一种基于中文分词的主观题自动评分优化算法研究*
2014-10-10胡恩博余腊生
胡恩博,余腊生
(1.中南大学信息科学与工程学院,湖南长沙 410083;2.湖南第一师范学院信息科学与工程学院,湖南长沙 410205)
一种基于中文分词的主观题自动评分优化算法研究*
胡恩博1,2,余腊生1
(1.中南大学信息科学与工程学院,湖南长沙 410083;2.湖南第一师范学院信息科学与工程学院,湖南长沙 410205)
论述了一种基于中文分词的主观题自动评分优化算法的设计与实现,详细介绍了中文分词技术及实现方法,对单词串匹配度从单词长度、单词词形、单词顺序及影响因子四个方面进行算法设计与分析,最后进行实验测试,测试结果表明采用此优化算法进行的自动评分准确率有显著提升.
中文分词;自动评分;相似度
考试是高校教育中的一个重要环节,考试后的阅卷评分工作,特别是涉及到全校性质的基础课程的阅卷评分工作给教师带来沉重负担的同时,还会带来效率低下,以及人为因素影响的公平公正问题.
现今社会的考试系统对于客观题的评分技术已经相当成熟,但在主观题的评分上由于受到很多因素,如算法复杂度、人类自然语言等的影响,还存在很多缺陷.现有研究基于最优指派问题的匈牙利算法[1]能较好地解决主观题评分的准确率问题,但运算速度有待提高;基于LSA(Latent Semantic Analysis,用于文本语义分析的潜在语义分析算法)的算法又过于繁琐,难于实现.
基于此,本文设计了一种易实现、且运算效率佳的基于中文分词的主观题自动评分优化算法,其原理图如图1所示,经测验,该算法能满足一般通用课程的主观题评分准确与效率可行的要求.

图1 算法原理图
1 中文分词技术
随着国内计算机的发展与应用的普及,中文分词的发展与应用也突飞猛进,衍生出了很多不同的算法,归纳其特点可分为:字符串匹配分词算法、理解分词算法、统计分词算法及语义分词算法四类[2].
其基本原理是将答案文件先做去标点、表格及图形的初始预处理,从《知网》知识库中获取各词的概念定义[3],然后利用分词技术,对其进行分词处理,得到单词串文件.其原理如下图2所示.

图2 分词处理流程
预处理与分词技术已经比较成熟,以分词技术为例,目前网络上有很多开源的分词软件,如跨平台的IKAnalyzer、Paoding和LibMMSeg等,以及基于Windows平台的FreeICTCLAS和CRF等,图3为利用基于跨平台的Paoding开源分词技术对“中华人民共和国万岁”这一语句进行分词计算的结果示例.

图3 分词示例
2 单词串匹配度计算
单词匹配度是衡量单词串A与单词串B相似程度的标准.匹配度越高表明两个单词串的意思越相近.单词串匹配度是用来判断考生答案文件和标准答案文件的相近程度.
单词串匹配中语义相似度的算法一般分为两类:基于语义词典的词语相似度算法和基于语料库的词语语义相似度算法[4].这两种方法共同的问题是过于依赖各自的词典以及语料库.
基于人工智能的理论思想,本文设计了一种从单词串长度、顺序和形状三者相结合的多层次比较算法,在提升了单词串匹配度计算的性能的同时,对主观题评分的准确率有明显改善.
3 算法实现
对于主观题的阅卷,教师一般先观察答案的字数够不够,有没有足够的篇幅,这一问题可描述为单词串的长度相似计算.其次是看有没有关键点,把这一问可分解描述为单词串的词形相似、词序相似及词点相似问题.将这三者综合,便是人工阅卷评分的思想.
以上四点可用四个算法解决,四个算法彼此约束,综合评分,现将算法实现如下:
3.1 单词串A长度与单词串B长度相似计算算法

式(1)中用Length(StringA)来表示标准答案文件经过预处理和分词技术分词后得到的单词串A,Length(StringB)表示考生答案文件经过同样处理后得到的单词串B,String-LengthSimila表示两者的长度相似度.
例1:Question:中国的全称是?
A1:中华人民(不完全得分答案)
A2:中华人民共和国(标准答案)
A3:北京人民大会堂(不得分答案)
以上标准答案A2经过分词处理后得到的分词结果见图3,则可知Length(StringA)=5,假设考生答案文件为A1,则Length(StringB)=3,若考生答案文件为A2,则Length(StringB)=5,由此得到StringLengthSimila分别为0.75和1.
由此可见,StringLengthSimila值越大,考生答案就与标准答案越相近.当然,如果仅凭这一项来评分就有可能出现完全错误的评分结果,例如如果考生答案是A3,分词后的结果为:北京|北京人|人民|大会|大会堂,得到的长度为5,如果仅凭长度评分的话,这个完全错误的答案会得到满分.
3.2 单词串A与单词串B词形相似计算算法

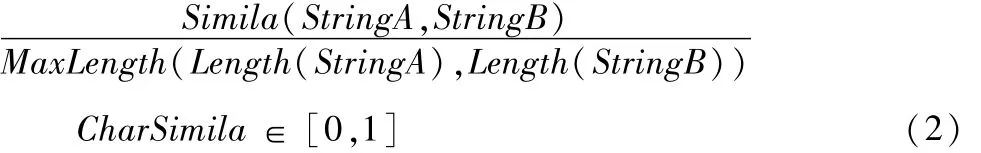
式(2)中用CharSimila表示单词串A与单词串B的词形相似度,SimilaChar表示两者相似词形的个数,MaxLength表示两者最大的单词个数.同样以例1为例,由此算法可知A1的词形相似度约为0.6,A2的词形相度为1,A3的词形相似度约为0.2.
由此可见,CharSimila的值越大,两个单词串就越相似,这样考生答案就越接近标准答案.
3.3 单词串A与单词串B的词序相似计算算法

式(3)中用SortSimila表示单词串A与单词串B的词序相似度,COUNT用来统计两个单词串的逆序数,Only1用来计算单词串A与单词串B中都出现并且仅出现1次的单词的集合.以例1为例,

由此算法可知A1、A2及A3的SortSimila均为1,显然SortSimila针对此一类答案的评分是有很大偏差的,但是否就该完全无视SortSimila呢,显然不能,比如学生的答案是A4(美利坚合众国),则Only1<1,故SortSimila=0,针对这一类答案,SortSimila的评判就尤为准确与重要.
3.4 字符串A与字符串B的综合相似计算算法
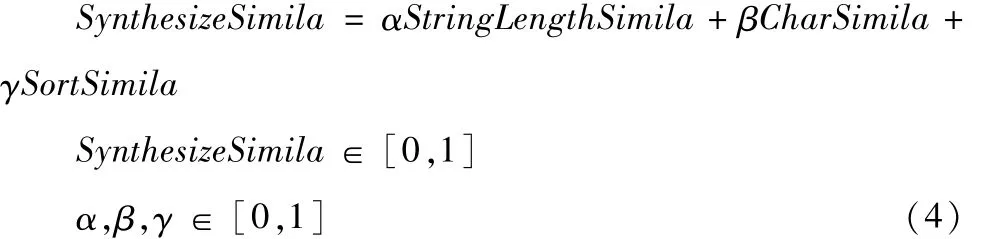
式(4)中α、β、γ分别为字符串长度、词形及词序相似度的影响因子,可根据不同的考试科目特点自定义,最后综合三者评分.
4 测试结果
依据以上算法,在点上对本文提及的四个答案进行综合相似度计算,对α、β、γ分别赋值0.2、0.7、0.1,则计算到的四个答案的综合相似度A1=0.67、A2=1、A3=0.42、A4=0.07.
在面上,通过4个实验进行测试,试卷题目分别为4个Office简答题,标准答案控制在100字内,每个实验回收电子试卷50份,与使用原算法的实验结果进行比对,结果如表1所示:
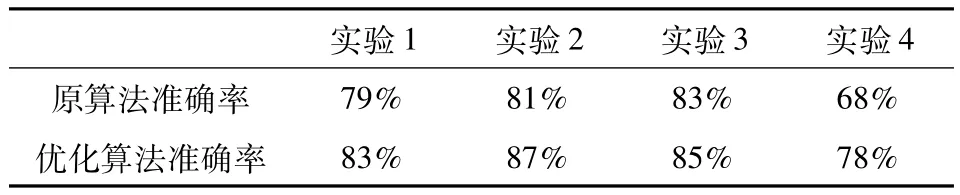
表1 原算法与优化算法准确率测试比对
通过以上测试结果可知,优化后的算法准确率在实验1、2和4上有明显提高,但在实验3上提高百分点不大.究其原因,在人工查看实验3的每个答案后,发现是由于实验3的答案在SortSimila度上已经很接近标准答案,故评分差距不大.
5 结语
本文算法由3个小算法综合而成,评分在综合考虑长度、词形与词序相似度的同时,还要根据考试科目的特性相对设置影响因子α、β、γ的值.一般而言,影响因子β的值所占比重要远远高于α、γ,即词形相似度的比重应充分考虑.本文在词形相似度较高的情况下的评分效果与原算法差距不大,依然有改进的空间.
[1]张旭辉,朱宏辉.最优指派问题匈牙利算法的探讨与C++实现[J].技术交流,2004,(5):67-69.
[2]张启宇,朱玲,张雅萍.中文分词算法研究综述[J].情报探索,2008,(11):53-56.
[3]张以利.匈牙利算法在主观题自动批阅中的应用研究[J].南京工业职业技术学院学报,2007,(2):73-75.
[4]李玉红,柴林燕,张琪.结合分词技术与语句相似度的主观题自动判分算法[J].计算机工程与设计,2010,(11):251-254.
(责任编校:晴川)
An Optim ization Algorithm of Automatic Grading for Subjective Questions Based on Chinese W ords Segmentation
HU Enbo1,2,YU Lasheng1
(1.School of Information Science and Engineering,Central South University,Changsha Hunan 410083,China;2.School of Information Science and Engineering,Hunan First Normal University,Changsha Hunan 410205,China)
The paper discusses the design and implementation ofan optimization algorithm ofautomatic grading for subjective questions based on Chinese words segmentation,introduces the Chinese segmentation technology and implementation method in detail,designs and analyses the word stringmatching algorithm from four aspects of the word length,word formation,word order and influencing factors,and finally the experiment is tested.The test results show that automatic grading accuracy is significantly improved with this optimization algorithm.
Chinese words segmentation;automatic grading;similarity
TP301
A
1008-4681(2014)05-0059-03
2014-06-11
胡恩博(1980-),男,湖北咸宁人,湖南第一师范学院信息科学与工程学院讲师,中南大学信息科学与工程学院硕士生.研究方向:软件工程.
