基于方向信息的随机蕨特征匹配算法
2014-08-05孙博文邱子鉴张艳鹏
孙博文,邱子鉴,沈 斌,张艳鹏
(哈尔滨理工大学 a. 计算中心;b. 计算机科学与技术学院,哈尔滨 1 50080)
基于方向信息的随机蕨特征匹配算法
孙博文a,邱子鉴b,沈 斌b,张艳鹏a
(哈尔滨理工大学 a. 计算中心;b. 计算机科学与技术学院,哈尔滨 1 50080)
特征点匹配是计算机视觉领域研究的核心问题之一。现有的随机蕨算法具有简单、高速的优点,但随机蕨算法训练得到的分类器体积过大,低内存的移动设备难以承受,严重限制了该算法的应用范围。针对该问题,提出一种基于方向信息的随机蕨特征匹配算法,对用于训练的小图块进行“归零化”处理,提取特征属性构造特征向量,建立朴素贝叶斯模型训练分类器。实验结果表明,经过该方法处理后,在相近识别精度下,得到的分类器体积减小到原始算法的1/8~1/16,满足实时性要求。
随机蕨;特征匹配;增强现实;模式识别;贝叶斯模型;方向蕨
1 概述
尺度不变性特征变换(Scale-invariant Feature Transform, SIFT)[1]特征点检测器和描述器是十几年前提出的算法,但是它在图像识别、图像匹配等领域中有着广泛的应用。然而,对于实时性要求高的系统,或者计算能力低的设备来说,SIFT的算法复杂度过大,无法满足要求,这很大程度地限制了该算法的应用范围。为降低图像匹配算法的计算复杂度,世界各国学者提出了许多改进算法,其中,快速稳健性特征(Speeded up Robust Features, SURF)[2]算法是公认的高效算法之一,该算法在保持SIFT高特异性的基础上,加速了局部特征点的获取与匹配,然而,仍不能满足实时性的要求。随着计算机硬件性能的不断提升,一些基于图像处理器(Graphic Processing Unit, GPU)的算法相继提出,如GPU-SIFT[3]和GPU-SUFR[4],这些算法充分利用了GPU并行处理的优势,很大程度地提高了算法的效率,对于高性能的GPU,这些算法可以实现对图像的实时处理。但是这类算法对GPU依赖过大,限制了算法的应该范围。由Willow G arage大学研究人员[5]提出的ORB(Oriented Brief)算法,结合简单高速的加速区域分割(Features from Accelerated Se gment Test, F AST)[6]检测器及二元鲁棒独立特征描述算子( Binary Robust In dependent E lementary Fe atures, BRIEF)[7],执行速度比SIFT快2个数量级,比SURF快1个数量级。但是由于FAST特征点不包含尺度信息,因此ORB算法对尺度的鲁棒性较差。
以上提及的算法都是基于文献[8]的理论构造的框架:(1)局部特征提取;(2)对特征进行不变性描述;(3)特征匹配;(4)基于外极几何约束,求得两图像间的对应关系。为降低运算量,文献[9-10]提出随机蕨(Random Fern)算法,把图像匹配视为分类问题,利用朴素贝叶斯分类算法对局部图像(小图块)进行分类。随机蕨算法相对与SIFT,具有计算量小,鲁棒性高的优势。然而,随机蕨产生的分类器较大,消耗内存严重。
在随机蕨特征匹配过程中,首先采集目标图像的特征点(又称角点),以特征点为中心,在31×31的邻域(小图块)内,随机抽取数10个点对提取位特征(binary feature),作为待分类项的特征属性[11]。一个训练集包含着目标图像的各种仿射变换,采取这种没有考虑到小图块方向的方式,忽略了不同方向的同一小图块之间的联系——通过“归一化”处理,可以旋转小图块到“零”方向。显然,以这种方式提取的特征属性会影响分类器的质量,降低分类器的识别率。为解决这一问题,本文提出一种基于方向信息的随机蕨特征匹配算法,在提取位特征之前,对小图块进行“归一化”处理,降低随机蕨丛的无向性对分类结果的影响。为与原始随机蕨算法加以区别,本文算法命名为OFern。
2 基于方向信息的随机蕨特征识别与匹配
随机蕨算法采用机器学习算法中的贝叶斯分类模型处理特征识别与匹配问题,将计算量庞大的特征不变性描述和特征匹配过程转移由分类器处理。本文采用基于方向信息的随机蕨特征,利用朴素贝叶斯分类模型,通过离线训练分类器和在线识别2个阶段实现特征的分类及匹配[12]。尽管算法增加了特征点方向信息的计算所需的系统开销,但是利用包含有方向信息的特征向量所训练的分类器,分类器识别率明显高于原始算法。并且实验结果证明,计算特征点方向的算法可满足实时性要求。
2.1 灰度重心
矩特征主要表征了图像区域的几何特征,又称为几何矩,由于其具有旋转、平移、尺度等特性的不变特征,因此又称其为不变矩[13]。本文利用从小图块的中心在它的灰度重心的向量,计算出该小图块的方向。在文献[14]中,用图像矩来计算小图块的灰度重心,公式定义如下:

其中,I( x, y)代表在点(x, y)处的图像灰度值。一阶矩用于确定图像质心,即:

如果用O代表小图块的中心,那么从中心到重心的向量为OC,则该小图块的方向可以表示为:

目前,有许多计算图像方向的方法,在文献[5]中,研究人员将该方法与其他2种基于梯度的方法进行了比较。他们的结果显示,在较大图像噪声的情况下,基于图像矩的方法计算得到的方向更为稳定。
2.2 朴素贝叶斯分类模型
在随机蕨特征匹配过程中,首先采集目标图像的特征点(角点),以特征点为中心,选取31× 31的邻域块(小图块),作为识别与分类的基本单位。为获得丰富且全面的训练集,系统会模拟出大量的仿射变换图像,并为图像添加高斯噪声。以同一特征点为中心生成的各种小图块看作一类,ci, i=1,2,…,N ,所有的类别记作N。位特征用gj表示,位特征计算公式如下:

其中,dj1和dj2表示在小图块I中的2个点(测试点对)。
由于旋转小图块后再根据上式计算位特征与旋转这个测试点对,再计算位特征的方式等价,并且前者需要遍历小图块内所有像素,后者只需要旋转2个点,计算复杂度明显低于前者,则旋转公式如下:
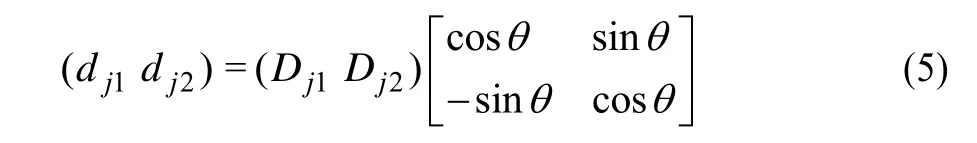
其中,Dj1和Dj2是在小图块中随机选取的2个位置,称为基准测试点对。θ由式(3)计算得到。分类问题用下式描述:
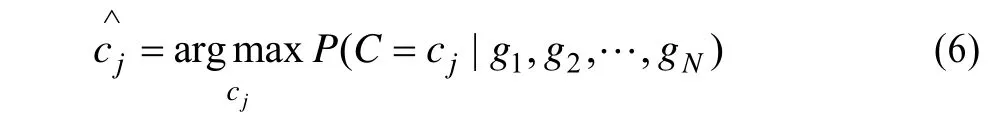
其中,C表示随机的某一个类。
根据贝叶斯公式,可将上式分解成:

由于先验概率P( C=ci)与分母P( g1, g2,…,gN)均为常数,因此式(6)可等价于:

随后将N个特征分为大小为S的M个组,每一个组叫做“蕨”。则式(7)可表示为:

根据以上朴素贝叶斯分类模型的相关公式,通过由计算机生成的训练样本集来训练分类器。
2.3 分类器离线训练
一个完善的分类器需要对图像光照变化、投影形变、图像模糊以及图像噪声具有较强的稳健性。这里利用仿射变换模拟出不同尺度、不同视角下的图像样本集合。对生成的图像人为地添加高斯噪声,以提高分类器对噪声的鲁棒性。然后从形变图像中提取特征点,利用逆仿射变换计算出特征点在模板图像中对应的坐标,选取特征点出现次数最多的前N个,每一个特征点记作一个类。
在原始的随机蕨算法中,通过在小图块内随机选取测试点对的方式,获得位特征属性。然而,采用这种方法,对于仅方向不同的小图块提取到的位特征属性会有很大差别,影响分类器的性能。考虑以上原因,本文引入图像矩的思想,通过一阶矩来计算图像的灰度重心,以图像的中心到重心的向量作为该图像的方向,然后进行图像“归一化”处理。在理想状态下,从经过处理后的小图块中,随机选取测试点对,仅方向不同的小图块的位特征应当相同。虽然,额外添加了图像“归一化”环节,使算法复杂度增加,但是实验表明,在相同的参数设置下,基于方向信息的随机蕨算法的识别率明显高于原始算法。
离线训练分类器的主要目的是,根据训练样本中每个类别下的各个蕨出现的频率估计各每个蕨的条件概率。条件概率P( Gm|C=ci)计算公式如下:
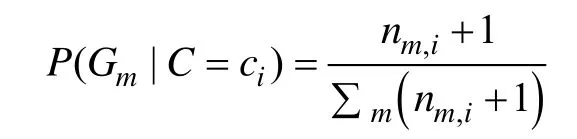
其中,nm, i表示在类别ci中第m个蕨的样本个数;分母为在类别ci中所有的训练样本数。
2.4 实时特征识别
在实时特征识别阶段,从图像采集设备上得到的图像中,提取特征点,以特征点为中心的31×31的邻域块(小图块)作为待分类项,根据2.2节中相关公式,旋转基测试点对,获得每一个小图块的位特征属性,用于后验概率的计算。根据位特征属性,从分类器中检索出对应的各个的类别后验概率,其中,后验概率最大的类别为该待分类项,进而实现了模板特征点与输入图像的特征点的识别与匹配,如图1所示。

图1 模板图像有效识别及定位
3 实验结果与分析
为对算法的识别率及运行速率等性能进行验证,使用如图2所示的2幅图像,分辨率分别为640×480、320×240,作为模板图像,在相同参数设置线,比较随机蕨与本文算法的性能指标。

图2 模板图像
3.1 识别率比较
训练分类器过程中使用随机生成仿射图像(10 0 00张)来训练分类器,用随机生成的200张图像验证生成的分类器的识别率。在随机蕨算法中,影响分类器性能的有如下参数:类的数量,蕨的个数以及每个蕨中测试点对的多少。图3~图5为在不同参数下随机蕨算法与本文算法在识别率上的比较。

图3 不同参数下分类器识别率变化比较1
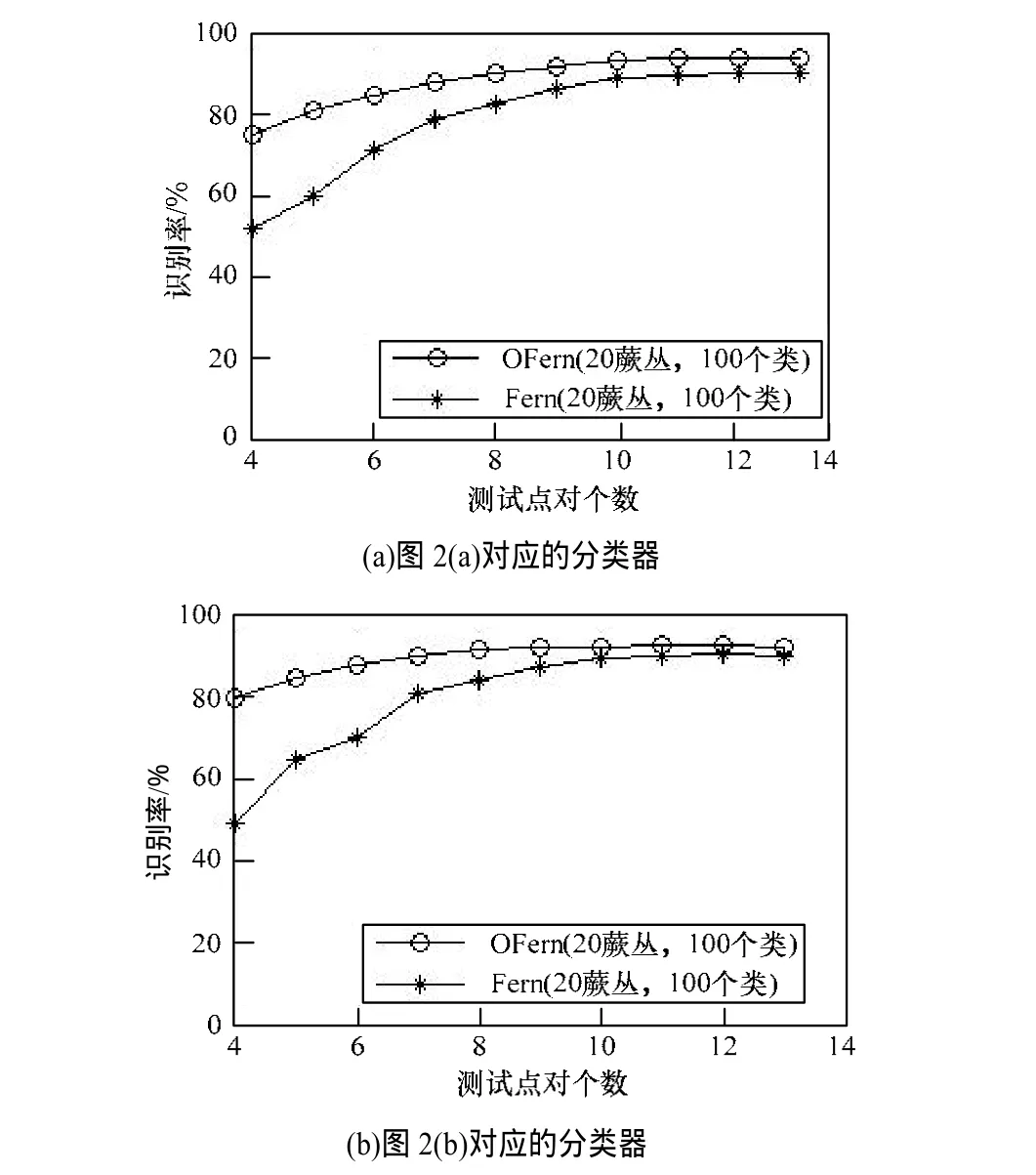
图4 不同参数下分类器识别率变化比较2
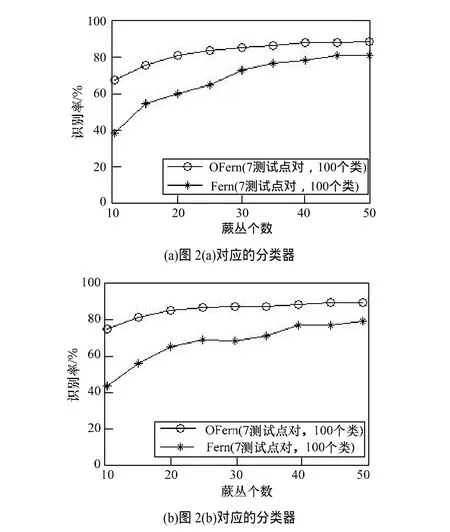
图5 不同参数下分类器识别率变化比较3
其中,图3为确定蕨个数与每个蕨中测试点对个数不变,随着类数量变化分类器识别率变化比较。图4为确定蕨个数与类数量不变,随着每个蕨中测试点对的个数不同分类器识别率变化比较。图5为确定每个蕨中测试点对个数与类数量不变,随着蕨个数变化分类器识别率变化比较。
如图3所示,尽管随着类的个数增加,识别率有所下降,但是本文算法的分类器识别率始终优于随机蕨算法。而且分类器的识别率也更加稳定。实验结果显示,本文算法可以处理更多的特征点。
图4和图5数据说明,随着蕨个数与每个蕨中测试点对的个数的增加,本文算法的识别率明显高于随机蕨,尤其是在蕨个数与每个蕨中测试点对的个数都较小的情况下,本文算法的识别率约是随机蕨算法的2倍。因此,可以在识别率较高的情况下,获得更小的分类器。
3.2 分类器大小比较
由于随机蕨算法生成的分类器通常较大,十分消耗内存资源,因此本文针对此问题提出了基于方向信息的随机蕨的改进方法。在相近识别率的条件下,原始算法与本文算法生成的分类器体积比较如表1所示。

表1 相近识别率下分类器体积大小的比较
其中,分类器的体积用classes × 2sizes× ferns 表示。
由表1可见,在较高识别率下,本文算法生成的分类器体积明显小于原始算法,验证了本文算法的有效性。
为达到稳定的识别效果,本文算法参数选取分别为:类的数量为100,每个蕨中测试点对的个数为7,蕨个数为20。则相应的分类器大小为500 KB(100×27×20×2 Byte/ 1 024),对于如今的智能手机而言,可轻松处理。
3.3 运行时间测试
对于实时性要求较高的应用,如增强现实,对算法的运行时间有着严格的限制。一般而言,图像每帧能够在30 ms内处理完毕,其图像序列在视觉效果上会比较流畅。随机蕨算法的主要优势在于它的实时性,对于640×480大小的图像,它的运行时间是20 ms/帧。
本文采用[6]提供的测试视频,测试机器配置为:AMD Athlon II X2处理器,2.69 GHz主频,2 GB内存。对于此测试视频,本文算法的平均处理时间为20 m s/帧,完全可以满足实时性的要求。
4 结束语
本文提出一种基于方向信息的随机蕨特征匹配算法,OFern。利用灰度重心公式,对用于训练的小图块进行“归零化”处理,使得理想状态下,仅方向不同的小图块提取得到的特征属性相同,该方法有效地解决了方向变化对随机蕨性能的影响。实验结果证明,经过该方法处理后,在相近识别精度下,可以大幅降低分类器的体积,并且算法依然保持着良好的实时性能。随着移动设备硬件的不断更新升级,使得在移动平台上实现实时、高精度的图像匹配成为可能。因此,下一阶段工作将尝试移植该算法到移动设备上,测试其性能,并结合GPU的并行处理优势,进一步优化算法。
[1] Lowe D G. Object Rec ognition from Local Scale-invariant Features[C]//Proceedings of the 7th IEEE In ternational Conference on Computer V ision. [S. 1.]: IEEE Press, 1999: 1150-1157.
[2] Bay H, Tuytelaars T, van Gool L. Surf: Speeded up Robust Features[C]//Proceedings of ECCV’06. Berlin, Germany: Springer, 2006: 404-417.
[3] Rublee E, Rabaud V, Konolige K, et al. ORB: An Efficient Alternative to SIFT or SURF[C]//Proceedings of the 7th IEEE International Conference on Computer Vision. [S. 1.]: IEEE Press, 2011: 2564-2571.
[4] Cornelis N, van Gool L. Fast Scale Invariant Feature Detection and Matching on Programmable Graphics Hardware[C]// Proceedings of CVPR’08. [S. 1.]: IEEE Press, 2008: 1-8.
[5] Terriberry T B, French L M, Helmsen J. GPU Accelerating Speeded-up Robust Features[C]//Proceedings of the 4th International Symposium on 3D Data Processing, Visualization and Transmission. [S. 1.]: IEEE Press, 2008: 355-362.
[6] Rosten E, Drummond T. Machine Learning for High Speed Corner Detection[C]//Proceedings of European Conference on Computer Vision. [S. 1.]: IEEE Press, 2006: 430-443.
[7] Calonder M, Lepetit V, Strecha C, et al. BRIEF: Binary Robust Independent Elementary Features[M]. Berlin, Germany: Springer, 2010.
[8] Schmid C, Mohr R. Local Gray Value Invariants for Image Retrieval[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1997, 19(5): 530-535.
[9] Ozuysal M, Calonder M, Lepetit V, et al. Fast Keypoint Recognition Using Random Ferns[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2010, 32(3): 448-461.
[10] Ozuysal M, Fua P, Lepetit V. Fast Keypoint Recognition in Ten Lines of Code[C]//Proceedings of IEEE Conference on Computer Vision and Pattern Recognition. [S. 1.]: IEEE Press, 2007: 1-8.
[11] 李 珍, 江贵平. 基于条件互信息量的随机蕨特征匹配算法[J]. 计算机工程与设计, 2012, 33(5): 1908-1912.
[12] 陈 冰, 赵亦工, 李 欣. 基于随机蕨的光电成像末端制导目标初始化[J]. 光学学报, 2010, 30(11): 19-22.
[13] Wikipedia Contributors. Moment(Mathematics)[EB/OL]. (2013-04-14). http://en.wikipedia.org/w/index.php?title=Moment_ (mathematics)&oldid=550315652.
[14] Rosin P L. Measuring Corner Properties[J]. Computer Vision and Image Understanding, 1999, 73(2): 291-307.
编辑 索书志
Random Fern Feature Matching Algorithm Based on Orientation Information
SUN Bo-wena, QIU Zi-jianb, SHEN Binb, ZHANG Yan-penga
(a. Compute Center; b. School of Computer Science and Technology, Harbin University of Science and Technology, Harbin 150080, China)
Feature point matching is a key base of many computer vision problems. A large advantage of fern algorithm, simple and fast, is noticed among the existing algorithms, but classifier trained by fe rn is too lar ge to low memory device, such as cellphones. For cutting down the size of a classifier, this paper proposes an improved version of fern, n amed Oriented Fern(OFern), which “normal” patches are done that training for a classifier, and features are extracted, a Naive Bayesian model is built to train a classifier. Experimental results show that compared with the traditional fern, OFern can save memory to 1/8~1/16 at the similar recognition rate, while it still keeps high speed for real-time applications.
Random Fern(RF); feature matching; augmented reality; pattern recognition; Bayes model; Oriented Fern(OFern)
10.3969/j.issn.1000-3428.2014.05.040
孙博文(1963-),男,副教授,主研方向:模式识别,虚拟现实,增强现实;邱子鉴、沈 斌,硕士研究生;张艳鹏,硕士。
2013-04-23
2013-06-10E-mail:949868412@qq.com
1000-3428(2014)05-0192-04
A
TP18
