入存放在Sector的文件中,等待进行下一步处理。
2.3 SRSCC系统整体架构
在该系统中,用户不与云端服务器直接交互,由Sphere客户端充当中间媒介。当录好音生成的文件上传到客户端时,该客户端就会登录到Sector/Sphere云,把文件交予云端服务器的slave节点处理。虽然当用户较少时,该架构显得有点繁琐,但用户访问量较大时,它就会发挥出高效的性能。在master的管理下,云客户端直接与slave进行交互,上传数据。SRSCC语音识别系统整体架构流程图见图3。
3 可定制性实现
3.1 语音识别的可定制性

图3 CCSR系统架构流程图Fig.3 Architecture flowchart of CCSR system
所谓可定制性是指用户可根据自身的需求,来定制自己所需要的产品和服务,以满足自己的个性化需要。比如软件的可定制性就是指可根据用户的具体情况,具体要求来设计软件系统,提供相应服务。而语音识别的可定制性,在这里是指,用户可以根据自己的实际需要来定制语音识别模型。通用的语音识别器,例如Google的语音搜索,用户只能用来做识别,而不可能更改它的语言模型(Language Model)和声学模型(Acoustic Model)。但可定制的语音识别器,可以更改语音模型和声学模型。比如一些特定领域的用户,只需使用自己特定领域的语音来进行训练,无需关注其他领域的语音。这样可使语音识别模型的生成变得更加简单和高效。并且在一般情况下比通用领域的语音识别识别模型具有更高的识别率。先前做过1个实验。只针对菜名进行训练,得到1个只识别菜名的模型。经过测试发现,这个只面向菜名的语音识别器对菜名语音的识别正确率为87%,而Google语音搜索对菜名的识别正确率只有44%。
3.2 实现方法
针对有特殊需求,需要定制语音识别模型的用户,本文在Sector系统中为其创建对应的文件夹,以存放用户自己的语音识别模型。可以通过以下2个途径来实现语音识别模型的可定制性。一是用户可以自己上传语音识别模型到指定的文件夹下。由于本系统的语音识别环境是用HTK搭建的,而使用HTK生成语音识别模型有相对统一的规范。所以用户可以使用HTK来录制自己本领域的录音训练样本,并训练生成用来做语音识别的隐马尔科夫模型,然后上传到云端。当用户进行语音识别时,云端可根据用户的IP地址找到其对应文件夹下的语音识别模型进行识别。二是用户可以指定自己语音识别模型的识别范围。当使用语音识别模型进行识别时只针对识别范围内的语音进行加强,从而逐步达到用户对特定领域语音进行识别的要求。
4 实验评估
实验室先前实现了1个C/S架构的语音识别系统。下面做了2个实验,一个是云架构的语音识别系统和传统的C/S架构的语音识别系统进行对比,证明云架构的语音识别系统在用户请求数较大时有更好的表现;另一个是云架构语音识别系统内的对比,通过运行不同的slave节点数,证明云架构语音识别系统具有一定的可扩展性。由于录音环节,会花费大量时间,且在录音的过程中,云端和服务端都处于闲置状态,而本实验的主要目的是测试云端和服务端的性能。所以为了使云端和服务端一直运行,达到性能极限,本实验去掉了录音环节,改为直接上传已经录好的语音文件。
4.1 实验环境
为了验证SRSCC语音识别系统性能,本文选择了4台一般的PC机搭建了1个较小的Sector/Sphere云计算平台,详细配置见表1。
由表1可知,集群中部署了1个Security Server节点,1个Master节点,11个slave节点。对于C/S架构的语音识别系统的服务器,本文选择配置最高的PC1来充当。
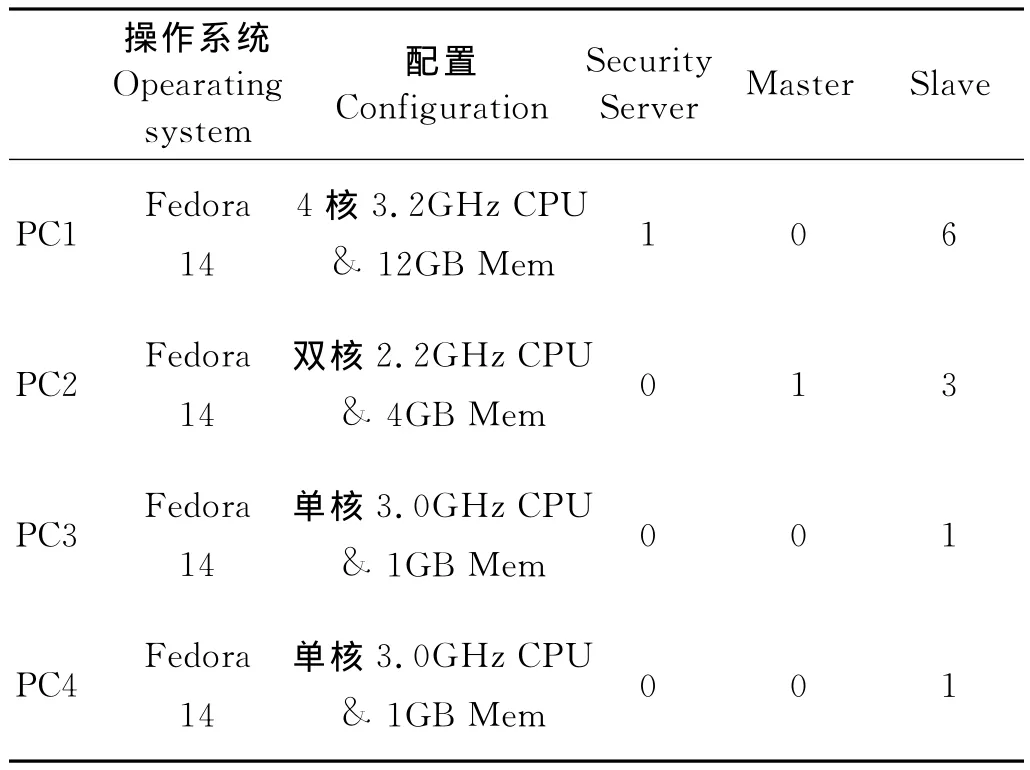
表1 Sector/Sphere集群环境Table1 Sector/sphere cluster environment
4.2 性能对比
本实验主要对SRSCC语音识别系统和传统的C/S架构的语音识别系统进行对比。所用实验数据为实验室人员录制的12 000个菜名录音文件。实验场景为每个系统有10个用户连续上传录音文件,系统对录音文件进行处理,然后返回结果。通过改变用户上传的文件数量,来得到每个系统对不同数目请求的时间变化趋势。然后对这种趋势进行对比,得出最终结论,具体结果见图4。图中横轴为每个用户上传的文件数,纵轴为总的处理时间(从上传第一个文件,到最后一个文件返回结果)。TRA代表传统C/S架构的语音识别系统,NCC代表云计算架构的语音识别系统,即SRSCC语音识别系统。由图可知,虽然刚开始用户请求量较少时两者所用时间相差不大,但SRSCC语音识别系统的处理时间增长速率要低于传统服务器模式的语音识别系统。并且从图中可以看出当每个用户的上传量达到1 200个时,传统语音识别系统就遇到了性能瓶颈,时间增长速率出现了拐点。可见看出云架构的语音识别系统有效的推迟了拐点的到来。从而可以得出,SRSCC语音识别系统具有更好的性能,更有能力面对大用户请求挑战,更符合语音识别的发展趋势。
4.3 节点数对性能的影响
实验的数据集是12 000个录音文件,并且只对这些录音文件进行简单的识别操作。图5显示的是识别这12 000个录音文件所花费的时间受集群节点数影响的情况。有图5可知随着节点数量的增加,识别这12 000个文件所花费的时间在逐渐减少。虽然随着节点的增加所用时间减少的速率逐步趋缓,但可以得出随着数据集量的增加,可以通过增加节点数来提高语音系统的性能。这也从侧面说明了云计算架构的语音识别系统具有一定的可扩展性。
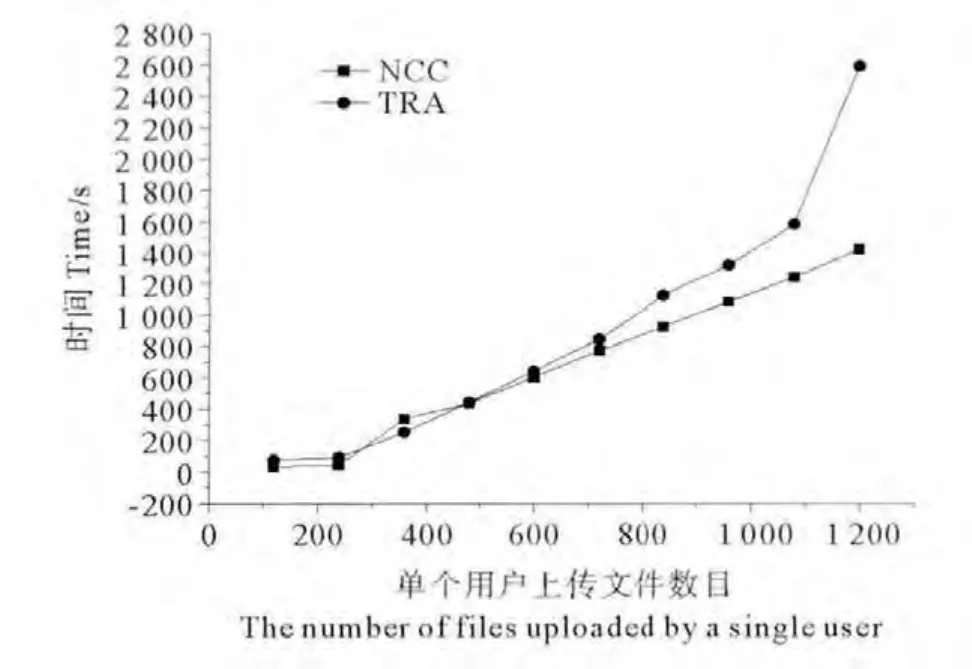
图4 传统架构和云计算架构在语音识别上的性能对比Fig.4 Comparison between traditional architecture and cloud architecture in speech recognition
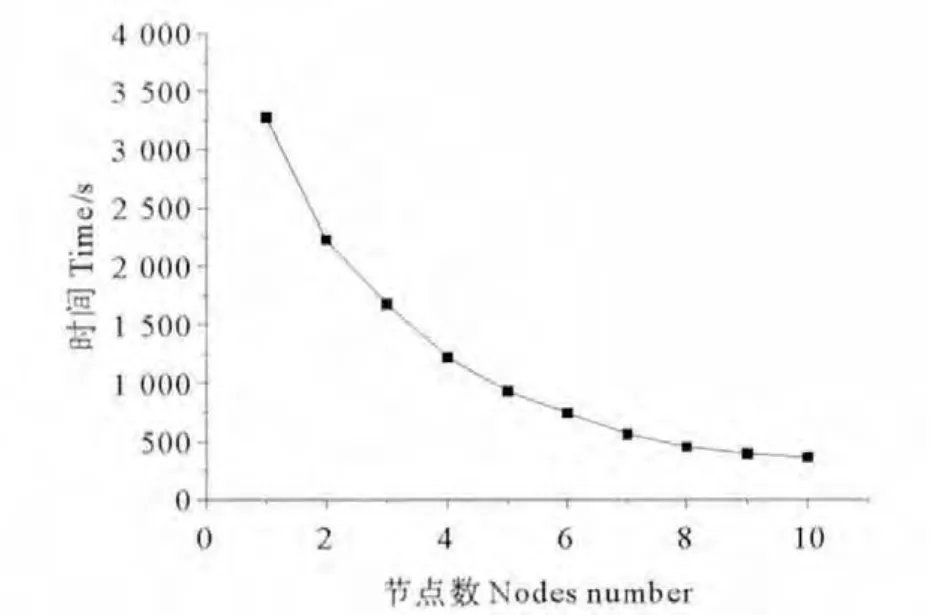
图5 集群节点数量的影响Fig.5 Effect of number of nodes
5 结语
本文结合 MapReduce编程模型,利用Sector/Sphere工具实现了SRSCC语音识别系统,并给出了语音识别模型的可定制性方法。实验表明,SRSCC语音识别系统与传统服务器模式的语音识别系统相比,具有更好的性能,更有能力面对大用户请求所带来的挑战。并且该系统具有一定的可扩展性。但本文所搭建的云计算系统规模较小,功能比较简单,下一步要完善系统的功能,扩大系统规模,从而得到更好的结果。
[1]Lee K F.Automatic Speech Recognition:The Development of the Sphinx System[M].Boston:Kluwer Academic Publishers,1989.
[2]刘加.汉语大词汇量连续语音识别系统研究进展[J].电子学报,2000,28(1):85-91.
[3]方敏,浦剑涛.嵌入式语音识别系统的研究和实现[J].中文信息学报,2004(6):73-75.
[4]Michael Armbrust,Armando Fox,Rean Grith,et al.Above the clouds:A berkeley view of cloud computing[R].Technical Report UCB/EECS-2009-28,EECS Department,University of California,Berkeley,2009.
[5]Dean J,Ghemawat S.MapReduce:Simplified data processing on large clusters[C].//Proc of the 6th Symp on Operating System Design and Implementation,Berkeley:USENIX Association,2004:137-150.
[6]Robert Grossman,Yunhong Gu.Data Mining Using High Performance Data Clouds:Experimental Studies Using Sector and Sphere[C].SIGKDD 2008,Las Vegas:NV,2008.
[7]Yunhong Gu,Li Lu,Robert Grossman,et al.Processing Massived Sized Graphs using Sector/Sphere,3rd Workshop on Many-Task Computing on Grids and Supercomputers[C].co-located with SC10,LA:New Orleans N,2010:15.
[8]Yunhong Gu,Robert Grossman.Sector and Sphere:The design and implementation of a high performance data cloud[J].Theme Issue of the Philosophical Transactions of the Royal Society A:Crossing Boundaries:Computational Science,E-Science and Global E-Infrastructure,2009,v 367(1897):2429-2445.
[9]Young S J,Evermann G,Gales M J F,et al.PC (2006)The HTK Book Version 3.4[M].Cambridge:Cambridge University Engineering Department,2006.
[10]Dean J,Ghemawat S.Distributed Programming With MapReduce[M].//Oram A,Wilson G,eds.Beautiful Code,Sebastopol:O’Reilly Media Inc,2007:371-384.
[11]Dean J,Ghemawat S.MapReduce:a flexible data processing tool[J].Communications of the ACM,2010,53(1):72-77.
