分布式数据挖掘综述
2014-10-20刘滨
刘 滨
(河北科技大学经济管理学院,河北石家庄 050018)
随着网络(有线和无线)技术在计算、通信和安全等领域不断产生重要突破,互联网、移动网、广电网、物联网、视联网等现代网络及衍生业务迅速扩张,形成泛在于网络空间的、包括各种数据和计算资源的分布式计算环境[1-2]。例如:互联网的蓬勃发展,催生出丰富的网络业务形态,如电子商务、电子政务、网络教育、网络游戏等,为各类组织迅速集聚起海量数据。为了最大化这些数据的价值,将其应用范围从传统的服务于业务处理、报表统计的事务服务层次扩展至知识服务层次,需要利用数据挖掘(data mining,DM)技术发现其中隐藏的模式或规则,用以指导和辅助生产或运营中的管理决策行为,以提高决策水平及决策收益。例如,在电子商务领域,研究基于关联规则的购物篮分析方法[3],针对客户动态地调整站点结构和网页内容,有助于实现商品的关联销售;研究购买行为相似的客户分类方法[4],有助于提供个性化服务以提高客户满意度;研究浏览行为相似的客户聚类方法[5],有助于把握各类客户的消费习惯和倾向,向其推荐特定商品和实现交叉销售,既提高了营销的目标性和有效性,又降低了营销成本。
然而,这些互联于网络的数据源间普遍存在异构性、私有性和平台兼容性等限制,兼因行业竞争和法律约束等因素(如个人或企业的数据隐私保护问题等)难于进行集中式挖掘[6],而分布式数据挖掘(distributed data mining,DDM)技术,通常被视为DM技术在分布式环境中的扩展,已经证明了其在应对以上问题时的有效性,并且,即便在数据非物理分布的条件下,DDM技术也能提高挖掘的效率。GIANNELLA等对分布式挖掘与集中式挖掘进行了比较,概括出了DDM的2点优势[7]:
1)网络通信开销较少 在DDM过程中,在每个数据源处进行局部挖掘后,将中间结果(局部模式)而非数据传输到中央处理单元,以便整合出全局模式。与集中式DM需要传输局部数据源处的大量数据相比,DDM中仅需传输局部模式,网络通信带来的时空开销更少;
2)安全性较好 对分布式环境下拥有各个局部数据源的组织而言,DDM过程中只需共享(传递)挖掘出来的局部模式而非全部数据,有助于更好地保护数据私有性。
1 DDM相关概念
1.1 定义与框架

图1 分布式数据挖掘框架Fig.1 Distributed data mining framework
DDM在20世纪90年代后期逐渐被人们关注,通常被定义为分布式环境中的数据挖掘[8],或是利用分布式计算资源挖掘分布式数据资源,并对局部结果(模式)进行整合以得到最终结果(全局模式)[9]。在图1中给出的DDM 高层架构中[10],显然,最终结果的质量与局部数据源的类型、可用性、局部结果的质量及整合方法等密切相关。
DDM的实施未必都以站点间纯粹独立挖掘的方式进行,当某个(些)站点具备较强的计算、存储和通信能力时,这个(些)站点可以汇聚其他站点的数据,形成“全局分布、局部集中”挖掘方式;此外,DDM中的数据也未必都来自于分布式数据源,对于拥有海量集中数据,同时拥有分布式站点(计算资源、存储资源等)的组织来讲,可以将数据分散到各站点,充分利用站点资源,实施分布式挖掘,获得优于集中式挖掘的效率。
1.2 适用场景
DDM通常适用于具有如下特征的场景中[11]:
1)系统包括多个具有独立数据和计算资源的站点,站点间仅通过消息传递进行通信;
2)站点之间的通信开销昂贵(否则,可以进行集中式DM了);
3)站点具有资源限制(例如,资源的可用时间、范围等);
4)会考虑站点资源私有性保护(例如,数据资源的使用权限、可用范围等)的问题。
1.3 研究挑战
当前,DDM研究与应用领域的主要挑战如下[12-13]。
1)异构与同构挖掘 当源数据主要来自少数几处站点,并且由相同的数据库管理系统(data base management system,DBMS)和管理模式来维护时,大部分数据的结构(属性、格式、单位等)规范而统一,此时,DM的主要开销在于处理同构式数据;而当源数据内部存在大量异构数据时,则需要在挖掘前将各分布站点的数据转变为全局一致的结构,否则,结构上的冲突在所难免(例如:同类同质数据却分别归于不同的属性等)。
2)动态环境下的数据多变性 在传统的挖掘过程中,数据通常被视为静态的,挖掘工作在拥有足够多数据的环境中进行。而随着一些新兴业务的发展,例如电子商务,与其相关的数据具有天然的时变性,即数据的产生、有效性等与时间值密切相关,挖掘结果也具有时间敏感性。由此知,在分布式环境下,将各个站点处时间敏感的、具有动态特征的局部挖掘结果正确传送、聚集、整合具有一定的挑战性。
3)通信开销 集中挖掘条件下,挖掘算法通常结合系统的I/O开销和CPU时间开销进行设计。而在分布式数据环境中,站点间的通信开销是影响挖掘效果的重要因素,和网络带宽、传送的信息量等密切相关。
4)知识整合[14-15]DDM的最终目标是通过分析、整合局部模式来获得最终的全局模式。就局部数据集的分析任务而言,可以采取现有的集中式挖掘的方法;而在整合局部结果方面,传统的简单整合的方法或许不再有效。例如,对某个或某些局部站点的有趣模式,放在全局层面来看,或许将不再具有价值。所以,为了整合出全局模式,有必要先收集全部的局部有趣模式,站在全局层面考察局部模式的价值。
5)语义异构 分布式数据源间普遍存在语义异构,而现有DDM模型大多根据数据源间结构上的同构或异构,假设它们是一张虚拟表的水平或垂直分割结果[11],对数据源的挖掘实际是以语义分割的方式独立进行。当数据源间的语义距离较大时,将无法形成该虚拟表的构建基础,由此推及,语义分割式的独立挖掘将损害结果质量[16]。作为一种语义描述模型,本体有效而规范[17],在数据源本体构建相关的本体学习领域[18-20]和计算本体间相似度的本体匹配领域[21-23]积累了很多方法,为有效度量数据源间的语义距离奠定了基础。
2 DDM系统及分类
DDM是利用分布式计算资源挖掘分布式数据资源,通过整合局部结果以获得全局知识的方法,主要瓶颈在于分布式数据环境下的挖掘限制和多算法协作问题,挖掘质量主要取决于局部结果的质量和整合方法的质量。基于以上共识,国内外学者引入Agent和网格等突破挖掘限制、引入元学习优化挖掘算法的选择和组合、引入CDM(collective data mining)框架改善局部结果质量,取得了许多有代表性的成果,下面根据各自的主要设计理念进行归类分析和综述。
2.1 基于Multi-Agent的DDM系统
此类DDM系统的主要设计理念是利用Agent的自治性实现局部挖掘以保护数据私有性;利用Agent的主动性减少用户参与以提高挖掘自动化水平;利用Agent的协作性实现多算法协同挖掘等[24]。
GAYA等给出了一个利用分布式Agent整合局部挖掘结果(Theory)的DATS(decentralized agentbased model for theory synthesis)模型[25],该模型由采用进化方法整合结果的 MASETS(multi-agent system for evolutionary theory synthesis)系统实现。其中,每个Agent的架构如图2所示,其中,每个Agent包括4个模块:分类模块(对于给定的实例e,将其归类于c)、通信模块(通过消息与其他Agent通信)、学习模块(从本地数据Di学习本地结果LT)、整合模块(利用局部结果生成和修正全局结果GT)。
杨博等研究了在分布式动态网络环境中挖掘社区关系问题,引入自组织Agent网络,设计了面向自治计算的AOC(autonomy-oriented computing)方法进行分布式和增量式的网络社区关系挖掘[26],AOC方法利用被动Agent在分布式动态进化网络中协作式地侦测和更新社区结构。如图3所示,社区网络分布于5个不同位置的Agent间,每个Agent对于全网都有自己的局部视图(包括在其控制下的点和从这些点连出的线)。分布式网络社区挖掘的任务可以被描述为这5个Agent利用各自的视图相互协作找出网络中的全部社区。
以上2个研究侧重于对Agent自治性和协作性的利用;MATEO等提出一个智能分布式架构和基于Agent的DM模型来实现自适应机制,以便实施DM算法和多Agent间的高效交互[27]。如图4所示,DM模型基于Multi-Agent系统实现,包括3项DM功能:聚类、分类和关联规则挖掘,来实施知识发现和系统需求的采集。
做法:1.准备适量的燕麦片,然后用温水浸泡三个小时,加入少许蜂蜜,直至糊状。2.将燕麦糊敷在手部,然后用保鲜膜包好整只手。等待8分钟以后,取下保鲜膜,开始搓揉按摩手部。
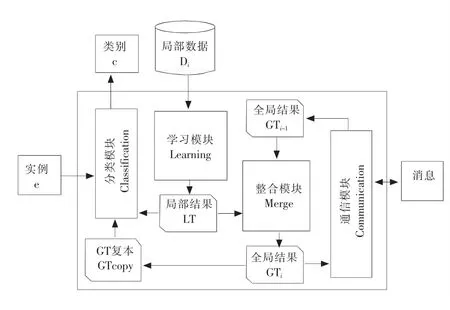
图2 Agent结构Fig.2 Agent′s architecture
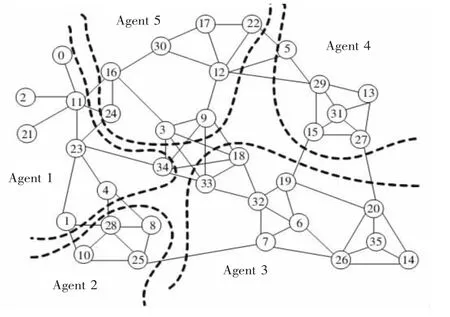
图3 分布式网络社区挖掘问题示意Fig.3 A schematic representation of the d-NCMP
熊赟等设计的挖掘转录调节元素的TREMAgent(transcriptional regulatory element mining agent)系统[28],能对转录因子(transcription factor,TF)或转录因子结合位点(transcription factor binding site,TFBS)的预测,提供多种类的检索和鉴别服务并及时更新结果。如图5所示,TREMAgent包括4类Agent:1)算法Agent,与其他Agent交互以处理各类任务(查询、检索、挖掘);2)数据库Agent,与外部数据源交互,它们也管理数据库的本地拷贝并转换为其他Agent可以访问的格式;3)接口Agent,为其他3类Agent提供间接通信服务;4)协调Agent,在接口Agent和算法Agent间建立通信通道,派发任务给不同的Agent,协调处理和冲突。此外,协调Agent存储每个Agent的信息,维护全系统的控制工作。

图4 面向基于Multi-Agent间通信和协作的智能分布式框架的DM模型Fig.4 Data mining model for the intelligent distributed framework based on the communication and coordination of Multi-Agent

图5 TREMAgent系统全景图Fig.5 Overview of TREMAgent system
综上所述,此类基于Multi-Agent的DDM系统中,多Agent间的通信和协作是影响挖掘效率的重要因素,而现有研究多侧重于协作机制的设计,较少考虑Agent间的通信开销。
2.2 基于网格的DDM系统
基于网格的DDM系统的主要设计理念是利用网格在资源共享、开放服务和协同工作等方面的优势,提高挖掘的可靠性和协同性;在网格计算环境中进行DM,也是通过共享局域和广域网络分享资源(计算和存储等)的典型范例。由此可知,利用网格计算提高挖掘的性能、可扩展性、可访问性和资源利用率是这个方向的主要发展动力。
STANKOVSKI等提出的数据挖掘网格(data mining grid,DMG)[29],基于面向服务的体 系 结 构 (service-oriented architecture,SOA)[30-31]、标准化和开源原则设计。采用了开放式网格服务体系 (open grid services architecture,OGSA)[32-33]和 Web 服 务 资 源 框 架 (web services resource framework,WSRF)[34-35]以支持其进化。图6给出了DMG系统的4层体系架构,通常而言,高层次的组件会调用低层次的组件。最底层组件包括了软件和硬件资源;Globus Toolkit 4层给出了一些系统的核心网格中间件组件;服务层给出了提供中枢DMG服务的组件;客户组件层给出了DMG应用客户端的组件。
为了应对“信息与数据重叠”的挑战,楚一红等提出了基于网格的子空间聚类算法(nonredundant subspace cluster mining,NORSC)[36],以便在保证必要数据覆盖度的前提下高效发现间接的子空间距离。NORSC不仅能避免在给定数据大都归属于高维聚类情况下产生冗余聚类,而且在处理数据覆盖问题时只有有限的信息丢失。图7给出了NORSC算法流程图。

图6 DMG系统体系结构Fig.6 DMG system architecture

图7 NORSC算法流程图Fig.7 Flowchart of algorithm NORSC
罗杰文等系统分析了Agent网格面对的主要问题,实现了一个基于Agent网格的智能平台(agent grid intelligent platform,AGrIP)[37],AGrIP平台为网格环境中基于Agent的DDM提供了底层构造。同时,从实现的观点出发,设计了一个面向AGrIP平台的4层模型,如图8所示。
1)公共资源层(Common Resources) 包括分布在网格环境中的各类资源,例如,工作站、PC机、计算集群、存储设备、数据库、数据集等,可以运行在Unix,Windows NT或其他操作系统平台上。
2)Agent环境层(Agent Environment) 这是网格计算的核心层,负责资源定位、分派、验证、统一信息访问、通信、任务分配和Agent库的管理等。
3)开发工具包层(Developing Toolkits)开发环境,包括Agent的创建、信息检索、DDM,以便让用户更有效地使用网格资源。
4)应用服务层(Application Service) 包括部分面向特定应用的被组织起来的Agent,这些应用包括:科研信息化(E-Science)、电子商务、决策支持和生物信息等。
作为此类方法的基础,网格技术在资源管理和任务调度方面尚有很大的研究空间,而与之关联的负载平衡问题则是提高挖掘效率的关键问题[38]。

图8 AGrIP的体系结构Fig.8 Architecture of AGrIP
2.3 基于元学习的DDM系统
其主要设计理念是通过元学习优化挖掘算法的选择与组合,并对已获知识进行多次学习以提高结果质量[39]。
HMIDA等 提 出 了 Weka4GML 框 架[40],它的建立基于 Globus工具包——一种支持WSRF标准,并被广泛采用的网格中间件,服务于开发元学习方法以处理分布于数据网格间的数据集。Weka4GML扩展了Weka工具包[41-42](一个串行DM算法集,面向知识发现,包括标准的数据预处理、挖掘和可视化技术)来支持数据挖掘算法的分布式执行。如图9所示,Weka4GML包括4种类型的节点:存储节点、基分类节点、元分类节点和用户节点。
1)存储节点 包括分布式数据集的一个或多个片段,并将所存数据及其属性作为Web服务发布,同时通过FTP服务器与其他网格节点分享本地数据。
2)基分类节点 通过在本地数据集上执行基分类算法挖掘局部模式。这些模式被用于各类数据集以进行预测,并将预测结果发送给元分类节点。
3)元分类节点 利用FTP服务器收集元数据,并在其上执行元级挖掘算法生成最终分类器。
4)用户节点 提供系统的图形界面允许用户选择Weka支持的算法,来对存储节点上的数据集进行挖掘,执行网格上的元学习过程。

图9 Weka4GML框架上执行的元学习过程Fig.9 Meta-learning process on Weka4GML framework
杨立等提出的SOA4KD(service oriented architecture for knowledge discovery)体系,结合元学习和语义网来选择和执行挖掘算法[43]。其结构见图10,其中数据服务层对应于“知识发现过程”定义(见文献[43])中的F,知识发现算法服务层对应于“知识发现过程”定义中的L,KB0(knowledge base,背景知识库)以领域本体的形式被放置于语义服务层中;此外,语义服务层中还包含了KDS(knowledge discovery service)质量本体、扩展的知识发现任务本体和回答本体。质量本体是一个可扩展的定义,它不仅包含“知识发现过程”定义中的确定程度C和感兴趣程度I,还包含了KDS作为服务的一些通用测度和过程测度,这就保证了KDS质量评价的通用性、完整性和可扩展性,从而最大限度地满足不同用户多样性的需求。基于自然语言扩展的知识发现任务本体是一个将知识发现任务和自然语言问题元素连接起来的扩展本体,结合领域本体,实现以自然语言方式获取用户需求,SOA4KD通过元学习器动态挑选出满足用户需求的最合适的知识发现算法服务并触发执行,而回答本体的作用是将知识发现的结果转化为自然语言,以方便用户理解。
此类方法的主要局限在于,并非所有挖掘算法都能直接实现元学习。
2.4 基于CDM(collective data mining)框架的 DDM系统
其主要设计理念是将待学习的函数表示为一组基函数的分布式存在,允许各数据源选择不同的学习算法,并以全局结果正确为前提减少网络通信量。
KARGUPTA等提出了CDM框架,建立了基于异构站点的集合式挖掘系统BODHI(besizing knowledge through distributed heterogeneous induction)[44],并将CDM 应用于分布式聚集[45]和Bayes网络[46]中,在解决无法正确生成构造全局结果所需的局部结果方面效果明显。CDM方法的主要步骤如下:
1)在每个数据源站点生成正交基系数;
2)从每个站点选择合适的数据样本,传送到一个专用站点,生成与非线性交叉项对应的标准正交基系数;
3)整合局部模型,将其变形为用户描述出的正则表示中(符合用户的输出要求),输出该最终模式;
4)此类方法需要先根据整体数据集合生成正交数据模型,成本较高,却直接关系到最终结果的质量,而且其表述能力能否满足需要也未能给出证明。

图10 SOA4KD体系结构Fig.10 Architecture of SOA4KD
图11给出了BODHI系统的结构图,共包括4个基础组件:1)独立Agent,可以完成特定学习任务的自治实体;2)Agent站,负责提供Agent运行时环境,以及Agent与其他系统内站点间的通信;3)协调器,是Agent实例,负责各个Agent站间的协作通信;4)系统中传递的消息。

图11 BODHI系统的全景图Fig.11 Overall systems diagram for the BODHI system
3 当前DDM研究存在的问题
第2部分中介绍的4类主要DDM方法,大多根据数据源间的结构关系(同构或异构)设定数据背景,较少考虑数据源间的语义关系及其可能引发的问题,例如,概念间的内在联系因分布式环境而隐匿等,而这将导致局部结果的冗余性或无效性,或遗失潜在有用结果,进而影响全局结果的质量[16]。当前,虽然有涉及此类问题的研究,例如,文献[16]根据频繁项集计算数据源相似度,据此分组数据源并独立挖掘各组,提高了挖掘质量。然而,频繁项集的生成开销正比于数据源规模,限制了该方法的可扩展性;并且,准确度量数据源间的语义关系,需要全面、深入地考察元素和结构距离并进行有效综合。
综上可知,现有DDM研究存在的共性问题有:
1)挖掘质量问题 不考虑各个站点数据源间的内在语义联系,各站点独立挖掘本地数据,与其他站点间无语义层面的数据交互和融合,形成纯粹的“分割式”挖掘,最终导致全局结果质量受损。为此需要研究如何度量站点数据源间的内在语义距离,既从宏观级(例如:数据文件级、数据库级、数据表级等),也从微观级(例如:元组级、属性级、维度级等)度量这种语义距离,构建数据源间语义距离的复合量化体系,并能根据数据源间的语义距离改变或改善挖掘方式,从而提高局部结果的挖掘和整合质量,递进式解决全局结果的质量问题;
2)挖掘效率问题 DDM系统也是分布式计算系统,同样面对各个站点处的负载均衡、通信开销缩减等问题,所以,DDM系统中的挖掘效率问题可以理解为如何调度资源以平衡挖掘负载、减少协作挖掘中的通信开销问题。
4 本体与DM
作为语义网[47-48]的基础,本体能为对象语义距离度量提供有效支持。2000年时,本体第1次被引入DM领域[49],主要被应用于领域和背景知识本体、DM过程本体和元数据本体[50]:1)领域和背景知识本体组织领域知识,在知识发现过程中的几个阶段具有重要作用;2)DM过程本体编辑挖掘过程描述,根据给定问题确定最适合的任务处理方法,例如,DM算法的确定和实施等;3)元数据本体则描述项目构造过程。本体的作用主要有:1)澄清了领域知识的结构,从而为知识表示打好基础;2)为人和组织之间的通信提供共同的词汇,使知识共享成为可能;3)在不同建模方法、范式、语言和软件工具之间进行翻译和映射,以实现不同系统之间的互操作和集成[51-52]。
在利用本体描述挖掘任务的领域背景方面,MARINICA等针对关联规则挖掘中需要从海量规则中遴选有效规则的问题,提出了交互式的、用于删减冗余规则的挖掘后处理方法ARIPSO(association rule inter-active post-processing using schemas and ontologies)[49],应用本体表达用户的背景知识,在挖掘后处理时改善用户知识的集成。图12给出了ARIPSO的框架结构,包括2个部分:首先,利用知识库规范化用户知识和目标,通过领域知识展现用户知识的概貌,通过用户期望阐明用户对被发现规则的先验知识;其次,后处理任务包括迭代应用一系列的筛选器(最小化提升约束筛选器、条目关联筛选器和模式筛选/裁剪)对规则集进行筛选,以提取出有价值的规则。
在利用本体描述DM过程本身方面,ŽAKOVÁ等针对在给定知识发现过程的输入和输出类型前提下,知识发现工作流的自动构造问题,提出了解决方法[53]。该方法包括2个步骤:1)通过知识发现本体定义知识类型和DM算法的规范化概念;2)利用领域和任务本体实现工作流组成的规范化。该方法的核心是由知识发现本体所提供的知识发现领域中的规范化概念。如图13所示,该本体定义了知识发现的场景、各种知识的表示和算法,其基本目标是使得工作流计划制定者能够以之为根据,对于具体的DM任务选择出可以产生中间和最终结果的算法。

图12 ARIPSO系统框架Fig.12 ARIPSO Framework description

图13 知识本体的部分上层结构(子类间的关系由箭头指示)Fig.13 Part of the top level structure of the knowledge type part of the ontology with subclass relations shown through arrows
5 结 语
对DDM研究领域的研究现状进行综述,介绍了基本概念,结合实例对主要系统进行分类,归纳出主要问题与挑战。通过本文的阐述可知,为了提升分布式挖掘过程中局部结果和最终结果的质量,策略之一就是将DDM理论和本体理论作融合,以数据源间语义距离的度量为突破口,建立语义距离度量的复合量化体系,通过构建和求解新型DDM模型来实现目标。具体路线:首先,利用本体描述数据源的语义特征;进而,基于本体匹配技术构建数据源间语义距离的复合量化体系,根据度量结果分组数据源,并依次构建层次化的挖掘模型、知识整合模型和负载平衡机制;最终,形成具有可操作性和可解释性的DDM方法,并结合具体实例进行实验验证和仿真分析。
[1] DELAMARE S,FEDAK G,KONDO D,et al.SpeQuloS:A QoS service for BoT applications using best effort distributed computing infrastructures[A].Proceedings of the 21st International Symposium on High-Performance Parallel and Distributed Computing(HPDC’12)[C].New York:ACM,2012.173-186.
[2] PETER B,LI Y,THAIN D.Weaver:Integrating distributed computing abstractions into scientific workflows using Python [A].Proceedings of the 19th ACM International Symposium on High Performance Distributed Computing(HPDC’10)[C].New York:ACM,2010.636-643.
[3] CHEN Jinlin,XIAO Keli.BISC:A bitmap itemset support counting approach for efficient frequent itemset mining[J].Transactions on Knowledge Discovery from Data,2010,4(3):1-37.
[4] GOES P,ILK N,YUE W T,et al.Live-chat agent assignments to heterogeneous e-customers under imperfect classification[J].Transactions on Management Information Systems,2011,2(4):1-15.
[5] DEODHAR M,GHOSH J.SCOAL:A framework for simultaneous co-clustering and learning from complex data[J].Transactions on Knowledge Discovery from Data,2010,4(3):1-31.
[6] LIU Bin,CAO Shugui,HE Wu.Distributed data mining for e-business[J].Information Technology and Management,2011,12(2):67-79.
[7] GIANNELLA C,BHARGAVA R,KARGUPTA H.Multi-agent systems and distributed data mining[A].Cooperative Information AgentsⅧ:8th International Workshop(CIA’04)[C].Berlin:Springer,2004.1-15.
[8] HAMMOUDA K M,KAMEL M S.Hierarchically distributed peer-to-peer document clustering and cluster summarization[J].IEEE Transactions on Knowledge and Data Engineering,2009,21(5):681-698.
[9] LIU Kun,KARGUPTA H,RYAN J.Random projection-based multiplicative data perturbation for privacy preserving distributed data mining[J].IEEE Transactions on Knowledge and Data Engineering,2006,18(1):92-106.
[10] PARK B H,KARGUPTA H.Distributed Data Mining:Algorithms,Systems,and Applications[M].Mahwah:Lawrence Erlbaum Associates,2002.
[11] DA S J C,GIANNELLA C,BHARGAVA R,et al.Distributed data mining and agents[J].Engineering Applications of Artificial Intelligence,2005,18(7):791-807.
[12] DAVIES W H E,EDWARDS P.Agent-based knowledge discovery[A].Working Notes of the AAAI Spring Symposium on Information Gathering from Heterogeneous,Distributed Environments[C].Stanford:Stanford University,1995.234-237.
[13] 庄 艳,陈继明,徐 丹,等.基于 Multi-agent系统的分布式数据挖掘[J].计算机科学,2007,34(12):163-167.
ZHUANG Yan,CHEN Jiming,XU Dan,et al.Distributed data Mining based on Multi-agent system[J].Computer Science,2007,34(12):163-167.
[14] JASJIT S.Distributed R &D,cross-regional knowledge integration and quality of innovative output[J].Res Policy,2008,37(1):77-96.
[15] SUMNER M.How alignment strategies influence ERP project success[J].Enterprise Information Systems,2009(4):425-448.
[16] LI Tao,ZHU Shenghuo,OGIHARA M.A new distributed data mining model based on similarity[A].Proceedings of 2003ACM Symposium on Applied Computing[C].New York:ACM,2003.432-436.
[17] WASSIM J,NAJLA S,FAIEZ G.Approach and tool to evolve ontology and maintain its coherence[J].International Journal of Metadata,Semantics and Ontologies,2010,5(sup2):151-166.
[18] ZAVITSANOS E,PALIOURAS G,VOUROS G A.Gold standard evaluation of ontology learning methods through ontology transformation and alignment[J].IEEE Transactions on Knowledge and Data Engineering,2011,23(11):1635-1648.
[19] WEICHSELBRAUN A,WOHLGENANNT G,SCHARL A.Refining non-taxonomic relation labels with external structured data to support ontology learning[J].Data and Knowledge Engineering,2010,69(8):763-778.
[20] 刘凯鹏,方滨兴.基于社会性标注的本体学习方法[J].计算机学报,2010,33(10):1823-1834.
LIU Kaipeng, FANG Binxing.Ontology induction based on social annotations [J].Chinese Journal of Computers,2010,33(10):1823-1834.
[21] NICOLA F,CLAUDIA D,FLORIANA E.Composite ontology matching with uncertain mappings recovery[J].ACM SIGAPP Applied Computing Review Archive,2011,11(2):17-29.
[22] MASCARDI V,LOCORO A,ROSSO P.Automatic ontology matching via upper ontologies:A systematic evaluation[J].IEEE Transactions on Knowledge and Data Engineering,2010,22(5):609-623.
[23] LI Juanzi,TANG Jie,LI Yi,et al.RiMOM:A dynamic multistrategy ontology alignment framework[J].IEEE Transaction on Knowledge and Data Engineering,2009,21(8):1 218-1 232.
[24] SANTHANA C,KATIE A,FRANS C.Multi-agent based clustering:Towards generic multi-agent data mining[A].Proceedings of the 10th Industrial Conference on Advances in Data Mining:Applications and Theoretical Aspects(ICDM’10)[C].Berlin:Springer,2010.115-127.
[25] GAYA M C,GIRÁLDEZ J I.Merging local patterns using an evolutionary approach[J].Knowledge and Information Systems,2011,29(1):1-24.
[26] YANG Bo,LIU Jiming,LIU Dayou.An autonomy-oriented computing approach to community mining in distributed and dynamic networks[J].Autonomous Agents and Multi-Agent Systems,2010,20(2):123-157.
[27] MATEO R M A,LEE J W.Data mining model based on multi-agent for the intelligent distributed framework[J].International Journal of Intelligent Information and Database Systems,2010,4(4):322-336.
[28] XIONG Yun,ZHENG Guangyong,YANG Qing,et al.A collaborative multiagent system for mining transcriptional regulatory elements[J].IEEE Intelligent Systems,2009,24(3):26-37.
[29] STANKOVSKI V,SWAIN M,KRAVTSOV V,et al.Digging deep into the data mine with DataMiningGrid[J].IEEE Internet Computing,2008,12(6):69-76.
[30] DAN A,JOHNSON R D,CARRATO T.SOA service reuse by design[A].Proceedings of the 2nd International Workshop on Systems Development in SOA Environments(SDSOA’08)[C].New York:ACM,2008.35-40.
[31] JOSUTTIS N.SOA in Practice[M].California:O'Reilly Media,2007.
[32] FOSTER I,KESSELMAN C,NICK J,et al.Grid services for distributed system integration[J].Computer,2002,35(6):37-46.
[33] NATHALIE F,WILLIAM L,ANTHONY M,et al.ICENI:An open grid service architecture implemented with Jini[A].Proceedings of the 2002 ACM/IEEE Conference on Supercomputing(Supercomputing’02)[C].Los Alamitos:IEEE Computer Society Press,2002.1-10.
[34] ZHANG Donglai,CODDINGTON P,WENDELBORN A.Web services workflow with result data forwarding as resources[J].Future Generation Computer Systems,2011,27(6):694-702.
[35] MOLTÓI,HERNÁNDEZ V,ALONSO J M.Automatic replication of WSRF-based Grid services via operation providers[J].Future Generation Computer Systems,2009,25(8):876-883.
[36] CHU Yihong,CHEN Yiju,YANG Denian,et al.Reducing redundancy in subspace clustering[J].IEEE Transactions on Knowledge and Data Engineering,2009,21(10):1432-1446.
[37] LUO Jiewen,WANG Maoguang,HU Jun,et al.Distributed data mining on agent grid:Issues,platform and development toolkit[J].Future Generation Computer Systems,2007,23(1):61-68.
[38] HERRERO P,BOSQUE J L,PÉREZ M S.Covering the cooperative load balancing delivery in collaborative grid environments[J].Multiagent and Grid Systems,2009,5(3):267-286.
[39] PRODROMIDIS A L,CHAN P K,STOLFO S J.Meta-learning in distributed data mining systems:Issues and approaches[A].Advances of Distributed Data Mining[C].California:MIT/AAAI Press,2000.81-114.
[40] HMIDA M B H,SLIMANI Y.Meta-learning in grid-based data mining systems[J].International Journal of Communication Networks and Distributed Systems,2010,5(3):214-228.
[41] BOUCKAERT R R,FRANK E,HALL M A,et al.WEKA-experiences with a java open-source project[J].The Journal of Machine Learning Research,2010,11:2533-2541.
[42] LIEVENS S,BAETS B D.Supervised ranking in the weka environment[J].Information Sciences,2010,180(24):4763-4771.
[43] 杨 立,左 春,王裕国.面向服务的知识发现体系结构研究与实现[J].计算机学报,2005,28(4):445-457.
YANG Li,ZUO Chun,WANG Yuguo.Research and implementation of service oriented architecture for knowledge discovery[J].Chinese Journal of Computers,2005,28(4):445-457.
[44] KARGUPTA H,PARK B,HERSHBERGER D,et al.Collective data mining:A new perspective toward distributed data mining[J].Advances in Distributed and Parallel Knowledge Discovery,1999,2:131-174.
[45] KARGUPTA H,HUANG W,SIVAKUMAR K,et al.Distributed clustering using collective principal component analysis[J].Knowledge and Information Systems,2001,3(4):422-448.
[46] CHEN R,SIVAKUMAR K,KARGUPTA H.Collective mining of bayesian networks from distributed heterogeneous data[J].Knowledge and Information Systems,2004,6(2):164-187.
[47] TIM B L,HENDLER J,LASSILA O.The semantic web[J].Scientific American,2001,284(5):34-43.
[48] SHADBOLT N,HALL W,TIM B L.The semantic web revisited[J].IEEE Intelligent Systems,2006,21(3):96-101.
[49] MARINICA C,GUILLET F.Knowledge-based interactive post mining of association rules using ontologies[J].IEEE Transaction on Knowledge and Data Engineering,2010,22(6):784-797.
[50] NIGRO H,CISARO S G,XODO D.Data Mining with Ontologies:Implementations,Findings and Frameworks[M].Hershey:Idea Group Inc,2007.
[51] 王春红,刘紫玉.基于本体和多代理的考试系统模型研究[J].河北工业科技,2010,27(3):174-176.
WANG Chunhong,LIU Ziyu.Research in examination system model based on ontology and multi-agent[J].Hebei Journal of Industrial Science and Techology,2010,27(3):174-176.
[52] 张 娟,高克峰,张 曦.从文本中学习本体的系统设计[J].河北工业科技,2011,28(3):160-163.
ZHANG Juan,GAO Kefeng,ZHANG Xi.Design of system of learning ontology from texts[J].Hebei Journal of Industrial Science and Technology,2011,28(3):160-163.
[53] ŽAKOVÁ M,KR RˇEMEN P,ŽELEZN YˇF,et al.Automating knowledge discovery workflow composition through ontology-based planning[J].IEEE Transactions on Automation Science and Engineering,2011,8(2):253-264.
