基于云计算的网络生物医学信息专题系统的构建
2014-07-13尔西丁买买提罗雪琼陈国忠
王 爽, 尔西丁·买买提, 罗雪琼, 陈国忠, 森 干, 周 毅,
(1新疆医科大学, 乌鲁木齐 830011; 2中山大学,中山医学院, 广州 510080)
随着信息技术和网络技术的飞速发展,共享在网络中的生物医学信息在互联网中呈爆发性的增长,这些信息在网络中呈现出数量庞大、分布广泛、内容丰富、时效性强、质量良莠不齐等特点[1]。人们对于生物医学信息的获取越来越多地依赖于互联网,如何从大量的生物医学信息中查找并提取人们想要的信息,十分困难。基于此本文提出了构建基于云计算的网络生物医学信息专题系统,为生物医学信息需求者及时主动地提供全面准确的信息。
1 生物医学信息获取现状
目前传统的生物医学信息获取方式主要为[2]:(1)通过搜索引擎。输入关键词进行检索,但是通用搜索引擎返回的结果信息量巨大,相关性不强;(2)利用生物医学文献数据库。生物医学文献数据库提供多种检索方式,较强的依赖于用户的检索技能;(3)浏览生物医学网站。目前网络中存在数量很多的生物医学相关的网站、论坛、博客以及微博等,信息量多而繁杂处于无序状态。现阶段生物医学信息的获取方式主要还是以“手工”方式为主,即需要用户主动地去网络中收集需要的相关信息,过程耗时费力。
2 云计算
云计算是将IT相关的能力以服务的方式提供给用户,允许用户在不了解提供服务的技术、没有相关知识以及设备操作能力的情况下,通过Internet获取需要的服务[3]。 “云”可以理解为一种资源池,它是一些可自我维护和管理的虚拟计算资源,由计算服务器、存储服务器、网络资源等组成的大型服务器群集。“云”所提供的服务能够通过软件实现自动管理,可无限扩展,用户可以随取随用,按使用付费,摆脱自建数据中心投入多、可扩展性差、管理维护困难的窘境。云计算拥有以下特点[4]:(1)超大的存储和计算能力;(2)可靠性、安全性和可扩展性;(3)经济性;(4)共享性。云计算被视为现代科技的下一次革命,它将为信息的搜集、管理和使用带来根本性改变。
从目前情况分析,在云计算架构下,主要提供的服务分为3个层次:一是提供计算、存储、网络等资源的基础设施服务;二是构建的计算平台服务;三是在云计算平台上构建的软件服务。即IaaS(Infrastructure as a Service,基础设施即服务)、PaaS(Platform as a Service,平台即服务)和SaaS(Software asa Service,软件即服务)[5]。
随着互联网的发展,国际上许多国家自20世纪就开展了对网络信息的采集和分析,并对采集得到的信息进行智能分析和处理,实现从大量相关的资源和行为中发现和抽取客户所关注的信息。国、内外信息采集与分析系统有成熟的技术,它凭借着大量的服务器存储着数量巨大的互联网信息,在生物医学信息化领域将会有广阔的应用。目前利用云计算技术来解决海量生物医学信息数据的存储、采集和分析越来越受到研究者们的重视。
3 系统功能
针对传统生物医学信息资源获取的特点和获取存在的困难,集合云计算技术,构建基于云计算的网络生物医学信息专题系统,利用云计算技术的优势,为生物医学信息需求者提供及时、准确、全面的信息服务。
3.1个性化的信息提供系统采用B/S模式,以网站的形式提供生物医学领域的网络信息,包括新闻信息、新发相关论文以及会议信息和课题申报信息等等。可为用户提供全面的生物医学领域内的最新信息,并可按照用户的需求为用户提供个性化的定制信息。用户登录系统,做好所关注领域的配置之后,再次登录后系统将会自动推送用户所关注领域最新的、全面准确的信息,方便用户跟踪了解所关注领域的发展动态。
3.2信息检索由于系统信息几乎是实时地提供给用户的,过期未查看的信息会被掩盖,用户可通过信息检索功能对较长时间之前的信息进行回顾,也可通过检索功能形成某一个专题的信息集合,便于专题信息的跟踪分析。系统提供信息检索窗口,通过简单的时间段设置,可以实现对存储在数据库中的信息进行全文检索。
系统采用Lucene作为全文检索系统架构,以方便在目标系统中实现全文检索的功能。Lucene是一套用于全文检索和搜寻的开源程式库,提供了一个简单却强大的应用程式接口,能够做全文索引和搜寻,见图1。采用Lucene作为全文检索引擎,具有5个方面的优点[6]:(1)在倒排索引的基础上,实现了分块索引,能针对新文件建立增量或者小批量索引,使索引速度得到了提升,并可通过合并原有索引达到优化索引的目的。(2)索引文件格式与应用平台独立。Lucene定义的索引文件格式以8位字节为基础,使其能在不同平台的应用或不同系统中共享建立的索引文件。(3)支持多语言。也可编写解析器(Analyzer)扩展支持其他语言。(4)Lucene采用独立于文件格式和语言的文本分析接口,索引器通过接收Token流来完成索引文件的创建,用户只需实现文本分析接口就可实现新的语言和文件格式的支持。(5)采用基于组件式的面向对象的系统架构,降低了对Lucene的扩展难度,易于在其基础上扩充新的功能。Lucene提供的接口函数功能强大,接口简单。
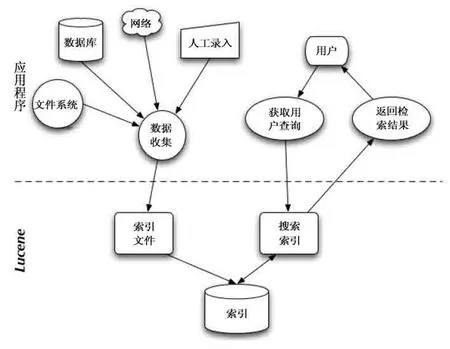
图1 搜索应用程序和lucene之间的关系
3.3信息分析系统可提供用户所关注领域的信息随时间发展变化的趋势分析。利用lucene全文检索系统对信息按相关度和时间排序进而进行统计学分析,跟踪相关领域的发展变化趋势;采用聚类算法,分析发现热点信息,提高信息获取的有效率;采用基于向量空间模型(VSM:Vector Space Model)的支持向量机分类算法对系统后台所采集的信息进行分类[7],便于相关领域的用户检索,提高查询的准确率和查全率。
4 系统架构
基于云平台的网络生物医学信息专题系统包括2个部分,即后台用于数据采集的垂直搜索引擎和前台给客户提供信息服务的信息服务系统。系统以云平台为基础,借助云平台的优势以软件即服务的模式为用户提供信息支持。其系统架构如图2。
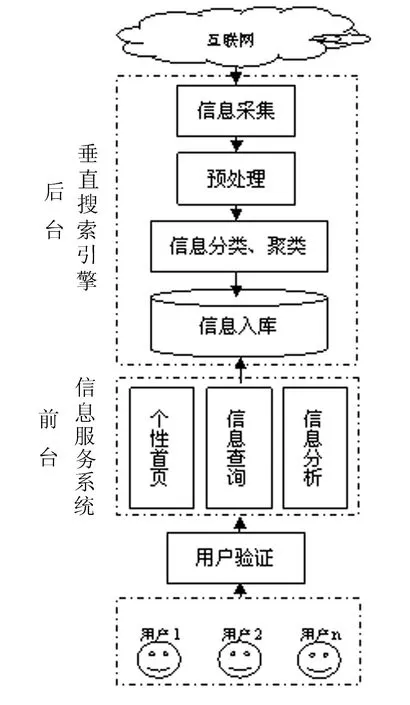
图2 系统架构
4.1信息采集信息采集系统为分布式蜘蛛采集架构,支持上万服务器自动调度,支持自动去重以及增量更新。系统由中央控制服务器和部署在多地的采集服务器集群组成。中央控制服务器是整个系统的核心,它连接所有的采集服务器组成一个大规模的分布式数据采集网络;它保存和调度所有的采集任务,为每台采集服务器动态分配不同的任务,计算任务抓取周期和优先级,监控所有采集服务器工作状态。
采集服务器在获取抓取任务后,依据任务配置抓取特定的网页,并提交给相关的内容抽取策略算法库完成信息抽取。每台采集服务器完成单次任务后,会再次向中央控制服务器请求新的任务。中央服务器会记录该机上次的任务分配记录,并分配一个不相同的任务开始新的抓取工作(图3)。
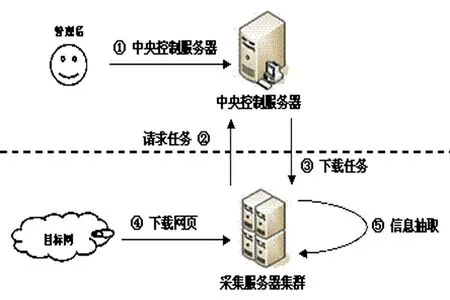
图3 信息采集流程
4.2信息预处理对于采集服务器采集来的网页信息需要经过预处理才能进行后面的分类和聚类操作。信息预处理包括网页预处理和信息预处理两部分。
网页预处理首先是进行网页规范化处理,目前互联网上充斥着大量格式不规范的网页,这对正文抽取工作带来极大的不便,因此首先需要对网页进行规范化处理,将其转换成格式良好的XML文档。之后进行网页解析,建立标签树,再根据网页的HTML格式使用正则表达式对各DOM子树进行剪枝,去除不用来储存正文信息的节点,最后用基于统计的方式来抽取网页中的正文。
网页预处理完之后对于抽取出来的正文信息接着进行处理,即信息的预处理。信息预处理首先调用中科院的中文分词系统(ICTCLAS)进行中文分词,然后用互信息算法进行特征词选择,用TF*IDF进行权值计算,用向量空间模型对信息进行表示,为信息分类做准备。
4.3建立分类体系分类即在给定的分类体系下,根据文本的内容自动地确定文本关联的类别。从数学角度来看,文本分类是一个映射的过程,它将未标明类别的文本映射到已有的类别中。该映射可以是一一映射,也可以是一对多的映射。文本分类的映射规则是系统根据已经掌握的每类若干样本的数据信息,总结出分类的规律性而建立的判别公式和判别规则;然后在遇到新文本时,根据总结出的判别规则,确定文本相关的类别[8]。
目前国内尚无针对网络医学信息的分类,也没有相应的现成语料库。中国知网和万方数据库关于生物医学方面的论文数据库均有一个分类,该分类较为明晰,2种分类也很相似,因此本系统的分类将参考中国知网和万方数据库关于生物医学的分类而建立,将网络中的生物医学信息分为医药卫生方针政策与法律法规研究、医学教育与医学边缘学科、预防医学与卫生学、中医学、中药学、中西医结合、基础医学、临床医学、感染性疾病及传染病、心血管系统疾病、呼吸系统疾病、消化系统疾病、内分泌腺及全身性疾病、外科学、泌尿科学、妇产科学、儿科学、神经病学、精神病学、肿瘤学、五官科、口腔科学、皮肤病与性病、特种医学、急救医学、军事医学与卫生、药学、生物医学工程、医疗保健总共29个分类。分别收集各类下的网络信息形成训练语料库,为采集的未知分类信息正确分类做准备。
另外,系统还可根据用户需求建立特殊分类,提供除了已知固定分类之外的分类,可完全按照用户提出的需求提供符合要求的信息,提高系统的友好性。
4.4数据来源系统开发前期主要集中精力采集和整理几个特定分类或领域下的信息,由点到面分阶段逐步进行,不断完善最终建成一个覆盖所有生物医学领域的信息系统,为用户提供全面的信息。其主要信息来源为:(1)生物医学文献数据库。生物医学文献数据库主要采集国内外生物医学文献数据库中文献的标题、摘要、作者信息等;(2)生物医学相关站点。除了生物医学文献数据库之外,互联网中还有很多生物医学相关的门户、论坛、博客、微博以及“开放存取”的很多国内外的生物医学信息等[9];(3)人工录入。因为网络中生物医学信息数量巨大,计算机自动采集重要站点的信息,人工录入是信息完善的辅助方式,为计算机自动采集进行查漏补缺;(4)用户指定。数据来源可以根据用户要求制定采集策略,以便提供个性化的信息服务。
5 总结
本文提出的基于云平台的网络生物医学信息专题系统的建立,可以给生物医学领域的研究人员提供及时、全面、准确的信息,这样大大节省了信息获取的时间,提高了信息获取的效率,用户能够利用该平台掌握生物医学领域的最新发展动态,跟踪国内外生物医学各学科和课题组研究进展,对寻找和把握新的生物医学研究和医疗技术发展方向提供支持。
参考文献:
[1] 陈欣.试论网络医学信息资源的现状与利用[J].医学信息,2007,20(1):89-90.
[2] 饶从志,周毅,王卓青,等.基于网络的临床科研信息获取模式的研究与探讨[J].医学信息,2010,24(8):5222-5223.
[3] 陈全,邓倩妮.云计算及其关键技术[J].计算机应用,2009,29(9):2562-2567.
[4] 罗雪琼,陈国忠,饶从志,等.论云计算及其在医疗卫生信息化中的应用[J].现代医院, 2012,12(11):4-7.
[5] 维基百科.云计算[EB/OL].http://zh.wikipedia.org/wiki/%E4%BA%91%E8%AE% A1% E7%AE%97#cite_ref-nist_4-1.
[6] 周锦程,王丹,余泉,等.基于Lucene的全文检索系统的研究与实现[J]. 计算机技术与发展,2011,21(3):67-71.
[7] 朱红斌,蔡郁. 基于主动学习支持向量机的文本分类[J]. 计算机工程与应用,2009,45(2):134-136.
[8] 庞剑锋,卜东波,白硕.基于向量空问模型的文本自动分类系统的研究与实现[J].计算机应用研究,2001,18(9):23-26.
[9] 王凤产.期刊开放存取及其策略研究[J].中国科技期刊研究,2009,20(2):248-251.
