Hadoop平台数据访问监控机制研究
2014-08-04王玉凤梁毅金翊李光瑞
王玉凤,梁毅,金翊,李光瑞
1.北京工业大学计算机学院,北京 100124
2.北京市计算中心,北京 100094
Hadoop平台数据访问监控机制研究
王玉凤1,梁毅1,金翊2,李光瑞1
1.北京工业大学计算机学院,北京 100124
2.北京市计算中心,北京 100094
WANG Yufeng,LIANG Yi,JIN Yi,et al.Data access monitoring mechanism in Hadoop platform.Computer Engineering and Applications,2014,50(22):43-49.
1 引言
全球信息化推动大数据时代的到来。海量数据处理技术在网络服务、科学计算、生物工程等各个领域得到广泛应用[1-4]。Hadoop开源数据处理平台是海量数据处理领域的最新技术进展,提供新型Map/Reduce并行计算模型及其运行时环境[5-7]。Hadoop平台中Map/Reduce并行作业可由多个Map任务和Reduce任务组成。Map任务首先完成输入数据的形变或过滤,然后Reduce任务完成数据归约。
数据访问监控是海量数据处理平台保障数据可用和优化数据存取效率的主要依据[4]。与传统数据处理平台相比,Hadoop平台所提供的运行时环境支持海量数据基于计算节点分布存储,Map任务调度通过感知数据的分布信息实现数据本地化处理,从而提高作业执行效率[5]。显然,数据分布和访问情况成为了Hadoop平台中任务调度需考虑的影响因素,这使得Hadoop平台中数据不仅作为存储对象存在,还成为任务调度需感知的资源。因此,本文提出Hadoop平台中数据访问监控不仅服务于数据存取效率的提升,还应服务于Map/Reduce并行作业执行效率提升的基本思想。同时,在Map/Reduce作业中,Map任务处理的数据规模往往占有较大比例[8]。因此,本文的工作主要围绕Hadoop平台中Map任务数据访问监控机制展开,提出了服务于并行作业执行效率的目标,Hadoop平台数据访问监控应增加对并行执行的多Map任务数据访问开销均衡性的监控。本文的主要贡献如下:
(1)定义了Hadoop平台数据访问监控的粒度和监控信息的组成。以物理数据块作为数据访问监控的基本粒度,监控信息主要包括物理数据块静态属性信息、物理数据块动态访问事件信息、逻辑文件块访问热度信息和文件访问并行度及均衡度信息。其中,文件访问并行度及均衡度信息体现了并行执行的多Map任务数据访问开销的均衡性。
(2)给出了Hadoop平台数据访问监控体系结构。依托Hadoop平台现有结构,采用基于master-slave结构,由一个用于数据访问监控信息汇总与统计的功能模块(master)和多个具有监控信息收集能力的功能模块(slave)构成。slave模块进行物理数据块静态属性信息和物理数据块动态访问事件信息收集;master模块进行slave模块收集信息的汇总,统计形成逻辑文件块访问热度信息和文件访问并行度及均衡度信息,并实现对上述信息的存储。
(3)给出了Hadoop平台数据访问监控机制具体实现技术。通过对Hadoop源代码进行插桩,以在Hadoop已有框架上增加新的线程的形式实现各监控功能模块;监控信息收集线程基于socket通信,周期性将监控信息发送到监控信息汇总与统计线程;并给出逻辑文件块访问热度信息和文件访问并行度及均衡度信息的统计计算方法。
2 Hadoop平台数据访问需求分析
图1给出了传统平台与Hadoop平台架构的差异。传统数据处理平台中,数据基于后端存储集中存放,计算资源和存储资源在部署和管理上相对独立。调度模块根据作业对计算资源的需求进行任务调度。而Hadoop平台中数据基于计算节点分布存储,任务调度不仅需要获取计算资源的状态信息,而且需要通过感知数据的分布信息,来实现数据的本地化处理,进而提升Map/Reduce并行作业的执行效率。这意味着Hadoop平台中数据不仅是存储对象,还应作为调度资源存在。因此,Hadoop平台中数据访问监控信息不仅服务于数据存取效率(如数据访问响应时间等)的提升,还应服务于任务调度需求,提升Map/Reduce并行作业执行效率(如作业响应时间等)。
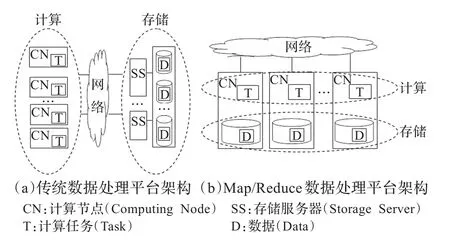
图1 传统数据处理平台与Map/Reduce数据处理平台架构比较
如图2所示,Hadoop平台中Map/Reduce作业的数据处理过程被抽象为Map和Reduce阶段。其中,Map任务处理的数据规模往往占有较大比例,而Reduce阶段以Map阶段处理结果作为输入数据,需等待所有Map任务结束后才开始执行。而大数据场景下,数据读取开销往往占据Map任务执行时间的相当比重,这使得均衡的数据访问开销成为保障并行执行的多Map任务执行效率的对称性,减少后续Reduce任务启动等待时间,进而提升Map/Reduce作业执行效率的关键因素之一。图3给出示例,虽然(a)、(b)方案具有相同的数据访问平均响应时间,但在(a)方案中,由于隶属于同一作业的多个并行Map任务数据访问开销存在差异,导致其Map/Reduce并行作业执行效率低于方案(b)。
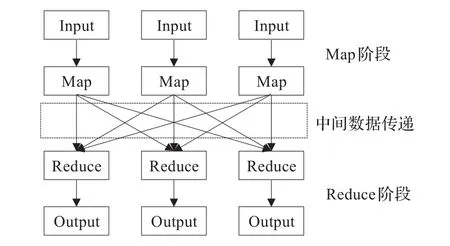
图2 Hadoop平台并行计算模型
因此,在Hadoop平台数据访问监控中,应增加对并行执行的多Map任务数据访问开销均衡性信息的监控,以满足数据作为调度资源这一新角色的需求。


图3 Map任务数据访问开销均衡性对作业执行效率的影响
3 Hadoop平台数据访问监控信息的组成与定义
通常而言,数据处理平台的数据访问监控信息包含两类:数据静态属性信息和数据动态访问信息。其中,数据静态属性信息主要包括数据的存储、归属等静态配置信息;数据动态访问信息则包含平台运行时数据动态访问事件相关的信息。各类数据处理平台根据其不同的服务目标,定义数据访问监控的粒度以及上述两类监控信息的具体组成。
在Hadoop平台中,任一文件由多个逻辑文件块组成,每个逻辑文件块在物理存储上对应多个互为副本的物理数据块(通常以独立小文件的形式存放)。Hadoop平台中,作业通常以全文件为单位进行数据处理(即需要处理一个数据文件中的全部数据),而构成作业的多个Map任务通常处理文件所包含的一个或多个物理数据块。在这种文件组织结构和访问模式下,本文选择物理数据块作为数据访问监控的基本粒度。
以物理数据块为基本粒度,数据静态属性信息被定义为物理数据块的静态属性信息,主要包括物理数据块所属文件信息和物理数据块的存储节点信息。上述信息可满足在优化平台数据存取效率及作业执行效率时,对基本数据存储单元以及数据处理单元的快速定位。
服务于提升数据存取效率和作业执行效率的目标,对数据动态访问信息的定义包含三个部分:物理数据块动态访问事件信息、逻辑文件块访问热度信息以及文件访问并行度及均衡度信息。其中,物理数据块动态访问事件信息是指Map任务对物理数据块的一次访问所包含的信息。物理数据块动态访问事件信息作为数据访问的基础监控信息,为其他两类数据动态访问信息的监控提供依据。逻辑文件块访问热度信息则是在物理数据块动态访问事件信息的基础上,通过统计逻辑文件块所对应多个物理数据块副本被访问次数的均值和方差获得。逻辑文件块访问热度信息可服务于提升数据存取效率,为定位数据访问瓶颈提供依据。
数据动态访问信息中的文件访问并行度及均衡度信息则服务于Hadoop平台提升作业执行效率的新需求。文件访问并行度信息被定义为文件所包含的物理数据块被Map/Reduce作业所包含的Map任务并发访问的数量。文件访问均衡度信息则被定义为Hadoop平台中作业所包含多个并行执行的Map任务对物理数据块访问开销的方差。根据定义可知,通过对文件访问均衡度的监控,可感知Map/Reduce作业中Map任务数据访问开销的差异,定位影响Map任务并行执行效率的文件;而通过文件访问并行度的监控,则为物理数据块的重分布等优化方案提供量化依据,进而提升Map/Reduce并行作业的执行效率。
4 Hadoop平台数据访问监控体系结构
Hadoop平台由一个管理节点(master)节点和多个计算节点(slave)组成。Hadoop平台中的海量数据管理是由NameNode模块和DataNode模块完成的。其中,NameNode模块部署于管理节点,负责数据文件元数据信息的存储和管理,DataNode模块则驻留在各计算节点,负责本地数据的存储并实现数据块的读、写操作。
图4给出Hadoop平台数据访问监控的体系结构以及与Hadoop平台既有模块间的交互关系。其中,白色方框模块表示数据访问监控相关模块,灰色方框模块则表示Hadoop平台的既有模块(为使图4更简洁明了现有Hadoop平台中既有模块间通信并没有在图中给出)。由图4可知,Hadoop平台数据访问监控采用master-slave结构,即由一个用于数据访问监控信息汇总与统计的功能模块和多个具有监控信息收集能力的功能模块构成[9]。其中,监控信息收集模块的主要功能是获取物理数据块的静态属性信息和物理数据块的动态访问事件信息;数据访问监控信息汇总与统计模块的主要功能包括汇总监控信息收集模块收集的信息,统计形成逻辑文件块访问热度信息和文件访问并行度及均衡度信息,并实现对上述信息的存储。
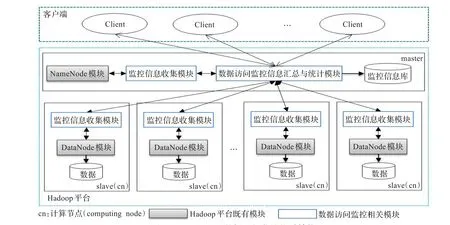
图4 Hadoop平台数据访问监控体系结构
在实际部署中,监控信息收集模块部署于管理节点及所有计算节点上。部署于管理节点的监控信息收集模块负责与NameNode模块交互,周期性获取物理数据块静态属性信息,并将信息发送到数据访问监控信息汇总与统计模块。部署于各计算节点的监控信息收集模块则负责与该节点上的DataNode模块交互,实时收集Map任务对物理数据块的动态访问事件信息,并将数据块动态访问事件信息周期性地发送到数据访问监控信息汇总与统计模块。数据访问监控信息汇总与统计模块可部署于管理节点或独立的第三方节点,数据访问监控信息汇总与统计模块接收各监控信息收集模块发送的信息,并以物理数据块静态属性信息和物理数据块动态访问事件信息为依据,统计形成逻辑文件块访问热度信息和文件访问并行度及均衡度信息;数据访问监控信息汇总与统计模块将收集所得以及统计所得的监控信息以独立文件的形式存储于监控信息库中。
5 Hadoop平台数据访问监控的具体实现
5.1 数据访问监控信息的描述形式
本文设计的Hadoop平台数据访问监控中的监控信息,包括物理数据块静态属性信息、物理数据块动态访问事件信息、逻辑文件块访问热度信息和文件访问并行度及均衡度信息,分别以独立文件的形式存储于监控信息库中。以下给出各类监控信息的描述形式。
(1)物理数据块静态属性信息
物理数据块静态属性信息以四元组<TimeStamp, File,BlockID,Host>描述。其中TimeStamp为时间戳,即获取物理数据块静态属性信息的时刻点,File为物理数据块从属文件路径信息,BlockID为物理数据块对应逻辑文件块的标识信息,Host为物理数据块所在计算节点IP信息。
(2)物理数据块动态访问事件信息
物理数据块动态访问事件信息以六元组<StartTime,EndTime,BlockID,Host,TaskID,JobID>描述。其中StartTime、EndTime均为时间戳,分别表示Map任务开始访问物理数据块和结束访问物理数据块的时刻点,BlockID为物理数据块对应逻辑文件块的标识信息,Host为物理数据块所在计算节点IP信息,TaskID为Map任务的标识信息,JobID为Map任务从属的Map/ Reduce作业的标识信息。
(3)逻辑文件块访问热度信息
逻辑文件块访问热度信息以五元组<TimeStamp,File,BlockID,Mean,Variance>描述。其中TimeStamp为时间戳,即记录逻辑文件块访问热度信息的时刻点,File为逻辑文件块所属文件路径信息,BlockID为逻辑文件块的标识信息,Mean为逻辑文件块所对应多个物理数据块副本被访问次数均值信息,Variance为逻辑文件所对应多个物理数据块副本被访问次数方差信息。
(4)文件访问并行度及均衡度信息
文件访问并行度及均衡度信息以四元组<TimeStamp,File,ParallelismDegree,BalanceDegree>描述。其中TimeStamp为时间戳,即记录文件访问并行度及均衡度信息的时刻点,File为文件路径信息,ParallelismDegree为文件访问并行度信息,BalanceDegree为文件访问均衡度信息。
5.2 监控信息收集模块
监控信息收集模块部署于管理节点及所有计算节点上,分别实现收集物理数据块静态属性信息和物理数据块动态访问事件信息的功能。
(1)收集物理数据块静态属性信息
Hadoop平台中数据文件的元数据信息主要包括文件包含的物理数据块信息,不同计算节点拥有的物理数据块信息。元数据信息由NameNode模块负责存储和管理。物理数据块静态属性信息收集模块、NameNode模块均表现为独立的线程。NameNode线程启动时,实例化物理数据块静态属性信息收集线程,之后物理数据块静态属性信息收集线程开始执行。物理数据块静态属性信息收集线程周期性从NameNode线程拉取物理数据块静态属性信息,并使用socket通信机制将物理数据块静态属性信息发送到数据访问监控信息汇总与统计模块。
(2)收集物理数据块动态访问事件信息
Map任务在访问物理数据块时,建立与特定DataNode模块的socket连接,然后进行数据传输。为抓取物理数据块的动态访问事件信息,在DataNode模块接收到读物理数据块请求时,在现有读物理数据块操作执行前,首先将物理数据块动态访问事件信息发送给物理数据块动态访问事件信息收集模块。物理数据块动态访问事件信息收集模块、DataNode模块均以线程的方式运行。DataNode线程启动时实例化物理数据块动态访问事件信息收集线程,之后物理数据块动态访问事件信息收集线程开始执行。DataNode线程将物理数据块动态访问事件信息实时发送到物理数据块动态访问事件信息收集线程,物理数据块动态访问事件信息收集线程使用socket通信机制周期性地将物理数据块动态访问事件信息发送到数据访问监控信息汇总与统计模块。
由于DataNode线程提供的访问物理数据块的接口不只服务于Map任务读取输入数据的操作,对于其他读取物理数据块的操作,如读取运行作业的jar文件、xml文件和split文件,均通过相同的接口完成。因此,需要区分不同的读物理数据块操作,只抓取Map任务执行时读取输入数据的操作。采用的方法为针对每个发送到DataNode线程的读数据请求,根据请求中包含的Client值进行区分。Map任务发送给DataNode线程的Client值为:DFSClient_taskID,而其余读请求发送的Client值为:DFSClient_整型随机数,因此通过Client值的不同捕捉到执行Map任务时读取物理数据块的请求。
5.3 数据访问监控信息汇总与统计模块
监控信息收集模块周期性地将监控信息发送到数据访问监控信息汇总与统计模块。数据访问监控信息汇总与统计模块以线程的方式运行,并启动两个子线程。两个子线程根据父线程最新接收到的物理数据块静态属性信息和物理数据块动态访问事件信息分别统计计算逻辑文件块访问热度信息和文件访问并行度及均衡度信息。
(1)统计逻辑文件块访问热度信息
对于逻辑文件块访问热度信息的计算,首先根据Host和BlockID项对所获得的物理数据块动态访问事件信息进行分组,确保每个分组中的事件记录具有相同的Host和BlockID项值,则每个分组内包含的事件记录总数,即为由BlockID和Host项值唯一确定的物理数据块被访问次数。然后,对所有具有相同BlockID项值的分组统计其事件总数的均值和方差,即为标识为Block-ID的逻辑文件块综合其所对应多个物理数据块副本被访问次数后,统计得到的访问热度信息。
(2)统计文件访问并行度及均衡度信息
对于文件访问并行度信息的计算,首先根据物理数据块动态访问事件信息中的BlockID信息查找物理数据块的静态属性信息,获得该动态访问事件中Map任务访问物理数据块所属的文件信息File;然后根据File、JobID和StartTime项对所获得的物理数据块动态访问事件信息进行分组,确保每个分组中的事件记录具有相同的File、JobID和StartTime项值,则每一个分组表示作业号为JobID的Map/Reduce作业在StartTime标识的时刻点并行访问和处理File所标识的文件数据的所有Map任务;分别统计各分组中的事件记录总数,并对所有具有相同File项值的分组统计其事件总数的均值,作为File所标识文件的文件访问并行度信息。
对于文件访问均衡度信息的计算,则是在上述根据File、JobID和StartTime项对所获得的物理数据块动态访问事件信息进行分组的基础上,分别对每个分组的事件记录统计其EndTime与StartTime项差值的方差,并对所有具有相同File项值的分组统计该方差的均值,作为File所标识文件的访问均衡度信息。
6 实验结果
6.1 功能验证
本章给出所设计的Hadoop平台数据访问监控界面,如图5所示。Hadoop平台中文件及文件所包含逻辑文件块信息以树型结构显示在界面左侧。物理数据块静态属性信息中物理数据块所在计算节点信息以图形方式显示在界面右上侧。物理数据块动态访问事件信息、逻辑文件块访问热度信息和文件访问并行度及均衡度信息在界面右下侧显示。当用户在界面左侧选中文件时,在界面右上侧高亮显示文件包含的所有物理数据块,从而显示出物理数据块与文件间的从属关系;同时,在右下侧显示该文件访问并行度及均衡度信息。当用户在界面左侧选中逻辑文件块时,在界面右上侧高亮显示逻辑文件所对应多个物理数据块副本,在界面右下侧显示该逻辑文件块访问热度信息。当用户将鼠标移动到界面右上侧所示的物理数据块上时,在界面右下侧显示该物理数据块动态访问事件信息。
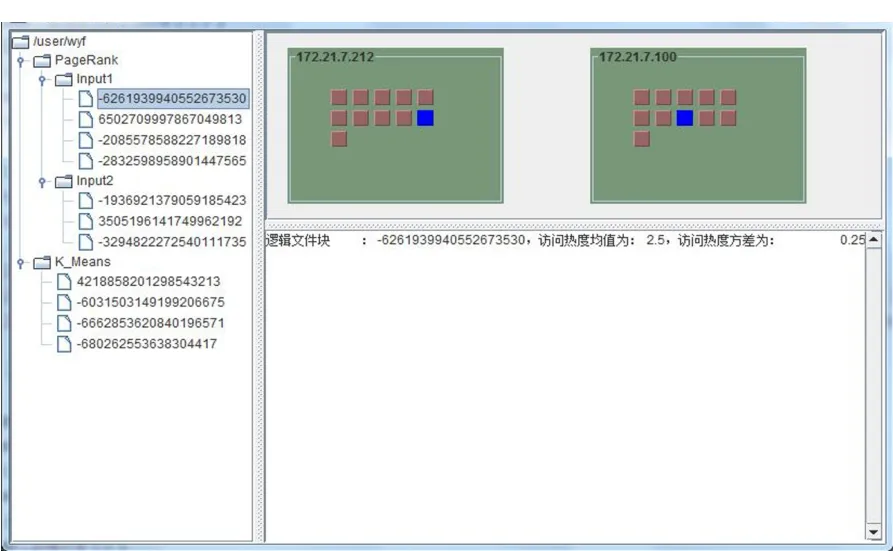
图5 Hadoop平台数据访问监控界面
6.2 性能测试
实验环境为包含10个物理节点的Hadoop平台,其中一个物理节点运行NameNode线程,其余物理节点运行DataNode线程。Hadoop版本为0.20.2。每个物理节点配置如下:双核处理器,CPU为Intel®Pentium®4,3.00 GHz;80 GB磁盘,8个物理节点的内存大小为2.5 GB,2个物理节点的内存大小为512 MB。物理节点间使用百兆以太网互联。
首先对Hadoop平台数据访问监控统计一次物理数据块静态属性信息、物理数据块动态访问事件信息、逻辑文件块访问热度信息和文件访问并行度及均衡度信息所需时间进行测试。测试作业为处理1 GB数据的WordCount作业,监控周期为10 s。在包含4、6、8、10个物理节点的Hadoop平台中依次进行测试。测试结果如图6所示。物理节点规模从4增加到10时,统计一次信息所需时间仅增加1.56 s,远小于监控周期10 s。
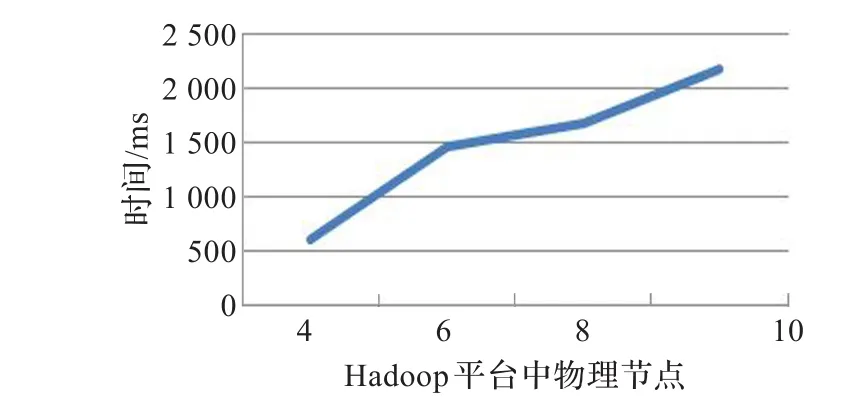
图6 Hadoop平台数据访问监控统计一次信息所需时间
下面对Hadoop平台数据访问监控消耗平台资源情况进行测试。在包含8个物理节点的Hadoop平台中分别部署监控节点资源使用情况的脚本程序。监控资源包括:CPU和内存。在两种模式下执行wordcount作业,一是原始Hadoop平台,二是增加数据访问监控的Hadoop平台。作业输入数据为1 GB。测试结果如图7、8所示。由测试结果可知,对CPU使用情况而言,增加数据访问监控的Hadoop平台较原始Hadoop平台CPU资源消耗最小仅增加0.2%,平均增加值为5.1%;对内存使用情况而言,增加数据访问监控的Hadoop平台较原始Hadoop平台内存资源消耗最小仅增加0.8%,平均增加值为3.6%。总体而言,数据访问监控对Hadoop平台资源消耗有较小影响。

图7 不同计算节点CPU使用百分比平均值比较
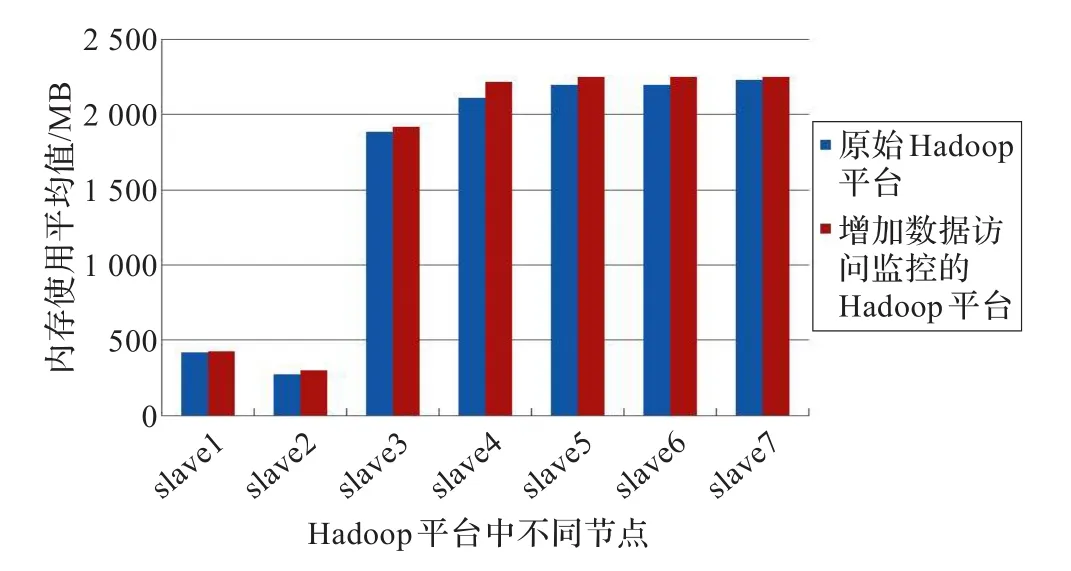
图8 不同计算节点内存使用平均值比较
最后对数据访问监控对Hadoop平台中作业执行效率的影响进行测试。分别在4、6、8、10个物理节点规模的Hadoop平台中运行GridMix提交的作业,作业以1 GB数据作为输入。在两种模式下执行作业,一是原始Hadoop平台,二是增加数据访问监控的Hadoop平台。由图9可知,与原始Hadoop平台比较,增加数据访问监控的Hadoop平台中作业执行时间最小仅延长0.87%,最大延长5.38%。
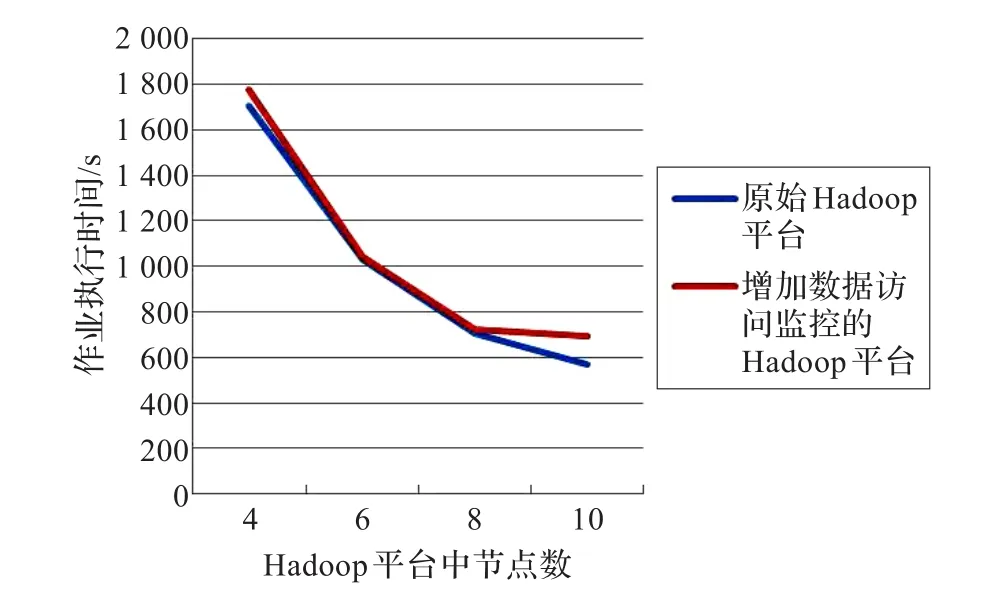
图9 数据访问监控对作业执行效率的影响
7 相关工作
对于海量数据处理应用的性能研究已有较多成果[10-11]。本文着力于Hadoop平台中数据访问情况的研究。文献[12-14]以离线的方式对日志信息进行分析,这与本文在线对数据访问情况进行监控不同。文献[12]通过对日志的分析,抽取控制流和数据流的情况。控制流主要包括map、reduce任务的运行情况;数据流指由于作业执行导致节点间的数据流动情况,这里的数据统计以字节为单位。文献[13]通过对Hadoop平台运行日志进行分析,从而捕获控制流和数据流。在此基础上提出错误诊断的方法。错误诊断包括:对执行时间过长的任务的诊断和发生错误的节点的诊断。文献[14]通过分析系统日志,对集群上作业的形态进行全面的分析,并对作业的完成时间进行预测,给出预测算法。文献[15]通以作业执行整体流程为目标进行分析,与本文针对于Map任务访问数据行为进行监控不同。文献[15]通过为控制流关联相应的数据流,进而给出控制流和数据流间的关系,并进行详细分析及异常检测。文献[16]进行HDFS层面和作业层面的监控。在HDFS层面主要包含文件包含的物理数据块信息,即本文中数据块静态属性信息,但文献[16]中不包括Map任务对物理数据块的动态访问信息。总结而言,文献[12-16]均基于作业层面对作业生命周期进行监控,在数据块层面仅局限于对数据块静态分布属性的监控。与文献[12-16]不同,本文提出Hadoop平台中数据访问监控不仅服务于数据存取效率的提升,还应服务于Map/Reduce并行作业执行效率提升的基本思想,并增加对并行执行多Map任务数据访问开销均衡性的监控。
8 总结及下一步工作
本文针对Hadoop平台数据被任务调度感知,进行本地化处理的新特征,研究面向Hadoop平台的数据访问监控机制。本文提出Hadoop平台中数据访问监控不仅服务于数据存取效率的提升,还应服务于Map/ Reduce并行作业执行效率提升的基本思想,并增加对并行执行多Map任务数据访问开销均衡性的监控。基于该思想,本文的主要贡献有:(1)定义数据访问监控的粒度和监控信息组成;(2)设计基于master-slave的数据访问监控体系结构;(3)给出数据访问监控机制具体实现技术及测试结果。在该成果的基础上,课题组下一步的工作主要包括并行多Map任务数据本地化处理优化机制的研究。
[1]Bell G,Gray J,Szalay A.Petascale computational systems[J]. Computer,2006,39(1):110-112.
[2]Newman H B,Ellisman M H,Orcutt J A.Data-intensive E-Science frontier research[J].Communications of the ACM, 2003,46(11):68-77.
[3]Cannataroa M,Taliab D,Sriman P K.Parallel data intensive computing in scientific and commercial applications[J]. Parallel Computing,2002,28(5):673-704.
[4]Middleton A M.Data-intensive technologies for cloud computing[R].Handbook of Cloud Computing.[S.l.]:Springer,2010.
[5]Dean J,Ghemawat S.MapReduce:Simplified data processing on large clusters[C]//USENIX Symposium on Operating Systems Design and Implementation,2004:137-150.
[6]Ghemawat S,Gobioff H,Leung S T.The Google file system[J].SIGOPS Operating Systems Review,2003,37(5):29-43.
[7]Apache Software Foundation,“Hadoop”[EB/OL].[2012-06-12]. http://hadoop.apache.org/core.
[8]Ananthanarayanan G,Ghodsi A,Wang A,et al.PACMan:Coordinated memory caching for parallel jobs[C]//USENIX Symposium on Networked Systems Design and Implementation,2012.
[9]Tanenbaum A S,Steen M V.Distributed systems:principles and paradigms[Z].2008.
[10]刘超,金海,蒋文斌,等.基于MapReduce的数据密集型应用性能优化研究[J].武汉理工大学学报,2010,32(20):36-41.
[11]郑湃,崔立真,王海洋,等.云计算环境下面向数据密集型应用的数据布局策略与方法[J].计算机学报,2010,33(8):1472-1480.
[12]Tan J,Pan X,Kavulya S,et al.Mochi:visual log-analysis based tools for debugging hadoop[C]//USENIX Workshop on Hot Topics in Cloud Computing(HotCloud),2009.
[13]Tan J,Pan X,Kavulya S,et al.SALSA:Analyzing logs as state machines[C]//USENIX Workshop on Analysis of System Logs(WASL),2008.
[14]Kavulya S,Tan J,Gandhi R,et al.An Analysis of Traces fromaproductionMapReducecluster[C]//IEEE/ACM International SymposiumonCluster,Cloud,andGrid Computing(CCGrid),2010:94-103.
[15]Tan J,Kavulya S,Gandhi R,et al.Visual,log-based causal tracing for performance debugging of MapReduce systems[C]//International Conference on Distributed Computing Systems,2010:795-806.
[16]Huang D,Shi X,Ibrahim S,et al.MR-Scope:A real-time tracing tool for MapReduce[C]//The MapReduce of HPDC,2010:849-855.
WANG Yufeng1,LIANG Yi1,JIN Yi2,LI Guangrui1
1.College of Computer Science,Beijing University of Technology,Beijing 100124,China
2.Beijing Computing Center,Beijing 100094,China
Aiming on the issue of task scheduler considering the data location information for locality-based data processing in Hadoop Map tasks,a novel data access behavior monitoring mechanism is proposed in this paper.It is argued that the data access monitoring mechanism of Hadoop platform should not only serve to promote the efficiency of data access,but also serve to promote the execution efficiency of parallel Map/Reduce jobs.It is necessary to monitor the balance of data access overhead in the parallel execution of multiple Map tasks.The granularity and information set of data access monitoring in Hadoop platform is defined;The master-slave-based monitoring architecture is presented,which works with the support of Hadoop existing function modules;The detail implementation of the main monitoring function modules is discussed and the experimental results is analyzed.
Hadoop;Map/Reduce;monitoring;data access
针对Hadoop平台数据被任务调度感知,进行本地化处理的新特征,探索Haoop平台中Map任务数据访问监控机制。提出Hadoop平台数据访问监控不仅应服务于数据存取效率的提升,还应服务于Map/Reduce并行作业执行效率提升的基本思想,并增加对并行执行多Map任务数据访问开销均衡性的监控。基于该思想,定义Hadoop平台数据访问监控的粒度和监控信息组成;依托Hadoop平台现有结构,设计了基于master-slave的监控体系结构,并给出了监控主要功能模块的具体实现技术及测试结果。
Hadoop;Map/Reduce;监控;数据访问
A
TP302
10.3778/j.issn.1002-8331.1212-0302
北京市教委科技计划项目(No.JC007013201101);国家自然科学基金(No.61202075);北京市自然科学基金预探索项目(No.4133081)。
王玉凤(1988—),女,硕士研究生,主要研究领域为云计算、高性能计算;梁毅(1975—),女,博士,副教授,主要研究领域为云计算、高性能计算;金翊(1978—),男,博士,高级工程师,主要研究领域为云计算、高性能计算;李光瑞(1989—),男,硕士研究生,主要研究领域为云计算、高性能计算。E-mail:wangyf@emails.bjut.edu.cn
2012-12-26
2013-04-17
1002-8331(2014)22-0043-07
CNKI网络优先出版:2013-04-27,http://www.cnki.net/kcms/detail/11.2127.TP.20130427.1446.007.html
