基于迭代算法的新词识别
2014-09-29赵小宝张华平
赵小宝,张华平
(北京理工大学计算机学院,北京 100081)
1 概述
词是最小的能够独立应用的有意义的语言成分[1],中文信息处理的特有问题即汉语分词,汉语分词是句法分析等深层处理的基础,也是机器翻译、信息检索和信息抽取等应用的重要环节[2],但随着语言的不断发展和进化,新词开始大量出现。特别是随着网络技术的高速发展,新词的产生变得更快更多,传播也变得更快更广,如“拼客”、“山寨”、“蚁族”、“裸婚”、“神马都是浮云”、“给力”、“屌丝”、“高富帅”等。如果在中文分词过程中不考虑这些新词,不实施新词发现,必然影响中文分词的质量。
与英语不同,中文词语与词语之间没有特定的分隔标记,任何相邻中文字符都可能构成一个词语;且书面语中没有字符形态变化,这都给中文新词自动检测带来了巨大障碍[3]。国内外大量科研院校和科研单位都相继开展了新词识别研究工作,并取得了一定的研究成果。在这些研究中,主要分为有监督和无监督的方法。大量研究实践表明,在没有大规模标注语料的情况下,使用无监督的方法获得候选新词具有对语料依赖程度小、适应能力强、新词识别效果好等特点,因此该方法也成为新词识别领域比较流行的研究方法。本文介绍新词发现研究的相关工作及衡量词语内聚性的特征,论述衡量词语外部灵活性的特征,提出一种左邻右平均熵和右邻左平均熵的计算方法。
2 相关工作
众多研究者从不同角度应用不同的方法进行了研究。利用递增的N-Gram模型提取重复模式,在此基础上使用手工编制的提取和过滤规则从互联网语料中提取新词[4]的方法,其主要思想是先统计所有二字串的频次,然后逐步统计三字串,四字串,五字串,……,记CRF录每一次扩展的字串以及对应频次,到达句末或者是字串长度达到阈值时停止扩展。该方法的优点是空间复杂度低,但时间复杂度较高。在此方法的基础上,使用正则表达式来表示过滤规则[5],可实现任意长度新词的检测。另一种新词检测方法是采用形式化描述模型在框架下判断是否是新词[6]。其训练和解码所选用的语言知识特征包括前缀、双字前缀、后缀、双字后缀、串长、命名实体后缀、候选模式的出现频率、互信息、色子系数和左、右熵等11项。结合LDCRF和semi-CRF的基于全局特征的判别模型[7]同样被用来进行新词识别和词性猜测。首先利用LDCRF识别新词候选,然后利用semi-CRF对新词候选的Nbest进行剪枝和过滤,得到新词。该方法加快训练速度,缩短了计算时间。以上2种方法的优点是无监督方式进行新词识别,不需要过多的人工干预,缺点是易受训练数据的影响,训练特征的选择导致了人工工作量的增加。在分词的过程中进行新词识别的方法[8]提出了一种快速的分词训练法——ADF,利用该方法得到的模型即使在多维特征的数据集上依然能够快速的进行分词和新词识别。针对专业领域的新词识别[9],第1步是构建专业领域词典,第2步是利用该词典寻找该专业的专家用户,最后从专家用户的输入内容中提取该领域的新词,该方法只能识别某一领域内的新词,构建专业领域词典需要人工参与,而且专家用户的选择会直接影响到新词识别的结果。另外还有一些研究者在位置成词概率的基础上,结合新词内部模式的特征,综合互信息、邻接类别等统计量对新词进行识别[10]。
本文针对以上方法的优缺点,考虑到词语的结构特性,把词语内部的凝聚程度(内聚度)和外部的灵活程度(灵活度)作为识别新词的特征,提出一种基于完全无监督的新词识别算法。该算法提出使用左邻右平均熵和右邻左平均熵作为表征词语外部灵活性的特征,新词发现的正确率得到一定程度的提升。
3 新词识别
3.1 基本设计理念
在自然语言处理过程中,词是最小的可以独立应用的语言单位。其中无监督的分词方法——ESA[11]综合了频率、长度、左(右)信息熵等特征计算字符串的IV(AB)值和2个子串连接在一起时的CV(AB)值,判定字符(串)AB是独立成词还是子串A和B分别成词,通过反复迭代,最终将一串字符进行粗切分,并利用局部最优化方法进行最优化,选出最优序列作为最终分词结果。新词作为词的有机组成部分,同样也会拥有词语的所有特性。在结构上,新词应该具有较高的内聚性和灵活性,这样才能满足独立应用的要求。
到目前为止,学术界对于新词的定义仍然没有达成共识。这里所说的新词指的是自动分词工具未能正常切分且可以独立表达完整意义的词。这些词或者是由已经存在的多字词组成(如:“中国特色社会主义”是由中国、特色、社会主义3个多字词组成),或者是由单字词组成(如:“高富帅”是由高、富、帅3个单字词组成,“白富美”是由白、富、美3个单字词组成)。从这些词的后验表现上看,这些新词都有一个共同的特点:出现频率高,内部结合紧密(内聚性高),上下文语境灵活(灵活性高)。假设一个字串在语料中反复出现(高于一定的频率阈值)、内部结合紧密(高于一定的内聚性特征阈值)、上下文语境灵活(高于一定的灵活性特征阈值),可以认定该字串是一个新词。即使该字串不是新词(某一灵活性特征未达到阈值,如:白富、富美),它仍有可能是某一新词的一个组成部分,可以反复迭代以解决类似问题。
综合上述思想,本文算法使用迭代方法,利用内聚性(共现频率、互信息)和灵活性(左熵、右熵、左邻接右平均熵、右邻接左平均熵)2个方面的6个特征对新词进行识别。
3.1.1 内聚性
新词作为一个有机的并且能够独立应用的有意义的语言成分,新词内部各元素之间必然存在高耦合度。内聚性作为词语的内部特征,有多种度量方法:共现频率,色子矩阵,互信息等,本文利用共现频率和互信息两种方法度量词语的内聚性。
互信息(Mutual Information,MI)是信息论里一种有用的信息度量,它是用来度量2个事件集合之间的相关性,假设S是长度为n的字符串,S=xy,其中,x,y为字符串S的2个子串,x=c1,c2,…,ck,y=ck+1,ck+2,…,cn,则x,y的互信息可由式(1)计算得到互信息:

其中,Pxy表示字符串S在待分析语料中出现的频率;Px表示子串x在待分析语料中出现的概率;Py表示子串y在待分析语料中出现的概率。
3.1.2 灵活性
作为一个独立的语言成分,新词应该比非独立的语言成分具有更灵活的应用场合。人们用熵来衡量对事物的不确定性,熵越大,表示人们对该事物认知的不确定性越大,对应的,该事物对于人们来说就具有很高的灵活性;反之,说明人们对该事物的认知是确定的,此时该事物对于人们来说是确定的,失去了灵活性。左(右)熵是度量人们对于新词左(右)邻接的不确定性,即新词的左(右)灵活性。左熵和右熵可以分别由式(2)、式(3)计算得到。受对偶原理的启发,若一个字符串是新词,其左邻接应该具有较高的右灵活性,同样的,其右邻接应该具有较高的左灵活性。进一步,该算法用左(右)邻接右(左)平均熵作为左(右)邻接右(左)灵活性的判定特征,可以分别由式(6)、式(7)计算得到。

3.2 算法流程
基于迭代算法的新词识别算法流程如图1所示,具体流程为:用中文自动分词工具对语料进行中文分词和词性标注;对分词后的结果进行词频统计,找出重复模式。统计过程中利用词性进行停用词过滤。该过程利用两遍扫描法进行词频统计,有效地提高了程序运行速度。第一遍扫描只统计单个词语的词频,将低于一定阈值的词加入到过滤词表(因为如果一个词的词频低于该阈值,则包含该词的字符串肯定不会大于该阈值),第二遍扫描时,只统计不以排除词表(过滤词表和词性过滤列表,其中词性过滤列表由人工添加)中的词作为子串的字符串;再次,找出重复模式,统计重复模式的左(右)邻接信息,计算重复模式的互信息、左(右)熵、左(右)邻接右(左)平均熵,利用这些特征信息进行新词识别,获得新词候选列表;最后,利用中文词语搭配库[12]对候选结果进行最后过滤,得到最终的新词列表。

图1 基于迭代算法的新词识别算法流程
3.3 新词识别过程描述
新词识别是一个层叠迭代的过程,如图2所示,其中实线表示算法流程,虚线表示迭代层级。该算法主要包括一个核心过程和2个子过程,首先介绍2个子过程。描述中常用符号说明见表1。
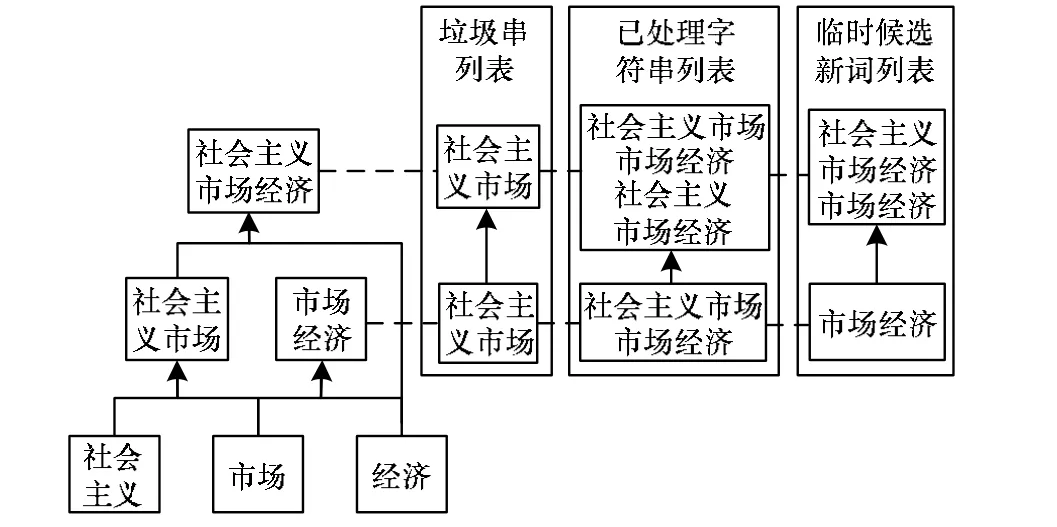
图2 新词识别过程示意图
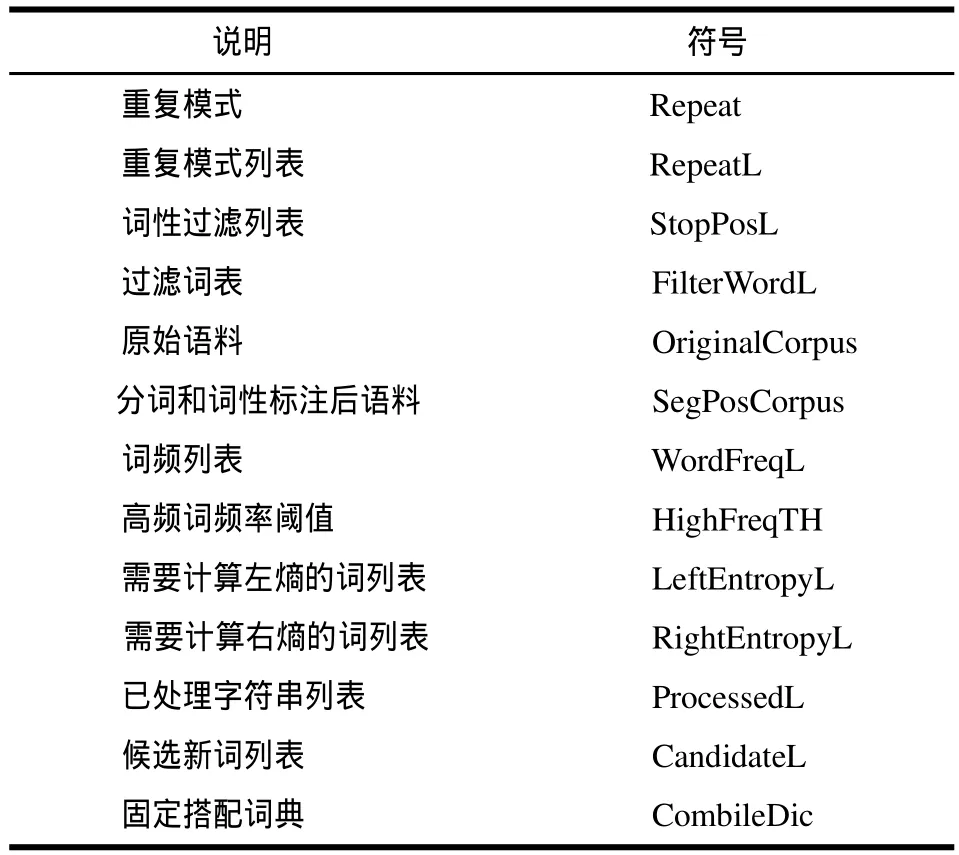
表1 符号说明
子过程1主要通过2次扫描获得重复模式列表:第1次扫描进行词频统计,根据设置阈值获得过滤词表,第2次扫描基于过滤词表和词性过滤列表获得重复模式列表。


假设语料中的用词个数为n,第1遍扫描的时间复杂度为O(n),空间复杂度为O(n)。如果重复模式平均由m个词构成,第2遍扫描的时间复杂度为O(nm),空间复杂度为O(n)。该子过程的时间复杂度为O(n+mn),该算法所占用的空间主要为O(n)。
子过程2是整个算法中的核心子过程,计算给定重复模式的内聚性和灵活性特征的值。

该过程是整个算法中时间复杂度和空间复杂度最高的部分。由式(1)、式(2)、式(3)、式(6)、式(7)计算5项特征的值,时间复杂度主要取决于后4项特征值的计算时间,假设平均每一个重复模式包含ml个左邻接和mr右邻接,每一个左邻接的平均右邻接个数为mlr,每一个右邻接的平均左邻接个数为mrl,则该过程的时间复杂度为O(mlmlr+mrmrl),空间复杂度为5个特征值的空间,即O(1)。
核心过程负责2个子过程的执行和判定重复模式是否为新词,是从原始语料识别新词、得到新词列表的过程。

该过程的时间和空间复杂度主要取决于子过程1和子过程2,假设总共有m个重复模式,时间复杂度为:O(mn+m×(mlmlr+mrmrl));空间复杂度为:O(n+m)。
4 实验结果及分析
4.1 实验环境
实验在普通的PC单机上进行,采用Windows操作系统,CPU为2.4 GHz×2,内存为3 GB,算法的实现代码采用C/C++语言实现。
4.2 测试对象的选取
实验主要分两部分进行,实验1取中国共产党第十八次全国代表大会报告(以下称十八大报告);实验2取北京大学提供的98年1月的《人民日报》手工标注语料(以下简称北大语料),手工标注后进行实验。表2为语料的详细说明。

表2 语料的详细说明
4.3 实验条件设置
实验均采用如下设置:MI0表示互信息大于0,作为基准实验(baseline),LE0表示左邻接熵大于0,RE0表示左邻接熵大于0,LRAE0表示左邻接右平均熵大于0,RLAE0表示右邻接左平均熵大于0,Filter表示经过中文词语搭配库过滤,NoFilter表示未经过中文词语搭配库过滤。
4.4 实验评测
在不同的条件下,新词列表按照互信息由高到低进行排序,取P@N作为实验结果的评测指标。
正确率计算公式:

其中,p表示正确率;Nq表示正确的新词个数;Nc表示新词总数。
4.5 实验结果与性能分析
表3为实验1中不同参数下的结果比较。实验结果显示,正确率均高于72%,利用互信息这一单一特征,N=100的正确率达到了72%,经过词语固定搭配的过滤,准确率提升到78%。经过全部5项特征的过滤,N=100的正确率达到83%,经过词语固定搭配词典的过滤,新词的正确率能够达到85%。
表4为实验2中不同参数下的结果比较。实验结果显示,正确率均高于76%,利用互信息这一单一特征,N=100的正确率达到了76%,经过词语固定搭配的过滤,准确率提升到78%。经过全部5项特征的过滤,N=100的正确率达到88%,经过词语固定搭配词典的过滤,新词的正确率能够达到90%。
图3、图4分别为实验1和实验2中的部分新词列表。
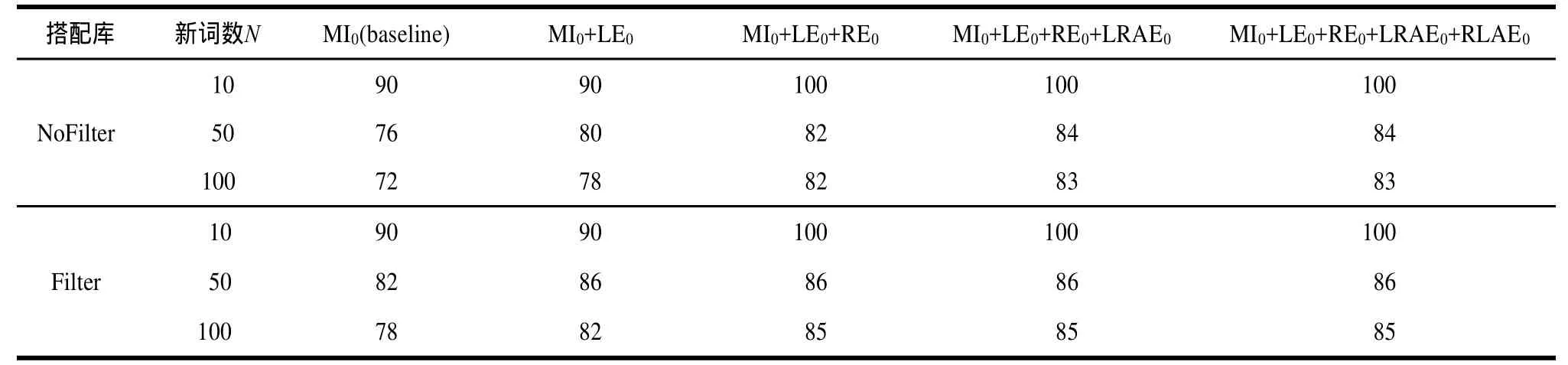
表3 实验1中不同参数下的结果比较%

表4 实验2中不同参数下的结果比较%

图3 实验1中部分新词列表

图4 实验2中部分新词列表
以上数据表明:N=10时,均有很高的正确率。随着N的增加,正确率有一定程度的下降是因为互信息是该算法的主要特征,互信息的变化对新词识别的准确率有直接的影响。随着特征的逐一加入,新词识别的正确数和正确率均呈现不断上升的趋势,证明各项特征均起到了提高正确率的效果。在同一实验条件下,固定词语搭配词典的过滤可以不同程度的提高正确率。当语料的规模较小时,新词发现的正确率略低,而语料规模较大时,新词发现的正确率会升高,这是因为该算法完全基于统计方法,语料规模的越大,各项统计信息越接近真实情况。另外,左邻接右平均熵和右邻接左平均熵可以在一定程度上提高新词识别的正确率,如果对新词识别的正确率要求不高,可酌情删除这2个特征,提高算法的执行效率。
另外从2个实验的执行时间来看,算法的执行效率不是很高,主要有以下3个方面的原因:
(1)共现频率阈值设置太小(为保证召回率),导致重复模式过多,计算量增加;
(2)灵活度的4个特征值,尤其是左(右)邻接右(左)平均熵计算复杂度过高;
(3)程序设计不尽合理,代码执行效率偏低。
5 结束语
本文基于迭代算法,提出了运用左(右)邻右(左)平均熵作为判断重复模式是否为新词的外部灵活度特征,采用内聚性和灵活度等6项特征判断重复模式是否为新词,通过十八大报告和北大语料的实验测试,结果表明,该算法能够有效提取新词。通过对2组实验进行对比分析发现,无论语料规模的大小,各项特征均起到提高正确率的效果。此外,语料规模对新词发现的正确率也有一定的影响。语料规模越大,新词发现的正确率就越高,这是因为该方法是基于统计的方法,数据量越大,统计数据的可靠性也越高,正确率也就越大,表明使用非监督的统计方法整合有效特征是一种非常有前途的新词识别研究方法。
下一步工作是充分挖掘有效的新词检测特征并将其放入统计框架中,以进一步改进新词检测效果与算法的执行效率,利用机器学习的方法学习各个特征的阈值,减少人工干预,以便将该方法整合到中文分词技术中,提高中文分词效果。
[1]朱德熙.语法讲义[M].北京:商务印书馆,2004.
[2]刘 群,张华平,俞鸿魁,等.基于层叠隐马模型的汉语词法分析[J].计算机研究与发展,2004,41(8):1421-1429.
[3]李 钝,屠 卫,石 磊,等.基于上下文感知的中文新词识别算法[J].计算机工程与设计,2012,33(10):4022-4027.
[4]郑家恒,李文花.基于构词法的网络新词自动识别初探[J].山西大学学报:自然科学版,2002,25(2):115-119.
[5]邹 刚,刘 群.面向Internet的中文新词语检测[J].中文信息学报,2004,18(6):1-9.
[6]张海军,栾 静,李 勇,等.基于统计学习框架的中文新词检查方法[J].计算机科学,2012,39(2):232-235.
[7]Sun Xiao,Huang Degen,Song Haiyu.Chinese New Word Identification:A Latent Discriminative Model with Global Features[J].Journal of Computer Science and Technology,2011,26(1):14-24.
[8]Sun Xu,Wang Houfeng,Li Wenjie.Association for Computational Linguistics[C]//Proc.of the 50th Annual Meeting of the Association for Computational Linguistics.[S.1.]:Association for Computational Linguistics,2012:123-128.
[9]Liu Zhiyuan,Zheng Yabin,Xie Lixing,et al.User Behaviors in Related Word Retrieval and New Word Detection:A Collaborative Perspective[J].ACM Transactions on Asian Language Information Processing,2011,10(4):20-27.
[10]林自芳,蒋秀凤.基于改进位置成词概率的新词识别[J].福州大学学报:自然科学版,2011,39(1):43-48.
[11]Wang Hanshi,Zhu Jian,Tang Shiping,et al.A New Unsupervised Approach to Word Segmentation[J].Computational Linguistics,2011,37(3):421-454.
[12]搜狗实验室.搜狗中文词语搭配库[EB/OL].(2009-01-20).http://www.sogou.com/labs/resources.htm.
