基于单波束测距声呐的水下机器人避障仿真研究
2014-12-01黄朝熙吴海涛吴道曦徐素霞
黄朝熙,潘 伟,陈 杰,吴海涛,吴道曦,徐素霞
(福建省仿脑智能系统重点实验室(厦门大学),厦门大学信息科学与技术学院,福建 厦门361005)
由于海洋环境的探测面积巨大,水下环境的复杂多变,传统的定点或走航式的作业方式,越来越难以适应新的海洋探测需求,自主式水下航行器(autonomous underwater vehicle,AUV)的研究与应用便成了自然.AUV可以自主地在远程复杂甚至危险的海洋环境之中运行,在海洋探测、海底地形绘制、海洋资源探测等各方面扮演着重要角色.
为了使AUV完成海洋环境检测、海底救捞及水下作业等复杂任务,保证AUV自身的安全是一切任务开展的前提.具备自主避障功能的AUV的研究与应用,受到越来越多研究者的重视.Qiao等[1]利用神经网络的学习能力,用近似Q函数的方式来存储Q值,其基于行为的控制架构使其获得了更好的稳定性和更优的实时性,通过一段时间的学习能使机器人有效地躲避障碍物.Sayyaadi等[2]提出了基于强化学习算法随机值的学习函数,通过得到连续的输出值使AUV具备更强的控制能力使其达到避障能力.Jia等[3]提出了针对AUV的一个基于势函数和行为规则的控制算法,通过对避障区域的划分,有效地解决了势函数控制算法只适用于较大避障半径的问题,验证了多AUV编队在未知的环境中控制和避障算法的有效性.这些算法在避障的稳定性和实时性方面都进行了不同程度的优化,对各自算法存在的不足都进行了改进,存在的不足主要是计算量的差异.此外,目前研究的大多数AUV系统需要接受上位机的控制,缺乏有效的信息获取手段,无法适应复杂多变的水下环境.因此,研究集成有多种传感器的AUV系统,提高水下航行器的自主运动能力和避障功能,具有非常重要的意义.比如Khanmohammadi等[4]设计了一个基于前视声呐信息的模糊鲁棒控制器,通过声呐对障碍物的速度和角度信息能较为精确的获取,使AUV能实现自主躲避动态的障碍物;Zhang等[5]通过建立水下环境模型,对遗传算法进行优化,提高了对多障碍情况下的位置和速度等数值的优化处理,达到了有效的水下避障,并在名为“Twin-Burger”的AUV上实验成功;McPhail等[6]基于高分辨率的彩色成像技术和多波束声呐的应用,提出了重试避碰算法的调用机制,有效地补充了其默认避障算法的不足,提高了避碰的成功率.AUV系统中的控制算法是基于声呐探测的范围和标高相对于AUV的水平线来实现的,“Autosub6000”号AUV在大西洋的卡萨布兰卡海山区的深水海试结果显示了其良好的避障效果.这些基于大型传感器设备的避障实验在已有算法的基础上,能较好地达到避障的效果,显示出一定的应用前景,但是其高额的资金投入限制了推广应用.
AUV要实现避障的行为,环境传感器数据起着举足轻重的作用.很多的科研机构使用基于多波束的前视声呐来采集AUV周围环境障碍物的信息[7-8],但前视声纳体积大、价格高,不适合用于小型的AUV平台.也有些AUV使用光学强度摄像机来获取环境障碍物的信息,但光线在水下环境会很快衰减.即使增加辅助灯光,光学摄像机探测距离也十分有限,不适用于AUV工作的实际海洋环境.
本文结合课题组的实际研究项目,模拟单波束声纳的工作特点,提出了一种基于强化学习的AUV自主避障策略.仿真实验结果表明:通过强化学习获得的障碍物状态与避障动作之间的最佳组合,可以保证AUV在行进过程中,安全躲避前方90°开角内的障碍物.
1 AUV与声纳设备
我课题组在英国Essex大学胡豁生教授的指导下,基于原有智能机器鱼的研究与应用成果,联合设计如图1所示的新一代机器鱼.新设计的AUV具有更好的小阻力外形,更强的续航能力,更好的机动性能.机器鱼拟采用单波束声纳为环境障碍物信息采集传感器,实现一种小型、低成本的机器鱼避障方案.
针对近海浅海的实际情况,同时着眼于小型的开发平台,本课题组使用的避障传感器是由英国Tritech International Limited公司基于 Micron DST开发的侧扫成像单波束声纳(图1).
2 避障算法设计
2.1 环境数据采集
本文中对环境数据采集使用的传感器是单波束声呐,这款声纳的工作中心频率为700kHz,最大探测范围为100m.声纳水平开角为3°,垂直开角为30°.这种单波束声呐数字化程度高,成像清晰,与多波束声呐相比,具有体积小,成本低,便于安装,可应用到小型化的平台上去的优势;但是在同等时间内,其扫描范围较多波束声呐而言小了许多.如图2所示.

图2 单波束声呐与多波束声呐扫描范围的大致对比Fig.2 Scan range comparing single beam sonar with multi beam sonar
同时单波束声呐在随着AUV的行进中,声呐扫描的截面也会发生相应的移动.在扫描成像方面可能出现图像错位的情况,所以在后期数据处理与成像分析的时候,需要进一步的处理(图3).

图3 AUV的扫描划分与动作选择执行Fig.3 Scanning division and action choice of AUV
根据单波束声呐的工作特点,我们设计以下避障算法.整个避障模块分为学习阶段和执行阶段,两个阶段相对独立,又相互联系.各自的工作流程如图4所示.
2.2 AUV的状态集与行为集
强化学习采用试错法(trial-and-error),不用建立环境和任务的精确数学描述.通过学习,AUV能通过获取系统状态、动作和奖励等有用的经验,从而掌握一套优化的避障策略与知识.
基于单波束声呐的特点,本文中的AUV强化学习模型由以下几部分组成:控制策略P被定义成状态集合S到控制行为集合Μ 的映射,其函数的形式是:m=P(x),x∈S,m∈M.其含义是:根据策略Ρ,当观察到系统状态为x时,决策结果是控制行为m.

图4 避障算法设计流程图Fig.4 Obstacle avoidance algorithm design flow chart
由于AUV的游动方向主要表现为前向运动,所以在AUV的前方有无障碍及与障碍间的距离对AUV的运动影响是最大的.为了减少状态集的数量和提高学习速度,对各种状态进行了合并[9],AUV状态的描述由声呐扫描的左中右3个方位的状态组合而成,并根据其各个方位与障碍物距离关系在s0,s1,s2中取值(详见表1),此处详见2.4节.
同时针对AUV可能遇到的环境状态设计了如下的6种行为:
b1:AUV右螺旋桨速度为0向右转弯;
b2:AUV左螺旋桨速度为0向左转弯;
b3:AUV以速度V向右转弯;
b4:AUV向前直游;
b5:AUV以速度V向左转弯;
b6:漫游.
上述行为中,b1~b5是AUV学习的目标,而b6并不需要AUV通过学习获取,它作为AUV本身所应该具有的基本能力,当声呐在3个方向都没有探测到障碍物时,AUV自动选择该行为.
2.3 AUV的奖惩评价设置
如何奖惩也是AUV强化学习中的一个重要环节,它影响到学习的好坏、快慢.在Tucker Balch的文献[10]中,给出了一套描述符,对强化学习的奖励进行了分类.情况设置见表2.
假定3个方向探测到的距离值分别为dL,dF,dR,则障碍物相对AUV的距离d定义为:d=min(dL,dF,dR).
状态评价函数V是某个状态和目标状态之间距离的度量,其定义如下:在某种控制策略下,从某个状态转移到目标状态的过程中,把增强信号加权和的数学期望定义为该状态的评价函数值,即:

表1 合并后的状态集Tab.1 After the merger of the state set

表2 奖惩情况设置Tab.2 Rewards and punishments set

式(1)中的E表示数学期望;γ称为折扣因子(discount factor),也是常数,且0<γ<1,在数学上使式(1)中的无穷级数收敛;rt+1是t+1时刻产生的增强信号值;x0表示初始状态.某个状态的评价函数值越大,表示它距离目标状态越近.从上述定义可知,状态评价函数和控制策略是相联系的,不同控制策略下的状态评价函数可能不同.强化学习使状态评价的估计值逐渐逼近最优策略控制下的状态评价值,同时使控制策略逼近最优策略.
2.4 声呐数据处理与方位角设置
本文对声呐所扫描到的距离数据采取了分段处理方式.假定声呐的最大探测距离为Dmax,执行有效避障行为的临界距离为Dc,AUV到障碍物的危险距离为Dh,这3者的距离关系是Dmax>Dc>Dh.
根据声呐测量到的数据值Dt,将AUV某一方向的障碍物分布情况分为s0,s1,s2等3种如下的状态:
s0:AUV没有探测到障碍物;
s1:AUV距离障碍物较远,即Dc>Dt>Dh;
s2:AUV距离障碍物较近,即Dh>Dt.
将AUV声呐的扫描范围做一个如图3的划分,同时将L区所包含的扫描范围视为AUV的左方位,将F区部分范围视为AUV的前方,同理R区部分为AUV的右方位.在描述AUV的状态时,可建立一个3个方位的状态组合为FWLFWFFWR,其中FWL为AUV左方位的状态,FWF为AUV前方的状态,同理,FWR为 AUV 的右方位状态.FWL,FWF,FWR在s0,s1,s2中取值.例如:s0s0s1表示 AUV右方扫描到障碍物,且距离较远,其他方向没有探测到障碍物.
由于传感器不能对障碍物进行精确的方向定位,为此综合AUV 3个方向的信号情况,将障碍物相对于AUV的方向角离散化为7种情况[9],作如下定义:
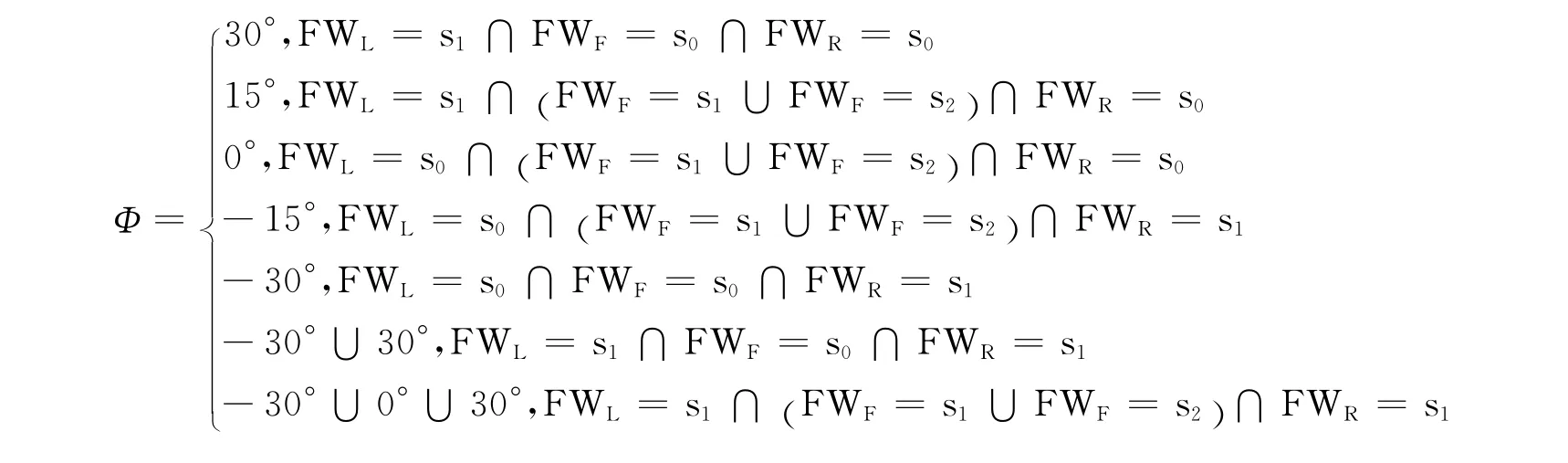
AUV与障碍物的相对方向角为Φ,当AUV执行行为偏离障碍物相对AUV的方向时,称AUV偏离障碍物;反之称AUV靠近障碍物.
3 仿真实验
在MATLAB仿真下,对局部有障碍物的环境设置如图5所示,图5中的圆框为障碍物,星形点为AUV,障碍物为高约15cm,边长约5cm的等八边形柱体.AUV长60cm(只包含鱼身部分),最宽处宽度为16cm,最高处高度为27.6cm.本文采用强化学习来进行状态-动作的学习,不用建立环境和任务的精确数学描述,通过不断的试错,再对其选择的行为给予奖惩,从而获取对避障有用的经验.行为学习选取采用贪婪算法,贪婪算法的基本思想是采用逐步构造最优解的方法,其本质上是一种局部搜索算法,可以对当前的环境选择局部最优的避障行为.ε表示各设定避障行为的加权系数,其初始值εn设为0.9,每代递减,其中T为学习总代数,学习总代数为60,每代最大运动步数是2 000步.通过不断的试错之后,AUV系统掌握了一套有效的避障策略.在实验中,对障碍物的位置随机设置,均达到了预期避障目标.相关的仿真实验如图5所示.

图5 避障仿真实验路径图Fig.5 The path graph of obstacle avoidance simulation experiment
系统学习的任务是通过训练次数的不断深入,对AUV的避障方法学习得出一个较为稳定的躲避策略,图6给出了学习策略改变次数与学习代数之间的变化曲线关系,可以看出,算法是收敛的,且学习代数为50时,可以达到一个学习成本与执行效果较好的平衡,同时可以看出其曲线基本趋于平稳,继续增加学习代数对提高学习效果并不明显.综上所述作出如上选择.

图6 学习代数与策略学习的平均步数的关系图Fig.6 The graph of the relationship between the strategies of learning algebra and the average number of strategy learning
4 讨 论
本文针对小型的AUV开发平台,使用基于Micron DST开发的侧扫成像单波束声呐,提出了一种基于单波束声呐扫描特性的AUV避障控制策略.利用单波束声呐的探测波束依次旋转,依次获取AUV前方3个区域的障碍物距离信息,同时给出了合适的环境状态与有效的避障行为集合,并通过强化学习来优化状态行为组合,给小型、低成本AUV避障提供一种解决方案.在仿真实验中,通过多次随机设定环境的初始状态,均达到了预期的避障效果,验证了学习结果的有效性.
通过多次的仿真实验表明,使用基于强化学习的避障算法和基于Micron DST开发的单波束声纳能够及时地为系统的安全运行提供有效的信息和控制策略.但是在水池实验中由于惯性导航系统的低精度问题,我们不能得到准确的速度信息,在一定程度上影响到系统反应的准确性;此外,单一的声学传感器的局限性问题也在特定的环境中显现出来.所以在未来我们要从以下3个方面来改善它:
1)采用精度较高的惯性导航系统或其他巡航速度传感器,速度信息的补充将使决策更加及时有效.
2)添加一个视觉传感器系统,在一定的距离范围内,给声学传感器提供补充和辅助.
3)添加其他模块如通信模块、导航模块等使系统更完整.
[1]Qiao J F,Hou Z J,Ruan X G.Application of reinforcement learning based on neural network to dynamic obstacle avoidance[C]∥Proceedings of the 2008IEEE International Conference on Information and Automation.Changsha,China:IEEE,2008:784-788.
[2]Sayyaadi H,Ura T,Fujii T.Collision avoidance controller for AUV system using stochastic real reinforcement learning method[C]∥Proceedings of the 39th SICE Annual Conference.Iizuka,Japan:IEEE,2000:165-170.
[3]Jia Q L,Li G W.Formation control and obstacle avoidance algorithm of multiple autonomous underwater vehicles(auvs)based on potential function and behavior rules[C]∥Automation and Logistics,2007IEEE International Conference on.Jinan,China:IEEE,2007:569-573.
[4]Khanmohammadi S,Alizadeh G,Poormahmood M.Design of a fuzzy controller for underwater vehicles to avoid moving obstacles[C]∥Fuzzy Systems Conference.London,England:IEEE,2007:1-6.
[5]Zhang M,Ura T.Motion optimization of autonomous underwater vehicle by genetic algorithm[J].Journal of the Society of Naval Architects of Japan,1997,182:491-497.
[6]McPhail S,Furlong M,Pebody M.Low-altitude terrain following and collision avoidance in a flight-class autonomous underwater vehicle[J].Journal of Engineering for the Maritime Environment,2010,224(4):279-292.
[7]Huvenne V A I,Blondel P,Henriet J P.Textural analyses of sidescan sonar imagery from two mound provinces in the Porcupine Seabight[J].Marine Geol,2002,189:323-341.
[8]Petillot Y,Ruiz I T,Lane D.Underwater vehicle obstacle avoidance and path planning using a multi-beam forward looking sonar[J].IEEE Journal of Oceanic Engineering,2001,26(2):240-251.
[9]沈志忠,曹志强,谭民.基于增强式学习的仿生机器鱼避障控制[J].高技术通讯,2006,16(12):1253-1258.
[10]Balch T.Behavioral diversity in learning robot teams[D].Atlanta:Georgia Institute of Technology,1998.
