基于Bloom滤波器的快速路由查找方法
2014-08-30于明王振安王东菊
于明,王振安,王东菊
(大连理工大学信息与通信工程学院,辽宁大连116024)
互联网应用的快速发展给路由器技术带来了极大的挑战,如何提高路由器的转发速度已成为下一代网络技术的研究热点[1]。在影响路由器报文转发速度的众多因素中,路由查找方法的设计是极为关键的一个环节[2]。
相对于传统的路由查找方法,如基于Trie树的路由查找方法、基于HASH的路由查找方法和基于内容可寻址存储器(content addressable memory,CAM)的硬件实现方法等[3],基于Bloom滤波器的路由查找方法出现相对较晚,但其在查找时间和存储空间方面的优异性能却引起了研究人员的广泛关注。2003年,Sarang.D等首次将Bloom滤波器引入到路由查找中[4],将不同长度的IP地址前缀存储在不同的Bloom滤波器中,待查询的IP地址并行输入到所有Bloom滤波器中,并根据滤波器的查询结果探测相应的选路表,以确定报文转发的下一跳信息。实验结果表明,该方法在查找时间和存储空间方面较之传统的路由查找方法有了较大提升。其不足之处是[5]:1)选路表的探测次数与Bloom滤波器的个数直接相关,当出现误称的滤波器增多时,无效探测次数会随之增多,导致路由查找时间增长;2)不同长度的地址前缀对应的选路表大小不均,无法保证路由查找性能的最优化。
为了解决上述问题,Haoyu.S等提出了一种基于分布式Bloom滤波器结构的路由查找方法[6],该方法是将一个完整的Bloom滤波器分成k个大小相同的子部分,并将哈希函数重新分组,每组中哈希函数的数量与前缀长度的数量相对应。这样既能减少Bloom滤波器的数量,又能避免前缀长度分布不均的问题。不过,该方法结构复杂,且不同长度的前缀需要不同的哈希函数,而要找到大量相互独立且性能较好的哈希函数目前还是很困难的[7]。李鲲鹏等采用前缀扩展的方法来减少Bloom滤波器的个数[8],但前缀扩展会扩大选路表,使单次选路表的探测时间大幅增加,降低了查找速度。
综上可见,对基于Bloom滤波器的路由查找方法而言,提高其查找性能的主要目标是减少对选路表的探测次数,而改进的主要方向则是减少Bloom滤波器的数量。基于此,本文提出了一种快速的路由查找方法。
1 基本原理
Bloom滤波器是一种高效的数据结构,目前已在文本检索、正则表达式匹配和网络资源共享等领域得到了广泛应用。Bloom滤波器的应用涉及到2个关键结构:1)一个长为m比特的位向量V,用于存储集合元素的映射信息;2)k个相互独立的哈希函数h1,h2,…,hk(1≤i≤k),用于将集合元素映射到位向量V中。Bloom滤波器的基本应用过程包括集合元素的存储和元素查询2个关键步骤,其执行过程如下。
1)集合元素的存储。
首先,对向量V进行初始化,将V中各比特位全部置零。然后,计算集合元素xi的k个哈希值h1(xi),h2(xi),…,hk(xi)。最后,根据计算出的哈希值将位向量V中对应的比特位置1,即执行操作V[h1(xi)]=V[h2(xi)]=…=V[hk(xi)]=1。若V中的某个比特位在执行映射之前已经置1,则该位在执行映射时不做任何变化。图1给出了利用Bloom滤波器存储集合元素的原理示意图。
2)元素的查询。
对任一元素y,利用Bloom滤波器查询其是否属于集合 V时,首先要计算y的哈希值h1(y),h2(y),…,hk(y),然后检查位向量V中对应比特位是否满足 V[h1(y)]=V[h2(y)]=…=V[hk(y)]=1。若不满足,则y必不在集合V中;若全为1,则判断y属于集合V。不过,对于后一种查询结果,有可能出现元素y被误判为属于集合X的情况,此时,称Bloom滤波器查询发生了假阳性误称[9],简称误称。
各类基于Bloom滤波器的路由查找方法的基本原理是:首先将路由表中所有IP地址的前缀按长度进行分类,每一个前缀长度对应设置一个Bloom滤波器,用于存储和查询该长度下各IP地址的前缀信息,从而形成一个Bloom滤波器组;然后,将转发报文的目的IP地址并行输入到各Bloom滤波器中进行查询,查询结果被存储到一个匹配向量中;最后,根据匹配向量各比特位的取值情况探测选路表,得到下一跳地址。图2给出了基于Bloom滤波器进行路由查找的原理框图。
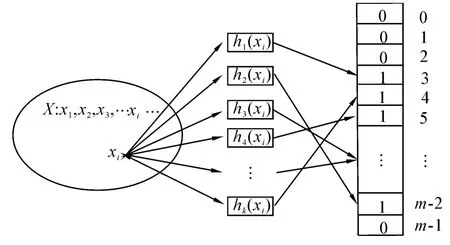
图1 基于Bloom滤波器的集合元素存储过程示意图Fig.1 Inserting an element to the Bloom filter
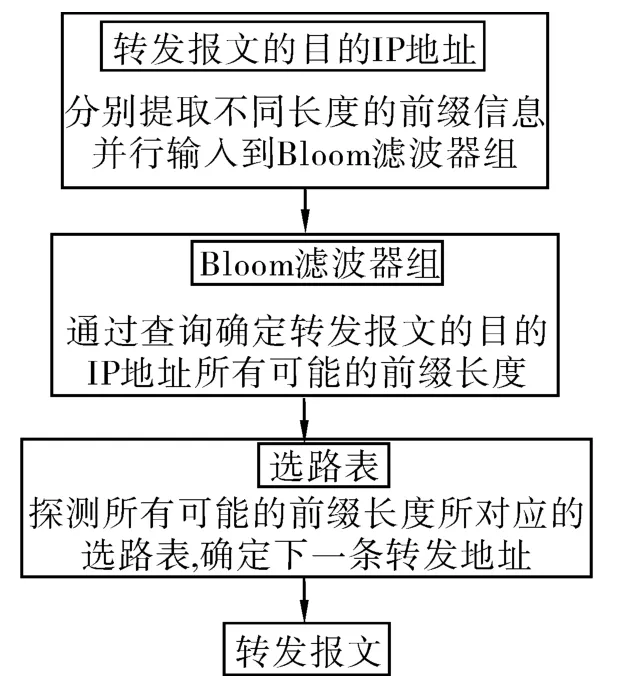
图2 基于Bloom滤波器路由查找的流程框图Fig.2 The flowchart of IP lookups based on Bloom filter algorithm
2 快速路由查找方法设计
2.1 设计原理
本文所提出的快速路由查找方法的核心架构包括一张根据路由表信息构建的首字节索引表、一组用于查询不同长度前缀的Bloom滤波器以及一组以IP地址前缀为索引的下一跳路由选路表,其设计原理如下。
首先,由于Bloom滤波器在判断元素是否属于已知集合时存在一定的误称率,所以,在设计路由查找方法时需要减少对Bloom滤波器的查询。现有的基于Bloom滤波器的路由查找方法都是直接将目的IP地址并行输入到所有可能的前缀长度所对应的Bloom滤波器中进行查询,而本文方法则预先根据已知的路由表信息设置了一张首字节索引表,该表的数据结构为{首字节,前缀长度1,前缀长度2,…,前缀长度n}。在执行Bloom滤波器查询之前,首先提取转发IP地址的首字节,并在首字节索引表中查找是否有对应的表项。若没有,则直接将该报文发送到默认端口;若有,则提取该首字节对应的所有可能的前缀长度,并将一个长度为32 bit的位向量V1中的相应比特位进行置位。之后,只需要根据V1中各比特位的置位情况查询相关长度所对应的Bloom滤波器即可。这一措施的实施可以有效地减少对Bloom滤波器的查询数量。
其次,本文方法还从Bloom滤波器组的优化入手减少Bloom滤波器的数量。常规Bloom滤波器组的设计方式都是每个可能的前缀长度对应一个Bloom滤波器,因而原则上需要近30个Bloom滤波器。而由亚太互联网络信息中心给出的路由表地址分析报告 (http://bgp.potaroo.net/as2.0/bgp-active.html)中的数据可以看出,对于采用无类域间路由的IPv4地址而言,长度小于8 bit、长度为31 bit和32 bit的前缀是不存在的,绝大多数的前缀长度集中在13~24 bit。图3在亚太互联网络信息中心报告的基础上给出了相关结论的图示结果,从中可以看出IPv4地址前缀长度分布的不均匀性。
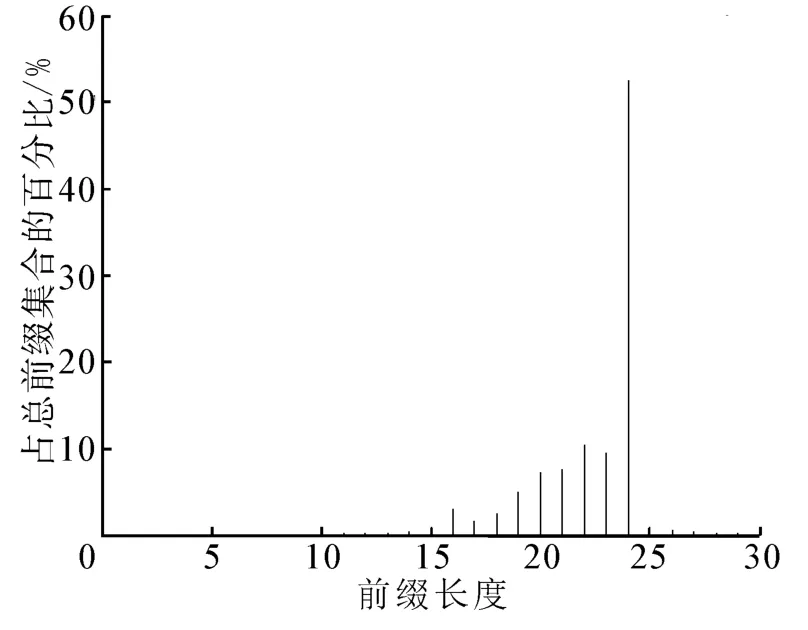
图3 IPv4前缀长度分布Fig.3 Distribution of the prefixes of IPv4 addresses
基于这一特性,本文方法在设计中使部分前缀长度共用一个Bloom滤波器,从而减少了Bloom滤波器的数量。具体的实施方案为:前缀长度为8~14 bit的前缀信息存储在1个Bloom滤波器中;前缀长度为15~24 bit的前缀信息分别存储在10个不同的Bloom滤波器中;前缀长度为25~30 bit的前缀信息存储在另外的1个Bloom滤波器中。所以,本文方法中共采用了12个Bloom滤波器。这一设计方式既可以平衡Bloom滤波器间的负载,又可以在减少Bloom滤波器个数的同时,不至于使选路表的规模过大,从而减小了因缩减Bloom滤波器的个数而对单次选路表探测时间的影响。
最后,由于路由表在更新过程中需要增添或删除某些地址信息,而标准的Bloom滤波器却并不支持元素的删除操作。因此,为了更好地支持路由表的更新,本文借鉴了计数型Bloom滤波器的设计思想[10],采用了具有计数功能的基本Bloom滤波器,其特征是将基本Bloom滤波器位向量中的比特位各自与1个计数器相关联,若将这些计数器记为C(j),0≤j≤m-1,则这种改进型Bloom滤波器的存储和查询操作可归纳为:1)添加元素xi:C[h1(xi)]=C[h1(xi)]+1,i=1,2,…,k;2)删 除 元 素xi:C[h1(xi)]=C[h1(xi)]-1,i=1,2,…,k。
需要指出的是,由于计数器需要占用较大的存储空间,为了减少对嵌入式内存的需求,可采用由独立控制器控制的计数器,并建议在具体实现时将其置于路由器芯片外的存储器中。
2.2 关键处理过程
2.2.1 转发路由的查找过程
转发路由的查询过程主要依据首字节索引表、Bloom滤波器组和选路表完成报文转发操作。图4给出了转发路由查找过程的流程框图。
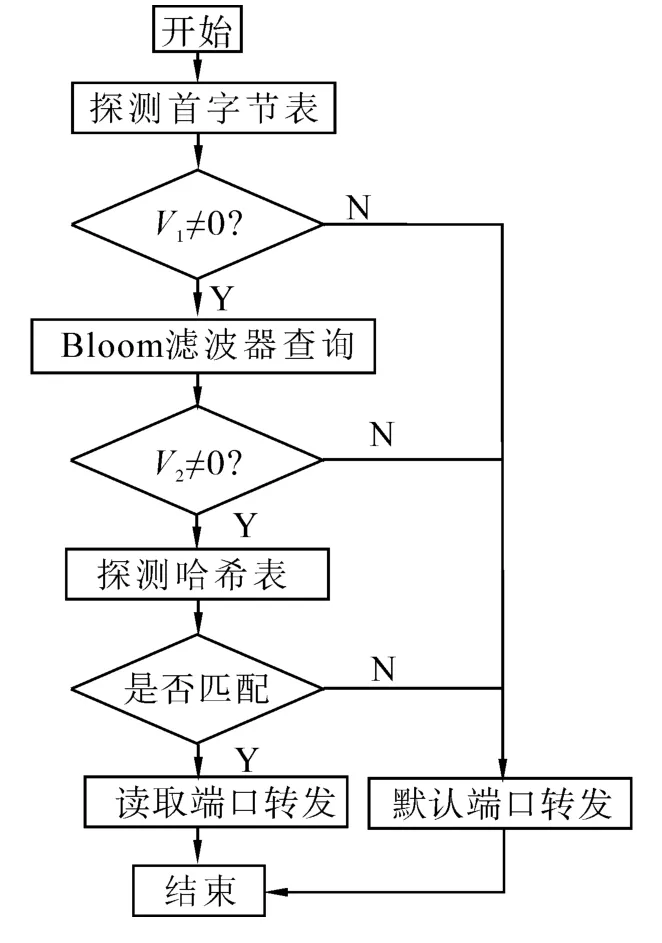
图4 转发路由查找过程的流程框图Fig.4 The flowchart of searching operations
首先,提取目的IP地址的首字节,在首字节索引表中查找是否有对应的表项,并将查找结果输出到匹配向量V1。若V1为零向量,说明首字节索引表中没有该IP地址的首字节所对应的表项,该报文将被发往默认端口;反之,则根据V1中各比特位的置位情况查找代表对应长度前缀的Bloom滤波器。
然后,将对Bloom滤波器的查找结果分为匹配(置1)或者不匹配(置0)2种情况,并记录到匹配向量V2中。
最后,根据V2的取值情况探测选路表。若V2为零向量,说明Bloom滤波器匹配失败,即目的IP地址对应的前缀不在选路表中,待转发报文被发送至默认端口;若V2不为零向量,说明至少有1个Bloom滤波器匹配成功,可依据最长前缀匹配的原则,根据V2的置位情况从较长前缀的选路表开始探测。若某次探测成功,则提取下一跳地址并转发数据包;若全部探测均以失败告终,说明基于Bloom滤波器的查询出现误称,待转发报文被发送至默认端口。
2.2.2 Bloom滤波器存储信息的更新过程
为了支持路由表更新,本文方法中采用了一种具有计数器的改进型Bloom滤波器。图5给出了本文方法中Bloom滤波器存储信息更新过程的流程图。
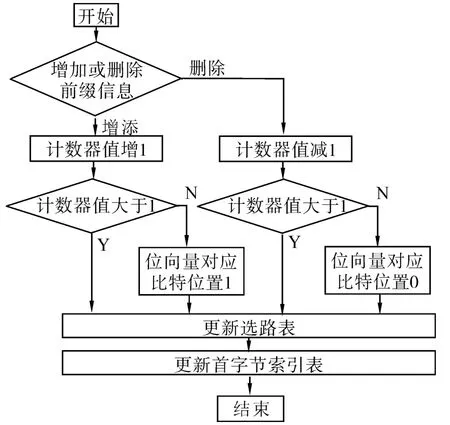
图5 Bloom滤波器存储信息更新过程的流程图Fig.5 The flowchart of element updating operations
当需要添加一个新的前缀信息时,首先根据其长度对Bloom滤波器相应的计数器进行元素添加操作。若更新后计数器的值为1,则必须同时将Bloom滤波器位向量中相应的比特位进行置位,否则,不再做任何变化。类似的,当需要删除一个前缀信息时,首先对Bloom滤波器相应的计数器进行元素删除操作。若更新后计数器的值为0,则必须同时将Bloom滤波器位向量中相应的比特位进行置零,否则,不再做任何变化。
需要指出的是,在完成Bloom滤波器的更新操作后,还要更新相应的选路表和首字节索引表,以确保路由查找的准确性。
2.3 性能分析
时间复杂度是目前衡量基于Bloom滤波器的路由查找方法性能的主要指标,影响时间复杂度的因素有2个:选路表的大小和探测选路表的次数。在其他条件一定的情况下,选路表越小,单次探测时间就越短;探测次数越少,查找时间就越短。但是,对于同一地址集合而言,在基于Bloom滤波器的各种查找方法中,每一前缀长度所对应的选路表的大小都是相同的,因此,不同查找方法的时间复杂度主要由选路表的探测次数决定。
文献[4]指出,假设单个Bloom滤波器的位向量大小为mi,存储条目的总数为ni,则单个滤波器的最小误称率fi与该滤波器的哈希函数数量ki之间的关系式为[4]
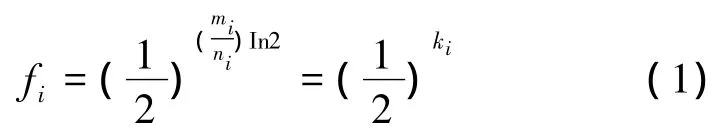
在实际应用中,滤波器组中各滤波器一般都设置为具有相同的位向量大小和哈希函数,但却可能具有不同的存储条目数,因此,各滤波器的误称率未必都会取得最优值。前文指出,本文方法依据IP地址前缀分布的不均匀性对滤波器的数量进行了优化,减小了各滤波器间存储条目的不均衡性,从而保证了各滤波器具有相近的误称率。为了便于分析,本文方法中假设各滤波器具有相同的误称率f。
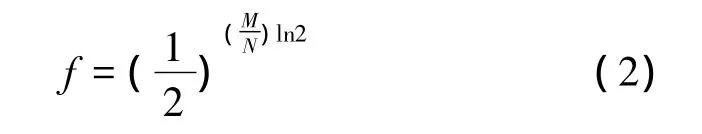
由方法的设计原理可以看出,选路表的探测次数与匹配向量V1和V2密切相关。假设需要对一个前缀长度为l的IP地址进行转发,设:1)由V1决定应查询的Bloom滤波器个数为B;2)进行选路表探测前需检查匹配向量V2中前缀长度大于l的滤波器的个数为Bl。则为了匹配前缀长度为l的IP地址,路由查找过程中需探测选路表的平均次数El可表示为
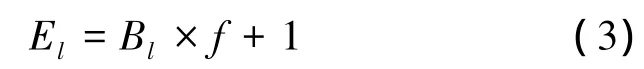
式中:Bl×f表示因滤波器的误称而对选路表进行的无效探测次数,1表示成功探测。对于任意前缀长度的IP地址,路由查找过程需探测选路表的平均次数可表示为

在所有滤波器均出现误称的最坏情形下,执行路由查找所需的选路表最大探测次数Emax为
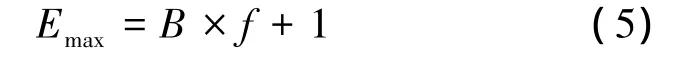
基于上述分析,可以从以下3个方面来说明本文方法与D.Sarang[4]、S.Haoyu 等[6]提出的同类方法相比所具有的的性能优势:
1)同类方法中Bloom滤波器的平均数量均在20~30个;本文方法则根据IP地址前缀长度的不均匀分布特性使部分长度的前缀共用一个滤波器,将滤波器的总数B缩减为12个,当Bl服从[0,12]间的均匀分布时,路由查找过程需探测选路表的平均次数可表示

最坏情形下选路表的最大探测次数Emax为
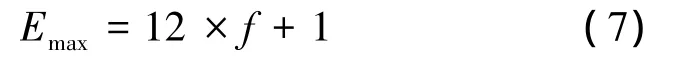
2)同类方法在进行地址查询时,都是直接将目的IP地址并行输入到所有Bloom滤波器中,查询计算量大且平均误称率高;本文方法在执行滤波器查询之前首先将待查地址通过首字节索引表进行预过滤,以减少需要查询的滤波器的个数,从而有助于降低查询的误称率。
3)同类方法中不同滤波器所存储的前缀条目的数量具有不均衡性,因而滤波器间的误称率差别较大,整个滤波器组的平均误称率fs较高;而本文方法则通过对滤波器数量的优化减小了各滤波器存储条目的不均衡性,使各滤波器具有相近的误称率,降低了整个滤波器组的平均误称率f。
表1对比了本文方法较之同类方法在性能方面的改善情况。
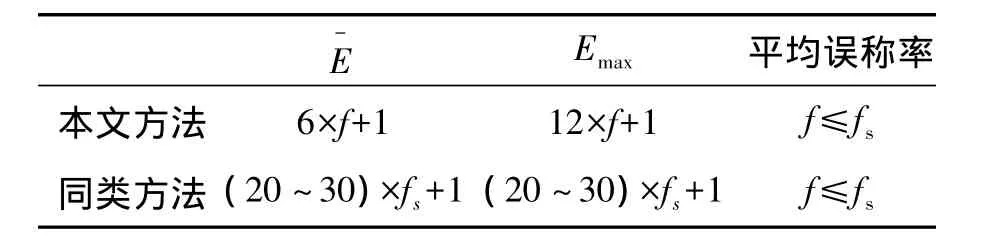
表1 本文方法与同类方法的性能比较Table 1 Performence comparisons between the proposed method and other similar methods
需要说明的是,本文方法中首字节索引表的引入必然会增加系统实现的复杂度,但索引查询过程仅涉及简单的二进制“与”操作和判断操作,实现并不困难。不过,当被查询地址的首字节对应的前缀索引数量较多时,首字节索引方式较之并行查询的优势会缩小。另外,对于前缀长度为8~14 bit及25~30 bit的地址查询而言,滤波器数量的减少会使其对应的路由表规模有所增大,单次探测时间会有所增加,当这类地址的数量较多时(实际应用中这种情况出现的概率很低,见图3),查询性能可能会低于同类方法。
3 实验验证
为了验证本文方法的有效性及相关性能分析的正确性,本文在Eclipse开发平台上用Java编写了本文方法的测试代码,并采用由中国网通、中国电信和中国联通等公司提供的2011年的路由数据进行了验证,该路由数据集中共有250 000条不同前缀长度的转发路由。此外,软件中为Bloom滤波器组分配的用于位向量的内存大小为4 Mbit。根据前述性能分析的结果,实验前首先对相关指标进行了理论计算,计算结果如下:
1)为了使各滤波器的误称率接近最优值,根据式(1)和式(2)计算出哈希函数数量的估值为
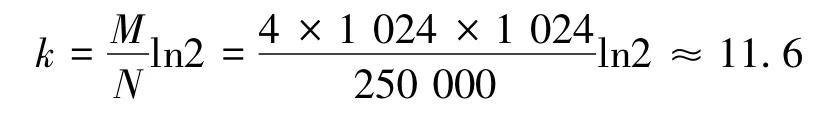
因此选择在软件实现中设置12个哈希函数。
2)根据式(2)估算出各滤波器最低误称率的理论值为
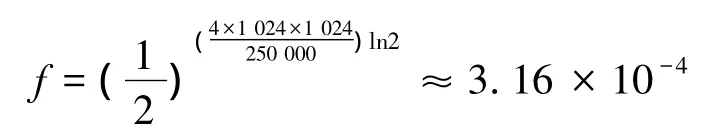
3)根据式(5)计算出路由查找过程中需探测选路表的平均次数≈ 1.001 9。
4)根据式(6)计算出最坏情形下执行路由查找所需的选路表最大探测次数Emax=1.003 8。
实验中对数据集里每一条IP地址都进行了查询测试,并在输出结果中记录了相关的Bl值和对应的选路表平均探测次数El,然后将相同Bl下对应的El进行了算术平均处理,作为对应于Bl的平均探测次数值,相关结果如表2所示。
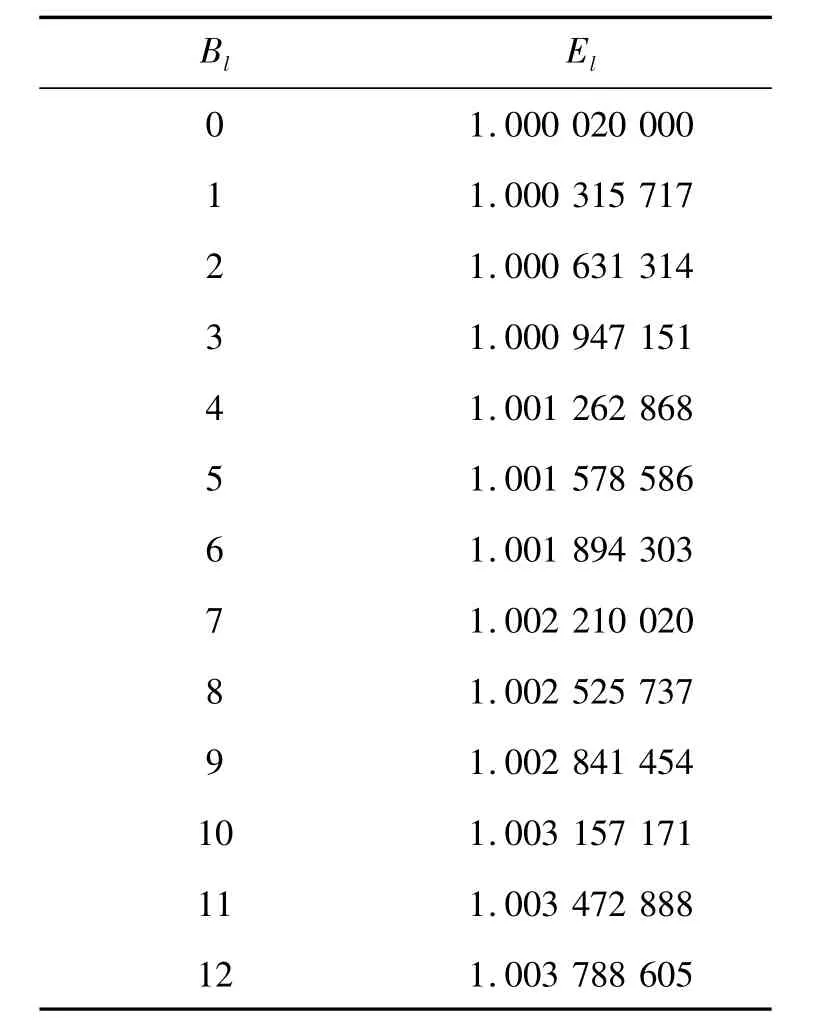
表2 选路表平均探测次数的实验结果Table 2 Experimental results of the averaged number of times to probe the HASH tables for each IP lookup
根据表2可以得到如下结论:
1)对表1中测得的13个El值做算术平均,得到,该结果与理论计算结果相符。
3)实验结果中El的最大值为1.003 788 605,而根据式(6)得出的最坏情形下执行路由查找所需的选路表最大探测次数Emax=1.003 8,从而验证了式(6)的正确性。
4 结束语
本文提出了一种基于Bloom滤波器的快速路由查找方法。该方法采取了2个措施以减少路由查找过程中对选路表的探测次数。1)建立了一个首字节索引表,用于减少需要并行查询的Bloom滤波器的数量,以降低Bloom滤波器的误称率对查询效率的影响。2)利用IP地址前缀长度分布的不均匀性对Bloom滤波器组的设置进行了优化,降低了路由查询对滤波器总数的需求。此外,本文方法还将Bloom滤波器位向量中的每一位与一个计数器相关联,以实现对路由更新的支持。实验结果验证了该方法的有效性及相关性能分析的正确性。
[1]NIU Yun,WU Liji,ZHANG Xiangmin.An IPsec accelerator design for a 10Gbps in-line security network processor[J].Journal of Computers(Finland),2013,8(2):319-325.
[2]胥小波,郑康锋,李丹,等.基于并行BP神经网络的路由查找算法[J].通信学报,2012,33(2):61-68.XU Xiaobo,ZHENG Kangfeng,LI Dan,et al.Routing lookup algorithm based on parallel BP neural network [J].Journal of Communications,2012,33(2):61-68.
[3]袁博,汪斌强,王志明.并行多流水绿色路由查找架构和算法[J].西安电子科技大学学报,2012,39(2):145-152.YUAN Bo,WANG Binqiang,WANG Zhiming.Green IP lookup architecture and algorithm based on the parallel multi-pipeline[J].Journal of Xidian University,2012,39(2):145-152.
[4]SARANG D,PRAVEEN K,TAYLOR D E.Longest prefix matching using bloom filters[J].IEEE/ACM Transactions on Networking,2006,14(2):397-409.
[5]LIM Hyesook,LIM Kyuhee,LEE Nara,et al.On adding Bloom filters to longest prefix matching algorithms[J].IEEE Transactions on Computers,2014,63(2):411-423.
[6]SONG Haoyu,KODIALAM M,HAO Fang,et al.Building scalable virtual routers with trie braiding[C] //Proceedings of IEEE INFOCOM 2010.San Diego,USA,2010:14-19.
[7]LUO Layong,XIE Gaogang,XIE Yingke,et al.A hybrid hardware architecture for high speed IP lookups and fast route updates[J].IEEE/ACM Transactions on Networking,2014,22(3):957-969.
[8]李鲲鹏,兰巨龙.基于TCAM的高效浮动关键词匹配算法[J].计算机工程,2012,38(4):269-274.LI Kunpeng,LAN Julong.Efficient unfixed keywords matching algorithm based on TCAM[J].Computer Engineering,2012,38(4):269-274.
[9]GUO Deke,LIU Yunhao,LI Xiangyang,et al.False negative problem of counting Bloom filter[J].IEEE Transactions on Knowledge and Data Engineering,2010,22(5):651-664.
[10]ROTHENBERG C E,MACAPUNA C A B,VERDI F L,et al.The deletable Bloom filter:a new member of the Bloom family[J].IEEE Communications Letters,2010,14(6):557-559.
