基于CUDA的图像预处理并行化研究
2014-09-06,,,
, ,,
(哈尔滨工业大学机器人技术与系统国家重点实验室,黑龙江 哈尔滨 150001)
基于CUDA的图像预处理并行化研究
占正锋,李戈,张学贺,尹旭悦
(哈尔滨工业大学机器人技术与系统国家重点实验室,黑龙江 哈尔滨 150001)
为加快图像预处理算法的执行速度,提出了基于计算统一设备架构(CUDA)的预处理算法来实现高速并行处理。分析了图像灰度化、高斯滤波以及直方图均衡化等预处理方法的原理,并对它们进行并行化分析,从而将CUDA并行计算技术引入到图像预处理算法。实验结果表明,此算法充分利用GPU的并行处理能力,与CPU串行处理方法相比,速度提高明显,有效提高数据处理能力。
图像预处理;CUDA;并行处理
0 引言
一般情况下,成像系统获取的图像(即原始图像)由于受到种种条件限制和随机干扰,往往不能在视觉系统中直接使用,必须在视觉信息处理的早期阶段对原始图像进行灰度变换、噪声过滤等图像预处理[1]。传统的预处理算法,当数据量较大时,这种方法的效率不高,难以满足实时性的要求。近年来,基于图像处理器(GPU)的大规模通用并行计算,为图像处理算法的高效分析计算提供了可能。NVIDIA公司提出的计算统一设备构架,是一种将GPU作为数据并行计算设备的软硬件体系,其特点是将CPU作为主机,GPU作为协处理器[2]。这个模型中,CPU和GPU协同工作,CPU负责逻辑性强的事务和串行计算任务,而GPU处理高度线程化的并行计算任务[3]。
在此,以GPU作为计算平台,对图像预处理算法中的图像灰度化、高斯滤波以及直方图均衡化处理进行并行化分析,并在CUDA上实现。
1 图像的灰度化并行
将彩色图像转化成为灰度图像的过程称为图像的灰度化处理。彩色图像中的每个像素的颜色由R,G,B3个分量决定,而每个分量有255种值可取,这样一个像素点可以有1 600多万(255×255×255)种颜色的变化范围。而灰度图像是R,G,B3个分量相同的一种特殊的彩色图像,其一个像素点的变化范围为255种,所以在数字图像处理中,一般先将各种格式的图像转变成灰度图像,以使后续图像的计算量变得少一些。图像的灰度化处理,一般而言,常用如下几种方法:最大值法、平均法和加权平均法等[4]。这里采用加权平均法,分别赋予R,G,B不同的权值,然后取其加权后的平均值作为最后的灰度值。
并行灰度转换实现过程中,将每个像素3个通道的颜色值存放在线程寄存器内,1个block包含256个thread,则对于一幅尺寸为width × height的图像,一共需要width × height/256个block,创建索引标号为index=blockIdx.x×256+threadIdx.x。
2 高斯滤波并行化
高斯滤波(高斯平滑)是数字图像处理和计算机视觉里面最常见的操作。高斯滤波器是根据高斯函数的形状来选择权值的线性平滑滤波器[5]。高斯平滑滤波器对去除服从正态分布的噪声有很好的效果。对图像来说,常用二维高斯函数表达式为:

(1)
σ为高斯滤波器的宽度。
高斯滤波时,在对整幅图像进行加权平均的过程中,每一个像素点的值,都由其本身和邻域内的其他像素值经过加权平均后得到。高斯滤波的具体操作是:用1个模板(或称卷积、掩模)扫描图像中的每一个像素,用模板确定的邻域内像素的加权平均灰度值,去替代模板中心像素点的值。
为了实现高斯滤波的快速运行,根据高斯函数具有可分离性的特点,提出了可进行分离的高斯卷积的方法,把二维高斯卷积转换成2个一维高斯卷积,将高斯模板放入GPU带缓存的常量存储器中。
由高斯函数的性质可知,高斯函数具有各向同性的特点,二维高斯函数可进行逐次卷积,一个沿水平方向,另一个沿垂直方向。即
(2)
在离散系统中,二维高斯卷积是靠n×n的高斯模板对整幅图像进行卷积的,每个图像的像素都需要进行n×n次的乘加操作,对于大小为m×m的图像就需要m×m×n×n次乘加操作,同时还要用n×n个存储空间来存储模板。而将二维高斯函数进行分离以后,把二维的n×n高斯模板分解成1 ×n的一维高斯模板,对图像先进行行卷积再进行列卷积,对于大小为m×m的图像一共只需要2 ×m×n×n次操作。可以看出,当图像很大时,使用本文的方法进行高斯卷积将提升运算速度。以5×5的二维高斯模板为例,如图1所示。将其分解后对应的一维高斯模板如图2所示。图1所示的5×5二维高斯模板可分解为图2的1×5一维模板和其转置的乘积,这样就将二维高斯平滑转换成了2次的一维高斯平滑。
在GPU上对高斯卷积进行并行化的主要流程如图3所示。
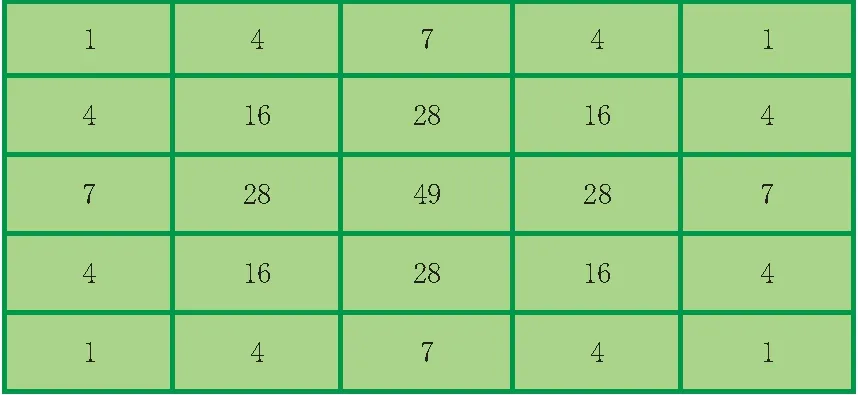
图1 5×5高斯模板

图2 1×5一维高斯模板
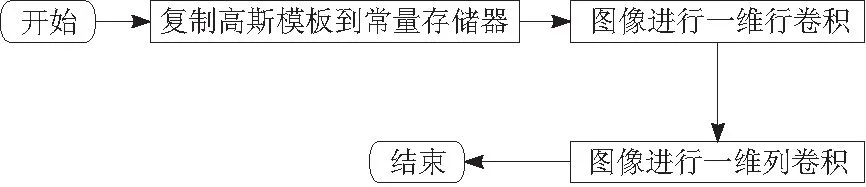
图3 GPU高斯卷积流程
首先将图像从主机端拷入到设备端,绑定纹理内存。选择绑定纹理内存是由于以下原因:纹理内存缓存在芯片上,能够减少对内存的请求并提供更高效的内存带宽,是专门为那些在内存访问模式中存在大量空间局部性的图形应用程序而设计的,能在随机存取的环境中,保持较高的性能;图像在高斯滤波时要面临边界问题,而图像处理器程序并不擅长条件判断语句的执行,纹理内存能够通过属性设置,比较高效处理此类问题。
高斯卷积模板在主机端计算完毕后,传入设备端的常量存储器。在行列2个维度上使用2个kernel函数进行卷积。对行维度卷积时,将Grid中的block按照二维地址排序,每个block负责处理1幅图像的1行的部分数据,大小可以定为16×16,即每个block有256个thread,每个thread负责处理图像的1个像素点的值,即每个线程把当前的像素点和其周围的8个像素点进行加权计算。同一个block中的线程在进行计算时,有很多数据是重复的,将它们放在block的共享存储器中,这样就可以加快运算速度。行卷积任务分配如图4所示。对列的卷积与行卷积类似,这样完成行列卷积后,就可以完成对整幅图像的高斯二维卷积。

图4 行卷积任务分配
3 直方图均衡化技术并行化
利用直方图统计的结果,通过使图像直方图均衡的方法称为直方图均衡化[6]。直方图均衡化处理是数字图像处理中增强图像的一种重要的方法。
灰度直方图的计算十分简单,依据定义,在离散形式下有以下公式成立:
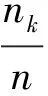
(3)
nk为图像中出现Sk级灰度的像素数;n为图像像素总数;nk/n为频数。
计算累积直方图各项:
(4)
取整扩展:
tk=int[(L-1)tk+0.5]
(5)
映射对应关系:
k⟹tk
在CUDA上实现直方图的均衡化需要进行原子操作,而使用原子操作的方式是调用函数atomicAdd(addr,y)生成1个原子的操作序列。这个操作序列包括读取地址addr处的地址,将y增加到这个值,以及将结果保存回地址addr。底层硬件将确保当执行这些操作时,其他任何线程都不会读取或写入地址addr上的值,这样就能确保得到预计的结果。
将直方图的计算分为2个阶段。在第1阶段中,每个并行线程块将计算它所处理数据的直方图。由于每个线程块在执行这个操作时都是相互独立的,因此,可以在共享内存中计算这些直方图,这将避免每次将写入操作从芯片发送到DRAM。因为在线程块中的多个线程之间会处理相同值的数据元素,所以需要原子操作。在第1阶段中,给每个block分配256个thread,同时分配1个共享内存缓存区并进行初始化,用来保存每个线程块的临时直方图,即_shared_ unsigned int temp[256];temp[threadIdx.x]=0。由于随后的步骤将包括读取和修改这个缓冲区,因此,需要调用_syncthreads(),来确保每个线程的写入操作在线程继续前进之前完成。
在第2阶段,要求将每个线程块的临时直方图合并到全局缓冲区histo中。假设将输入数据分为两半,这样就有2个线程查看不同部分的数据,并计算得到2个独立的直方图。如果线程A在输入数据中发现字节0xFC出现了20次,线程B发现字节0xFC出现了5次,那么字节0xFC在输入数据中共出现了25次。同样,最终直方图的每个元素,只是线程A直方图中相应元素和线程B直方图中相应元素的加和。这个逻辑可以扩展到任意数量的线程,因此,将每个线程块的直方图合并为单个最终的直方图,就是将线程块直方图的每个元素都相加到最终直方图相应位置的元素上。这个操作需要自动完成,即atomicAdd(&(histo[threadIdx.x]),temp[threadIdx.x])。由于使用了256个线程,并且直方图中包含了256个元素,因此,每个线程将自动把它计算得到的元素只增加到最终直方图的元素上。本算法并不保证线程块将按照何种顺序将各自的值相加到最终的直方图中,但由于整数加法是可以交换的,无论哪种顺序都会得到相同的结果。
4 实验分析
实验平台采用Windows 7操作系统,CPU为Intel Core i7-3770,主频3.40 GHz,系统内存为8 GB;GPU为GeForce GTX 570。
4.1 图像灰度化
分别使用图形尺寸为256×256,512×512,1 024×1 024的图像,在GPU上测试其运行速度,并且与预处理算法在CPU上运行的速度进行比较。实验效果如图5和表1所示。

图5 灰度化效果
表1 灰度化在GPU和CPU上运行时间的比较

图像大小CPU/msGPU/ms加速比(CPU/GPU)256×2560.0930.0283.26512×5120.1870.0355.311024×10240.4360.0449.87
4.2 高斯滤波
对平滑尺度为1,模板尺寸为5×5的高斯滤波算法在GPU上进行实验,分别使用图形尺寸为256 ×256,512×512,1 024×1 024的加椒盐噪声的图像,在GPU上测试其运行速度,并且与该算法在CPU上运行的速度进行比较。实验效果如图6和表2所示。

图6 高斯滤波效果
表2 高斯滤波在GPU和CPU上运行时间的比较

图像大小CPU/msGPU/ms加速比(CPU/GPU)256×2560.7560.04915.21512×5122.3590.08228.631024×10246.7850.18536.65
4.3 直方图均衡化处理
分别使用图形尺寸为256×256,512×512,1 024×1 024的图像,在GPU上测试其运行速度,并且与该算法在CPU上运行的速度进行比较。实验效果如表3和图7所示。
表3 均衡化在GPU和CPU上的运行时间的比较

图像大小CPU/msGPU/ms加速比(CPU/GPU)256×2560.1240.0158.23512×5120.3870.02515.721024×10240.8360.03324.96

图7 直方图均衡化效果
4.4 实验结果分析
由表1~表3可以看出,图像预处理算法在GPU上运行的速度明显高于在CPU上的速度,并且从图像灰度化、直方图均衡化以及高斯滤波这3种算法的对比来看,算法越复杂、并行程度越高和图像的分辨率越高,这种加速效果会越明显。
5 结束语
对传统的图像预处理算法中的图像灰度化、高斯滤波以及直方图均衡化处理进行了并行化分析,并且使其在CUDA上实现。实验结果表明,预处理算法在GPU上运行与其在CPU上运行相比,明显提高了其运算速度。
[1] 颜 瑞.基于 CUDA 的立体匹配及去隔行算法[D].杭州:浙江大学,2010.
[2] 邹治海.GPU 架构分析与功耗模型研究[D].上海:上海交通大学,2011.
[3] 张 舒,褚艳利.GPU高性能运算之CUDA[M].北京:中国水利水电出版社,2009.
[4] Sanders J, Kandrot E.CUDA by example:an introduction to general-purpose GPU programming[M].Addison-Wesley Educational Publishers Inc,2010.
[5] 郭陆峰.双目视觉系统关键技术研究[D].泉州:华侨大学,2007.
[6] Oon-Ee Ng,Ganapathy V.A novel modular framework for stereo vision[C]∥IEEE/ASME International Conference on Advanced Intelligent Mechatronics,2009:857-862.
Parallel Study of Image Preprocessing Based on CUDA
ZHANZhengfeng,LIGe,ZHANGXuehe,YINXuyue
(State Key Laboratory of Robotics and System,Harbin Institute of Technology,Harbin 150001,China)
To speed up the execution speed of image preprocessing algorithm,the paper proposes preprocessing algorithm base on Compute Unified Device Architecture (CUDA) to achieve high-speed parallel processing.It analyzes the principle of image gray,Gaussian filtering and histogram equalization preprocessing methods,and does parallel analysis,and then puts CUDA parallel computing technology into the image preprocessing algorithm. Experimental results show that the image preprocessing algorithm based on CUDA takes full advantage of parallel processing capabilities of GPU,compared with CPU serial processing method,significantly faster,improve data processing capability.
image preprocessing;CUDA;parallel processing
2014-03-10
机器人技术与系统国家重点实验室(哈尔滨工业大学)自主研究课题(SKLRS201302C)
TP301.6;TP391
A
1001-2257(2014)07-0064-04
占正锋(1990-),男,福建福安人,硕士研究生,研究方向为机器人视觉。
