基于分布式工作流的地理国情普查统计计算执行研究
2014-10-31孙立坚董春赵荣刘琼张旭敏
孙立坚,董春,赵荣,刘琼,张旭敏
(1.中国测绘科学研究院,北京 100830;2.武汉大学 资源与环境科学学院,武汉 430079)
1 引 言
为了掌握国情,国务院做出开展第一次全国地理国情普查的部署,明确提出用三年时间查清我国自然和人文地理要素的现状和空间分布情况[1]。地理国情统计分析是在地理国情普查成果的基础上,对地形地貌、植被覆盖、水域、荒漠与裸露地表、交通网络、居民地与设施、地理单元等地理国情普查要素的数量特征、空间分布特征等进行定量化的计算,用以反映地理国情信息的数量特征、数量关系与数量规律,并进一步分析空间分布模式、趋势、过程和空间关联规律等[2]。地理国情统计分析面临数据量大,过程繁琐的难题;尤其是近年来,随着通信技术、分布式技术的发展及高效计算和人工智能理论方法的新突破,如何构建一个涉及分布式存储结构,符合大数据时代数据分布式、任务协同式、流程自动化特征的高效海量数据统计计算方案已成为近几年来一个前沿性热点研究方向。
工作流技术是实现面向过程的建模、仿真分析管理与集成,高效实现业务过程自动化的有效技术[3]。工作流是一系列工作的偏序集,工作的序列可以有多种方式,如任务X与Y,满足X<Y当且仅当X在Y开始之前就已经就绪[4]。工作流的执行分为集中式和分布式两种,早期的工作流应用系统都是集中式的,即由一个工作流引擎去完成整个流程实例的执行。现在为了满足异构、分布、松散耦合的特点,大多采用分布式。
2 分布式工作流
“分布式工作流”的概念是相对于早期的集中式工作流引擎而言的,即整个工作流管理系统只有一个核心工作流引擎,这个核心引擎负责解析工作流的流程定义,将工作流定义加载为运行时定义,然后调度和监控流程中每个活动的执行。对于人工活动结点,负责为参与者生成相关的工作项,对于自动活动结点,负责调用外部的具体应用(如企业中的HR、CRM等应用,或者是执行某项操作的一个JavaBean)[3]。这种集中式的工作流管理系统由于主要的负荷全集中在一个工作流引擎上,因此在可扩展性、健壮性以及吞吐量等方面都不能满足企业执行大规模复杂应用的需求,尤其是当基于此集中式的工作流引擎的应用同时被大量用户访问时,将有可能导致工作流服务器的过载而瘫痪[4]。而分布式工作流是指采用一组分布在不同节点上的工作流引擎来共同协作完成整个工作流实例的执行。每个工作流引擎负责完成其中一部分活动实例的执行,不同的工作流引擎之间通过可靠的通信机制实现协作。通过分布在不同网络节点上的多个工作流引擎的协作来运行工作流流程,可以明显改善集中式工作流引擎的性能瓶颈问题。
一般认为分布式工作流要解决的根本问题不是性能问题,性能问题可以通过cluster解决,分布式工作流要解决的还是一个分布式的问题,也就是解决分布式应用的协作问题。一般来说,一个复杂的地理国情数据的统计计算系统包括数据服务(地理数据服务、专题数据服务)、业务服务(统计计算服务),不同服务资源分布在不同的地点(或者跨部门),而一个业务流程需要多个服务协作完成,这很难通过集中式的工作流来完成,可以通过分布式的工作流来完成,借助消息中间件和EJB2.0来实现工作流的分布式。
2.1 研究现状
在分布式工作流的研究领域,以IBM公司的基于“永久消息队列”、瑞士苏黎士大学的基于“事件驱动”和美国达特茅斯大学的基于“可移动代理”的分布式工作流系统较具典型性和可行性[5]。
IBM Almaden研究中心提出基于“永久消息队列”的分布式工作流[5],通过永久消息(persistent messages)的方式来保存工作流相关执行信息。执行节点接收到消息后,执行当前活动,当前活动执行完后,根据当前活动的输出连接弧向其他节点发送消息,从而推动整个过程实例的进程。
苏黎士大学计算机系研究人员提出基于“事件驱动”的分布式工作流―EVE(Event Engine),用以集成工作流执行过程中松散耦合的分布式功能组件(包括各类应用)[6]。主要由事件引擎服务器和Broker(代理)组成。事件引擎服务器负责接收来自本地代理及远程事件引擎服务器的事件,并根据ECA(Event Condition Action)规则定义,把事件发送给“感兴趣”的代理,当代理接到相应的事件后,就开始执行一个工作流实例的某一个活动,在这期间,代理还会产生新的事件。这些事件被通知到事件引擎服务器后,服务器将继续以事件的方式推动整个过程实例的进程。
DartFlow是达特茅斯学院(Dartmouth College)计算机系设计开发的一种基于可移动代理的工作流系统,由可移动的代理将代码与数据传递到另外的网络节点上去执行,从而实现工作流过程的分布式执行[5]。Yan等人采用Petri网来对分布式工作流系统进行建模,进而提出标准的工作流结构和工作流块的概念,以此支持复杂的分布式工作流管理系统的实现。Winograde与Flores在语言行为(speech act)理论的基础上提出了一种基于对话的工作流模型。Pallec等人采用 MOF(Meta-Object Facility)来达到工作流管理系统中的互操作性[8]。这些方法在不同层面和方向上提高了工作流解决实际问题的能力,但在系统的自管理性、可扩展性方面并不令人满意。
本文在目前已有研究基础之上,针对国情普查数据统计的计算要求和特点,提出了一种节点分布式工作流引擎的实现方案以及与之相关的规则定义TCA(Task Condition Action)与应答流程模型,借助真实数据的样本例子作为数据源,通过实验对模型的可行性和效率进行了分析和讨论。
3 统计过程任务模型
地理国情普查数据统计具有数据量大、计算流程化、数据资源分散的特点,在工作流执行过程中适合采用松散耦合的分布式计算模式,以任务为驱动(Task Engine)。在群内节点计算单元内主要包括任务引擎服务器、代理和数据端等。数据端存储数据,任务引擎服务器负责控制、分发来自本节点及其他节点的任务,任务存储采用消息队列,并根据任务流转规则(Task Action Rule)定义,把任务发送给相关代理,当代理接到相应的任务后,就开始解译任务,执行一个工作流实例的某一个活动。在这期间,代理把自身工作状态及参数按照应答方式反馈任务引擎服务器。这些消息被通知到任务引擎服务器后,服务器将继续以任务的方式推动整个过程实例的进程。
3.1 统计过程任务
这里的任务不是简单的统计任务,确切的讲,是统计计算任务的元任务。任务是“任务驱动”的基本组成,任务驱动与事件驱动的最大区别是任务驱动的规则定义TCA相对于ECA更明确,因为为了保证在全国范围内计算结果的一致性和可比较性,地理国情普查的统计指标、模型和算法是明确的,因此不同的任务节点的任务也是明确的,每一个进入集群环境的计算节点都有明确的身份令牌,经过注册后,身份令牌在任务引擎服务器端是可识别的。因此TCA的任务发送不存在“搜索兴趣”的问题,是一种明确的定向发送,相对于ECA减少了搜索环节,进一步提高了整个工作流的运转效率。分布式工作流地理国情普查数据统计计算执行任务主要包括以下主要内容见表1。

表1 统计过程任务列表
3.2 数据统计计算过程执行
客户端向数据服务器请求国情信息数据,将数据下载到本端的数据统计控件中,其余客户端根据任务需要采用同样的操作将数据从与其相连的数据服务器下载到本端的数据统计控件中。客户端同步启动某项指标统计计算,此时启动该项指标统计流程,通过节点身份比对将数据请求或权限以“令牌”(Token)的形式,同时触发同步通讯,将该“令牌”信息参数打包并发送给服务端,服务端接收数据包,将信息解译后(包含令牌信息以及相应的流程信息)进入队列管理,在队列管理轮转触发后,立即转发给已注册且相关的其他所有客户端,客户端取得服务端传送数据包,将数据解析出来,依据流程指令触发本地任务。
不失一般性,在一个最小群內的分布式工作流国情数据统计计算模型(请求/相应,不包括反馈,队列数量为1,省略队列管理)至少包括3部分:代理(A)、管理中心(B)和数据服务中心(C)。涉及一个基本统计计算任务过程的流程情况如图1所示,在每个节点任务流转的过程中,为了简化,省略了控制连接项的条件以及连接项的过滤器。
基于图1对应的过程描述如表2所示,参数描述如下:Proc为节点任务;Act为活动任务;InT_A为输入任务;OutT_A为输出任务;Quit为中断退出;InD_A为输入数据(From);OutD_A为输出数据(To);IData为输入信息;OData为输出信息。

图1 基于请求/响应工作流流转图
过程执行过程中,与过程有关的信息存放在一个活动队列管理器(Active Link Manager,ALM)管理的表中(堆栈或链式),由活动线程管理器执行Put、Get调用,并将相关调用的消息属性保存管理。过程执行时,所有的消息关联至过程环境(压栈或排队);ALM周期查询队列,接受新申请,对消息创建线程并关联与该线程有关的数据。该线程对应实例表中的一个表项纪录,包含该线程的活动执行登记信息;ALM检查活动开始的条件,如果都不具备,ALM则转入休眠直道被新的消息唤醒。如果活动开始条件出错,ALM则按照预案处理方法处理,无预案的则退出队列。所有这些操作都是在活动周期(从开始到结束)内作为一个基础行为完成。如果开始条件为真,则相应的调用被激活,并传递内容项,如上图中IData。在此,定义输出传递包括2种:消息传递和数据传递(对应消息服务和数据服务),消息传递一般作为触发条件,内容量少,多以BOOL值标记,具备双向/循环触发的功能,数据传递一般是在满足消息传递条件下,按照消息传递中的数据要求,将数据结果传递,特点是数据量大,一般单向传送,不支持双向/循环触发。当成功中止时,判断输出传递控制连接项,如上图中Out T_A项(消息传递)和Out D_A项(数据传递),并被发送到过程表中输出数据连接项指定的节点;一个完整的请求/响应过程后从过程队列中清除与该活动相对应的登记,因为一个任务对应一个活动,一旦活动成功中止就没有必要再保留该消息。所有这些操作也是作为一个基础处理来完成的。
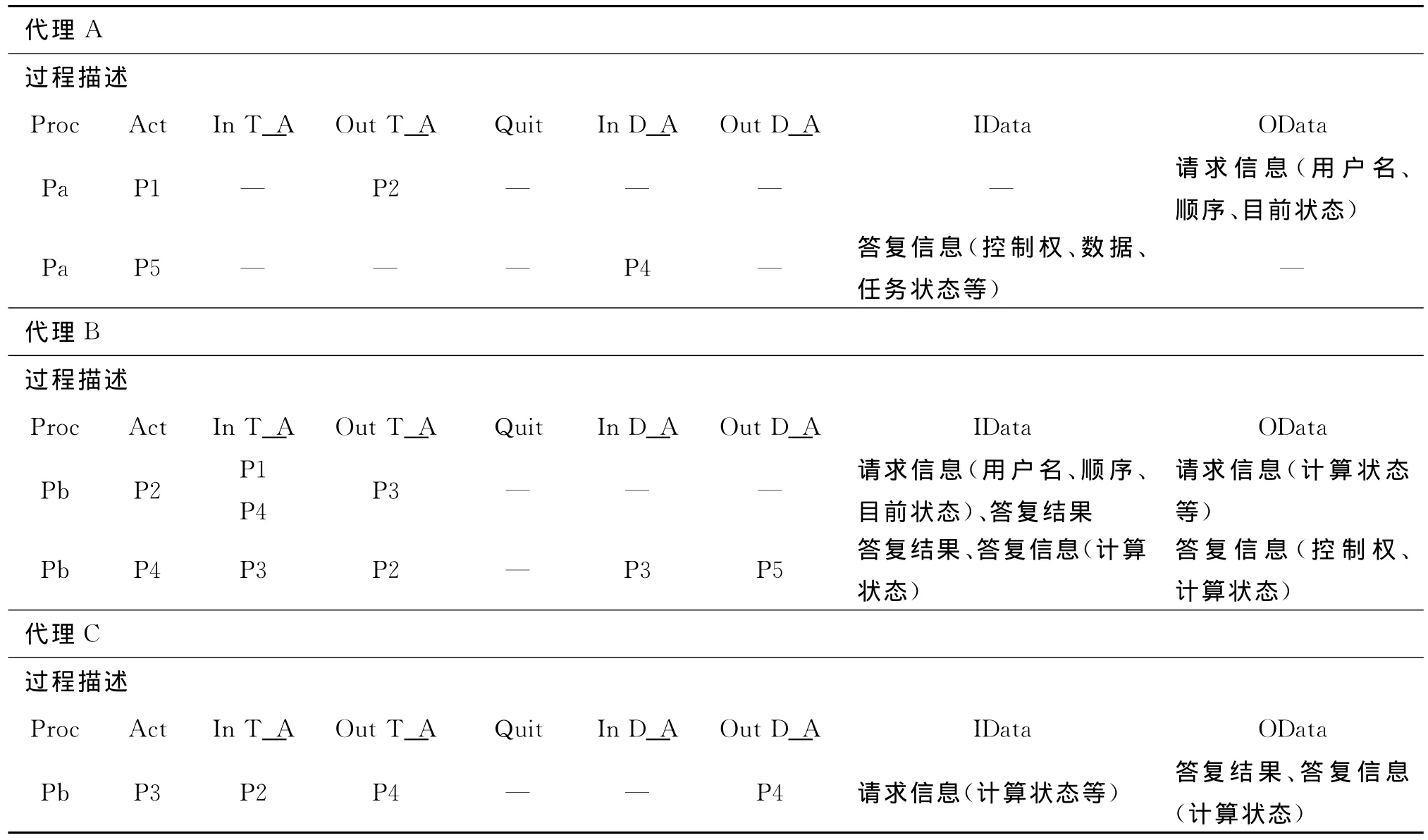
表2 任务流程及其对应的过程表
4 实验与分析
从以上执行模型中可以看出,在统计指标、模型和算法明确的条件下,任务流程设置、队列调度策略和代理单元数量是影响统计计算效率的重要因素,一般来说任务流程设置和队列调度策略一旦确定,承担计算任务的节点数量则成为影响统计计算效率的关键因素。为验证分布式工作流普查数据统计计算计算节点数量与的计算效率之间的关系,搭建如下实验环境:
(1)任务名称:不失一般性,计算指标选取计算某地区DEM平均高程。
(2)计算过程描述:如图2所示:
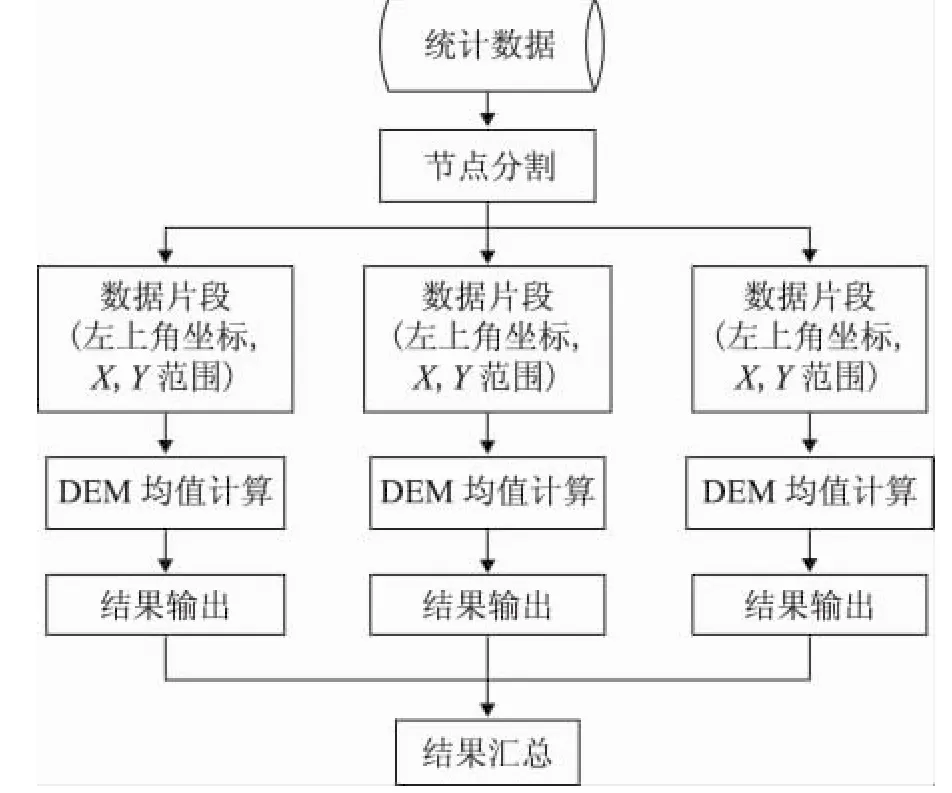
图2 DEM平均高程分布计算流程图
(3)数据描述:DEM 数据,数据大小11881*9720,数据量440.53MB(未压缩),格式Grid。
(4)队列调度算法方面为实现负载均衡,执行工作流引擎采用轮转法进行调度。
(5)硬件描述:利用11台台式机组成一个小型工作群,其中1台电脑(主频3.00GHz;内存为8G)充当该集群主控节点,其余10台分别充当计算节点和数据存储节点。节点间使用百兆以太网进行数据传输。
(7)系统软件描述:系统均为 Ubuntu12.10,Hadoop版本0.20.2、java版本1.6;HBase版本0.20.3。
(8)实验过程:主控节点启动分布式工作流系统,从各节点中运行数据和任务并监视节点;启动任务(调用、请求数据处理工作流),主控节点对被处理数据按照一定分解规则(一般为均匀分割)进行分割处理后,交给数据节点按照工作流模式计算处理,然后由汇总任务节点将收集到的结果归并、聚合,进行最终结果的导出。实验中10台台式机电脑分别充当运算节点与本地数据存储节点,将数据分别在不同节点数下运行数次,剔除其中可能错误的时间,取其平均数,记录此运行时间。实验结果如表3所示:
其运算节点数与计算时间关系如图3所示:
从图中可知,参与分布式工作流计算的系统其计算效率在工作流程、指标和模型方法确定的情况下与参与计算的节点数量有关系,计算所用的时间与节点数目呈现局部负相关关系,即在一定运算节点数范围内计算时间随运算节点数量增加而降低。但从上图可知当参与计算的节点数超过一定数目后,以后的运算节点数量虽然增加,但是计算执行所用时间大体不变,这是由于受到数据分割消耗(参与分割的节点越多,分割复杂度越高,计算成本增加)以及数据传输消耗(参与交互的节点越多,交互时间与复杂度越高,计算成本增加)等因素的影响,整个计算时间曲线趋于平缓。

表3 同一栅格数据不同运算节点计算时间

图3 同一栅格数据不同节点运算时间对比图
5 结束语
本文探讨采用分布式工作流方法解决地理国情普查数据统计分析数据海量性与任务繁琐性问题,提出一种以任务驱动采用松散耦合的分布式工作流计算模式,提出了包括引擎状态、会话、状态控制、统计计算和过程控制的规则定义TCA(Task Condition Action)模型,并分析了一个最小节点群结构的应答模式;构建一个集群计算环境,并通过实验给出计算效率与节点数量的对应关系。实验表明以上模型和方法是一种提高地理国情普查统计分析计算效率的有效方法。尽管如此,该模型还有待完善,尤其是运算节点的数据分解规则以及不同队列调度策略对计算效率的影响分析将是下一步研究的重点内容。
[1]陈俊勇.地理国情监测研究与探索[M].北京:测绘出版社,2011:19-25.
[2]国务院第一次地理国情普查领导小组办公室.GDPJ 03-2013地理国情普查基本统计技术规定[S].北京,2013.
[3]AALST W M P V.Three good reasons for using apetri-net-based workflow management system[M].Kluwer Academic Publishers,1996.179-201.
[4]贾文珏,李斌,龚健雅.基于工作流技术的动态 GIS服务链研究[J].武汉大学学报(信息科学版),2005,30(11):982-985.
[5]何凯涛,唐宇,刘书雷.基于工作流的GIS服务动态聚合方法、技术体系和参考模型研究[J].国防科技大学学报,2008,30(1):47-52.
[6]王华敏,边馥苓.基于微工作流的可扩展 GIS模型研究[J].武汉大学学报(信息科学版),2004,29(2):127-131.
[7]ALONSO G,MOHAN C,GUNTHOR R,et al.Exotica/FMQM:A persistent message-based architecture for distributed workflow management[R].IBM Almaden Research Center,1994.
[8]GEPPERT A,TOMBROS D.Event-based distributed workflow execution with EVE[R].Switzerland:University of Zurich,1996.
[9]姬涛,胡金柱.一个基于持续消息的分布式工作流管理模型[J].计算机应用研究,2001(6):53-55.
[10]于明远,俞栋辉,叶蕾.基于改进微粒群的分布式工作流调度优化[J].系统工程理论与实践,2011,31(2):191-196.
[11]胡春华,吴敏,刘国平,等.一种基于业务生成图的 Web服务工作流构造方法[J].软件学报,2007,18(8):1870-1882.
[12]孙立坚,朱翊,刘晓东.基于分层工作流的电子政务突发事件快速信息发布研究[J].地理信息世界,2009(6):16-21.
[13]刘书雷.基于工作流的空间信息服务聚合技术研究[D].长沙:国防科技大学,2006.
