基于特征漂移的数据流集成分类方法*
2014-09-14张育培刘树慧
张育培,刘树慧
(郑州大学信息工程学院,河南 郑州 450052)
基于特征漂移的数据流集成分类方法*
张育培,刘树慧
(郑州大学信息工程学院,河南 郑州 450052)
为构建更加有效的隐含概念漂移数据流分类器,依据不同数据特征对分类关键程度不同的理论,提出基于特征漂移的数据流集成分类方法(ECFD)。首先,给出了特征漂移的概念及其与概念漂移的关系;然后,利用互信息理论提出一种适合数据流的无监督特征选择技术(UFF),从而析取关键特征子集以检测特征漂移;最后,选用具有概念漂移处理能力的基础分类算法,在关键特征子集上建立异构集成分类器,该方法展示了一种隐含概念漂移高维数据流分类的新思路。大量实验结果显示,尤其在高维数据流中,该方法在精度、运行速度及可扩展性方面都有较好的表现。
特征选择;特征漂移;概念漂移;数据流;互信息;集成分类器
1 引言
近年来,隐含概念漂移的数据流分类问题引起了人们重视,并得到广泛研究。文献[1,2]对数据流模型、存在的问题以及概念漂移定义做了详细描述,为研究工作提供充分有力的概念模型支持。数据流分类工作,尤其高速高维数据流,需应对“无限性”、“高速性”、“大数据量”和“概念漂移”。虽已有大量研究工作及成果,但仍然缺少有效处理概念漂移且高效的分类方法。
数据流分类工作大致分为两类:单个增量模型和自适应集成分类器。单个增量模型是通过维持和持续更新一个单分类器去应对数据流中的概念漂移[3],但学习速度慢且分类精度低,而且难以处理高速高维数据流。自适应集成分类器利用加权集成分类器在隐含概念漂移数据流分类中具有更高精度的特性[4],将概念漂移对分类结果的影响削弱在共同决策中[5,6],并利用最新或最有效分类器替换过时分类器[7]以确保分类器的先进性。然而以往集成分类器,大多基于完整数据而难以处理高维数据流且时间复杂度高。另外,特征选择技术是高维数据分类及文本分类领域的一个重要研究方向,能够有效缩减数据维度、提高分类精度并增强结果可理解性,主要可以分为滤波器法[8,9]、嵌入式法[10]及结合法。滤波器法快速简单但精度低而嵌入式法精确却复杂,故而产生了两者结合法。文献[11]提出基于特征选择的随机森林分类方法,文献[12]提出针对文本分类的DFS特征过滤算法,文献[13]提出基于支持向量机的特征选择和分类方法。但是,都没有考虑数据流特性因而不适于数据流分类。
本文首先描述了特征漂移概念及其与概念漂移的关系;然后提出无监督特征选择技术UFF(Unsupervised Feature Filter),利用相邻特征集的不同来判定特征漂移发生;最后选用具有概念漂移处理能力的概念自适应快速决策树CAFDT(Concept Adaptive Fast Decision Tree)和在线贝叶斯(OnlineNB)为基础算法,依选定的特征子集构建基础分类器,进而建立异构集成分类器,提出了基于特征漂移的数据流集成分类方法ECFD(Ensemble Classifier for Feature Drifting)。大量对比实验结果表明,ECFD具有较低复杂度,且在精度、运行速度及可扩展性上都有较强的表现。
2 相关概念及原理
2.1 问题描述
数据流是按时间顺序不断到来的数据序列,可形式化表示为:S={d1,d2,…,dn,…},其中di=[f1,f2,…,fp]是维度为p的数据点,而di所对应的已知类标号为c∈{c1,c2,…,ck}。数据流分类任务是根据先验事件构建模型M且di的类标号ci=M(di),使得S新到数据点di+1的分类概率P(M(dk+1)=ck+1)≥1/2。当维度p非常大时,可以选择最具有数据信息的特征子集CFS⊂{f1,f2,…,fp}来构建数据流分类模型M,从而降低时间复杂度。同时,若S中两段数据Sm和Sm+1具有不同的模型M,即MSm≠MSm+1,则利用MSm按时间顺序对Sm+1段的数据分类是不正确的,称此时发生概念漂移[2]。
2.2 概念定义

定义2(关键度)对工作窗口W中数据分类时,依特征fi划分之后,子集合的类别纯度越高说明fi越关键,因此可以用fi的信息熵来表示其关键度CD(Critical Degree),即CD=H(W|fi)。关键度达到阈值的特征,称为关键特征;未达到阈值的特征,称为噪特征。
定义3(关键特征集)对维度为p的数据流S分类时,从p个特征中选出对分类起关键作用的关键特征CF(Critical Feature),也即析取关键度相对较高的特征,组成关键特征集CFS(Critical Feature Set),即CFS⊂{f1,f2,…,fp}。
定义4(缓存窗口) 对工作窗口W的数据已经完成特征选择,但还未做分类,将此类数据暂存于缓存中以等待最终处理并交回数据流S,称这段缓存为缓存窗口(CW)。


定义7(特征分类器)选取具有概念漂移处理能力的基础分类算法,依特征数据集CSw建立分类器,称该分类器为特征分类器FC(Feature Classifier)。多个FC加权集成构成集成分类器,称为面向特征漂移的数据流集成分类器ECFD。
2.3 特征选择原理
利用特征选择技术可去除重复冗余的噪特征,降低分类时间复杂度。本文认为噪特征对CFS的依赖度要低于关键特征对CFS的依赖度,可由互信息准则[14]来表示,为此本文给出定理1。



□

2.4 特征漂移与概念漂移
数据流S中,使用i和i+1表示相邻工作窗口,若Wi和Wi+1的过程中发生特征漂移,也即特征选择得到的关键特征集而CFSi≠CFSi+1,则S在Wi和Wi+1之中发生概念漂移,为此本文给出定理2。
定理2数据流S中,特征漂移的发生必导致概念漂移的发生。
证明首先,S中数据段Wi+Wi+1发生特征漂移,因此由特征漂移定义知CFSi≠CFSi+1,即取得最关键特征top_crii({f1,f2,…,fp})≠top_crii+1({f1,f2,…,fp})。于是由定理1可知{I1,I2,…,Ip}i≠{I1,I2,…,Ip}i+1,而互信息值由关键度CD得到,所以{CD1,CD2,…,CDp}i≠{CD1,CD2,…,CDp}i+1。其次,机器学习建立数据模型是找到对训练数据拟合的模型M(f1,f2,…,fp),而建立的模型M必定对关键度大的数据特征具有偏置性,因此Mi≠Mi+1。再者,由文献[2]知,若相邻数据段是由不同模型产生,则在这两段数据中发生概念漂移。故特征漂移的发生必将导致概念漂移的发生。定理证毕。
□
反之,数据流S中,相邻数据段Wi和Wi+1分别由Mi和Mi+1产生且Mi≠Mi+1,则在数据段Wi+Wi+1中发生概念漂移,但是概念漂移的发生不一定会引起特征漂移的发生,为此本文给出定理3。
定理3数据流S中,多数发生概念漂移的情况会导致发生特征漂移。
证明设数据质心为G(f1,f2,…,fp),数据半径为R(f1,f2,…,fp)。数据段Wi+Wi+1中发生概念漂移,也即数据流S的数据分布发生改变[2]。而本文认为数据分布发生变化有两个原因:数据分布质心发生移动和数据分布半径发生变化。
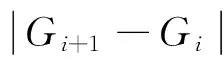
(3)Gi+1≠Gi且Ri+1≠Ri,某些数据特征的关键度必定发生了变化,数据整体质心分散。
因此,概念漂移发生时,数据特征CD不一定发生变化。据实验统计,实际中第(3)种混合情形占85%以上,故多数概念漂移会致使某些特征关键度变化,从而使CFS改变,引发特征漂移。故而多数概念漂移会引发特征漂移。定理证毕。
□
由定理2和定理3得知,特征漂移是概念漂移的充分条件,且现实中多数概念漂移引发特征漂移,因此本文提出以处理特征漂移替代处理概念漂移,由数据分布半径引起的概念漂移交给基础分类器去处理。由此可降低分类复杂度和运行时间,且可即时检测到大部分概念漂移,从而提高分类精度。
3 特征选择UFF和ECFD算法
3.1 特征选择技术UFF
由定理1可知,计算各数据特征与余下特征集的互信息值,其中互信息值较大者拥有更大的关键度,本文选取最大的num个特征为关键特征集。而互信息的计算需要对数据特征熵进行计算,本文采用文献[15]的熵估计法:
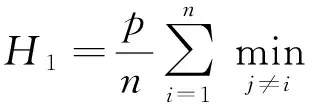
(1)
其中,tik表示数据点di和第k个近邻在一维子空间的欧几里得距离;lik为数据点di与第k个近邻在p-1维子空间的欧几里得距离。由定理1和公式(1),同时利用数据流“无限性”,通过已标记数据和已构造分类器验证精度确定关键特征的个数。本文提出特征选择算法UFF,如算法1所示。
算法1UFF算法
输入:数据集S,特征集F,已标记数据T和已构造分类器M,正随机小数∂。
输出:关键特征集CFS。
1: whileF≠null do
2: 利用公式(1)计算特征fi的UFFStr值并按从小到大放入数组UFFS;
3:endwhile
4:whileUFFS≠nulldo
5: num++;
6: 将UFFS中num_top_highest个特征作为关键特征集,利用T和M计算分类精度Pi;
8:CFS=num_top_highest-1;
9: end if
10: end while
为了处理数据流,本文将UFF算法使用于工作窗口中,以窗口数据为数据集S。当工作窗口数据点数目达到阈值时,便启动UFF算法进行特征选择,同时清空工作窗口W以继续接收数据流S的数据,将W中的数据交予缓存窗口CW等待最终处理。当相邻工作窗口得到的关键特征集不相同时,就断定此时有特征漂移发生。
3.2 ECFD算法
本文提出ECFD算法的目的是对隐含概念漂移的数据流进行分类,该方法从特征漂移入手,并利用特征选择技术析取关键特征集,构建特征集成分类器,从而降低时间和空间复杂度,且提高分类精度。ECFD算法流程包含四个步骤,如图1所示。

Figure 1 Algorithm of ECFD图1 ECFD算法流程示意图
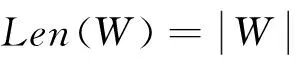
(2)判断是否有特征漂移发生。若CFSi=CFSi-1,则没有特征漂移发生,即特征漂移检测FD过程返回NO,此时需对具有CFSi的特征分类器特征漂移FC进行再学习,使FC提高分类精度且获取最近数据信息;若CFSi≠CFSi-1,则有特征漂移发生,即FD过程返回YES,此时需利用新得到的特征数据集CS训练新的特征分类器FCnew。
(3)特征集成分类器ECFD学习与实时更新。对特征分类器FC的再训练,本文采用文献[16]所提出的平均距离测试泊松分布方法得到Poisson(1)的值num,对特征数据集CS中的数据拟合训练Num次。而对于ECFD的更新,首先找出其中精度最高的和最差的特征分类器,利用新得到的CS训练,并选用与精度最高分类器同样的基础算法,得到新的FCnew,然后将FCnew替换掉最差FC。据定理2和定理3及以上分析,提出特征集成分类器ECFD的学习算法,如算法2所示。
算法2ECFD学习算法
输入:数据流S,集成分类器数目N,工作窗口尺寸Wl。
输出:ECFD集成分类器。
1: 以N*Wl个数据点初始化ECFD;
2: whileS≠null do
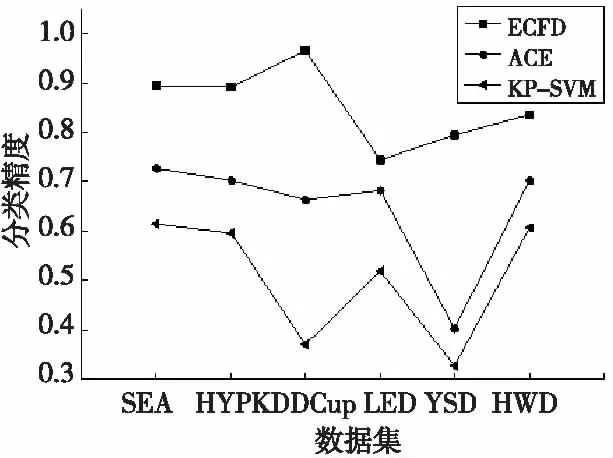
3: ifLen(W) 4: 将数据点d加入W; 5: else 6: 执行UFF得到FCSi及CSi; 7: ifCFSi≠CFSi+1then 8: 以CSi评估ECFD得出精度最高b-FC及其类型T和w-FC; 9: 以类型T和数据CSi训练新分类器n-FC; 10: 以n-FC替换w-FC; 11:else 12: 令num=Poisson(1)[16]; 13: 以CSi再训练ECFD中同特征FCnum次; 14: end if 15: end if 16: end while (4)利用加权投票对数据进行分类。由于ECFD进行了特征选择,故依文献[4]的集成分类器权值计算方法和本文特征度量值UFFStr的定义,提出如公式(2)所示的ECFD加权法。公式(2)以分类所用关键特征集中所有特征的特征度量值之和弥补特征选择带来的偏置性,从而使各分类对于所有数据特征相对公平;同时,使用文献[4]所提出的方法来区别各分类器权值比例。 (2) 算法3ECFD分类算法 输入:未分类数据点d。 输出:d的类标矩阵C=[c1c2…ck]及最大类标号。 1: 依据公式(2)计算ECFD中所有FC的权值w; 2: forFCi∈ECFD 3: ifFCi分类为Ctthen 4:ct=ct+wi 5: end if 6: end for 7: 返回向量C和类标号argmax(C); 3.3 算法性能分析及比较 3.3.1 算法时间复杂度 设v为属性值的最大个数,c为类别的最大个数,l为树最长的路径长度,p为数据流维度,k为ECFD中包含特征分类器的数目。由于分类算法与以往算法只是权值公式的不同,所以这里只对ECFD学习算法进行分析。初始化不计入持续学习时间,ECFD算法主要包含以下三个步骤。 因此,ECFD学习算法的时间复杂度为三者之和,合并转换后如公式(3)所示。 (3) 3.3.2 算法精度和抗噪性 ECFD算法主动处理概念漂移和过滤无用特征,从而减少不必要的算法运行和缩小分类器的规模,进而达到降低时间复杂度和增加分类精度的目的。 (1)概念漂移的检测与处理。ECFD方法采用先检测后处理的办法,且有特征漂移和概念漂移的双重检测,大大提高检测能力,从而提高分类精度,而目前多数方法是边训练边检测给分类器学习造成巨大负担且检测效果不佳。 (2)对信息的提取能力。ECFD算法采用UFF特征提取方法,有效地利用了数据流的特性,从而使得不再像其他大多数方法一样疲于应对数据流的特性。虽然特征提取丢弃了一些数据信息,但是同时也提高了ECFD算法的抗噪性,因为关键特征含有大量对分类有益的信息,而噪特征则含有大量的噪声信息。因而ECFD可以达到相对高的分类精度。 (3)分类策略。ECFD的分类策略采用加权投票方式,一定程度上矫正了权值的偏置性,对优良的特征分类器更为有利,具有更好的公平性,从而更有利凸出正确类别。 总之,从理论上ECFD可以达到相对高的分类精度,且具有更好的抗噪性。 为了对ECFD算法全面测试,首先对UFF特征选择与已有先进技术进行对比实验,然后对概念漂移检测能力进行检验并做对比,最后对算法整体性能进行测试对比。实验中,设置ECFD拥有10个特征分类器,工作窗口尺寸为1 000。运行环境为双核CPU主频2.27 GHz,内存2 GB,使用VS2010平台C++编程实现。 4.1 数据集描述 (1)人工数据集。便于与其他方法对比,本文依托MOA软件平台[18]分别使用仿真数据流产生器和移动超平面数据流产生器,产生含有突变概念漂移和缓慢概念漂移的数据集,大小为100 000,并分别记为SEA和HYP。 (2)真实数据集。为真实反映ECFD对网络数据实时动态处理情况,将入侵检测竞赛数据库KDDCup99模拟为数据流,大小为494 022;为了检测ECFD的抗噪性,选用UCI的LED数据集,大小为100 000;另外,通过雅虎Web服务接口采集的提供者与商家的雅虎购物数据库,记为数据集YSD,大小为840 000; http://www.csie.ntu.edu.tw/cjlin/libsvmtools/datasets手写识别数据集,记为HWD,大小为60 000。 4.2 结果与分析 4.2.1 特征选择 为了验证UFF算法的特征选择能力,分别在各数据集运行KP-SVM[13]与FCBF[9]各50次并计算平均结果,如表1所示。由于KP-SVM和UFF是具体的嵌入式方法,而FCBF是独立的过滤方法,所以FCBF要比KP-SVM和UFF高效。但是,从表1可以看到,KP-SVM和UFF得到的关键特征均数都要比FCBF要小,这是因为嵌入式特征选择要比过滤器方法对特征的评估更加有效。同时,表1显示了UFF具有与KP-SVM相当甚至更好的特征选择能力,但UFF利用了数据流的特性故而适合于对数据流的分类。关键特征选择结果说明,ECFD方法中特征选择UFF算法的有效性,能够去除冗余数据属性,且充分利用数据流的特性缩短了算法运行时间,更利于对高维数据流的处理,进而降低了分类器学习的时间复杂度。 Table 1 Critical feature selection 4.2.2 概念漂移 为了验证ECFD方法检测概念漂移的能力,与文献[19]所提出的PSCCD漂移检测算法进行对比,对所有数据集进行特征漂移检测50次,结果如表2所示。从表2可以看到,ECFD在ESEA、HYP和YSD数据集上误报次数高于PSCCD,是因为ECFD算法是通过检测特征漂移达到概念漂移检测的目的,由定理3也可以得知特征漂移检测并不能完全检测概念漂移,但是少部分非特征漂移的概念漂移由分类器处理。而表2中ECFD的失报次数要低于PSCCD,主要是因为ECFD算法是每个窗口都能进检测,而PSCCD算法是通过统计积累检测故而会大量失报持续时间短的概念漂移。从表2也可以看到,ECFD算法的概念漂移检测能力和PSCCD的相当,甚至更好,这是因为大多数概念漂移是由特征漂移引起的。总之,不论是人工数据集还是真实数据集,ECFD方法都能够有效地检测概念漂移,且分类结果证明失报率在可以接受的范围内。 Table 2 Dection of concept drifting 4.2.3 性能比较 (1)为了清楚地看到ECFD方法的有效性,在数据集上以先测试后训练最后再丢弃的顺序,分别与AWE(NB)[4]、AWE(C4.5)[4]、Bagging(NB)[17]和Bagging(CVFDT)[17]进行对比。将ECFD及AWE算法和Bagging算法在所有数据集上运行50次并计算平均结果,如表3所示。从表3中可以看出,除在KDDCup99数据集外,ECFD分类精度都高于其他算法,这是因为实际中多数概念漂移是由特征漂移引起的,ECFD准确地 检测特征漂移同时使用了具有概念漂移检测能力的算法构建特征分类器,所以有着比其他算法更好的概念漂移处理能力。而在KDDCup99数据集上也有着不错的精度,但不如Bagging(CVFDT),主要是由于ECFD方法使完整数据集转为特征数据集,因而缺少一定的训练维度造成的。另外,从表3还可以看出,除两个人工数据集外,ECFD方法运行时间也较其他方法快,维度越高越能体现其时间效率,这主要是因为ECFD使用UFF特征选择使得构建分类器更简单,说明ECFD方法更容易应对高维数据流。而在两个低维模拟数据集上,ECFD特征选择的时间相对构建分类器来说比较大,从而该方法时效性不如Bagging(NB)。总之,实验结果也充分证实了文中对算法分析的结论,不论是人工数据集还是真实数据集,ECFD方法都有较高的分类精度和时间效率。 (2)为了验证ECFD算法在特征选择之后数据流分类中的优势,与ACE集成分类算法[11]和KP-SVM分类算法[13]分别在各数据集上运行50次,同样ACE算法取10个分类器集成,结果如图2所示。 Figure 2 Result of kinds of dataset with concept drifting图2 含漂移各数据集 图2说明ECFD算法在各实验数据集上的分类精度均高于其他两者,而ACE算法的分类精度要高于KP-SVM,这主要是因为数据集中隐含有概念漂移,而ECFD主动处理概念漂移,ACE由于 Table 3 Algorithm comparison on precision and time 集成分类器而对概念漂移有一定应对能力,KP-SVM没有考虑概念漂移。但是,该实验还表明ECFD算法运行速度要低于其他两者,这是因为ECFD特征选择完之后需要去寻找合适的特征集数目。因此,ECFD可高精度处理隐含概念漂移的数据流分类。 (3)为了验证ECFD的抗噪性,本文选用HYP数据集和KDDCup99数据集分别加入5%、10%、15%、20%和25%的噪声数据,各算法分别运行50次并计算分类精度均值,如图3和图4所示。图3中随噪声数据的增多,ECFD分类精度下降约17%,而其他算法的下降都大于20%;同时,图4中随噪声数据的增多,ECFD分类精度下降约10%,而其他算法的下降都大于16%,且在噪声数据达到20%以及更高时,ECFD精度超过了Bagging(CVFDT)。实验表明,ECFD算法比其他算法具有更好的抗噪性,这是因为ECFD做了特征选择而使得噪特征的噪声对该算法没有大的影响。 Figure 3 Result of dataset HYP图3 HYP数据集 本文提出了一种基于特征漂移的数据流集成分类方法(ECFD),首先给出特征漂移的概念及其与概念漂移的关系,论证了可以通过检测特征漂移来检测概念漂移的原理;然后为应对数据流特性,利用互信息理论提出无监督特征选择UFF技术并检测概念漂移;最后提出了ECFD的学习算法,并根据改造后的权值计算方法给出ECFD分类算法。ECFD充分利用数据流的特性比较成功地解决数据流难题,且特征选择算法和基础分类算法是可选的,为隐含概念漂移的数据流分类展示了一个新思路。理论分析和实验结果都表明ECFD算法具有更高的分类精度和更好的抗噪性。但是,对该方法的研究才刚开始,对特征选择算法的稳定性及算法框架的完整性有待研究,这将是下一步的研究方向。 [1] Babcock B, Babu S, Datar M, et al. Models and issues in data stream systems [C]∥Proc of ACM PODS, 2002:16-24. [2] Tsymbal A. The problem of concept drift:Definitions and related work [R]. TCD-CS-2004-15. Ireland:Trinity College Dublin, Department of Computer Science, 2004. [3] Hulten G, Spencer L, Domingos P. Mining time-changing data streams [C]∥Proc of ACM SIGKDD, 2001:97-106. [4] Wang H, Fan W, YU P S, et al. Mining concept-drifting data streams using ensemble classifiers [C]∥Proc of the 9th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2003:226-235. [5] Masud M M, Gao J, Han J, et al. Classification and novel class detection in concept-drifting data streams under time constraints[J]. IEEE Transactions on Knowledge and Data Engineering, 2011, 23(6):859-874. [6] Zhang P, Zhu X, Tan Jian-long, et al. Classifier and cluster ensembles for mining concept drifting data streams [C]∥Proc of IEEE International Conference on Data Ming, 2010:1175-1180. [7] Sattar H, Ying Y, Zahra M, et al. Adapted one-vs-all decision tree for data stream classification [J]. IEEE Transactions on Knowledge and Data Engineering, 2009, 21(5):624-637. [8] Inza I, Larranaga P, Blanco R, et al. Filter versus wrapper gene selection approaches in DNA microarray domains[J]. Artificial Intelligence in Medicine, 2004, 31(2):91-103. [9] Lei Y, Huan L. Feature selection for high-dimensional data:A fast correlation-based filter solution[C]∥Proc of the 20th ICML’03, 2003:856-863. [10] Hsu W H. Genetic wrappers for feature selection in decision tree induction and variable ordering in Bayesian network structure learning[J]. Information Sciences, 2004, 163(1-3):103-122. [11] Tuv E, Borisov A, Runger G, et al. Feature selection with ensembles, artificial variables, and redundancy elimination[J].Journal of Machine Learning Research, 2009, 10:1341-1366. [12] Alper K U, Serkan G, A novel probabilistic feature selection method for text classification[J]. Knowledge-Based Systems,2012, 36:226-235. [13] Maldonado S, Webber R, Basak J. Simultaneous feature selection and classification using kernel-penalized support vector machines [J]. Information Sciences, 2011, 181(1):115-128. [14] Cover T M, Thomas J A. Elements of information theory[M]. New York:Wiley-Interscience, 1991. [15] Goria M, Leonenko N, Mergel V, et al.A new class of random vector entropy estimators and its applications in testing statistical hypotheses[J]. Journal of Nonparametric Statistics, 2005 17(3):277-297. [16] Gabor J S, Maria L R. Mean distance test of poisson distribution [J]. Statistics & Probability Letters, 2004, 67(3):241-247. [17] Breiman L. Bagging predictors [J]. The Journal of Machine Learning Research, 1996,24(2):123-140. [18] Bifet A, Holmes G, Kirkby R. MOA:Massive online analysis [J]. The Journal of Machine Learning Research, 2010,11:1601-1604. [19] Niloofar M,Sattar H,Ali H.A precise statistical approach for concept change detection in unlabeled data streams [J]. Computers and Mathematics with Applications, 2011, 62:1655-1669. ZHANGYu-pei,born in 1985,MS candidate,CCF member(E200027694G),his research interests include machine learning, and data mining. 2014中国计算机大会(CNCC2014)征文通知 第十一届CCF中国计算机大会(CCF China National Computer Congress,CCF CNCC 2014)将于2014年10月23~25日在河南郑州国际会展中心举行,承办单位是信息工程大学。CNCC是由中国计算机学会(CCF)于2003年创建的系列学术会议,已在不同的城市举办十届,现每年一次。 CNCC旨在探讨计算机及相关领域最新进展和宏观发展趋势,展示中国学术界、企业界最重要的学术、技术事件和成果,使不同领域的专业人士能够获得探讨交流的机会并获得所需信息。CNCC2014将有逾2000人参会交流,有近百项科研成果进行展示,是中国IT领域的一次盛会。 CNCC2014现公开征集会议论文,征文范围涵盖计算机领域各方向,要求是没有公开发表过的原创性论文。本次大会不出版会议论文集,拟挑选不超过50篇的优秀论文刊登在《计算机学报》上,其他录用论文将推荐到《小型微型计算机系统》、《计算机科学》、《计算机工程与应用》、《计算机工程与科学》等CCF会刊发表。《计算机学报》和《小型微型计算机系统》录用文章将在2014年10月发表。 征稿范围(但不限于) (1)计算机系统结构:高性能计算、CPU设计与多核处理器技术、 计算机网络与新一代互联网、 传感器网络和物联网、 物理信息融合系统、 对等计算与网格计算、 云计算与数据中心网络、 网络存储系统、 网络安全、 信息与内容安全。 (2)计算机软件与理论:计算机科学理论、 程序设计语言与编译技术、 软件测试、 形式化方法、 操作系统与系统软件、 数据库技术、 数据挖掘、 内容检索、 软件工程。 (3)计算机应用技术:人工智能与模式识别、 机器学习、 知识工程、 智能控制技术、 图形学与人机交互、 虚拟现实与可视化技术、 多媒体技术、 中文信息技术、 电子政务与电子商务、 生物信息学。 投稿方式 稿件内容要求以中文书写,并隐去作者姓名和单位,请提交PDF文件 论文模板:中文论文模板 大会网站:http://cncc.ccf.org.cn(请务必正确注册邮箱,并填写详细个人信息,包括联系电话以及通讯地址,以便联络论文修改和寄发录用通知等事宜,如信息不全,将会影响论文评审。) 联系:cncc_pr@ccf.org.cn(请在邮件标题中注明“CNCC2014征文”) 重要日期 论文提交截止日期:2014年5月10日 录用通知发出日期:2014年8月1日 CNCC召开日期:2014年10月23日~25日 Ensembleclassificationbasedonfeaturedriftingindatastreams ZHANG Yu-pei,LIU Shu-hui (School of Information Engineering,Zhengzhou University,Zhengzhou 450052,China) In order to construct an effective classifier for data streams with concept drifting,according to the theory that different data feature has different critical degree for classification,a method of Ensemble Classifier for Feature Drifting in data streams (ECFD) is proposed. Firstly,the definite of feature drifting and the relationship between feature drifting and concept drifting is given.Secondly,mutual information theory is used to propose an Unsupervised Feature Filter (UFF) technique,so that critical feature subsets are extracted to detect feature drifting.Finally, the basic classified algorithms with the capability of handling concept drifting is chosen to construct heterogeneous ensemble classifier on the basis of critical feature subsets. This method exhibits a new idea of way to high-dimensional data streams with hidden concept drifting.Experimental results show that the method has strong appearance in accuracy, speed and scalability, especially for high-dimensional data streams. feature selection;feature drifting;concept drifting;data stream;mutual information;ensemble classifier 1007-130X(2014)05-0977-09 2012-12-17; :2013-02-18 TP274 :A 10.3969/j.issn.1007-130X.2014.05.032 张育培(1985-),男,河南嵩县人,硕士生,CCF会员(E200027694G),研究方向为机器学习与数据挖掘。E-mail:zzuiezhyp@163.com 通信地址:450052 河南省郑州市大学路75号郑州大学信息工程学院 Address:School of Information Engineering,Zhengzhou University,75 Daxue Rd,Zhengzhou 450052,Henan,P.R.China
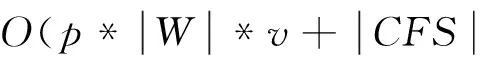
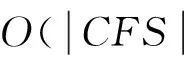

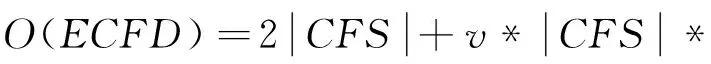


4 实验分析



5 结束语

