代码混淆技术在软件保护中的应用研究
2014-07-21康彦
康彦
(合肥工业大学,安徽 合肥 230031)
代码混淆技术在软件保护中的应用研究
康彦
(合肥工业大学,安徽 合肥 230031)
伴随着越来越多的逆向工程工具的出现,使得软件被篡改、盗版的威胁也逐渐增大.攻击者通过对程序的逆向工程获取程序的重要算法和核心数据.文章通过对代码混淆技术的定义、混淆方法分类、混淆应用和评价等方面详细阐述代码混淆技术在软件保护中的实际意义和应用,并指出了代码混淆技术未来的发展方向.
代码混淆;软件保护;逆向工程
1 引言
随着Internet的不断发展,使得各种软件的传播越来越广泛和迅速.随之而来的,软件被盗版、篡改的软件安全问题也愈发的严重起来.根据《2010年度中国软件盗版率调查报告》显示,相对于软件产品的价值盗版率达24%.同时伴随着程序设计语言(诸如Java,.NET等)的发展,出来了许多以使用与平台无关的中间代码发布的软件.其代码与源代码极为相似.这些软件比起普通的二进制代码更易受到来自恶意用户逆向工程和分析.伴随这各类逆向工程技术的出现,使得对此类软件的保护愈发的困难.因此,对于软件知识产权的保护,除了使用法律外,我们还需在技术上加以保护.软件保护的技术很多,其中代码混淆技术就是一种重要的手段.代码混淆是指采用混淆策略对应用程序进行混淆变换,使得变换后的软件功能与原程序保持一致.但是其更难以被静态分析和篡改.
2 代码混淆技术的定义
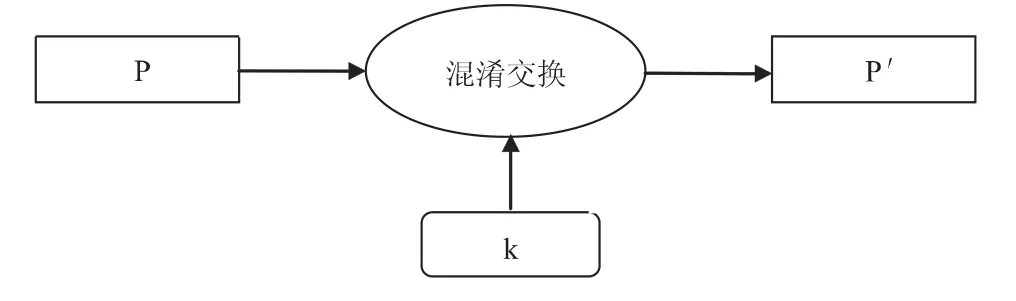
代码混淆是一种保持语义的程序变换技术,它将程序P依据一系列混淆策略k变换到P'(如图1),使对P'进行篡改更为困难,但是P和P'必须保证语义上的一致性,两者在软件功能上应该保持相同.简言之,代码混淆技术中变换的是程序本身,而不是程序所描述的功能.而代码混淆的目的是为了增大其被逆向工程的难度.通常来说,如果使用足够多的计算、存储资源和足够长的时间,对一个程序进行逆向工程总是可能的.同样,不管使用什么样的混淆策略也无法保证程序永远不会被逆向工程,我们所关注的是尽可能的提高混淆后程序P′逆向工程难度,使逆向工程的代价远大于其收益.从而保护软件不被盗版或篡改.
3 代码混淆技术的方法分类
依据代码混淆策略和对象的不同,代码混淆技术一般可分为名称混淆、流程混淆、数据混淆和预防混淆等方法. 3.1名称混淆
名称混淆也称为布局混淆,主要是删除和改名.即删除与实际执行无关的信息和修改程序中各类标示符的名称.删除主要是去除程序中的注释与程序执行无法使用到的代码等.删除之后不但可以压缩程序的大小、提高程序加载的速度和运行效率,还可以使程序被逆向工程的难度增加.改名的意义是将表意的名称替换为无意义的名称.以.Net中名称混淆为例,主要分为两类方法:
a.名称替换
.Net的元数据中有一个NameTable,这个表里面保存了所有类型,方法,属性,字段等的名称.这一类混淆的本质就是从NameTable里面进行一对一的名称替换.实现的方式可能是多样的.可以IL级替换,也可以直接元数据级替换,或者其它达到相同效果的方式.
b.名称擦除、索引破坏
这类混淆只能在元数据级进行操作,要求对元数据的全部结构十分清楚,有一定难度.它的本质,让名称索引数组越界.元数据中类型,方法,属性,字段等的定义处是通过一个整形的index值指向NameTable的,index所对应的字符串就是它的名称.这类混淆就是直接修改这个index值,如将它改为-1.如果还要进一步做,可以再删除NameTable中无用的字符串,以及删除NameTable有用但重复的字符串.再修改索引,让名称相同的指向同一个字符串.
名称混淆是最基础的混淆技术,大多数代码混淆工具都不同程度地使用到此类技术.
3.2 流程混淆
流程混淆指的是对程序的执行流程进行混淆变换,使得程序的执行流程变得难以理解,增大逆向工程的难度,一般情况下,在对程序执行流程进行混淆时,需要加入一些冗余的流程和计算,这样势必会导致程序执行效率的下降.因此,在使用流程混淆时,我们需要根据程序的执行效率的不同要求来设计不同程度的混淆策略.流程混淆技术大致可以分为如下两类:
a.增加混淆控制
通过添加冗余的、复杂的程序流程,可以在不改变程序语义的情况下,增加其被逆向工程的难度.例如,原程序中相邻的两个基本语句块A和B,因两者中间没有任何控制转移语句.
其执行顺序一定是依次发生.下图中我们通过在两者之间增加不同的跳转控制条件,已决定后者的执行.在图中我们能发现虽然流程更加复杂了,但所增加的跳转控制并没有影响语句块B的执行.

b.控制流重组
控制流重组是指将原程序中控制流在语义不变的前提下进行重新组织.如,可将一个被调用的方法直接嵌入到调用方法中,反过来,方法中一段基本语句块也可转换成一个新的方法,调用之.通过此类变换后,原程序的控制流程图被不同程度的破坏,使得系统的总体框架变得很难理解,从来提供程序的混淆强度.
3.3 数据混淆
数据混淆主要是对程序中的重要数据进行混淆处理,对程序中的数据结构进行转换,以不规律的方式组织数据,从而增加程序逆向工程的难度.常用的方法有以下几种:
a.动态生成静态数据
程序中静态数据,如字符串常量等,极易被逆向工程获取,可以利用函数动态生成的进行代替.对静态数据进行动态生成提高了逆向工程的难度,同时也会带来一定的程序执行效率的降低.在实际应用中因适当选择.
b.转换数组组织
数组是高级程序设计语言中最简单、最常用的一种数据结构.对于数组的混淆包括将大数组拆分为若干小数组,合并若干小数组为一个数组或修改数组的维数.对数组结构使用适当的转换,可以隐藏数组数据所代表的实际含义.
c.转换类结构
类结构的转换是指合并类、分裂类和类型隐蔽.类合并是将代码中的2个或多个类合并成一个类,从而改变类之间原来的关系,隐蔽程序设计的思路.如果有必要,甚至可以将程序中所有的类都合并成一个类.类的分裂是将一个初始的类转换成2个或以上个新类来代替.类型隐蔽主要是利用如Java、.Net中的接口(interface)进行类型映射操作来实现. 3.4预防混淆
预防混淆一般是根据一些已有反编译器的特点而设计的特殊混淆方法.已有的反编译器基本上都存在弱点或者Bug.利用好这些漏洞,就可以很好的提高程序的反编译强度.如VS.Net中自带的混淆器Dotfuscator就包含有针对反编译器ILDASM的预防混淆策略.
4 代码混淆技术的应用与评价
4.1 应用
代码混淆技术应用很广泛,目前,主要应用于以下4个领域:
(1)关键算法保护.对于程序中重要的算法采用必要的代码混淆,以确保算法策略不被攻击者分析获取,防止程序被恶意攻击或篡改.
(2)软件知识产权保护.随着网络软件和移动应用迅速发展,软件盗版也愈发的严重,使用代码混淆技术可以提高软件的逆向工程难度,是保护软件知识产权的有效技术手段之一.
(3)恶意代码取证.在网络信息取证中,恶意代码通过代码混淆产生多种变种,给计算机信息安全带来许多新的挑战.所以,研究恶意代码所使用的代码混淆技术,对于恶意代码的特征提取就有着非常重要的意义.
4.2 评价
如何评价代码混淆的效果,通常从强度(Potency)、弹性(Resilience)、代价(Cost)、隐蔽性(Stealth)等4个方面来评价:
(1)强度.指经过混淆交换后的程序被逆向工程的复杂程度.一般来说,增加代码的长度;增加程序控制结构中的分支数、循环嵌套数及函数调用的深度;加大类的继承高度等方法都可以提高代码混淆变换的强度.
(2)弹性.指经过混淆变换后的程序对反混淆工具的抵抗度.它包括以下两个方面,一个是反混淆工具编写者编码所需的代价,另一个方面是反混淆工具运行所需要的时空代价.
(3)代价.指经过混淆变换后的程序在执行时和原程序相比所增加的时间和空间的额外消耗.
(4)隐蔽性.是指经过混淆变换后的程序与原程序之间的相似程度.
5 总结
综上所述,通过适当的代码混淆变换,加大了程序被逆向工程的难度,一定程度上起保护了软件不被恶意篡改,保护了软件的知识产权.提高恶意用户通过分析程序获取软件重要数据和算法的难度.但代码混淆技术尚处于发展阶段,缺乏相应的理论基础,没有准确的度量代码混淆算法有效性的评估模型.在以后发展中,我们将需要一套完整的理论体系和相应的度量与评价模型.和其他软件保护技术结合起来,为软件安全提供更为有效的保护.
〔1〕Collberg C,Thomborson C,Low D.A taxonomy of obfuscating transformations.Technical Report 148,University of Auckland.1997.
〔2〕A.Barak,O.Goldreich,R.Impagliazzo,S.Rudich,A.Sahai,S. Vadhan,And K.Yang.On the(im)possibility of software obfuscation.Crypto01.2001.
〔3〕罗宏,蒋剑琴,曾庆凯.用于软件保护的代码混淆技术[J].计算机工程,2006(11).
〔4〕王一宾,陈意云.代码迷惑技术研究进展[J].吉林大学学报(信息科学版),2008(04).
TP393
A
1673-260X(2014)03-0017-02
