Expert ranking method based on ListNet with multiple features
2014-08-08CHENFangqiong陈方琼YUZhengtao余正涛WUZejian吴则健MAOCunli毛存礼ZHANGYouming张优敏
CHEN Fang-qiong(陈方琼), YU Zheng-tao(余正涛),, WU Ze-jian(吴则健),MAO Cun-li(毛存礼), ZHANG You-ming(张优敏)
(1.School of Information Engineering and Automation, Kunming University of Science and Technology, Kunming 650500, China; 2.Intelligent Information Processing Key Laboratory, Kunming University of Science and Technology, Kunming 650500, China)
Expert ranking method based on ListNet with multiple features
CHEN Fang-qiong(陈方琼)1,2, YU Zheng-tao(余正涛), WU Ze-jian(吴则健)1,2,MAO Cun-li(毛存礼)1,2, ZHANG You-ming(张优敏)1,2
(1.School of Information Engineering and Automation, Kunming University of Science and Technology, Kunming 650500, China; 2.Intelligent Information Processing Key Laboratory, Kunming University of Science and Technology, Kunming 650500, China)
The quality of expert ranking directly affects the expert retrieval precision. According to the characteristics of the expert entity, an expert ranking model based on the list with multiple features was proposed. Firstly, multiple features was selected through the analysis of expert pages; secondly, in order to learn parameters through gradient descent and construct expert ranking model, all features were integrated into ListNet ranking model; finally, expert ranking contrast experiment will be performed using the trained model.The experimental results show that the proposed method has a good effect, and the value of NDCG@1 increased 14.2% comparing with the pairwise method with expert ranking.
expert retrieval; expert ranking; ListNet; multiple features
The core problem of expert retrieval is how to efficiently and accurately rank expert information. Expert retrieval is the same with full-text retrieval, which takes the calculation of “similarity” as standards of ranking. However, ranking model for expert retrieval is very different from full-text retrieval due to the difference of the ranking object (entity level). The standard of measuring “similarity” in expert retrieval is the matching degree of query the user input and the experts named entity. Given query topic, the expert retrieval system can use a variety of documents and resources for characterization experts to calculate the relevance of query topics and experts, and show expert result list in accordance with the degree of ranking[1].
On the aspect of leaning to rank research, a model score as the relevant features of ranking model has been a very good application in information retrieval and many other fields. For example, BM25 and IBM model 1 as relevant features are widely used in learning to rank areas[2]. In 2004, Nallapati proposed discriminant model to rank documents using support vector machines and maximum entropy[3]. Burges and Shaked presented RankNet algorithm, which uses neural network model combined with the gradient descent algorithm to optimize the ranking loss function based on cross-entropy[4]. In 2007, Cao put forward ListNet algorithm based on data list, which calculates ranking loss on the entire ranked lists[5]. Cao Yunbo applied adapting ranking RVM to document retrieval in order to improve the ranking effect. There are two important factors that must be taken into consideration when applying learning to rank document retrieval. One is to intensify training for top-ranked documents, and the other is to avoid training a model biased toward queries with many relevant documents. The new loss function naturally incorporates the two factors into the Hinge Loss function used in Ranking SVM, with two types of additional parameters. They employ gradient descent and quadratic programming to optimize the loss function. Experimental results indicate that this method significantly outperform Ranking SVM and other existing methods in document retrieval[6]. On the aspect of expert ranking research, in 2010, Fang proposed expert ranking discriminant model, through the co-occurrence probability of topic and candidate in supporting document to rank candidate experts, which integrates various supporting document features to improve expert retrieval performance.To a certain extent, this model overcomes some independent assumptions in the language model and is helpful for learning some features better[7]. Experts ranking method could directly impact on the results of expert retrieval. Because the complex relationship may exist between experts list, the ranking process must consider the potential of these relationships between experts. Traditional expert retrieval discriminant model makes the correlation of individual experts absolute, ignoring the relative relationship or partial ordering relation between the whole expert lists. This pointwise approach can not reflect the ranking loss on the entire list of experts, and the ranking of expert samples is more important than the classification of related level of experts. Furthermore, the pairwise approach for expert ranking also has certain limitations.
This paper will study the correlation between the query and expert evidence documents, and analyze expert metadata, expert evidence documents, expert relations, and other factors affecting expert ranking. Utilizing statistical learning methods of ranking, combined with the page content features and relationship features, we study an expert ranking method based on the expert lists with multiple features.
1 Feature selection and extraction
Feature selection plays an important role in expert ranking, and the quality of the feature selection results will greatly influence the effect of the expert ranking. Therefore, how to select the appropriate features is one of the keys in this paper. We have divided expert evidence documents into four categories: expert homepage, expert blog page, Baidu Wikipedia page and non-expert page. According to the analysis of the characteristics of these pages, we select the page content features, and then by analyzing the relationship between evidence documents, we select the suitable relationship features. Because the candidate documents should be the most similar to the query, we use similarity features for expert ranking model.
In order to use the features of the context information more effectively and get the best expert ranking model, we extract features for each query-document pairs in the gathered datasets. The features can be classified into three categories.
1.1 Similarity features
We model the queries and candidate expert pages based on sentence similarity, by computing the similarity of each query and candidate documents as the feature value for expert ranking. Similarity features include term frequency (tf), inverse document frequency (idf), document length (dl), and their combinations (tf*idf)[8]. For each of these features, we have four different values corresponding to the four fields of a webpage: body, anchor, title, and URL.
1.2 BM25 score
BM25 retrieval algorithm[9]is presented by Robertson in TREC3 at 1994. It is used to calculate the similarity between documentDand queryQ. We used BM25 to compute the similarity between queryQand candidate answersA. We chose this similarity formula because it provided the best ranking at the output of the answer retrieval component. Given the queryQ(q1,…,qt), BM25 score is calculated as
whereNis the total candidate answers;n(qi) is the total answer that contains retrieval unitqi;f(qi,A) is the frequency ofqiappearing inA;f(qi,Q) is the frequency ofqiappearing inQ; |A| is the length of the answers, avgal is the average length of all candidate answers;k1,k3andbare regulatory factors, which are usually set based on experience. According to the definition, the role of parameterbis to adjust the relevant effects on length of the answer. Whenbis larger, and the impact of the length of answers on relevance score is greater, same if vice versa. When the relative length of answers is longer, and the relevance score will be smaller. It is understandable when the answer is longer, the opportunity includingqiis greater. Weight of each item is set in this paper as follows:k1=2.5,k3=0,b=0.8.
We extractedthree BM25 features in total, using the whole document, anchor text and title respectively.
1.3 Features related to expert
By the analysis of the query and expert evidence document, we selected expert page content features and relationship features among expert pages as features related to expert.
1.3.1 Expert page content features
For the characteristics of expert entities, through the analysis of candidate expert document sets, the page content features were selected as shown in Tab.1.

Tab.1 Expert page content features
1.3.2 Relationship features
We have already divided expert evidence documents into 3 categories: expert homepage, expert blog page and Baidu Wikipedia page. They usually contain information like expert files, research field and published papers. There are often coauthors’ name in the published papers and organization name in the expert files. The experts academic resources network, such as CNKI, reflects the information about institutions and cooperative relationship and others between experts. There is no good solution to select the appropriate relationship features between expert evidence documents according to the characteristics of relationship among experts. In order to get good expert ranking result, this paper selected the coauthor and organization as the relationship feature between expert evidence documents.
If coauthors’ name shows in the published paper among different expert evidence documents, it indicates a coauthor relationship. If the same organization name shows in different expert evidence documents, it indicates an organization relationship. A large amount of sample analysis shows that if there is coauthor or organization relationship between different evidence documents and one of the evidence document is candidate expert page when searching for the research direction and the organization, the probability that the other evidence documents belonging to candidate expert page for the same query will be greatly increased. Based on the analysis above, the selected relationship features are shown in Tab.2.

Tab.2 Relationship features

Fig.1 Relationship between evidence document pages
Fig.1 shows that there are coauthor and organization relationship between page A and page B, and there are organization relationship between page A and page C. If page A is the corresponding retrieval page for one query, then the probability that page B is the candidate expert page for the same query is greater than that of page C.
We assume that the size of a set of samples which have the most high frequency co-occurrence words with a certain page ismand the strength of coauthors relationship between the page and the sample set isn, so the coauthors feature value of this page isn/m.
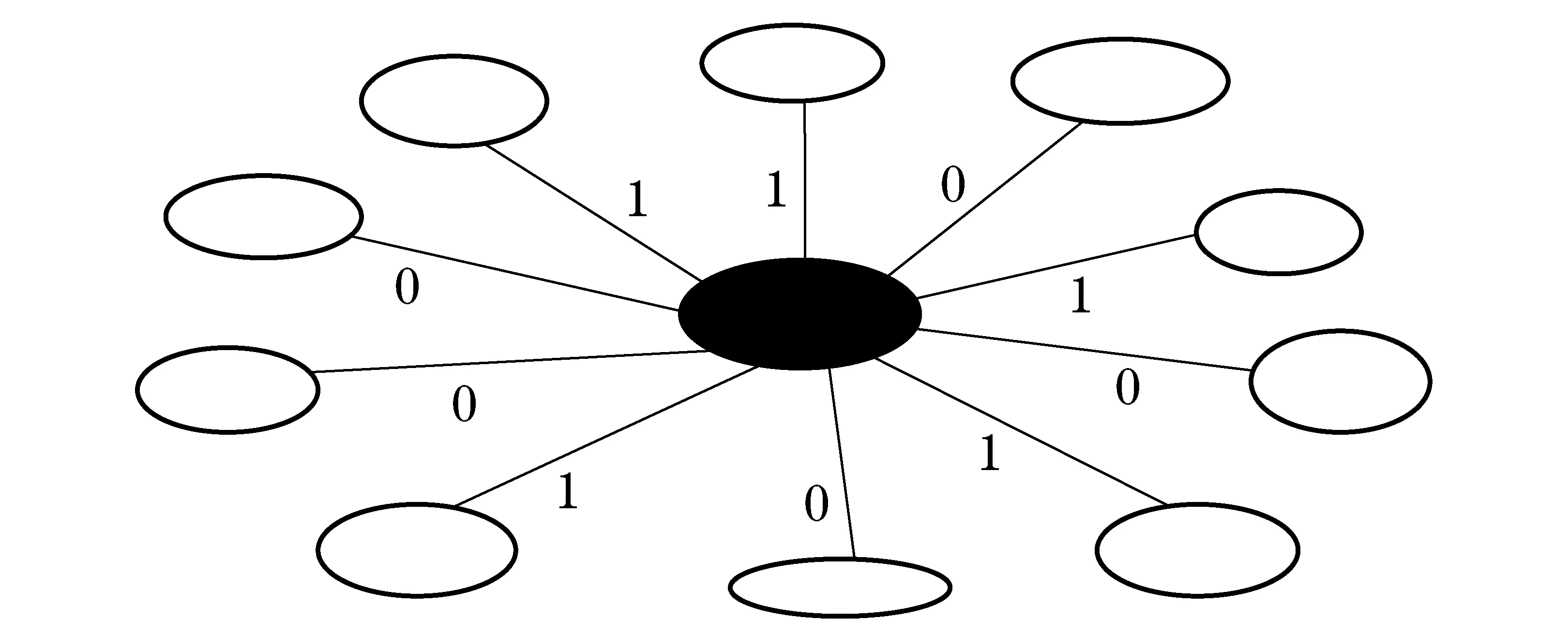
Fig.2 Relationship feature value
Fig.2 shows that the black node in this figure represents a page A of a certain expert, and the other white nodes represent the page set which composed of pages which have the highest frequency co-occurrence words with page A.The connection lines represent the strength of coauthors relationship between pages, so the coauthors relationship feature value of page A is 5/10. Similarly, if the connection lines represent strength of organization relationship between pages, the organization relationship feature value of page A is 5/10.
2 Learning method: ListNet
ListNet takes lists of documents as instances in learning. It uses a probabilistic method to calculate the listwise loss function. ListNet transforms both the scores of the documents assigned by a ranking function and the explicit or implicit judgments of the documents given by humans into probability distributions. It then utilizes cross entropy between the probability distributions as the loss function.
Let π denote a permutation on the objects. In ListNet algorithm, the probability of π with given scores is defined as
(1)
Thenthetopkprobability ofζ(j1,j2,…jk) can be calculated as
(2)
TheListNetusesalistwiselossfunctionwithcrossentropyasmetric

(3)
Denotefωas the ranking function based on neural network modelω. The gradient ofL(y(i),z(i)(fω)) with respect to parameterωcan be calculated as
(4)
Eq.(4) is then used in gradient descent. Algorithm 1 shows the learning algorithm of ListNet.
Algorithm 1 Learning Algorithm of ListNet
Input: training data {(x(1),y(1)), (x(2),y(2)), ..., (x(m),y(m))}
Parameter: number of iterations T and learning rateτ
Initialize parameterω
fort=1 toTdo
fori=1 tomdo
Inputx(i)of queryq(i)to Neural Network and compute
score listz(i)(fω) with currentω
Compute gradient Δωusing Eq.(4)
Updateω=ω-τ×Δω
end for
end for
Output Neural Network modelω
In each iteration,ωis updated with -τ×Δωin a gradient descent way. Hereτis the learning rate.
Notice that ListNet is similar to RankNet. The only major differences are the former uses document lists while the latter uses document pairs as instances, and the former utilizes a listwise while the latter utilizes a pairwise loss function. Interestingly, when there are only two documents for each query, i.e.,n(i)=2, then the listwise loss function in ListNet becomes equivalent to the pairwise loss function in RankNet.
For simplicity, we use a linear neural network model and omit the constantbin the model:
(5)
where〈·,·〉denotesaninnerproduct.
Totrainalearningtorankmodel,themanuallyevaluatedscorelistforeachquery’scandidatelistisrequired.Weassign2todefinitelyrelevantpages, 1topartiallyrelevantand0totheirrelevantpages.
3 Experiments
3.1Evaluationmeasures
Forevaluation,weuseprecisionatpositionn, mean average precision, mean reciprocal ranking and normalized discount cumulative gain as the measures. These measures are widely used in learning to rank. Their definitions are as follows.
3.1.1 Precision at positionn(P@n)
Precision atnmeasures the relevance of the topndocuments in the ranking result with respect to a given query:
Forasetofqueries,weaveragetheP@nvalues of all the queries to get the meanP@nvalue. SinceP@nasks for binary judgments while there are three levels of relevance judgments inour collection, we simply regard “definitely relevant” as relevant and the other two levels as irrelevant when computingP@n.
3.1.2 Mean average precision (MAP)
MAP is used to measure average retrieval quality in a retrieval system for multiple inquires. Given a query, the average precision is defined as:
whereNisthenumberofretrieveddocuments,andrel(n)isabinaryfunctionontherelevanceofthen-thdocument:
Forasetofqueries,wegetMAPbyaveragingtheAPvaluesofallthequeries:
3.1.3Meanreciprocalranking(MRR)
MRRisconcernedwiththelistofrelateddocumentsinthefirstplace.MRRisdefinedas
whereQis the set of all queries, and rankiis the location of the first document in the results list for thei-th query.
3.1.4 Normalized discount cumulative gain (NDCG)
In the evaluation of NDCG[10], each document has corresponding contribution to its position according to the correlation of documents, which can handle multiple levels of relevance judgments. The NDCG value of a ranking list at positionnis calculated as
whererjis the rating of thej-th document in the ranking list, andZnis a normalization factor chosen so that the ideal list gets a NDCG score of 1.
3.2 Experiment datasets and setup
At present, there are no authoritative corpus resources in expert retrieval system, so we manually collected 10 130 expert evidence document sets, which include expert homepage, expert blog page, Baidu Wikipedia page and non-expert page, to construct the expert query and candidate document set. The candidate documents will be marked as irrelevant (0), partial relevant(1), relevant (2).In order to avoid over-fitting phenomenon, we divided the data into three parts utilizing cross-validation approach, including training sets, validation sets, and testing sets. The trained ranking model is applied to adjust parameters on validation sets and test ranking performance on testing sets. We extracted various kinds of features from query and expert evidence and relationship features between candidate expert documents to train the ranking model. This part could be called training stage. We use gradient descent method to optimize the model.
3.3 Experiment and result analysis
3.3.1 Comparison of feature selection
Different feature sets have different impacts on ranking performance, which will, in turn, affect the results of expert ranking. The effectiveness of each type of feature was evaluated separately to show whether all of the proposed features are helpful. We put more attention to the performance of ranking model, so we evaluate the percentage of correct documents ranked top-1 and mean average precision. The ranking algorithm uses ListNet algorithm. Tab.3 lists the major features that we selected.

Tab.3 Features selection and the results of expert ranking
In the experiment, we added the new features continuously to examine the effects on expert ranking. Through analyzing the experiment result above, we find that the experimental effect is poor by only adopting BM25 model and it is improved when adding similarity features, and the MRR andP@1 acquire 69.79% and 62.13%, which shows that the combination of features is critical for improvement. When adding page content features, the MRR andP@1 respectively obtain 76.53% and 78.56%. When adding relationship features, the MRR andP@1 reach 83.49% and 88.71%. Therefore, the experimental result explains that the combination of multiple features can effectively improve the results of expert ranking. Furthermore, carry out the combination of various features, and repeat the experiment until the small change of accuracy.
3.3.2 Selection of ranking algorithm
First, through the analysis of expert pages, research, select similarity features between the query and candidate expert pages, expert page content features and relationship features between expert pages; second put these features into ListNet ranking model, construct expert ranking model based on the list with multiple features, and then calculate by model training and learning parameters; finally, test the effect of expert ranking on testing sets using the trained model.
In order to evaluate the performance of the expert ranking model based on list with multiple features, we separately chose RankNet and Ranking SVM algorithm as the baseline methods to do comparative experiment. In the experiments, we used respectively these three evaluations (P@n, MAP, NDCG) to measure the ranking results, comparison results are shown in Tabs.4-6.
Tab.4 Comparison results of different expert ranking method by precision at positionn
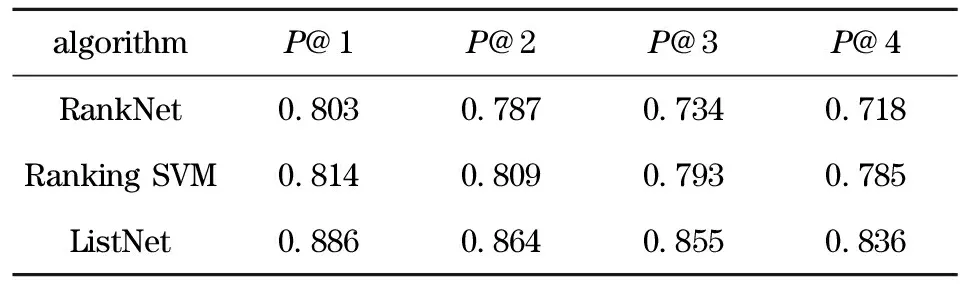
algorithmP@1P@2P@3P@4RankNet0803078707340718RankingSVM0814080907930785ListNet0886086408550836
Tab.5 Comparison results of different expert ranking method by mean average precision

algorithmMAPRanknNet0457RankingSVM0461ListNet0472
Tab.6 Comparison results of different expert ranking method by NDCG at positionn
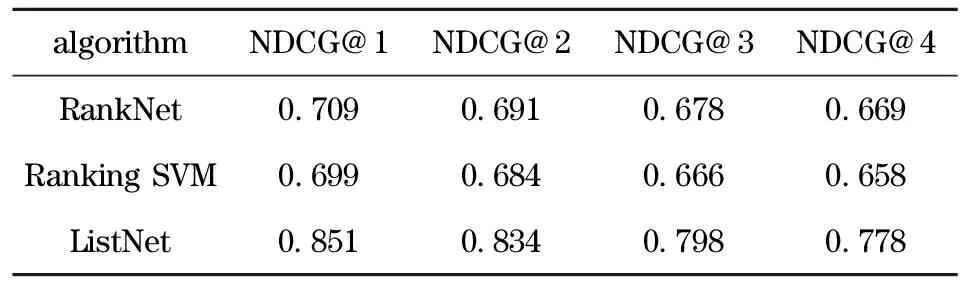
algorithmNDCG@1NDCG@2NDCG@3NDCG@4RankNet0709069106780669RankingSVM0699068406660658ListNet0851083407980778
The experimental results show that the experts ranking model based on ListNet algorithm has greatly improved comparing with RankNet and Ranking SVM algorithm through the performance of the three algorithms above (Tab.4) in expert retrieval. In our datasets, for the three evaluations the performance of Ranking SVM is slightly little bit better than RankNet. While the results of ListNet algorithm are much better than RankNet and Ranking SVM, the value ofP@1 reaches 0.886, 7.2% higher than RankNet, the value of MAP reaches 0.472, and the value of NDCG@1 reaches 0.851, 14.2% higher than RankNet.
3.4 Experimental evaluation
The proposed method of expert ranking based on list improved the results of ranking greatlyin the experiments. The initial relevant candidate documents were not in the front before ranking, which demonstrates that building ranking model to re-rank the documents could use various information better about the query and candidate expert documents. From the experiments we can see that the ranking method based on list can be applied to expert ranking, and has achieved very good results. In the future, we will expand the experimental datasets, and then continue to explore the characteristic of the expert evidence documents to increase the expert ranking effect.
4 Conclusion
For the characteristics of the expert entity, an expert ranking method based on ListNet with multiple features is proposed. This method makes a deep analysis of the query and expert pages, and extracts many kinds of features from the query and candidate expert pages, and then builds the expert ranking model based list to improve the effect of expert ranking. Experiments show that the presented method can effectively improve the results of expert ranking, and the value of NDCG, MAP andP@1 have significantly improved compared to other algorithms.
[1] Fang Yi, Si Luo, Mathur A. Learning to rank expertise information in heterogeneous information sources[C]∥Proceedings of SIGIR 2009 Workshop on Learning to Rank for Information Retrieval, Boston, USA, 2009.
[2] Liu Tieyan, Xu Jun, Qin Tao, et al. Letor: Benchmark dataset for research on learning to rank for information retrieval[C]∥Proceedings of SIGIR 2007 Workshop on Learning to Rank for Information Retrieval, Amsterdam, The Netherlands, 2007.
[3] Nallapati R. Discriminative models for information retrieval[C]∥Proceedings of the 27th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Sheffield, United Kingdom, 2004: 64-71.
[4] Burges C, Shaked T, Renshaw E, et al. Learning to rank using gradient descent[C]∥Proceedings of the 22nd International Conference on Machine Learning, Bonn, Germany, 2005.
[5] Cao Zhe, Qin Tao, Liu Tieyan, et al. Learning to rank:from pairwise approach to listwise approach[C]∥Proceedings of the 24th International Conference on Machine Learning, Corvallis, Oregon, 2007: 129-136.
[6] Cao Y, Xu Jun, Liu Tieyan, et al. Adapting ranking SVM to document retrieval[C]∥Proceedings of SIGIR2006, Seattle, USA,2006.
[7] Fang Yi, Si Luo, Mathur A. Discriminative models of integrating document evidence and document-candidate associations for expert search[C]∥Proceeding of the 33rd international ACM SIGIR, Geneva, Switzerland, 2010: 683-690.
[8] Baeza-Yates R, Ribeiro-Neto B. Modern information retrieval[M]. New York: Addison Wesley, 1999.
[9] Robertson S E, Walker S, Hancock-Beaulieu M, et al. Okapi in TREC3[C]∥Proceedings of Text Retrieval Conference, Gaithersburg: USA U.S. National Institute of Standards and Technology, 1994: 109-126.
[10] Zhou Dengyong, Weston J, Gretton A, et al. Ranking on data manifolds[C]∥Proceedings of 16th Advances in Neural Information Processing Systems, British Columbia, Canada, 2003: 16-169.
(Edited by Wang Yuxia)
2013- 02- 16
Supported by the National Natural Science Foundation of China (61175068)
TP 391.4 Document code: A Article ID: 1004- 0579(2014)02- 0240- 08
E-mail: ztyu@hotmail.com
杂志排行

Journal of Beijing Institute of Technology的其它文章
- Investigating fatigue behavior of gear components with the acoustic emission technique
- Contour tracking using weighted structure tensor based variational level set
- Consensus problem of multi-agent systems under arbitrary topology
- One-piece coal mine mobile refuge chamber with safety structure and less sealing risk based on FEA
- Three-dimension micro magnetic detector based on GMI effect
- On measured-error pretreatment of bionic polarization navigation