大数据环境下的增强学习综述*
2014-11-27冯延蓬孟宪军江建举何国坤
仵 博,冯延蓬,孟宪军,江建举,何国坤
(深圳职业技术学院 教育技术与信息中心,广东 深圳 518055)
增强学习(Reinforcement Learning,简称RL)是一种有效的最优控制学习方法,实现系统在模型复杂或者不确定等条件下基于数据驱动的多阶段优化学习控制,是近年来一个涉及机器学习、控制理论和运筹学等多个学科的交叉研究方向.增强学习因其具有较强的在线自适应性和对复杂系统的自学能力,使其在机器人导航、非线性控制、复杂问题求解等领域得到成功应用[1-4].
经典增强学习算法按照是否基于模型分类,可分为基于模型(Model-based)和模型自由(Model-free)两类.基于模型的有TD学习、Q学习、SARSA和ACTOR-CRITIC等算法.模型自由的有DYNA-Q和优先扫除等算法.以上经典增强学习算法在理论上证明了算法的收敛性,然而,在实际的应用领域,特别是在大数据环境下,学习的参数个数很多,是一个典型的NP难问题,难以最优化探索和利用两者之间的平衡[5-8].因此,经典增强学习算法只在理论上有效.
为此,近年来的增强学习研究主要集中在减少学习参数数量、避免后验分布全采样和最小化探索次数等方面,达到算法快速收敛的目的,实现探索和利用两者之间的最优化平衡.当前现有算法按照类型可分为五类:1)抽象增强学习;2)可分解增强学习;3)分层增强学习;4)关系增强学习;5)贝叶斯增强学习.
1 抽象增强学习
抽象增强学习(Abstraction Reinforcement Learning,简称 ARL)的核心思想是忽略掉状态向量中与当前决策不相关的特征,只考虑那些有关的或重要的因素,达到压缩状态空间的效果[9].该类算法可以在一定程度上缓解“维数灾”问题.状态抽象原理如图1所示.
目前,状态抽象方法有状态聚类、值函数逼近和自动状态抽象等方法.函数逼近方法难于确保增强学习算法能够收敛,采用线性拟合和神经网络等混合方法来实现函数逼近是当前的研究热点和方向.状态聚类利用智能体状态空间中存在的对称性来压缩状态空间,实现状态聚类.自动状态抽象增强学习方法利用 U-树自动地由先验知识推理出状态抽象,是状态抽象增强学习研究的方向之一.以上算法都在一定程度上缓解了增强学习中大规模状态造成算法无法收敛的问题,但是存在以下缺点:1)增强学习的绩效依赖于状态抽象方法对状态空间的划分,如何合理划分子空间是状态抽象增强学习面临的难题.如果空间划分过粗,难以实现增强学习算法的快速收敛;而如果空间划分过细,则会丧失泛化能力.2)状态抽象方法与特定问题表示相关,缺少统一的理论框架,阻碍了状态抽象增强学习的广泛应用.
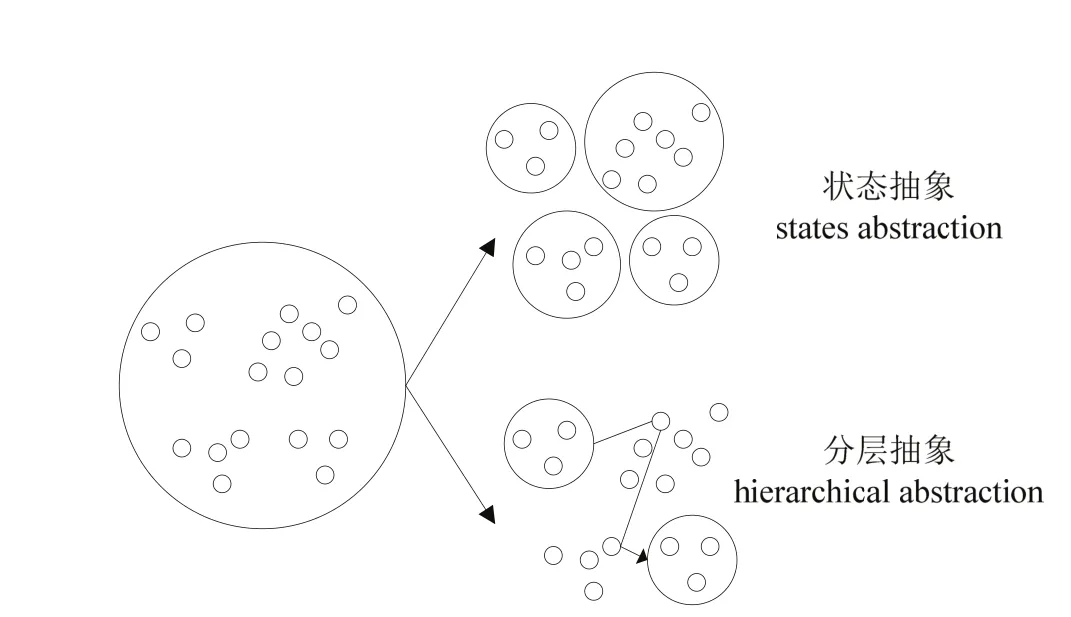
图1 状态抽象原理示意图
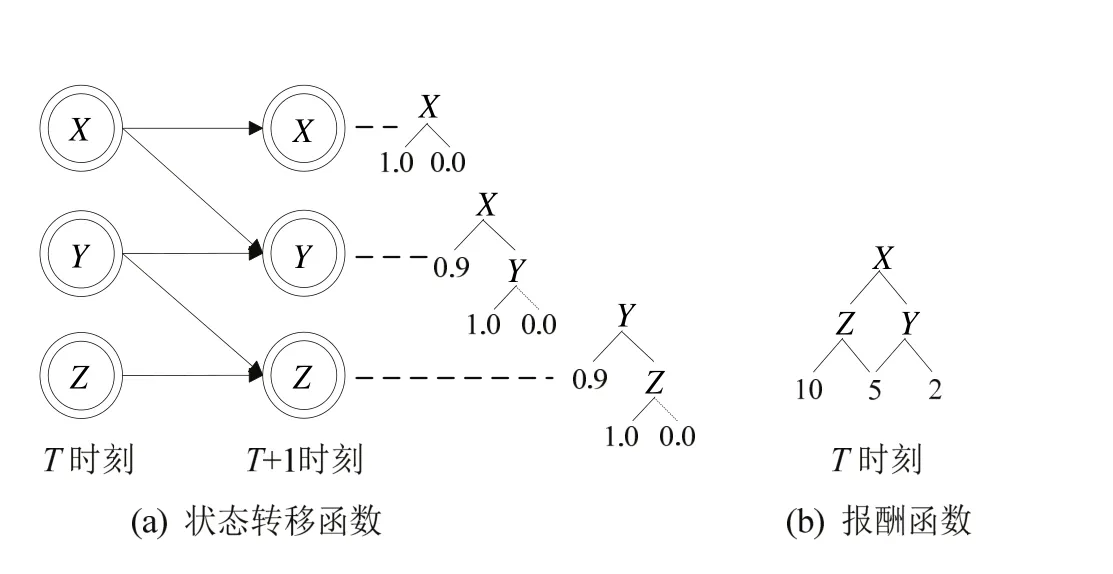
图2 可分解原理示意图
2 可分解增强学习
可分解增强学习(Factored Reinforcement Learning,简称 FRL)是一种对状态转移函数和报酬函数进行压缩表示的增强学习方法[10].该方法的核心思想是首先利用动态贝叶斯网络的条件独立特性和上下文独立特性将状态转移函数和报酬函数进行可分解描述,将离散的概率分布函数转化成决策树来表示,达到将大规模指数级的状态空间压缩到多项式级别的状态空间的目的,然后采用决策论回归方法对决策树进行学习,可分解原理如图2所示.
可分解增强学习的思想来源于Boutilier等人在2000年发表在《Artificial Intelligence》上的论文,该论文指出采用可分解表示方法可以将高维状态空间压缩为低维可求解空间,并详细介绍可分解的理论和方法,以及结构化动态规划(Structured Dynamic Programming,简称SDP)算法,为可分解增强学习奠定了理论基础.更进一步,Guestrin等人[11]提出结构化线性规划(Structured Linear Programming,简称SLP)算法和可分解增强学习算法,实现了求解240~250规模的问题.
由于FRL极大地降低求解问题的规模,提供学习算法收敛速度,成为近年来的研究热点.例如,Degris等人提出的SDYNA算法,Kroon等人提出的KWIK算法[12],Kozloval等人提出的IMPSPITI算法和 TeXDYNA 算法[13],Hester等人提出的RL-DT算法[14],Szita等人提出的 FOIM 算法[15],Vigorito等人针对状态和动作连续情况下提出的OISL算法[16]0.
以上FRL算法相同之处是首先采用监督学习方法建立状态转移函数和报酬函数的可分解表示,然后根据观察结果,采用不同的方法来更新状态转移函数模型和报酬函数模型.因此,如何建立应用对象的可分解泛化表示,减少学习的参数个数,提高在后验分布采样算法的性能是目前研究的难点.
3 分层增强学习
分层增强学习(Hierarchical Reinforcement Learning,简称HRL)实质上也是一种任务分层方法,其核心思想是将一个大规模难于求解的问题分解成若干个较小规模易于求解的问题[10].该算法可以有效解决学习参数数量随状态变量维数成指数级增长这一“维数灾”问题[17].HRL任务分层方法可分为手工分层和自动分层,手工分层方法是根据智能体先验知识采用手工方式来分解,自动任务分层方法是通过自动探索,自动发现和构造某种形式的层次结构.根据先验知识,采用自动任务分层方法是目前HRL领域的研究热点.HRL原理如图3所示.
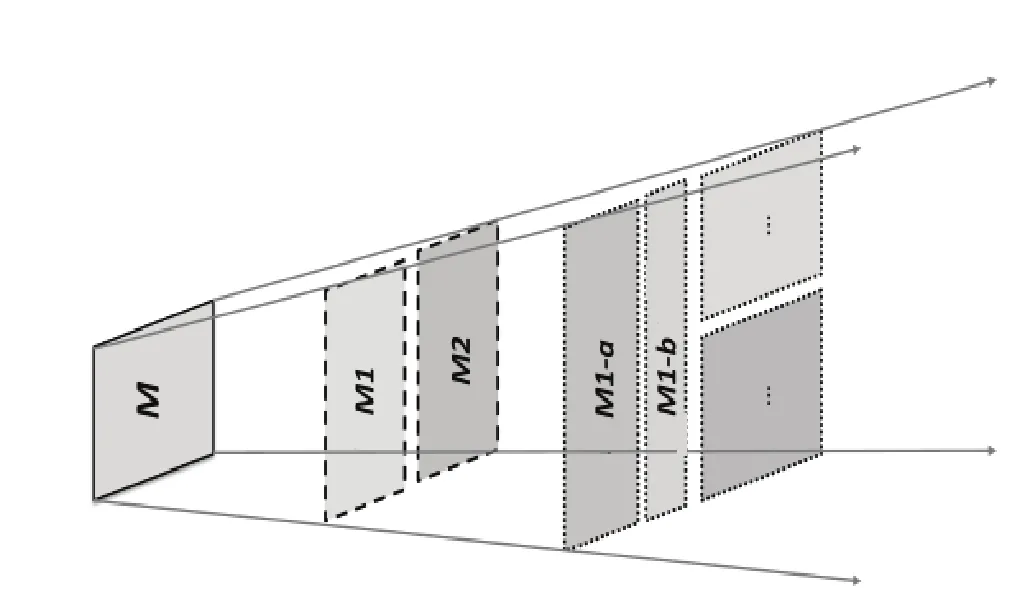
图3 分层原理示意图
由于HRL能够有效降低求解问题的规模,成为当前增强学习研究的热点和难点.在当前研究成果中,具有里程牌意义的算法为Option算法、HAMs算法和MAXQ算法.Option算法的任务分层其实是在大数据空间上探索子目标并构造Option的过程.HAMs算法通过引入有限状态机概念,使之用于表达大数据空间中的区域策略.MAXQ算法的任务分层是在任务空间上构造多个子任务的过程,它直接从任务分层的角度来处理大数据模型,所有子任务构成一个任务图.
近年来,国内外研究人员针对以上三个算法缺点,提出不少改进型 HRL算法.例如,Subramanian等人提出的 Human-Options方法[18],Joshi等人[19]采用面向对象表示方法来构造HRL模型,利用特定领域知识进行动作选择,以提高学习效果.Jong等人结合 Rmax算法和MAXQ算法的优点,提出一种混合型RMAXQ算法[20].
以上算法在特定的实验平台和应用领域有效,但是面对如何划分层次来保证HRL算法收敛的实时性和策略求解的最优性是目前的难题.
4 关系增强学习
人们在处理复杂领域的问题的时候,会很自然的使用关系的方法.关系增强学习(Relational Reinforcement Learning,简称RRL)是采用关系逻辑或图结构等表示方法来描述环境[21].当前RRL的研究主要以关系表示为基础,考虑在关系表示上如何把握环境的不同状态[22].RRL在的优点在于:首先,它可以将在相似环境中的对象和已经学习到的知识泛化到不同的任务中;其次,使用关系表示也是一种比较自然的利用先验知识(背景知识)的方式.目前比较常用的方法就是用一阶逻辑形式扩展成关系先验,或者扩展成能表达概率和效用的扩展逻辑行为语言[23,24].
RRL利用关系逻辑的形式来描述复杂问题,利用先验知识进行逻辑推理,符合人类的思维习惯.但是,从目前应用来看,RRL只在小规模特定问题有效,例如积木世界、十五子棋和一些小游戏中.如何实现RRL的泛化,如何在大规模动态不确定环境下进行逻辑推理是RRL领域中的难题.
5 贝叶斯增强学习
贝叶斯增强学习(Bayesian Reinforcement Learning,简称 BRL)利用模型先验知识对未知模型参数建模,然后根据观察数据对未知模型参数的后验分布进行更新,最后根据后验分布进行规划,以期最大化期望报酬值[25].由于 BRL为最优化探索和利用之间的平衡提供一种完美的解决方案,得到广泛关注,成为当前RL领域研究的热点.RRL原理如图4所示.
BRL可分为模型自由[26]和基于模型[27]两类.模型自由增强学习算法直接学习最优策略和最优值函数,需求太多的探索,造成算法收敛速度慢,无法实现在线学习.同时,在实际的应用领域状态转移函数往往会丢失数据,造成算法的失真.基于模型的增强学习利用先验知识缓和数据丢失,加速算法收敛,减少探索次数,能够最优化平衡探索和利用二者之间的关系.但是,基于模型的增强学习计算量大,使其无法实现在线学习.为此,如何有效降低未知参数个数,提高在高维后验概率分布上规划的效率是目前增强学习的难题.
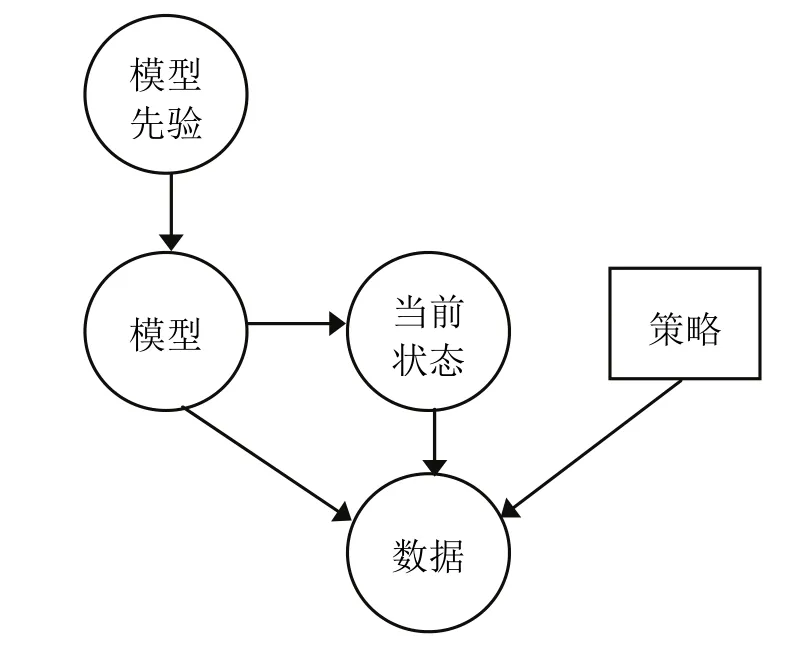
图4 贝叶斯增强学习原理示意图
6 结 论
在大数据中进行机器学习,特别是增强学习,是当前大数据基础研究的热点和难点,也是推进大数据应用的关键.规模巨大的数据是增强学习的瓶颈,针对于此,本文研究了当前五类增强学习方法,并指出它们的优势和缺点.大数据的关键在于应用,选用何种增强学习方法需要根据特定的应用而定.当前,在大数据应用领域,将监督学习或半监督学习与增强学习相结合是一条有效的方法.
[1] Silver D, Sutton R, Müller M. Temporal-difference search in computer Go[J].Machine Learning, 2012,87:183-219.
[2] 徐昕,沈栋,高岩青,等.基于马氏决策过程模型的动态系统学习控制:研究前沿与展望[J].自动化学报,2012,38(5):673-687.
[3] Wang F Y, Jin N, Liu D R, et al. Adaptive dynamic programming for finite horizon optimal control of discrete time nonlinear systems with ɛ-error bound[J].IEEE Transactions on Neural Networks,2011,22(1):24-36.
[4] Hafner R, Riedmiller M. Reinforcement learning in feedback control: challenges and benchmarks from technical process control[J].Machine Learning,2011,84:137-169.
[5] Choi J, Kim K E. Inverse reinforcement learning in partially observable environments[J].Journal of Machine Learning Research, 2011,12:691-730.
[6] Meltzoff, A N, Kuhl, P K, Movellan J, et al. Foundations for a new science of learning[J].Science, 2009,325:284-288.
[7] Kovacs T, Egginton R. On the analysis and design of software for reinforcement learning with a survey of existing systems[J].Machine Learning, 2011,84:7-49.
[8] Doshi-Velez F, Pineau J, Roy N. Reinforcement learning with limited reinforcement: Using Bayes risk for active learning in POMDPs[J].Artificial Intelligence,2012,1870-188:115-132.
[9] Frommberger L, Wolter D. Structural knowledge transfer by spatial abstraction for reinforcement learning agents[J].Adaptive Behavior, 2010,18(6):531-539.
[10] Kozlova O. Hierarchical & Factored reinforcement learning[D].Paris: Université Pierre et Marie Curie, 2010.
[11] Guestrin C, Koller D, Parr R, et al. Efficient solution algorithms for factored MDPs[J].Journal of Artificial Intelligence Research, 2003,19:399-468.
[12] Kroon M, Whiteson S. Automatic feature selection for model-based reinforcement learning in factored MDPs[C]//Wani M A, Kantardzic M M, Palade V, et al.Proceedings of 2009 International Conference on Machine Learning and Applications. Washington, DC:IEEE Press, 2009:324-330.
[13] Kozloval O, Sigaud O, Wuillemin P H, et al. Considering unseen states as impossible in factored reinforcement learning[C]//Buntine W. In Proceedings of the European Conference on Machine Learning and Knowledge Discovery in Databases: Part I. Berlin:Springer-Verlag, 2009:721-735.
[14] Hester T, Stone P. Generalized model learning for reinforcement learning in factored domains[C]//Decker K, Sichman J, Sierra C, et al. The Eighth International Conference on Autonomous Agents and Multiagent Systems. Richland, SC: IFAAMS, 2009:10-15.
[15] Szita I, Lorincz A. Optimistic initialization and greediness lead to polynomial time learning in factored MDPs[C]//Wani M A, Kantardzic M M, Palade V, et al.Proceedings of 2009 International Conference on Machine Learning and Applications. Washington, DC:IEEE Press, 2009:1001-1008.
[16] Vigorito C M, Barto A G. Incremental structure learning in factored MDPs with continuous states and actions[R].Amherst: University of Massachusetts Amherst,2009.
[17] 杜小勤,李庆华,韩建军.HAMs体系中的同态变换方法研究[J].小型微型计算机系统,2008,29(11):2075-2082.
[18] Subramanian K, Isbell C, Thomaz A. Learning options through human interaction[C]//Beal J, Knox W B.Proceedings of 2011 IJCAI Workshop on Agents Learning Interactively from Human Teachers. Palo Alto: AAAI Press, 2011:39-45.
[19] Joshi M, Khobragade R, Sarda S. Hierarchical action selection for reinforcement learning in infinite Mario[C]//Kersting K, Toussaint M. The Sixth Starting Artificial Intelligence Research Symposium.Lansdale, PA: IOS Press, 2012:162-167.
[20] Jong N K, Stone P. Hierarchical model-based reinforcement learning: Rmax+MAXQ[C]//McCallum A, Roweis S. Proceedings of the Twenty-Fifth International Conference on Machine Learning. Madison, Wisconsin: ACM Press, 2008:432-439.
[21] Liu Q,Gao Y,Chen D X,et al. A Heuristic Contour Prolog List Method Used in Logical Reinforcement Learning[J].Journal of Information & Computational Science, 2008,5(5):2001-2007.
[22] Song Z W, Chen X P, Cong S. Agent learning in relational domains based on logical MDPs with negation[J].Journal of Computers, 2008,3(9):29-38.
[23] Sanner S, Kersting K. Symbolic Dynamic Programming for First-order POMDPs[C]//Fox M, Poole D.Proceeding of the Twenty-Fourth AAAI Conference on Artificial Intelligence (AAAI-10). Atlanta: AAAI Press,2010:1140-1146.
[24] 刘全,周文云,李志涛.关系强化学习方法的初步研究[J].计算机应用与软件,2010,27(2):40-43.
[25] Ghavamzadeh M, Engel Y. Bayesian actor-critic algorithms[C]//Ghahramani, Z. Proceedings of the 24thInternational Conference on Machine Learning. New York: ACM Press, 2007:297-304.
[26] Poupart P, Vlassis N. Model-based Bayesian reinforcement learning in partially observable domains [C] //Padgham L, ParkesD. Proceedings of the International Joint Conference on Autonomous Agents and Multi Agent Systems. New York: ACM Press, 2008:1025-1032.
[27] Ross S, Pineau J, Chaib-draa B, et al. A Bayesian approach for learning and planning in partially observable Markov decision processes[J].Journal of Machine Learning Research, 2011,12:1729-1770.
