基于Hadoop平台的海量文件存储策略研究*
2014-11-27江建举孟宪军冯延蓬何国坤
江建举,仵 博,孟宪军,冯延蓬,何国坤
(深圳职业技术学院 教育技术与信息中心,广东 深圳518055)
基于信息化爆炸产生的海量数据非常复杂,既包含了结构化的数据和半结构化的数据、也包含了非结构化的文本、视频、图像等信息[1].针对大数据的研究也逐渐成为业界研究的焦点,大数据的采集、处理、存储、集成、分析和安全等问题成为主要的研究目标[2].其中基于分布式并行文件系统的分布式存储技术是大数据存储研究的首要选择,当前业界分别提出了GFS、PPFS、GPFS、PVFS、PFS和 HDFS等分布式文件系统.Hadoop是一套用于海量数据处理的系统基础平台,能够对大量数据进行以一种可靠、高效、可伸缩的方式进行分布式处理.Hadoop平台的基本组件HDFS是当前应用和研究最广泛的一种大数据存储分布式文件系统,其本质上是一种流式分块文件系统,基本的设计是处理大文件(文件大小通常大于64MB),在处理海量小文件时,在扩展性和性能方面将产生严重问题[3].本文研究一种改进的 Hadoop文件存储优化策略,通过文件大小的预处理,进行小文件的归并,提出一种新的元数据管理策略和通用文件存储模式,从而解决HDFS处理海量小文件导致的性能问题,可以为各种应用场景提供服务.
1 Hadoop平台数据存储描述
Hadoop平台核心为分布式文件系统 HDFS和分布式编程模型MapReduce.HDFS是Hadoop平台的底层文件存储系统,它是一种运行在大量廉价硬件上的分布式文件系统,主要负责分布式数据存储及管理,具有高容错性,虽然部署在低成本的硬件上,但是能提供高吞吐量的数据存取服务,其核心是以数据流的方式来访问存储文件,这极大的提高了系统存取文件的速度和效率.HDFS采用Master/Slaver体系架构,其中Master为一个作为名称节点的 NameNode,Slaver为多个数据存储节点的DataNode.名称节点负责目录、文件及数据存取等元数据信息管理和维护,主要完成管理元数据和文件块、简化元数据更新操作、监听和处理客户端及数据节点的请求、心跳检测等功能.数据节点负责基本的数据存储和对自己存储资源进行管理和计算,主要完成数据块的读写、定期向名称节点报告状态、执行数据块的流水线复制等功能.
在HDFS中,一个文件被划分为多个数据块(默认数据块大小为 64MB)并被分散存储在不同的数据节点上,每个数据块都能通过数据节点之间的相互复制而具有多个备份.当用户访问文件时,首先是把包含了文件名称的操作申请发送给名称节点,名称节点会将相关的元数据信息包括该文件对应的Block和Block在数据节点的位置信息等反馈给用户.用户端根据获得的元数据信息直接和相应的数据节点建立连接,进行具体的文件读、写、删除等操作.HDFS文件系统的文件操作结构图如图1所示.
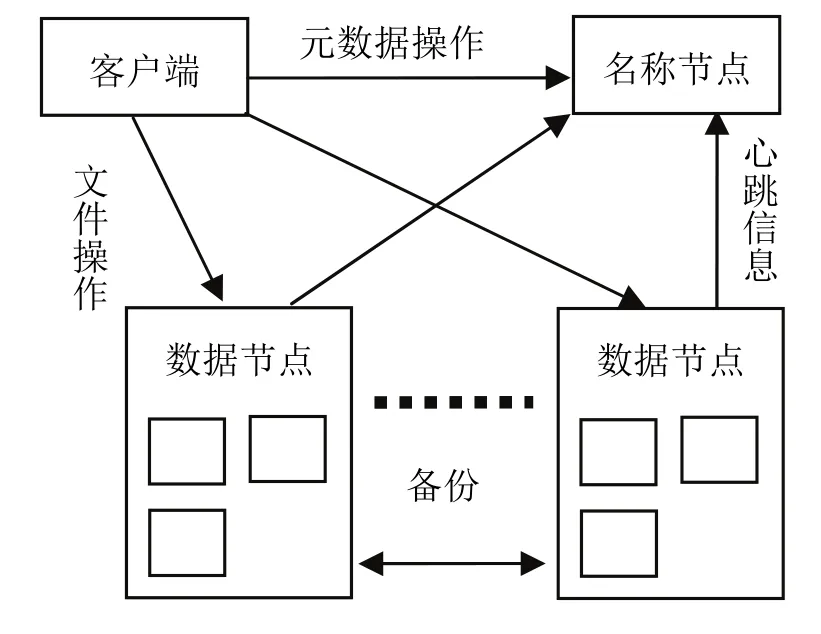
图1 HDFS系统文件操作示意图
2 HDFS存取小文件I/O优化策略
2.1 HDFS存取小文件 I/O性能分析
当前的信息技术大发展背景下,多种信息渠道获取大量的数据,这些海量数据尺寸大小各异,访问频繁.HDFS的初始设计是流式存取大文件,当处理大量小文件时,会产生如下明显的性能瓶颈问题:大量文件将占用大量的内存空间,因为名称节点将文件系统的命名空间存储于系统内存,每个小文件的元数据信息大约占用150bit内存空间,3个Block副本大约占用368bit内存空间,这样数量庞大的小文件将极大消耗名称节点的内存空间;HDFS主要设计用于提供流式数据访问模式,这种方式适用于大文件,当访问大量小文件时,会出现比较高的访问成本.对于小文件的检索,通常会导致从一个数据节点到另外一个数据节点的大量搜索和跳跃;HDFS中元数据频繁交互,元数据的处理是非常耗时的操作.对于海量小文件的操作,元数据操作消耗了大部分时间,小文件的I/O只占用少部分时间.小文件的操作,需要多次和名称节点进行交互,极大的增加了名称节点的负担,同时因为需要多次seek,也会在数据节点上产生跳跃,这一切都将增加HDFS的负载,从而导致大量小文件I/O性能的极大下滑.
针对HDFS处理海量小文件进行性能优化,是目前学术界和工业界研究的热门方向.MACKEY等[4]人提出利用Hadoop Archive技术进行小文件的归并,提高了 HDFS的元数据的存取效率;Liu XuHui等[5]提出一种新的方法优化大量WebGIS小文件的HDFS存储策略;Dong Bo等[6]提出了一种优化大量PPT文件的HDFS存储新策略;赵晓勇等[7]提出了一种新的基于Hadoop的海量MP3文件存储架构,优化MP3文件的存储访问.以上的研究基本都是基于某些特定应用,并不能适应优化 HDFS存取一般的大小文件混合的海量数据.张波[8]通过增加同一机架内增加名称节点和增加相应元数据的方式对HDFS存取小文件进行优化操作,有效的提高了小文件I/O的性能.本文将从文件预处理、增加操作元数据和元数据批处理操作等几个方面进行HDFS存取小文件的优化研究.
2.2 通用的优化HDFS小文件存取策略
针对增加的元数据信息,名称节点需要维护所有的元数据信息,因为小文件的海量数量需要消耗大量的内存,所以名称节点需要采用元数据缓存技术,通过LRU(近期最少使用算法)的替换策略进行名称节点的内存元数据管理.针对小文件频繁的读写操作,为了优化名称节点更新元数据的效率,采用负载小文件的整体Block作为向名称节点请求和更新元数据的策略,主要策略是当单个小文件写操作结束后暂时不进行名称节点中元数据的更新修改操作,从而减少名称节点的频繁访问.只有满足以下几个条件如Block空间写满、新用户对该Block产生了读请求、一定时间段内该Block没有新的读写请求时,才通知名称节点进行元数据的批处理更新操作.这种元数据的批处理更新策略可以加快系统小文件的I/O速度,并明显减轻名称节点的元数据更新负担.本文对HDFS进行优化扩展的存取架构如图2所示.
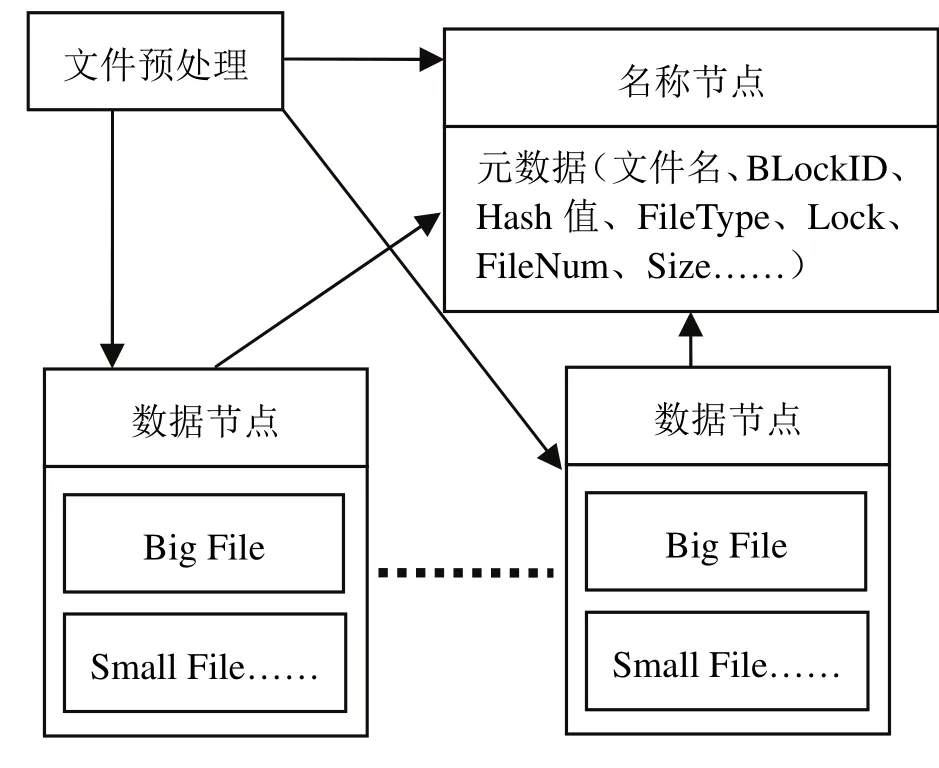
图2 优化的HDFS小文件存取架构图
3 实验性能评估
本次测试的实验环境是六台曙光A840r-H思路四核服务器,其中一台作为名称节点,其他五台作为数据节点,操作系统均为 64位 Red Hat linux 5,Hadoop版本是1.2.1 stable,JDK版本为1.6.0.24.实验中用10万个小文件进行测试,文件的大小从1k-1M大小不等的小文件.本次测试主要通过写 10万个文件的完成时间和期间名称节点的内存占用率两个方面进行传统HDFS系统和优化的HDFS系统的小文件I/O效率比较测试.
根据测试结果分析,在传统HDFS架构下,随着小文件数量的增加,写文件的时间明显呈现明显增长,而且增长时间越来越大,说明传统HDFS在处理大量小文件写操作时I/O性能下降明显,必须进行相应的优化操作.在优化的HDFS系统下,相同数量的小文件写文件的时间相对降低,而且随着小文件数量的倍增写文件时间呈线性增长,表明优化后的HDFS处理小文件时性能稳定提升.写文件时间示意图如图3所示.
根据测试结果分析,在传统HDFS架构下,名称节点在处理大量小文件写操作时内存使用率一直维持在一个相对比较高的状态,如果小文件数量过于庞大,将会导致名称节点内存占满而使系统吞吐率急速下滑.而在优化的HDFS系统下,名称节点写文件时的内存使用率一直保持在一个较低的状态,说明小文件写操作的批处理有效提高了小文件的I/O性能.写文件时内存使用率示意图如图4所示.
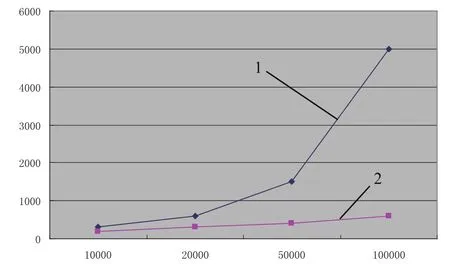
图3 写文件时间图
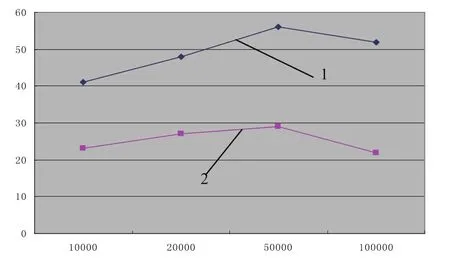
图4 写文件时名称节点内存利用率(%)
实验结果可见,在HDFS系统传统架构下,增加相应的元数据,进行文件的预处理,提高了HDFS系统写小文件的性能,并较好地降低了名称节点的内存瓶颈问题,能够适应不同场合提高HDFS存取海量文件的性能.
[1] 佘丛国,朱志军.大数据与云计算的关系及其对通讯行业的影响[C]//宽带中国战略与创新学术研讨会论文集,2012.
[2] 王珊,王会举,覃雄派,等.架构大数据:挑战、现状与展望[J].计算机学报,2011,34(10):1741-1752.
[3] Small files problem[EB/OL].http://www.cloudera.com/blog/2009/02/the-small-files-problem/.
[4] MACKEY G, SEHRISH S, WANG JUN. Improving metadata management for small files in HDFS[C]//Proceedings of 2009 IEEE International Conference on Cluster Computing and Workshops. Piscataway:IEEE Press, 2009:1-4.
[5] LIU XUHUI, HAN JIZHONG, ZHONG YUNQIN, et al.Implementing WebGIS on Hadoop: A case study of improving small file I/O performance on HDFS[C]//2009 IEEE International Conference on Cluster Computing and Workshops. Piscataway: IEEE press,2009:1-8.
[6] DONG BO, QIU JIE, ZHENG QINGHUA, et al. A novel approach to improving the efficiency of storing and accessing small files on Hadoop: a case study by PowerPoint files[C]//Proceedings of the 2010 IEEE International Conference on Services Computing. Washington, DC: IEEE Computer Society, 2010:65-72.
[7] 赵晓永,杨扬,孙莉莉,等.基于Hadoop 的海量MP3文件存储架构[J].计算机应用,2012,32(6):1724-1726.
[8] 张波.HDFS下文件存储研究与优化[D].广东工业大学,2013.
