基于决策树算法的银行客户分类模型*
2014-09-06尹鹏飞
尹鹏飞,欧 云
(1.中南大学信息科学与工程学院,湖南 长沙 410000,2.吉首大学信息科学与工程学院,湖南 吉首 416000)
基于决策树算法的银行客户分类模型*
尹鹏飞1,2,欧 云2
(1.中南大学信息科学与工程学院,湖南 长沙 410000,2.吉首大学信息科学与工程学院,湖南 吉首 416000)
利用决策树算法对银行的信用卡客户进行分类,构建了客户分类模型,给出了分类步骤中信用卡的客户类型特征,为银行的信用卡推广业务提供相应策略.
数据挖掘;决策树;剪枝;客户分类
从商业角度看,数据挖掘[1-2]是一种深层次的商业信息分析技术.按照企业既定业务目标,数据挖掘能对大量的企业数据进行探索和分析,揭示隐藏的、未知的或验证已知的规律性并进一步将其模型化,从而自动提取出用以辅助商业决策的相关商业模式.对于银行来说,一个新客户的到来,银行应该针对客户的信息,判断客户可能的类别,然后采用针对性较强的销售策略,以获得最高的效益.采用决策树,借助计算机对客户数据进行挖掘,并进行客观地分类分析,是一种科学且快捷的方法.在商业银行中,利用数据挖掘对客户进行分类,会发现申请或不申请信用卡的客户类型特征,从而为银行的信用卡推广业务制定相应策略,降低风险,提高利润.笔者研究了利用决策树算法对银行客户进行分类的方法.
1 决策树算法
决策树采用样本的属性作为节点,属性的取值作为分支,利用信息论原理对大量样本的属性进行分析和归纳.决策树的根节点是所有样本中信息量最大的属性,中间节点是以该节点为根的子树所包含的样本子集中信息量最大的属性,叶节点是样本的类别值.
1.1决策树生成算法
该算法构造的结果是一棵二叉或多叉树:二叉树的内部结点(非叶子结点)一般表示为一个逻辑判断,树的边是逻辑判断的分支结果;多叉树的内部结点是属性,边是该属性的所有取值,有几个属性值就有几条边.
构造决策树的方法通常采用自上而下的递归构造,其基本思路如下:
(ⅰ)以代表训练样本的单个结点开始建树.
(ⅱ)若样本都在同一个类,则该结点成为树叶,并用该类标记.
(ⅲ)否则,算法使用信息增益的基于熵的度量为启发信息,选择能够最好地将样本分类的属性,该属性成为该结点的“测试”或“判定”属性.
(ⅳ)对测试属性的每个已知的值创建一个分支,并据此划分样本.
(ⅴ)使用同样的过程,递归地形成每个划分上的样本决策树,一旦一个属性出现在一个结点上,就不必考虑该结点的任何后代.
(ⅵ)递归划分每个步骤,当下列条件之一成立时停止划分:(1) 给定结点的所有样本属于同一类;(2) 若没有剩余属性可以用来进一步划分样本,则采用多数表决;(3) 在分支test_attribute=ai没有样本时,以样本中的多数类创建一个树叶.
1.2ID3算法
ID3定义如下:(1)决策树中每个非叶结点对应着一个非类别属性,树枝代表这个属性的值,一个叶结点代表从树根到叶结点之间的路径对应的记录所属的类别属性值;(2)每个非叶结点都与属性中具有最大信息量的非类别属性相关联;(3)采用信息增益来选择能够最好地将样本分类的属性.
由此可知,ID3算法总是选择具有最高信息增益(或最大熵压缩)的属性作为当前结点的测试属性.设S是s个数据样本的集合.假定类标号属性具有m个不同值,定义m个不同类Ci(其中i=1,2,…,m),设si是类Ci中的样本数.对一个给定的样本分类所需的期望信息为
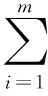
(1)
其中任意样本属于Ci的概率pi=si/s.
设属性A具有v个不同值a1,a2,…,aj,av,用属性A将S划分为v个子集{s1,s2,…,sj,sv},其中sj包含S中样本,且在A上具有值aj.若A作为测试属性,则这些子集对应于由包含集合S的结点生长出来的分支.设sij是子集Sj中类Ci的样本数,则由A划分成子集的熵为
(2)
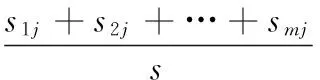
Gain(A)=I(s1,s2,…,sm)-E(A).
由ID3算法计算每个属性的信息增益,并选取具有最高增益的属性作为给定集合S的测试属性.对被选取的测试属性创建一个结点,并以该属性标记,对该属性的每个值创建一个分支,据此划分样本.
1.3C4.5算法
C4.5算法[3]是从ID3算法演变而来,除了拥有ID3算法的功能外,C4.5算法引入了新的方法并增加了新的功能.例如:(1)提出了信息增益比例的概念;(2)合并具有连续属性的值;(3)可以处理具有缺少属性值的训练样本;(4)通过使用不同的修剪技术以避免树过度拟合;(5)k交叉验证;(6)规则的产生方式.

1.4决策树剪枝
决策树的剪枝[4]通过一些度量减去不可靠的分支,以防止过分适应数据产生,剪枝可以分为先剪枝和后剪枝.先剪枝通过提前停止树的构造而对树剪枝,一旦停止,节点就成为叶节点;后剪枝是对完全生长的树减去分支.在决策树剪枝中,可以采用不同度量来评价分支的有效性,从而来决定是否剪枝.
2 客户分类模型
银行客户可以分为信用卡客户和非信用卡客户.通过分析客户的基本信息,利用数据挖掘方法可以获得每类客户的公共特征,保证信用卡推销中做到有的放矢,提高成功率.
文中讨论的客户分类模型[5]主要是针对信用卡客户类型,通过对银行信用卡客户的一批样本数据,采用决策树C4.5算法对其进行训练,提取客户的公共特征,获得1组分类规则,利用该组分类规则就可以对新客户进行分类判断,这样可以有针对性地开展信用卡销售业务,节省成本.
2.1样本数据
文中采用了350条银行客户信息,其中使用300条记录作为训练样本来构造决策分类树,提取相应的分类规则,用剩下的50条记录对得到的决策树模型进行测试,验证决策树的分类效果.
笔者利用的训练和测试数据是经过预处理后的数据,含有9个字段属性,分别为年龄、性别、所在地区、年收入、婚否、是否有小孩、是否有汽车、是否抵押贷款、是否信用卡客户.其中:年龄属性为整型值,记录客户的年龄值;性别属性为二值属性,取值为男(MALE)、女(FEMALE);所在地区属性为类别属性,这里用的是经过预处理后的值,取值分别为城市(CITY)、城市郊区(SUBURBAN)、农村(RURAL)、乡镇(TOWN);年收入为数值型,记录客户的年收入信息,本字段数据没有进行离散化处理;婚否属性为二值属性,取值为已婚(YES)、未婚(NO);是否有小孩属性为二值属性,这里的数据取值为经过了预处理的数据,分别取值为有小孩(YES)、无小孩(NO);是否有汽车属性也为二值属性,取值为有汽车(YES)、无汽车属性(NO);是否抵押贷款属性为二值属性,取值为有抵押贷款(YES)、无抵押贷款(NO),文中用到的数据也是经过预处理后的数据;是否信用卡客户属性也为二值属性,取值为信用卡客户(YES)、非信用卡客户(NO),在训练样本中,这个属性的取值是有真实值的,而在测试数据集中,这个值是需要进行预测的,所以用“?”替代了它的真实值.通过对训练样本采用C4.5算法来构造1棵决策树,然后利用构造的决策树对测试数据中的信用卡客户属性值进行预测.
部分原始的训练样本和测试数据格式如表1,2所示.其中:C代表是否有小孩;A代表是否有汽车;M代表是否抵押贷款;CC代表信用卡客户;F代表女;M代表男;Y代表YES;N代表NO.

表1 训练样本数据

表2 测试数据
2.2分类训练流程
文中采用开源的数据挖掘工具weka进行实验.首先,将实验的数据转换成weka定义的文本格式;然后,将转换后的文本数据作为数据源输入到weka中.采用C4.5算法对客户数据进行分类训练流程如下:
(ⅰ)读取数据集名称及内容.
(ⅱ)读取由@attribute所标记的属性字段名称及每个字段的取值类型.
(ⅲ)对离散型数据与连续型数据分别用相应的数据结构存放.
(ⅳ)读取由@data所标识的区域的样本数据:(1)以增量方式读取每个样本;(2)对样本的每个属性进行合法性检查(主要检查属性值是否符合所定义数据类型);(3)将所有的样本存储在一个表中,每行代表一个样本.
(ⅴ)利用数据集构建树:(1)基本算法与ID3相同,利用其他附属功能计算增益;(2)递归调用程序构建子树,直至所有的样本分类完毕;(3)根据设置的参数进行树的剪枝操作.
(ⅵ)从树中抽取规则RULES:(1)所有的叶存储在一个列表中,每个结点存储指向父结点的指针;(2)利用叶列表及指向父结点的指针生成规则表(下一步的分类都以抽取的规则为基础).
(ⅶ)测试生成的树:每个训练k-树都对应着一个k-集,每个树都产生对训练集及测试集分类的规则:(1)产生分类错误的计数;(2)分别对训练数据及测试数据的错误进行计算.
(ⅷ)计算所有k-树上的结果的平均值,预测最终结果.
2.3实验结果与分析
由300条样本数据构造一棵叶子节点为17个、总节点为31的决策树,采用剪枝操作,剪枝比例设置为25%,k交叉验证中的k设置为10.分类结果表明,分类正确的样本数为268个,占总样本数的89.3%,分类错误的样本数为32个,占总样本数的11.7%.实验详细结果见表3.
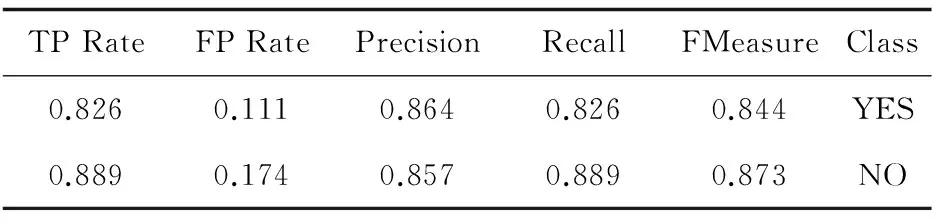
表3 实验详细结果
文中构建的决策树如下所示:
children=YES
income<=30099.3
car=YES:NO (50.0/15.0)
car=NO
married=YES
income<=13106.6:NO (9.0/2.0)
income>13106.6
mortgage=YES:YES (12.0/3.0)
mortgage=NO
income<=18923:YES (9.0/3.0)
income>18923:NO (10.0/3.0)
married=NO:NO (22.0/6.0)
income>30099.3:YES (59.0/7.0)
children=NO
married=YES
mortgage=YES
region=CITY
income<=39547.8:YES (12.0/3.0)
income>39547.8:NO (4.0)
region=RURAL:NO (3.0/1.0)
region=TOWN:NO (9.0/2.0)
region=SUBURBAN:NO (4.0/1.0)
mortgage=NO:NO (57.0/9.0)
married=NO
mortgage=YES
age<=39
age<=28:NO (4.0)
age>28:YES (5.0/1.0)
age>39:NO (11.0)
mortgage=NO:YES (20.0/1.0)
构建好决策树后,利用50条数据对决策树进行测试.测试结果如下:分类正确的样本数为44个,占整个测试样本的88%;分类错误的样本数为6个,占整个测试样本的12%.
最后,根据决策树抽取17条规则,部分规则描述如下:
(1)IF Children=yes and Income>30099.3 THEN CreditCard=YES;
(2)IF Children=yes and Income<=30099.3 and Car=YES THEN CreditCard=YES;
(3)IF Children=No and Married=No and Mortgage=No THEN CreditCard=YES;
(4)IF Children=No and Married=Yes and Mortgage=Yes and region=rural THEN CreditCard=NO.
其余规则见决策树.
3 结语
决策树是数据挖掘中一个常用的算法工具,因此它易于转化为图像显示,所以在决策支持中应用广泛.C4.5算法是在ID3的基础上改进而成的,修正了ID3的剪枝算法,并对高分支属性、数值型属性和含空值属性的整理有了系统地描述.文中采用C4.5算法,利用银行客户信息构造了一棵分类决策树,并以决策树为基础,抽取相应的分类规则建立了一个银行信用卡客户分类模型,对一批测试数据进行测试,从而验证了模型的有效性.
[1] HAB J,KAMBER M.Data Mining Concepts and Techniques[M].[S.l.]:Morgan Kaufmann Publishers,2000.
[2] 周根贵.数据仓库与数据挖掘[M].杭州:浙江大学出版社,2004:16-20.
[3] 王晓国,黄韶坤,朱 炜,等.应用C4.5算法构造客户分类决策树的方法[J].计算机工程,2003(14):89-91.
[4] 张晓龙,骆名剑.基于IF_THEN规则的决策树裁剪算法[J].计算机应用,2005(9):1 986-1 988.
[5] 郭 明.基于决策树的客户流失分析[J].广东通信技术,2004(11):37-40.
(责任编辑 陈炳权)
ApplicationofDecisionTreeinBankCustomerClassification
YIN Pengfei1,2,OU Yun2
(1.College of Information Science and Engineering,Central South University,Changsha 410000,China;2.School of Information Science and Engineering,Jishou University,Jishou 416000,China)
Decision tree is applied to classify the credit card customers of bank,and thus a classifying model is constructed.The features of different types of customers are discovered accordingly,which provides a best strategy for promoting the bank's credit card business.
data mining;decision tree;pruning;customer classification
1007-2985(2014)05-0029-04
2014-02-16
湖南省教育厅科学研究项目(14C0922)
尹鹏飞(1978—),男,湖南桃江人,中南大学计算机应用专业博士生,吉首大学信息科学与工程学院讲师,主要从事数据挖掘、推荐算法等研究.
TP274
A
10.3969/j.issn.1007-2985.2014.05.008
