基于GPU加速的音频检索技术
2014-08-05金国平余宗桥郭延文
金国平,余宗桥,郭延文,蒋 和
(1. 南京大学计算机科学与技术系,南京 21004 6;2. 南京师范大学数学科学学院,南京 21004 6)
基于GPU加速的音频检索技术
金国平1,余宗桥1,郭延文1,蒋 和2
(1. 南京大学计算机科学与技术系,南京 21004 6;2. 南京师范大学数学科学学院,南京 21004 6)
由于数字音频数据量极大的特点,采用传统音频检索方法会导致等待时间过长。为加快音频检索时间,提出一种基于GPU加速的数字音频检索方法。利用数字音频的特征将连续的音频划分成等长的多个短时音频段,采用GPU加速算法计算每个短时音频段的特征值,将各段的特征值构成特征矩阵。使用后缀数组的变形算法找出2个特征值序列的公共特征段落集合,并将公共特征段落集合进行精化和整体匹配,从而得出检索结果。实验结果表明,该检索方法的准确率可以达到95%以上,与已有方法相比,可以大幅度地提高检索速度,加速比可以达到10倍以上。
音频检索;GPU加速;后缀数组;音频特征;特征值序列;整体匹配
1 概述
近年来随着多媒体技术的迅猛发展,多媒体数据的数量呈指数增长,音频数据作为多媒体数据的一部分也得到了充分的发展。如何在海量的多媒体数据中找到感兴趣的内容成为了大家关注的焦点,音频数据的检索也不例外。音频检索是指通过对音频特征的分析在对应的音频目标中找出所对应的音频[1]。
目前音频的检索方法主要分为2类:一类是基于内容的音频检索方法,其主要是利用音频的特征,如利用音频的振幅、频率等物理特征,响度、音色等听觉特征和节奏、声纹等语义高层特征进行分类和比较[2-3],该类方法的缺点是技术较为复杂,检索精度难以跨越语义鸿沟的影响[4];另一类方法是基于相识度的方法,又称为固定音频检索,它是指直接利用音频检索音频,不需要识别音效和场景,也不需要提前定义模型和训练,直接提取音频特征进行遍历查找得出检索结果[5-6],这类方法实现简单灵活,检索正确率高,但是存在以下问题:计算代价随着检索目标长度呈正比,检索时间随着检索目标长度增加而呈线性增加。文献[7]中虽然提出将整个检索目标划分为若干个小时段,并将小时段单独检出,但是总的检索时间并没有明显减少。
针对基于相识度的音频检索方法存在的问题,本文提出一种基于GPU加速的音频检索方法。基于GPU的CUDA平台并行提取特征,提高音频检索的速度,并与传统的CPU检索方法进行比较。
2 GPU编程模型与线程结构
GPU通用计算通常采用CPU+GPU的异构模式,由CPU负责执行复杂逻辑处理和事务处理等不适合数据并行的计算,由GPU负责计算密集型的大规模数据并行。通常来说计算将CPU作为主机(host),GPU作为计算设备(device),在一个系统中可以有一个主机和若干个设备,CPU 和GPU各自拥有独立的存储地址空间,协同工作。首先CPU负责数据初始化工作和逻辑性强的事务处理,然后将CPU端的存储数据发送到GPU端,GPU端进行高度并行的数据处理任务,在任务完成好后将存储数据再发送回CPU端[8]。
在GPU端运行的函数称作内核函数(kernel),CPU通过调用内核函数调用GPU,每个内核函数中的线程结构包括工作块(work-grid)和工作单元(work-block)。每个线程有一个唯一的标示符(ID),如果线程逻辑结构是一维的,则其ID表示是线性的;如果线程逻辑结构是二维的,若线程块的大小为(Dx,Dy),则索引号为(x,y)的线程的ID为(x+y·Dx);如果线程逻辑结构是三维的,若线程块的大小为(Dx,Dy, Dz),则索引号为(x,y,z)的线程的ID为(x+y·Dx+z·Dy·Dx),当主机调用内核函数时,work-block被分配到不同的流处理器上,每个work-block中的线程在一个流处理器上执行,当一个线程块结束后,新的线程块将被唤醒并执行。
3 基于GPU加速的音频检索方法
本文提出了一种基于GPU加速的音频检索方法,目的是提高检索的时间,主要分为4个部分:音频分割,音频特征抽取,后缀数组查找以及结果精化和整体匹配。其主要算法流程如图1所示。

图1 基于GPU加速的音频检索算法流程
3.1 音频分割
将待检索的音频p和目标音频q,分别按照其音频的长度划分出长度相等的2组音频数据短时段。其中,待检索音频p划分为短时段集合Cp,Cp={cp1,cp2,…,cpi,…,cpLp},cpi表示短时段集合Cp中第i个音频采样值;1≤i≤Lp,Lp为短时段集合Cp的长度;目标音频q划分为短时段集合Cq,Cp={cq1,cq2,…,cqi,…,cqLq},cqi表示短时段集合Cq中第i个音频数据采样值,1≤i≤Lq,Lq为短时段集合Cq的长度。
3.2 音频特征抽取
对于每一个音频短时段D={P0,P1,…,Pi,…PN},提取其特征值W,N为该音频短时段D的长度。计算该音频短时段D的特征值,将向量D通过通用计算架构(Compute Unified Device Architecture, CUDA)的cudamalloc函数加载到GPU内存中并设置线程块block和线程thread,使得该设置动态最优的适合于向量D={P0,P1,…,Pi,…PN},并用GPU上kernel计算其特征。
查询音频需要提取音频数据的特征值作为比较的目标对象,在音频检索中,所选取的特征应该能够充分表示音频的重要区分度的特征并具有一定的鲁棒性。在音频的特征中,本文选取了以下3种特征来表征音频数据:
(1)响度。比较常用的音频特征,与短时能量密切相关。计算一般是在时域进行的,对每帧数据的采样值求平方和。其计算公式如下:为该特征段的平均采样值。

(2)短时平均过零率。它是指在一个短时帧内,离散采样值由正到负和由负到正变化的次数。单位时间内过零次数称为过零率。一定程度上,它说明了平均信号频率,它是区分音频信号有声或无声的重要标志之一[9]。过零率计算的公式如下:

(3)Mel变换对数倒谱系数(Mel-scaled Frequency Cepstral Coefficient, MF CC)。在表征音频的多种特征中,Mel倒谱系数是一种非常重要的特征参数,它采用一种非线性的Mel频率单位来模拟人耳的听觉系统,充分考虑人耳听觉的非线性特征,去除了因激励影响而引起的音频频谱峰值的波动,在音频检索中取得了非常好的效果[10]。这是音频经过Z变换和对数处理后得出的结果,一般对每帧数据取12个系数,可以很好地表现每帧的特征,计算得到的系数记为Mel[11-13]。Mel倒谱系数的提取流程如图2所示。

图2 Mel倒谱系数提取流程
计算特征段向量D={P0,P1,…,Pi,…,PN}的特征值w的过程分布到每个线程上,特征值 w的计算公式如下:

其中,Pi为音频短时段D上的采样点,N为音频短时段D上的特征点的总数,0≤i≤N;α,β,γ为设定的权值,Energy(D)为音频数据短时段D中采样点的能量信息;Zn(D)为音频数据短时段w中采样点的过零率。
3.3 后缀数组查找
对待检索音频p和目标音频q的短时段计算特征值,得到特征值序列Wp={wp1,wp2,…,wpi,…,wpLp}和特征值序列Wq={wq1,wq2,…,wqj,…,wqLq}。其中,Lp,Lq分别为特征值序列的长度,1≤i≤Lp,1≤j≤Lq;将特征值序列数值设为一个字符,构建字符序列Vw={wp1,wp2,…,wpi,…,wpLp, X, wq1,wq2,…,wqj,…,wqLq},X为隔断标记;构建后缀数组[11],其基本思路是计算Wp的所有后缀和Wq的所有后缀之间的最长公共前缀的长度,把最长公共前缀长度不小于k的部分全部加起来,k为设定的最小检索长度。扫描字符序列Vw={wp1,wp2,…,wpi,…,wpLp,X, wq1,wq2,…,wqj,…,wqLq},每遇到一个Wq的后缀就统计与前面的Wp的后缀能产生多少个长度不小于k的公共子串,这里Wp的后缀需要用一个单调的栈来高效地维护,其算法流程如图3所示。
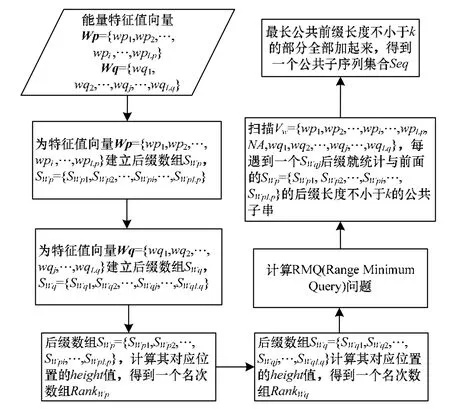
图3 后缀数组变形算法流程
将得到公共子串集合按照位置对应关系得出特征值向量Wp和Wq中对应的公共序列集合Seq;合并整理,将公共交叉的数据段落合并,将连续的部分整理连接得到公共段落集合。
3.4 结果精化和整体匹配
将公共序列集合Seg整理,得到相同区域集合WSeg= {Seg1(p,q), Seg2(p,q),…,Segh(p,q),…,SegLw(p,q)}。其中,Segh(p,q)即为p、q两音频的第h段公共区域,h介于1~Lw之间,Lw为短时音频段相同区域集合的长度;按照顺序将短时音频段相同区域集合进行排序,遍历短时段相同区域集合,若Segs(p,q)和Segt(p,q)存在数据段上交叉,则将其合并,整理得集合WSeg*={Seg1*(p,q),…,Segh*(p,q),…, SegLw*(p,q)};遍历新的集合,如满足下列条件则将其合并:
条件1 若存在Segs*(p,q)和Segt*(p,q)不相邻分别相隔1个短时段cpx、cqx,且Segs*(p,q)中音频p的短时段特征值为wps,音频q的短时段特征值为wqs,Segt*(p,q)中音频p的短时段特征值为wpt,音频q的短时段特征值为wqt,短时段cpx、cqx特征值为wpx、wqx。
条件2 若wps= wqs且wpt= wqt。
条件3 若wpx= wqx或| wpx-wqx|<T,T为阈值。
重复上述合并过程,直至不能合并为止,合并后得到的新的集合即为最简短时段相同区域集合。
4 实验结果和分析
本文实验数据文件有3组,3组文件都来自于Testronic的数据库:
(1)第1组文件是Testronic的shortTest文件,待检索文件是shortTest-Original,长度为190’,目标文件是shortTest-Edit,长度为600 s;
(2)第2组文件是音乐文件,来自Disney的Tangled片段,待检索文件为Tangle-TLR,长度为11’15’,目标文件是Tangle-TLR-Clean,长度为32’11’。
(3)第3组文件是电影文件Disney的Lionking片段,待检索文件是LionKing-C,长度为19’59’,目标文件是LionKing-C-Clean,长度为1°28’45’。
3组测试数据格式都是单声道,采样率为44.1 kHz,量化精度为24 bit。实验时发现将音频分割片段设为5 s,阈值设为0.95时效果较好。
本文使用查全率(RR)、查准率(PR)和时间(T)来评价算法的检索性能,其定义如下:

实验采用的机器配置为Intel Core2、2.80 GHz CPU、4 GB内存、NVIDIA GeForce GT440显卡。表1是对上述3组音频文件进行检索得到的结果。
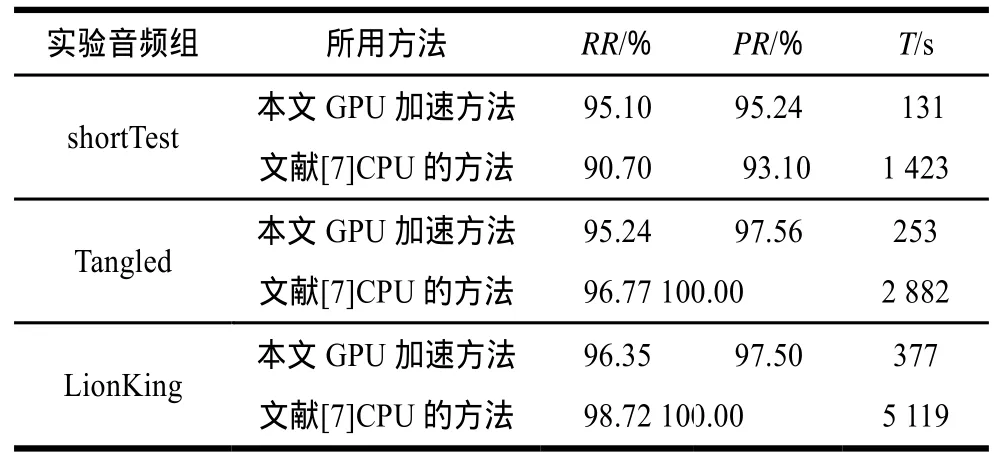
表1 3组文件检索结果
由实验结果可以看出:
(1)在速度方面,使用本文基于GPU加速的检索方法比文献[7]中基于CPU的算法节省了时间,且比较的音频的时间越长,节省的时间越多。shortTest组的加速比为10.86,Tangled组的加速比为11.39,LionKing组的加速比为13.58,可见音频长度越长其加速比越大。这与GPU编程在数据量越大加速比越大是一致的。
(2)在查全率和查准率方面,本文基于GPU加速的检索方法与文献[7]中CPU的算法性能相当,均能保证查全率和查准率在95%以上。
实验的3组数据分别为标准音频测试数据、音乐数据和电影数据,本文方法对这3种数据都有较好的实验结果。这是由于本文方法是通过计算相似性进行检索的,不关心其具体的语义信息,故这种方法可以用来检索任意类型的音频数据。
5 结束语
本文提出了一种基于GPU加速的音频检索方法,利用GPU的并行计算能力减少了音频检索的时间。实验结果验证了该方法的可行性和优越性。音频检索是目前多媒体信息检索领域研究的重点,未来会进一步改进算法结构,如引进更快的查找算法、基于Hash索引的方法[14]、引入模式匹配算法[15]等。本文创新点在于提出的方法首先使用数字音频的特征将连续的音频划分成等长的多个短时音频段,并利用GPU加速算法计算每个短时音频段的特征值,采用后缀数组得出初步检索结果,进一步精化和整体匹配后得到检索结果,提高了检索效率。
[1] Heryanto H, Akbar S, Sitohang B. Direct Access in Contentbased Audio Inf ormation Retrieval: A S tate of th e Art and Challenges[C]//Proc. of International Conference on Electrical Engineering and Informatics. Bandung, Indonesia: [s. n.], 2011: 1-6.
[2] Hansen J H L, Huang Rongqing. Speech Find: Advances in Spoken Docume nt Retrieval for a National Gallery of the Spoken Word[J]. IE EE T ransactions on Sp eech and Audio Processing, 2005, 13(5): 712-730.
[3] Chechil G, Le E, Rehn M, et al. Lar ge Scale Content Based Audio Retrieval from Text Queries[C]//Proc. of the 1st ACM International Conference on Multimedia Information Retrieval. New York, USA: [s. n.], 2008: 105-112.
[4] 齐晓倩, 陈鸿昶, 黄 海. 基于K-L距离的两步固定音频检索方法[J]. 计算机工程, 2011, 37(19): 160-162.
[5] Su J H, W u C W, Fu Shaoyu, et al. Empirical Analysis of Content-based M usic R etrieval for Music Identific ation[C]// Proc. of International Co nference on Multimedia Technology. Hangzhou, China: [s. n.], 2011: 3516-3519.
[6] Jurkas P, S tefin A M, Novak D, et al. Audio Similarity Retrieval Engine[C]//Proc. of the 3rd International Conference on Similarity Search and Applications. Istanbul, Turkey: [s. n.], 2011: 121-122.
[7] Kashino K, Kurozumi L, Murase H. A Quick Search Method for Audio and Video Signals Based on Histogram Pruning[J]. IEEE Transactions on Multimedia, 2003, 5(3): 348-357.
[8] 谈会星, 陈福才, 李邵梅. 基于模板子空间的快速固定音频检索方法[J]. 计算机工程, 2012, 38(20): 260-263.
[9] K edem B. Spectral Analysis and Discrimination by Zerocrossings[J]. Pro ceedings of the IEEE, 1986, 74(11): 147 7-1493.
[10] Li S Z. Content-based Classification and Retrieval of Audio Using the Nearest Feature Line Method[J]. IEEE Transactions on Speech Audio Processing, 2000, 8(5): 619-625.
[11] Johnson S E, Woodland P C. A Method for Direct Audio Search with Application to Indexing and Retrieval[C]//Proc. of IEEE International Co nference o n Acoustics, Spee ch and Signal Processing. New York, USA: [s. n.], 2000: 1427-1430.
[12] 江星华, 李 应. 基于LPCMCC的音频数据检索方法[J].计算机工程, 2009, 35(11): 246-247, 253.
[13] Manber U, Myers G. Suffix Arrays: A New Method for On-line String Searches[C]//Proc. of the 1st Annual ACM-SIAM Symposium on Discrete Algorithms. Philadephia, USA: [s. n.], 1990: 319-327.
[14] Gionis A, I ndyk P, Mot wani R. Similarity Search in High Dimensions via Hashing[C]//Proc. of the 25th International Conference on Very Large Data Bases. San Francisco, USA: [s. n.], 1999: 518-529.
[15] Cheng Deyuan, Gersho A, Rama murthi B, e t al. Fast Search Algorithm for Vector Quantization and Pattern Mat ching[C]// Proc. of IEEE International Conference on Acoustics, Speech and Signal Processing. San Diego, USA: [s. n.], 1984: 372-375.
编辑 顾逸斐
Audio Retrieval Technology Based on GPU Acceleration
JIN Guo-ping1, YU Zong-qiao1, GUO Yan-wen1, JIANG He2
(1. Department of Computer Science and Technology, Nanjing University, Nanjing 210046, China; 2. School of Mathematical Sciences, Nanjing Normal University, Nanjing 210046, China)
As digital audio has a feature of great data volume, traditional audio retrieval method results are used in intolerable response time. In order to speed up audio retrieval, this paper proposes a GPU acceleration audio retrieval method. The audio is divided into multiple short audio segments based on the features, and the characteristic matrix is constituted by the eigenvalues which is calculated from e ach short audio segment using the GPU acceleration algorithm. The suffix array deformation algorithm is used to find the common set from the two eigenvalues sequence. The common set is refined and overall matched to get the retrieval resu lt. Experimental re sults show that the retrieval accuracy is over 95% and compared with existing algorithms, this method can significantly improve the retrieval speed and speedup can be achieved in more than 10 times.
audio retrieval; GPU acceleration; suffix array; audio characteristic; eigenvalue sequence; overall match
10.3969/j.issn.1000-3428.2014.05.055
国家自然科学基金资助项目(61073098, 61021062);国家“973”计划基金资助项目(2010CB327903);江苏省自然科学基金资助项目(BK2009081)。
金国平(1988-),男,硕士研究生,主研方向:多媒体信息检索;余宗桥,硕士研究生;郭延文(通讯作者),副教授、博士、CCF会员;蒋 和,本科生。
2013-04-15
2013-05-15E-mail:ywguo@nju.edu.cn
