基于Apriori算法的海事事故中人为失误致因分析
2014-08-21李铃铃
李铃铃 仇 蕾
(河海大学管理科学研究所 南京211100)
0 引 言
我国是海洋大国,海洋问题事关国家根本利益。近年来,海事事故频频发生,严重制约了我国海洋事业的发展。研究表明,90%的海事事故是由人为失误引发的,人为失误又是由各种因素导致的,避免或减少海事事故的关键是减少这些因素的发生。笔者研究的主要内容就是找出人为失误和这些因素之间的关系,并获得影响力较强的因素。
以往研究主要采用查询、报表、联机应用分析等传统的方法,但这些方法只能初步识别出引发海事事故的人为失误行为,无法分析出人为失误与各影响因素之间的相互关系。笔者利用数据挖掘中的关联规则,挖掘出了它们之间存在的相互关系。关联规则分析是指在大型数据库系统中,迅速找出各事物之间潜在的、有价值的关联,并用规则的形式表现出来。陈兴伟和王志明[1]对海事各原因与结果之间的关联性进行了分析,发现船员因素与碰撞事故关联性最大。张晓辉、刘正江与吴兆麟[3]利用单维关联规则挖掘出人为失误与单因素之间对应关系。由于海事事故的发生是由多种因素混合组成造成的,光是挖掘出人为失误和单因素之间的对应关系还远远不够。笔者在前人研究的基础上,运用多维关联规则中的Apriori算法,借助Matlab软件工具,不仅挖掘出人为失误和单因素之间的对应关系,还挖掘出人为失误与影响因素组合之间的相互关系,更符合海事事故发生的实际情况,为相关部门的管理决策提供依据和支持。
1 基于Apriori算法的海事事故中人为失误致因分析模型
1.1 关联规则
1.1.1 Apriori算法
关联规则是数据挖掘中非常重要的分支,目前已经提出了很多算法,最著名的是R.Agrawal等人提出的Apriori算法[4],以下是Apriori算法的相关概念。
1)项集或候选集。Item={Item1,Item2,…,Itemk}称为k项集或k项候选集。假设DB包含m项属性(A,B,…,M),1项集1_Item={{A},{B},…,{M}},2项集2_Item={{A,B},{A,C},…,{A,M},{B,C},{B,D},…,{B,M},…,{C,D},…,{L,M}},共有[m×(m-1)/2]项项集;3项集3_Item={{A,B,C},{A,B,D},…,{A,B,M},{A,C,D},{A,C,E},…,{B,C,D},{B,C,E},…,{B,C,M},…,{K,L,M}};依次类推,m_Item={A,B,C,…,M},有一个项集。
2)支持度和可信度。支持度support简称sup,指某条规则的前件或后件对应支持度与总数的百分比。A的支持度sup(A)=|TR|TRA|/|n|,(AB)=sup(A∪B)=|TR|TR(A∪B)|/|
n|,其中,n是DB中总数的记录数目。可信度confidence简称为conf,规则AB具有可信度conf(AB),表示DB中包含A的事物同时也包含B的百分比,是A∪B的支持度和前件A的支持度的百分比:conf(AB)=sup(A∪B)/sup(A)。
3)强项集或频繁项集。如果k项候选集的支持度大于或者等于设定的最小支持度,则称该k项候选项集为k项强项集或者k项频繁项集。
4)关联规则。若A,B为项集,AItem,BItem并且A∩B=,关联规则是形如AB的蕴含式,算法普遍基于Support-Confidence模型。即在满足最小支持度时,若强项集可信度满足最小可信度,称此k项强项集为关联规则。例如,若(A,B)为二项强项集,sup(A∪B)≥min_sup且conf(AB)≥min_conf,则称AB为关联规则。
1.1.2 多维关联规则
根据关联规则所涉及的维数可以将其分成单维关联规则和多维关联规则[5]。当关联规则中属性只有一维,那么就称为单维关联规则或一维关联规则;否则称为多维关联规则。例如,天气(雾)→瞭望不当,规则左右两边的属性只涉及一维,则称为单维关联规则;若天气(雾)∧时间(03:30)→瞭望不当(“∧”指天气因素和时间因素同时存在),是规则的左边涉及天气和时间两维,则称为多维关联规则。由于海事事故的发生通常是由多种人为失误和影响因素造成,运用多维关联规则进行挖掘更符合实际情况。
1.2 人为失误和影响因素
海事事故中,人为失误指的是由于操作人员的错误决策和行为[9],导致船舶系统出现故障、效率降低或性能受损,从而引发海事事故。笔者将人为失误分成了13种;导致人为失误的影响因素分为4类,分别是个人因素、组织管理因素、船舶因素和自然因素,共有32种因素。为方便计算,对人为失误和影响因素进行编码,见表1、表2。

表1 人为失误编码Tab.1 Code of human errors
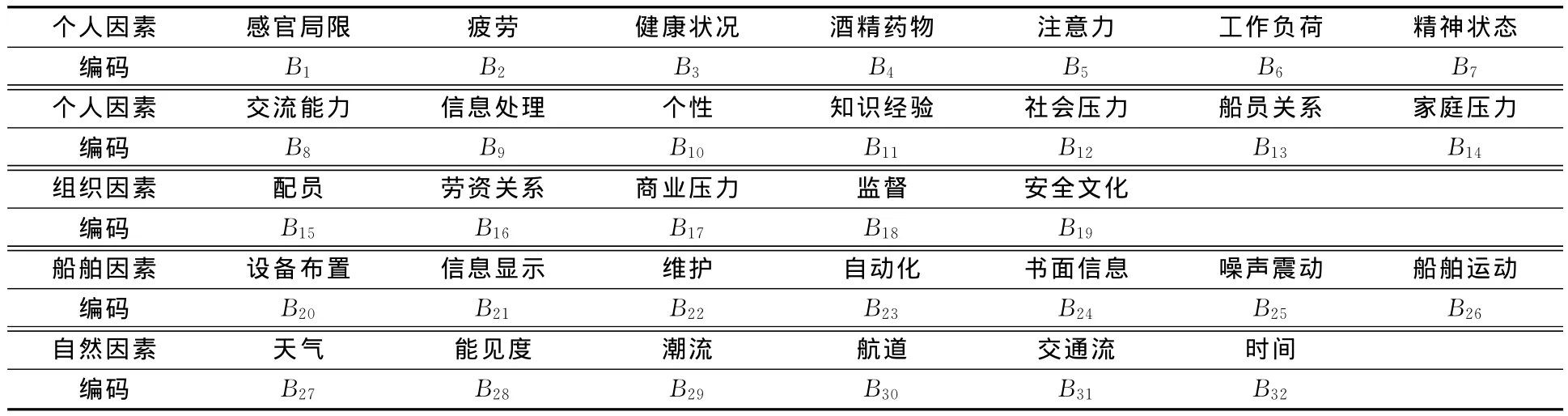
表2 影响因素编码Tab.2 Code of factors
海事事故的原始数据是杂乱无章,并且不完全的,需要对原始数据进行简化。保留事故记录中的导致事故发生的字段和事故结果字段,删掉其他字段,对事故记录进行简化。然后对事故的属性进行编码,并对属性值进行预处理,将其映射为整数。海事事故记录中的数据类型主要有3种:第1种是布尔型,如瞭望不当、未准确定位等;第2种是枚举型,如能见度、天气等;第3种是数值型,如时间、交通流。需要对数据进行处理[12]。
1)将布尔型数据进行转化。以瞭望不当为例,如果事故记录中有这项人为失误,则该属性的属性值为1;否则属性值为0。
2)对枚举型数据进行处理。以天气为例,主要有晴、阴、雨、雾4种天气,处理之后为:B27=1,晴;B27=2,阴;B27=3,雨;B27=4,雾。
3)对数值型数据进行离散化处理。以海事事故发生的时间为例,对该属性的属性值进行离散化:B32=1,00:00~06:00时;B32=2,06:00~08:00 时;B32=3,08:00~16:00 时;B32=4,16:00~18:00时;B32=5,18:00~24:00时。
1.3 分析步骤
运用Apriori算法分析人为失误诱因的步骤见图1[14]。
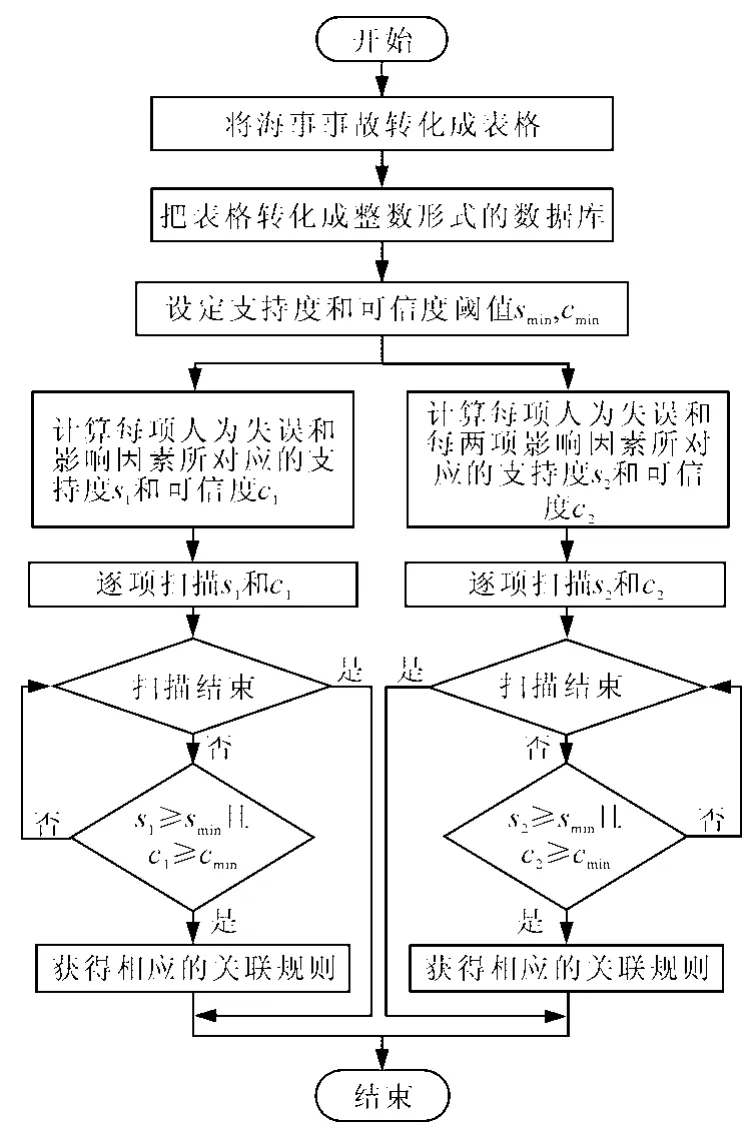
图1 基于Apriori算法的海事事故中人为失误诱因分析步骤图Fig.1 Causation analysis of human miss in marine accidents based on Apriori algorithm
具体步骤如下。
1)先将海事事故调查报告转化成表格的形式。
2)将表格转化成整数形式的数据库。
3)计算每项人为失误在数据库中出现的次数count(Am)。
4)计算每项人为失误和影响因素同时出现的次数count(Am∪Bn)。
5)根据步骤(3),(4)计算所有的支持度s(Am→Bn)和可信度c(Am→Bn)。
6)设定支持度和可信度阈值,若可信度和支持度都大于阈值,则获得相应的规则。
7)计算出每项人为失误和影响因素组合同时出现的次数count(Am∪(Bn1∪Bn2))。
8)根据步骤(3),(7)计算出人为失误和影响因素组合的支持度s(Am→(Bn1、Bn2))和可信度s(Am→(Bn1、Bn2))。
9)通过与阈值比较,获得相应的关联规则,并从中获得导致人为失误的主要诱因。
2 实例分析
2.1 报告来源
为了让数据更加符合研究的要求,从世界主要海运国家海事调查机构中精选了100份近年来的事故调查报告,并对这些调查报告进行研究分析,表3为报告的主要来源。
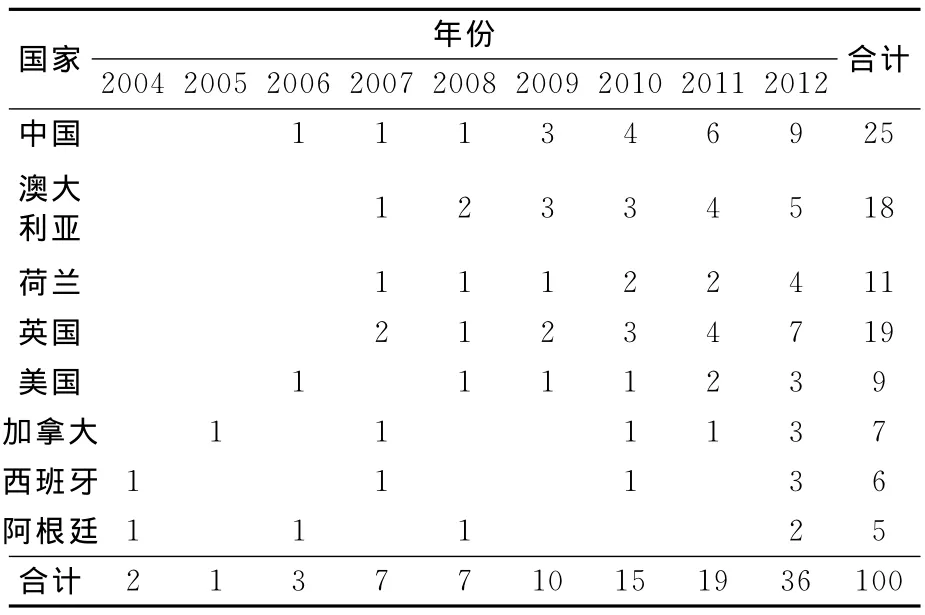
表3 海洋事故调查报告来源Tab.3 Sources of marine accident investigation report
报告具有以下几个特性。
1)时效性。事故报告选自近10年的事例,具有更好地参考价值。
2)权威性。事故报告必须是国家授权的海事调查机构或者海事管理机构发布的,这样对当事船的任何一方都不会有偏见。
3)随机性。选择事故报告时不要刻意考虑事故发生的时间、地点、船型、驾引人员情况、船舶所属公司和国籍等因素,保证人为失误与影响因素之间的关系不受报告来源影响。
4)完整性。书面报告要符合特定的格式,内容完整,事实表述清楚,分析有条有理。
2.2 实例分析
根据精选的100份调查报告建立1个海事事故数据库D,count(D)=100。每1个事故都有1个属性集合I={i1,i2,…,im,…,i45}。式中:im=0或1。由于已将人为失误分为13种,影响因素分为32种,所以总数是45。D中每一个事故都是I中1组因素的集合,即D∈I。设A是人为失误的集合,B是影响因素的集合,如果A∈T、B∈T,那么称事故T含A,B。其中:A={A1,A2,…,A13},B={B1,B2,…,B32}。
在对事故进行关联分析之前[15],要对最小支持度和最小可信度阈值进行合理的设定。阈值设定得过高,会忽略掉许多重要的规则;设定得过低,则会出现大量的矛盾规则和冗余规则。以往的研究中基本是采用经验法设定阈值,也就是凭借主观经验对阈值进行设定。事实证明,运用经验法设定的阈值要么偏高,要么偏低,不符合实际情况。笔者采用的是基于支持度变化的阈值设定方法,首先选择1个初始阈值进行计算,通过迭代,最终确定最适合用户的阈值。实例中,将初始支持度阈值设定为0.4,通过迭代确定最终的支持度阈值为0.305,可信度阈值为0.347。
1)第1次关联分析。首先计算每项人为失误和影响因素所对应的支持度s(Am→Bn)和可信度c(Am→Bn),将计算的结果与阈值进行比较,如果大于阈值,则获得相应的关联规则。
支持度和可信度由式(1)、式(2)计算,获得的关联规则见表4。

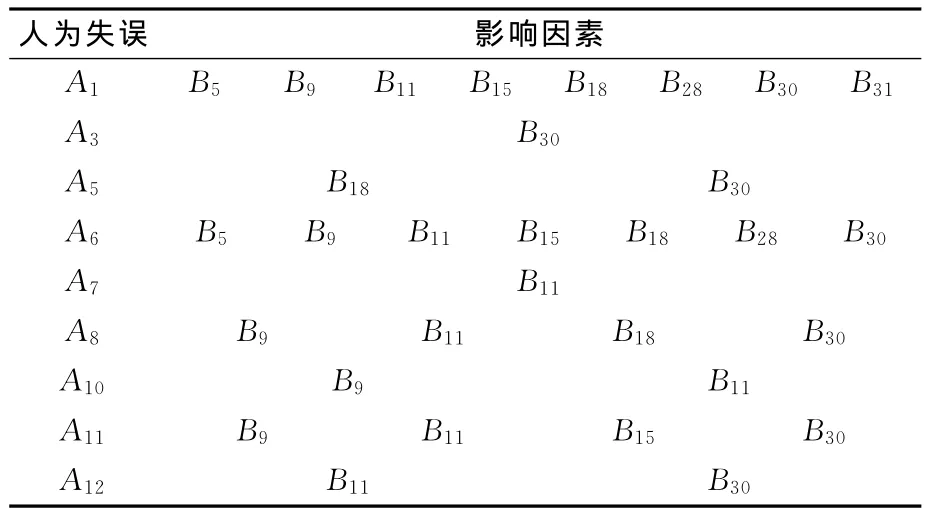
表4 第1次数据挖掘产生的关联规则Tab.4 The first data mining association rules generated
2)第2次关联分析。首先计算每项人为失误和影响因素组合所对应的支持度s(Am→(Bn1、Bn2))和可信度s(Am→(Bn1、Bn2)),若计算结果大于阈值,则获得相应的关联规则。
支持度和可信度由式(3)、式(4)计算,获得的关联规则见表5。
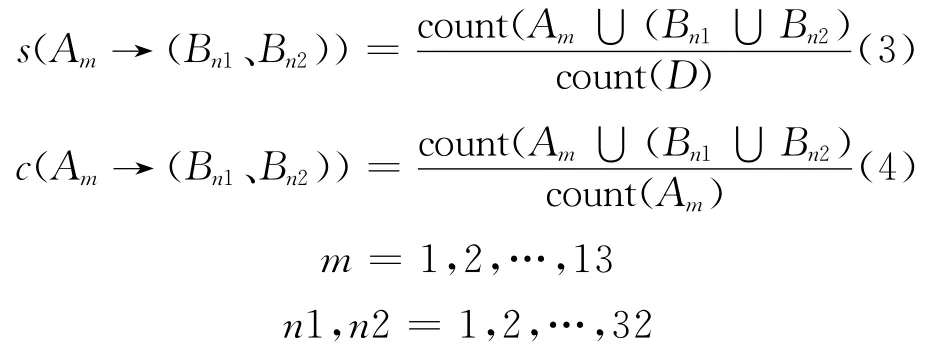
2.3 挖掘结果
采用不同的可信度和支持度阈值,运用关联规则挖掘出来的结果也不一样。笔者通过迭代确定合适的支持度和可信度阈值,对海事事故数据进行了2次挖掘。首先对人为失误和单因素之间的对应关系进行了挖掘。以其中1项人为失误瞭望不当为例,挖掘出主要的影响因素有B9,B11,B15,B18,B28,B30和B31,也就是注意力、信息处理能力、知识经验培训、配员、监督、能见度、航道和交通流。

表5 第2次数据挖掘产生的关联规则Tab.5 The second data mining association rules generated
第2次是挖掘人为失误和影响因素组合之间的关系。以瞭望不当为例,挖掘出的主要影响因素组合为(B9,B30),(B11,B30),(B18,B30)和(B28,B31),也就是(信息处理能力、航道),(知识经验培训、航道),(监督、航道)和(能见度、交通流)。
3 结论及建议
针对海事事故数据复杂量多等特点,运用多维关联规则的数据挖掘方法,建立了基于Apriori算法的海事事故中人为失误致因分析模型。通过对模型计算结果进行分析,得到一些有意义的结论和改进措施。
1)人员的注意力、信息处理能力、知识经验培训,船舶的配员、监督以及一些外部条件如天气的能见度、通行航道和交通流是导致人为失误,引发海洋事故的主要因素。所以要想减少海事事故的发生率,要从内部条件和外部环境2方面预防事故的发生。
从内部条件方面,选拔一些素质较高的工作人员,如思维反应比较敏捷,受教育程度较高的工作人员;在这个基础上制定合理的监管制度,并对人员进行合理的配置。
外部环境方面,尽量在天气较好、能见度较高的时候进行航行;选择路线较为安全,船舶流量较少的航线航行,以此减少事故发生的外部风险。
2)当外部的条件不是特别利于航行时,如航道不顺,交通流太密集,或能见度不高时,应当立即调整人员配置,加大监管措施,以减少事故的发生率。
3)研究表明,当交通流很密集的航行区域出现能见度较低的天气时,发生海事事故的概率较高。所以当航海出现这种情况的时候,可以适当地调整航行计划,如暂时将船舶停靠至附近的码头或者选择合适的时间段航行,降低事故发生概率。
同时,笔者所做研究仍然存在一些不足之处。
1)没有针对特定海域的海事事故分析研究,所以不具有太强的针对性。
2)在对海事事故进行关联分析时,仍然没有找出理想的针对海事事故数据的阈值设定方法。
[1] 陈兴伟,王志明.港口水域安全风险分析法[J].中国航海,2009,32(1):69-71.
[2] 曲生伟.海上交通事故案例[M].武汉:武汉理工大学出版社,2011.
[3] 刘正江,吴兆麟.基于船舶碰撞事故调查报告的人的因素数据挖掘[J].中国航海,2004(2):1-6.
[4] 陈 燕.数据挖掘技术与应用[M].北京:清华大学出版社,2010.
[5] 王宏雁,王 琪.多层多维关联规则在交通事故研究中的应用[J].交通科学与工程,2009,25(1):73-77.
[6] 刘 红,何 鹏.基于粗糙集的海事事故影响因素分析[J].上海海事大学学报,2013,34(2):18-23.
[7] 毕建欣,张岐山.关联规则挖掘算法综述[J].中国工程科学,2005,7(4):89-94.
[8] 张晓辉,刘正江,吴兆麟.基于水上交通安全事故基础数据的模式发现[J].大连海事大学学报,2011,37(2):40-42
[9] 付玉慧.海事事故中人为失误的作用机理[J].大连海事大学学报,2004(3):106-108.
[10] 程 岩,黄梯云.粗糙集中定量关联规则的发现及其规则约简的方法研究[J].管理工程学报,2001(3):73-77.
[11] 刘 洋,马寿峰.基于聚类分析的非参数回归短时交通流预测方法[J].交通信息与安全,2013,31(2):27-31.
[12] 王冬秀,赖先涛,李 辉,等.道路交通事故中关联规则挖掘研究[J].计算机与信息化,2012(8):207-208.
[13] 蒋 宏,方守恩,陈雨人,等.基于时间序列和灰色模型的交通事故预测[J].交通信息与安全,2012,30(4):93-98.
[14] 郭秀娟.基于关联规则数据挖掘算法的研究[D].长春:吉林大学,2004.
[15] 朱晓东,李帮义.基于支持度变化的关联规则重挖掘技术[J].电气技术与自动化,2005,34(2):75-77.
