基于Hadoop平台的并行化数据分类算法研究
2014-10-10黄黎,顾筠
黄 黎,顾 筠
HUANG Li,GU Jun
(江苏开放大学 信息工程系,南京 210017)
0 引言
随着云时代的到来和移动互联网的快速发展,数据规模急剧膨胀,数据挖掘的要求和环境也变得越来越复杂。数据分类作为数据挖掘中一项非常重要的工作,在商业、军事、科研的决策分析中应用广泛。但是海量数据本身具有噪声、异构、算法复杂、技术复杂等问题,使得传统的基于统计理论和机器学习算法的分类方法及其体系架构在海量数据中面临很多局限,因此,在海量Web数据分类中如何提高数据处理能力和执行效率已成目前的研究热点。
云计算平台提供的分布式文件存储和并行计算能力,为解决海量数据挖掘任务,提高挖掘效率提供了有效的手段。云计算Hadoop[1]平台的分布式系统基础架构充分利用超大集群进行高速运算和存储,为海量数据挖掘提供了一个并行计算框架。用户可以在不了解分布式底层细节的情况下,利用其MapReduce编程模式开发一个高度可扩展的分布式批量处理系统,有利于进行海量数据分类[2,3]。
本文基于云计算Hadoop平台下的MapReduce并行技术,提出改进的海量数据集成分类算法,提高了分类精度,在分类效率上达到了较好的加速比。
1 相关研究工作
目前,基于云计算的海量数据挖掘技术的研究正成为学术界研究的热点,很多学者认为MapReduce模型适合结构一致的海量数据,且要求计算简单;而大量的数据密集型应用,往往涉及到数据降维、程序迭代、近似求解等复杂的算法,计算非常困难。针对传统数据挖掘软件扩展性差以及MapReduce数据分析功能薄弱的特点,斯坦福大学Chu等人在国际学术会议NIPS’2006提出一种基于MapReduce的、适用于大量机器学习算法的通用并行编程框架,实现了在若干独立数据集上的并行化求和操作。Ranger等人提出了一个基于MapReduce的应用程序编程接口Phoenix,并实现了K-Means、主成分分析和线性回归三种数据挖掘算法。2011年,IBM研究院在KDD’2011会议上提出一种改进的基于MapReduce的并行数据挖掘和机器学习算法执行工具包NIMBLE[4]。中科院计算所与中国移动研究院合作研发了基于Hadoop的并行分布式数据挖掘平台PDMiner,集成了多种机器学习算法。但是基于云计算的海量数据挖掘技术仍存在许多问题亟待解决,例如各种数据挖掘算法的并行化策略,在MapReduce上实现更加复杂的分析、更大规模的分析等。
国内也有学者基于云计算的分布特点,做了很多研究工作。复旦大学一篇2010年SIGIR的论文对文档局部重复检测做了研究[5],他们的工作将重复检测定位于更细粒度的句子级别,使用了三步MapReduce工作:首先建立倒排索引,然后提取出句子特征,建立句子重复矩阵,最终将句子重复检测过程转换成了矩阵的对角线发现的过程。有学者提出基于属性集的不可辨识性和MapReduce设计了适合数据并行的差别矩阵,首次提出了面向大规模数据的差别矩阵知识约简算法[6]。很多研究者对在多核集群上以MapReduce方式实现机器学习算法进行了研究,如:KNN,K-means,ID3决策树等,验证了MapReduce化的高效性和可扩展性,在一定程度上提高了大数据处理的效率但并未改变传统决策树算法的分类精度[7~9]。有研究者采用朴素贝叶斯文本分类算法的MapReduce并行化方法,对文本统一格式进行分类,识别率达到86%,由于没有进行专门的特征词提取,因此对实验结果有一定程度的影响[10]。
2 并行化数据分类算法模型
2.1 MapReduce并行集成分类执行框架
数据分类过程一般分为3个关键过程:特征提取、特征加权和特征分类。针对大数据分类的上述过程,提出基于Hadoop平台的并行化分类算法,利用MapReduce并行编程模式的可扩展性,充分利用集群达到高速运算和有效分类的目的。具体过程如下:
1)并行特征提取:利用不同特征词共同出现的频率进行衡量,执行基于词共现模型的特征提取,形成具有领域指向性的特征项集合;针对特征稀疏问题,利用外部知识库构造产生新的特征集合,执行基于知识推理的特征构造。
2)并行特征加权:针对特征项,按照语义相关性进行启发式分析,利用TF*RF方法和基于概念层次结构的加权算法衡量分类特征项的重要程度。
3)并行特征分类:实现基于SVM、KNN分类算法的并行化处理。
2.2 并行化特征提取
2.2.1 基于词共现模型的并行化特征提取算法
该过程利用反映主题特征的多个属性项,即频繁共现词(Co-occurrence),通过特征之间的关联性提高特征向量之间距离计算的准确性。其MapReduce化过程如下:
1)使用分词工具对原数据集进行分词,得到分词集合。
2)在每个Map函数中读入分词后的集合块,对块中的每个分词后的文档提取Label和文档ID,作为key值,然后通过信息增益从集合块中选择决策性特征,形成特征序列,加入到value中,形成<key,value>。
3)每个Map函数输出中间值对<<Label,ID>,特征向量,特征相关性(COR)>,其中,特征相关性利用不同特征词共同出现的频率进行衡量,共现的频率越高,其关联越紧密。特征间的相对共现度可计算如下:

4)Reduce函数将上述中间结果中key值相同的结果合并,处理所有相同key值的特征向量,并且输出最终的<<Label,ID>,特征向量>。
2.2.2 基于知识推理的并行化特征构造算法
针对特征提取中关键词同义、近义、稀疏等问题,本文采取一种基于WordNet知识推理(WordNet-Inference)的学习方法,利用WordNet中的同义词集合为每个集合标明一个词汇概念,利用特征属性的同义词集合对文档特征进行划分。其MapReduce化过程如下:
1)每个M a p函数以文档为单位,将<Label,ID>读入key中。
2)利用WordNet相似度(WordNet-Similarity)计算包获得两个形式相似或各异的词项在同义词集合中的近似概念范围,输出中间值对。
其中,语义关联特征的推理形式化表示如下:ai和aj是分别位于不同文档中的属性特征,按照WordNet中词汇的上位词对这两个特征属性词汇寻找其共同上位af,当存在该共同上位时,则可用该共同上位词af替代ai和aj,可更好的突出主题,达到较好的分类目的。
同时,对推理规则进行严格限制:利用语义相似度权函数计算特征词间的语义距离d,给定λ表示语义距离阈值,只有满足大于阈值的概念特征才进行语义推理。
3)Reduce函数对经过规则限制及推理后的中间结果进行合并,输出结果<<Label,ID>,特征向量>,送入特征加权MapReduce过程。
2.3 并行化特征加权
2.3.1 基于TF*RF的并行化特征加权算法
使用“单位”样式。
特征权重是对特征向量值的计算方式,常用的计算方式有TF*IDF,Binary,TF,TF*CHI等,IDF类方法虽然考虑了词的分布特征,但是IDF没有考虑到类别的区分度,在实际实验中效果有时没有提升反而会下降,因此本文采用TF*RF的特征加权算法。TF计算方法如下:

其中n(t,d)是词语t在文档d中出现的次数,分母是文档d中所有词语出现次数总和。
文档中词语t的RF(Relevance Frequency,相关度频率)计算方法如下:

其中,b表示词语t在正例中的文档个数,c表示负例的文档个数。显然,对正面分类中的高频词比负面分类考虑得越多,那么,它对正例选择所做的贡献就要比负例越大。
基于TF-RF的特征加权MapReduce化过程由两个MapReduce Job组成, Job1以文档<Lable,ID>作为key,特征向量(Term-Vector)作为value,Reduce1计算每个特征的TF-RF值;Job2负责将<<Label,ID>,特征TF-RF>形式的数据转换为<<Label,ID>,特征向量>的形式。
2.3.2 基于概念层次结构的并行化特征加权算法
在2.2.2中构造的概念层次结构(Concept-Hierarchy)中,形成了一个多个概念主题特征下的多元特征集合,即F={A,C1,…,Cn},A表示原始特征集合,Ci表示相关概念的特征集合。当文档中的若干特征均与某一概念存在映射关系时,则其权值可计算如下:

其中,wF(ai)表示特征属性ai的权重,wInvIndex(cj)表示概念cj相对于ai的权重,kj为特征aj对应的概念cj的索引序列。
在基于概念层次结构的特征加权MapReduce化过程中,Job1主要针对每个文档中的每个特征计算它的权值。Job2主要实现将<<Lable,ID>,特征向量>形式的数据转换为<<Lable,ID>,特征向量加权>的形式。
2.4 关键词并行化特征分类
2.4.1 KNN并行化分类算法
KNN分类算法依据最邻近的K个样本的类别来决定待分类样本所属类别。采用余弦相似度度量文本特征向量之间的距离。
在KNN算法的MapReduce化过程中,Map函数将Label及ID存入key中,将训练数据文档的原始特征向量存于value中,计算测试向量与所有的训练数据的余弦相似度,选择前K个相似度最大的训练数据和测试向量一起发送给Reduce函数作为values,Reduce从values中取出距离,选择K个距离最小的训练数据,对于这K个训练样本,把多数样本所属的类别作为该测试数据的类别,输出分类结果。
2.4.2 SVM并行化分类算法
支持向量机的主要思想是要在r维空间中寻找一个最佳决策面,使得该决策面能最好地区分正例和反例,让正例和反例之间的分类间隔达到最大。SVM模型有两个非常重要的参数C与gamma。惩罚系数C越高,说明越不能容忍出现误差。C过大或过小,泛化能力都会变差。gamma是选择径向基函数作为kernel后,该函数自带的一个参数,隐含地决定了数据映射到新的特征空间后的分布,gamma越大,支持向量越少,gamma值越小,支持向量越多。由于(C,gamma)相互独立,因此便于并行化进行,其步骤如下:
1)首先将所有的参数对(C,gamma)计算出来,写入文件中,每行一组参数,然后上传到Hadoop上,系统会自动的将文件分发到每一台机器上。
2)将训练样本作为输入,即Map中的每对<key,value>就代表着一条样本,其中key为系统默认值,value为训练样本的每一行数据。将所有的参数对读入到list中。
3)Map产生中间结果,把输入的数据作为value,list中每组参数对作为key进行输出。
4)Reduce函数按照key进行排序,并将key相同的数据放在同一个机器上,将具有相同key的所有values汇总组成原来的训练样本。
5)把解析出来的参数以及整理好的样本进行训练,并把交叉验证的结果输出。
3 性能测试和评估
3.1 实验环境搭建
本实验基于云计算平台Hadoop开源框架实现虚拟化集群架构。实验环境共有7个节点:1个主节点和6个从节点,前者主要配置NameNode和JobTracker的角色,负责总管分布式数据和分解任务的执行,后者配置DataNode和TaskTracker的角色,负责分布式数据存储以及任务的执行。每个节点的配置为内存4G,4核处理器Intel(R)CoreTM i7 CPU 860@2.8GHz,操作系统为Ubuntu 10.04,Hadoop版本为0.20.2。
本实验在UCI数据库的Amazon Commerce Reviews(亚马逊电子商务网站用户评论)数据集和Adult(美国人口普查数据)数据集上进行。对每个数据集中的训练数据和测试数据按9:1的大小比例分配,使用交叉验证。对每个数据集所采用的特征提取和特征加权采用不同的算法组合,以验证其分类精度和时间加速比。在基于知识模型推理的特征提取算法中,取λ=0.5,在KNN分类算法中,取K=5。
3.2 测试结果评价
本实验从两个方面对Hadoop平台下的数据分类进行测试,包括:1)大规模数据的分类精度;2)在大数据处理中并行化程度不同所产生的时间加速比。在不同数据集上采用不同算法组合得到的分类精度如表1、表2所示。
表1、表2的实验结果表明,尽管基于词共现模型的特征提取算法很直观,但是分类精度并不高。这是由于Amazon Commerce Reviews数据量较少,且一般情况下评论本身很短,共现词出现的几率相对较小。同时由于评论内容的随意性,使得该数据集的属性具有高维性,有10000多个属性,导致特征提取困难。而基于知识模型推理的特征提取方法整体上优于共现词模型特征提取方法。另外,在各种组合下概念模型推理的特征向量加权算法优于TF*RF算法,也体现出SVM算法相对于KNN算法在分类精度上的优势。同时,对比两个数据集的分类精度发现在Adult数据集上的测试结果优于Amazon数据集。这是由于Adult数据集的样本量较大,抽取的特征数量高于Amazon数据集,属性数量适宜,有14个属性,属性类别主要为数值型和类别型,属于半结构化的数据类型,因此分类精度较好。

表1 在Amazon Commerce Reviews上的精度

表2 在Adult上的精度
在同一数据集上,不同的算法组合得到的加速比是不一样的,但是加速比的变化趋势都是一致的,即随着DataNode个数的增加而递增。如图2所示,其中C表示Co-occurrence,W表示WordNet-Inference,T表示TF*RF,H表示Concept-Hierarchy,K表示KNN,S表示SVM。
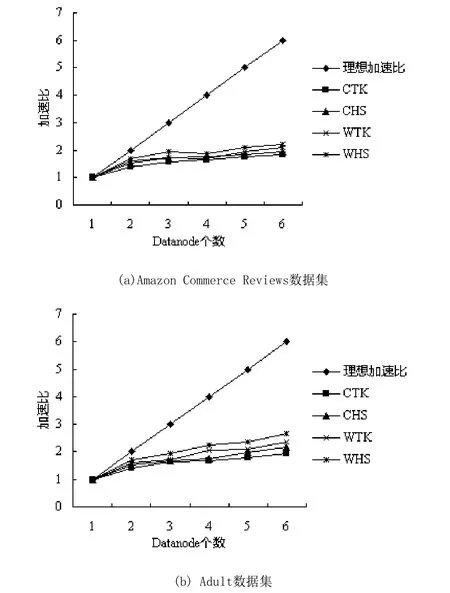
图1 MapReduce并行化分类算法加速比
由图1可以看出,WHS算法组合在两个数据集上均获得了最优加速比。在图1(a)中不同算法组合所得到的加速比差别不大,但在图1(b)中差别就比较明显,主要原因在于图1(b)的特征数量明显多于图1(a),且特征提取算法的优化使得特征数量逐渐增加,用于并行计算的开销占整体开销的比重也在增加,因此,加速比的增长量也就增加了。
同时,图1(b)的最优加速比优于图1(a)。因为图1(a)数据集小于图1(b)数据集,当数据集较小时,各个节点用于计算的时间较少,随着DataNode节点的增加,用于通信的时间开销所占的比重就会明显增加,而对于较大数据集,各个节点的计算时间较长,用于通信的时间开销所占的比重则相对较小。由此可见,该算法在规模较大的数据集上具有较好的加速比,因此在大规模数据的并行处理上更具优势。
4 结束语
云计算作为一种新型的大数据处理模型,为解决海量数据分类提供了新的解决途径。本文提出一种基于Hadoop平台的并行化数据分类算法,分别对特征提取、特征加权和特征分类3个关键环节的多种算法进行并行化计算,并通过对不同并行化算法组合的对比分析,验证了该算法的可行性和高效性,取得了较好的分类精度和加速比,达到了并行化处理大规模数据的目的。
[1]Hadoop[EB/OL].[2012-10-02]. http://hadoop.apache.org/index.heml
[2]Dean Jeffrey, Ghemawat Sanjay, MapReduce: a flexible data processing tool[J].Communications of the ACM,2010,53(1):72-77.
[3]Lin Jimmy,Dyer Chris, Data-Intensive Text Processing with MapReduce[M].2010.
[4]Amol Ghoting, Prabhanjan Kambadur, Edwin Pednault,et al, NIMBLE:An Infrastructure for the Rapid Implementation of Parallel Data Mining and Machine Learning Algorithms on MapReduce, San Diego,KDD,2011:334-342.
[5]Zhang Qi, Zhang Yue, Yu Haomin, et al, Efficient partialduplicate detection based on sequence matching[C]//Proceeding of the 33rd international ACM SIGIR conference on research and development in information retrieval, Geneva,2010:657-682.
[6]钱进,苗夺谦,张泽华.云计算环境下差别矩阵知识约简算法研究[J].计算机学报,2011,38(8):193-196.
[7]闫永刚,马廷淮,王建.KNN分类算法的MapReduce并行化实现[J].南京航空航天大学学报,2013,45(4):550-555.
[8]钱网伟.基于MapReduce的ID3决策树分类算法研究[J].计算机与现代化,2012,2:26-30.
[9]赵卫中,马慧芳,傅燕翔,等.基于云计算平台Hadoop的并行K-means 聚类算法设计研究[J].计算机科学,2011,38(10):166-168,176.
[10]江小平,李成华,等.云计算环境下朴素贝叶斯文本分类算法的实现[J].计算机应用,2011,31(9):2551-2554,2556.
