一种海量大数据云存储系统框架设计
2014-07-11费贤举王树锋王文
费贤举,王树锋,王文
(常州工学院计算机信息工程学院,江苏 常州 213002)
一种海量大数据云存储系统框架设计
费贤举,王树锋,王文
(常州工学院计算机信息工程学院,江苏 常州 213002)
随着数据爆炸性增长,传统的存储方式已经不再满足海量数据的存储需求,云存储技术的飞速发展,使得云存储成为了一种新型的数据存储解决方案。文章在分析Hadoop分布式文件系统HDFS的基础上,提出了一种新的基于云计算环境的海量大数据存储设计方法,主要给出了文件存储方案设计以及副本方案设计等,为云计算海量数据存储与管理提供了一种可行的关键技术方案。
海量大数据;云存储系统;HDFS
0 引言
近年来,随着社交网络、网络新闻媒体和娱乐视频等各种信息化服务的开展产生了大量的数据,使得数据存储规模也呈现爆炸性增长。个人用户的数据存储规模达到TB(1012B)级别,大中型企业的数据存储甚至达到EB(1018B)级别。[1]云计算和物联网的迅速发展,越来越多的个人和企业选择将自己的业务迁移到大规模的数据中心,以此来降低本地的硬件成本和系统维护费用。由于数据中心存储的数据量十分庞大,管理系统的复杂性较高;从存储设备级别上看,由于数据中心为了控制成本,大量采用廉价存储设备,致使数据极易因硬件设备故障而丢失。这些都对海量数据存储性能、可靠性等方面带来了挑战。
云存储是解决海量数据存储的最有效手段。谷歌公司提出的 MapReduce[2],作为一种新的编程模型,能有效地并行处理海量的数据,其采用的文件系统和数据管理模式分别是 GFS[3]和Big Table[4]。近些年,作为 MapReduce的开源实现,Hadoop[5]得到了企业和研究机构的广泛关注。本文基于Hadoop平台,提出了一种海量大数据云存储系统设计,并分析了实现应用系统需要实现的关键技术。
1 Hadoop平台
云计算是一种商业计算模式,其来源于分布式计算,并行计算和网格计算。Hadoop作为云计算的核心技术,目前在工业界得到了广泛的应用。
Hadoop是Apache开源组织按照MapReduce的工作原理设计的一种开源的分布式处理框架,也是云计算环境下最著名的开源软件。在Hadoop系统中,应用程序可以并行运行在由大规模廉价硬件构成的分布式系统中。Hadoop在内部实现了容错和扩展机制,可以构建成高可靠性和高扩展性的分布式系统。
Hadoop主要有三部分组成:HDFS(Hadoop Distributed File System)、MapReduce分布式计算模型和Hbase(Hadoop Database),其结构如图1所示。

图1 Hadoop结构图
HDFS[6]与谷歌的 GFS 相对应,布署在廉价的硬件设备上,是Hadoop的最底层。HDFS可以存储TB级(甚至PB级)的海量数据,并为应用程序提供高吞吐率的数据访问。HDFS的数据访问是顺序的,适用于数据密集型的应用。
MapReduce[2]是一种海量数据处理的分布式计算模型。在集群中运行分布式应用程序时,MapReduce编程模型简单易用。Hadoop提供的MapReduce编程模型是谷歌MapReduce的开源实现。在MapReduce编程模型中,开发者只需要编写Map和Reduce函数,而任务调度、容错等机制由底层实现。因此,即使开发者没有分布式系统的经验也能编写高效的分布式应用程序。
Hbase[7]是 Big Table 的开源实现。Hbase 构建在HDFS之上,提供分布式数据库服务。Hbase提供一种按列存储的模型,用户可以实时读写,也可以在大规模数据集上进行随机访问。
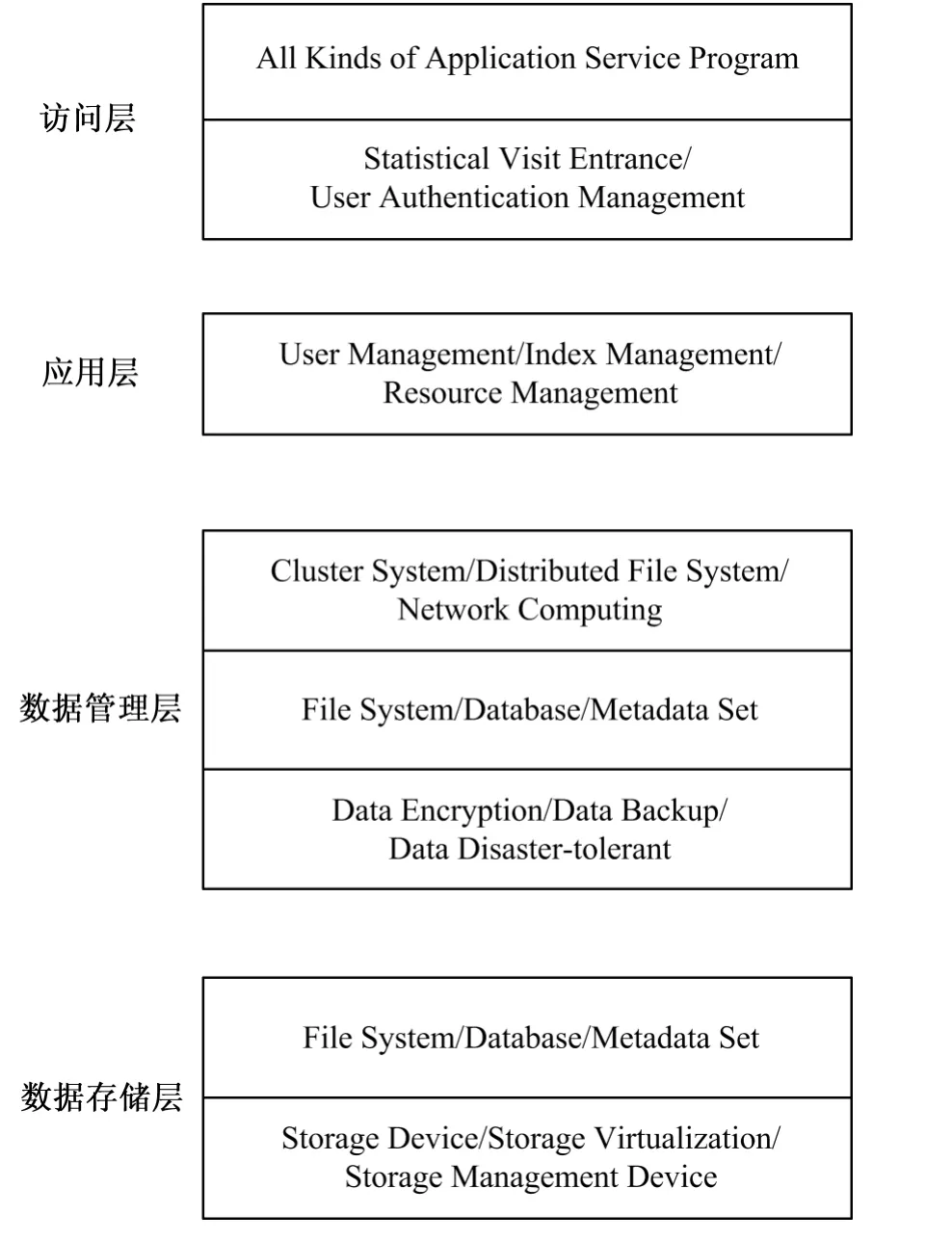
图2 海量数据存储和管理框架图
2 海量数据存储系统设计
2.1 文件系统的设计
节点主要分为两部分:一种是数据节点,另外一种是非数据结点,其中系统中的主要成分都是数据节点(如图3所示的DataNode节点),非数据节点主要指管理节点和监控节点统一由Master节点表示,如图3所示。
①Client节点。这个节点主要是指需要获取海量分布式文件系统数据文件的应用程序(访问客户),可以是Web应用业务服务器(如社交网络、娱乐视频、网络虚拟银行等),也可以是其他通过当前海量数据存储系统的访问接口进行访问的其他主机和服务器。
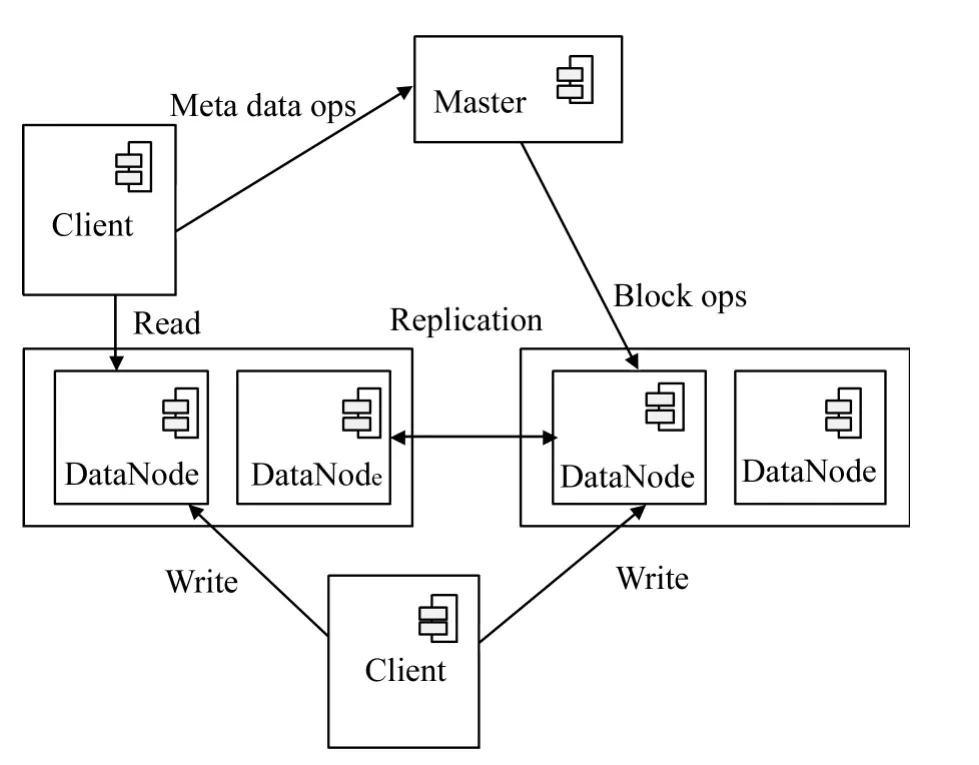
图3 云存储系统的结构示意图
②DataNode节点。作为系统的主要构成部分,DataNode节点负责了系统正常运行的大部分任务,其中包括:数据存储、提供查询和事务处理,并且在必要时根据系统的需求提供计算能力。其中所有Node节点之间的关系也不完全是相同的,可以根据地域划分邻居节点和非邻居节点,一般使得同一地域内的节点都是邻居节点,基于这种设计主要考虑到系统规模可能会随着分布式数据应用不断增大,如果只有一层关系管理节点,将会变得很困难,并且在实际使用中,同一地域的节点之间的通信单价和质量都是比较好的,所以让系统的管理分为3层,一个Master以每个组的关系看待节点,而节点自己能够区分是邻居节点(同一组)还是远程节点(不同组的)。
③Master节点。Master主要负责系统的整体状态的监控其中包括:整个系统的节点状态、提供局部数据节点的查询、保持文件块的地址信息等。这里需要注意的是,根据系统负载能力的需求Master节点本身不一定是单个PC机器,也可能有几台机器组成一个集群共同提供服务,这样才能保证系统不会因为管理节点的瓶颈而受到限制。
2.2 文件块存储策略及副本策略设计
在文件块存储设计时,规定每个文件块都用一个主副本,即每次每个事务处理本文件块的所有副本的更新都由主副本控制。每个文件块除了本身包含的信息之外必须有以下控制信息块。
①主副本所在节点编号。每个节点在加入系统时都从Master那里得到自己的唯一编号并且和自己的地址组成一个节点编号。
②副本个数。副本个数包括主副本和其他副本,如果为1说明没有其他副本,如果为0说明此文件块不存在。
③副本所在节点编号列表。保存所有节点编号,在必要的时候可以根据这里的节点编号找到保存了副本的节点的地址和系统编号以进行访问。
在Master里面有一个根据系统的客户信息生成的一个客户编号的快照,并且有此快照构成系统文件块保存的地址信息的索引,在进行全局查询的时候,Master就是根据这个快照表的信息进行客户信息定位的。然后根据算法把相应的文件块的地址返回到应用服务器,让它自行直接去访问相应的节点。Master快照表结构如表1。

表1 Master客户编号快照表
Master快照表中多个客户的信息有可能保存在同一文件块中,文件块出现重复是完全正常的。除了客户快照表之外,Master还保存了另外一重要的表——文件块副本表,这个表借用了Google的Big table的思想,主要包括文件块编号表项和节点信息表项,如表2所示。
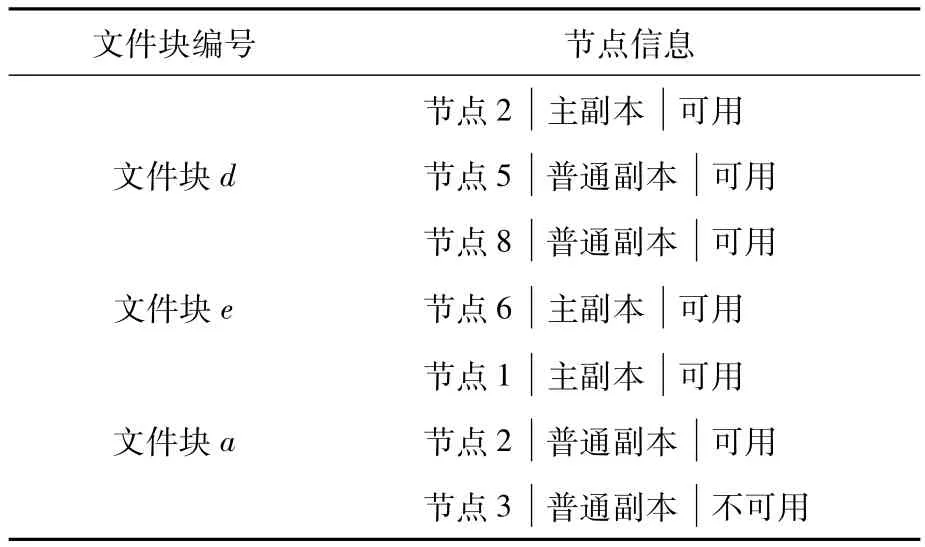
表2 文件块副本信息表
2.3 文件块更新算法设计
采用Google的Chubby提供进行文件块更新的锁控制服务,在进行事务处理的时候经常会遇到如下问题:同一个事务中需要更新的信息不在一个文件块中也不在一个节点中,在这个时候为了保证事务顺利地完成需要在多个涉及到信息更新的节点中选择一个作为协调节点,由它负责整个事务的更新流程和决定事务最后的成败,即决定事务最后是成功提交还是失败回滚。
与传统分布式的处理方式Paxos算法相比,Chubby服务机制主要解决以下几个问题。
1)开发人员在开发Service初期很少考虑到系统一致性的问题,也不会使用Consensus Protocol,但随着开发进行,问题会变得越来越严重。Chubby服务中采用Lock Service可以解决一致性问题,同时保持系统原有的程序架构和通信机制不变。
2)系统中很多事件发生(比如Master地址信息)是需要告知其他用户和服务器,Chubby使用一个基于文件系统的锁服务可以将这些变动写入文件中。因此,很多的开发人员通过使用Chubby来保存Metadata和Configuration。
3)虽然基于锁的开发接口更容易被开发人员所熟悉。但在Chubby系统中采用了建议性的锁而没有采用强制性的锁,采用这种方式是为了方便系统组件之间的信息交互而不会被阻止访问。同时,Chubby还采用了粗粒度(Coarse-Grained)锁服务而没有采用细粒度(Fine-Grained)锁服务,以提高系统性能。
4)Chubby选择一个副本为协调者(Coordinator),协调者从客户提交的值中选择一个,接受消息然后广播给所有的副本,各副本选择接受或拒接。协调者接收大多数副本的反馈后,认为达到一致性,向个副本发Commit消息。
Chubby的结构图如图4所示。
Chubby一般由5台机器组成就足以提供上万台机器的锁服务,5个服务器机器都是采用完全冗余策略来保证的,在Chubby内部采用Consensus Protocol协议保证系统的一致性,在每次5台机器内部通过此协议选出Master并且在一定时间后更新Master,在每次数据更新的时候5台机器在Master的控制下同步更新。
Client和Chubby之间采用event进行通信,并且为了降低通信频率,Client在本地会保存1个和自己相关的Chubby文件的cache,cache有2个状态(1个有效,1个无效)。当文件在Chubby端发生更新的时候,Chubby通知Client文件无效,然后Client自己去更新文件。
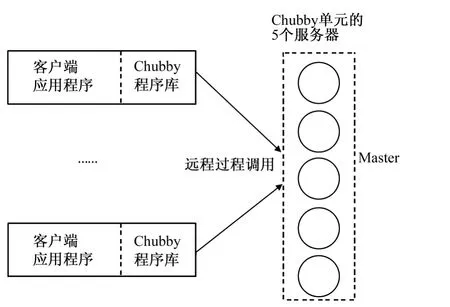
图4 Chubby系统结构图
Client更新DataNode节点数据文件的算法设计如图5所示。
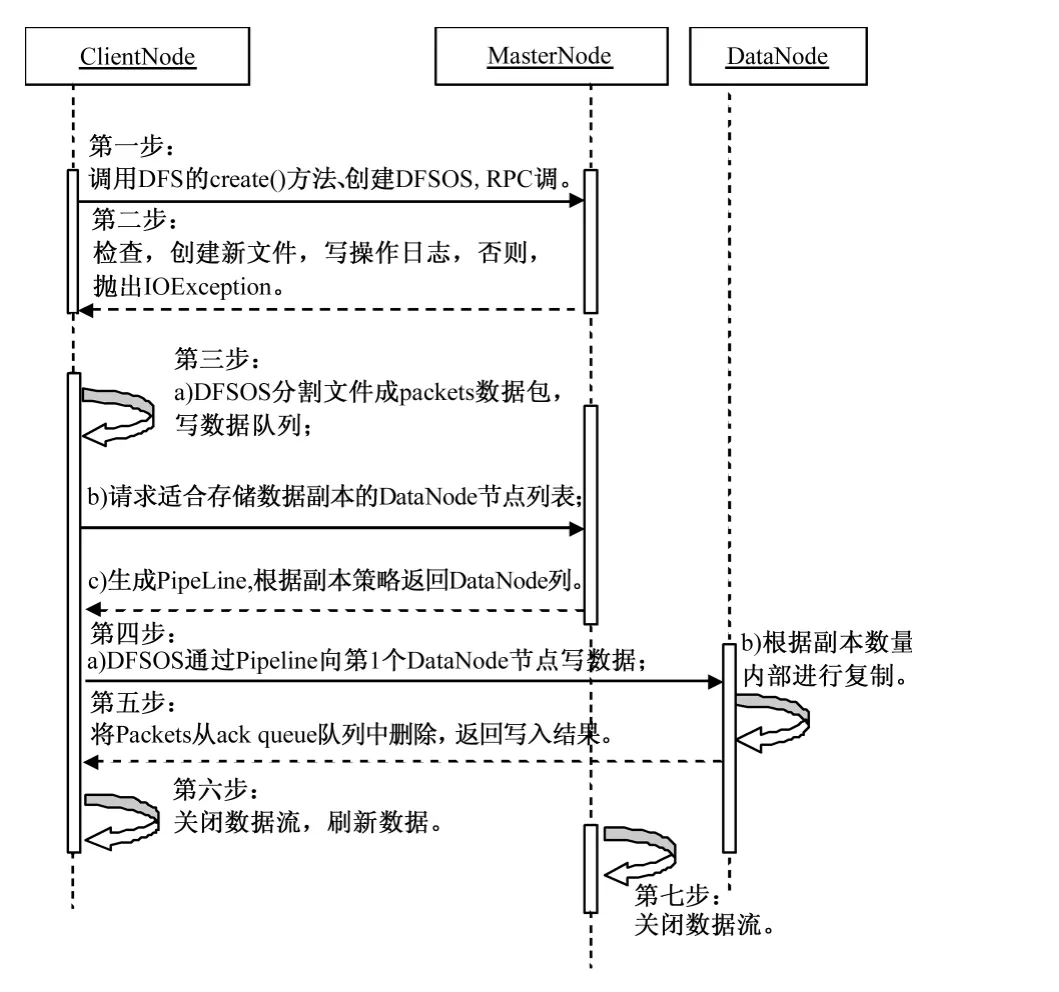
图5 Client更新DataNode节点数据时序图
其中,在DataNode节点数据更新的第四步中,如果Pipeline数据流管道中的某一个DataN-ode节点写操作失败,那么算法将进行如下操作。
1)关闭Pipeline数据流,然后将ack queue中的packets添加到 data queue的前面以免发生packets数据包的丢失现象;
2)升级在正常的DataNode节点上的保存的block的ID版本,使得发生故障的DataNode节点上的block数据会在节点恢复正常后被删除,同时也会从Pipeline中删除失效节点;
3)剩下的数据会被写入到Pipeline数据流管道中的其他正常的数据节点中。
2.4 事务故障恢复系统设计
云存储系统事务的恢复:对于云存储系统事务来说,因为处于网络环境中,其恢复过程远远要比集中式数据库复杂的多,在云存储系统事务恢复中,本地事务的恢复类同集中式事务的恢复。而整个云存储系统事务的恢复由云存储系统管理器与本地事务管理器协同完成。图6是本系统的全局事务恢复模型。
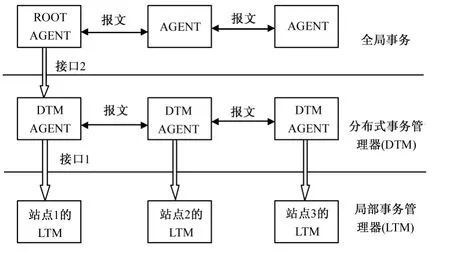
图6 云存储系统事务恢复模型
3 目录存储与负载均衡设计
系统目录存储和管理是将系统的目录分为若干个组,即前面所提到的按地域分组的方式。在每个组内,由Master指定一个节点专门提供目录服务,它本身也是一个普通节点,只是根据系统的设置成为一个为系统提供目录服务的组服务器,Master同时会将所有存储目录的节点的地址和编号信息通知所有节点。每个节点根据自己的信息和Master提供的信息对有目录的节点进行排序。然后在目录查询的时候各个节点就能够根据已知目录节点信息进行查询,虽然这个节点的其他查询任务也能执行,但在设计系统负载平衡算法的时候,尽量减轻提供目录查询的节点的其他查询任务。
按地区对来自客户的访问进行分类,并且根据客户的IP信息通过DNS进行分流。而在同一地区的负载进行轮转法分流本地区的各个访问到本地区的不同数据节点上,同时保持Master和DNS之间的通信,Master根据节点自身反应的信息对DNS中的各个节点的权值进行调整,及时调整系统的负载平衡。
4 结语
本文首先分析了Hadoop云计算平台,在文件系统架构层次中本系统尽量保持云计算平台的各种优势,提出了一种基于Hadoop的海量大数据云存储系统设计方案。对文件块的可读性特性方面进行了改进,并分析了实现应用系统所需要的关键技术,为云计算海量数据存储与管理提供了一种可行的关键技术方案。
[1]沈志荣,易乐天,舒继武.大规模数据中心的数据存储可靠性[J].中国计算机学会通讯,2012,8(10):8 -16.
[2]Dean J,Ghemawat S.MapReduce:Simplified Data Processing on Large Clusters[J].Communications of the ACM,2008,51(1):107-113.
[3]Ghemawat S,Gobioff H,Leung Shun-Tak.The Google File System[J].ACM SIGOPS Operating Systems Review,2003,37(5):29-43.
[4]Chang F,Dean J,Ghemawat S,et al.Bigtable:A Distributed Storage System for Structured Data[J].ACM Transactions on Computer Systems(TOCS),2008,26(2):4.
[5]武海平,余宏亮,郑纬民,等.联网审计系统中海量数据的存储与管理策略[J].计算机学报,2006,29(4):618 -624.
[6]崔杰,李陶深,兰红星.基于 Hadoop的海量数据存储平台设计与开发[J].计算机研究与发展,2012,49(z1):12 -18.
[7]刘树仁,宋亚奇,朱永利,等.基于 Hadoop的智能电网状态监测数据存储研究[J].计算机科学,2013,40(1):81 -84.
[8]Zeng Wenying,Zhao Yuelong,Ou Kairi,et al.Research on Cloud Storage Architecture and Key Technologies[C]//Proceedings of the 2nd International Conference on Interaction Sciences:Information Technology,Culture and Human.ACM,2009.
[9]Robert G L,Gu Yuhong,Sabala N,et al.Compute and Storage Clouds Using Wide Area High performance Networks[J].Future Generation Computer Systems,2009,25(2):179 -183.
[10]Storer M W,Greenan K,Long D D E,et al.Secure Data Deduplication[C]//4thInternation Workshop on StorageSS'08,Virginia:Fairfax,2008:1 -10.
Designing a Cloud Storage System of Massive Data
FEI Xianju,WANG Shufeng,WANG Wen
(School of Computer Information Engineering,Changzhou Institute of Technology,Changzhou 213002)
With the explosion of data,traditional storage methods no longer meet the massive data storage requirements.The rapid development of cloud storage technology makes cloud storage become a new type of data storage solution.Based on the Hadoop Distributed File System(HDFS),this paper puts forward a new type of distributed cloud storage solution for massive data,providing the persistence of high availability of data storage.This paper proposes a framework of storage and management of massive data,and analyzes key techniques that we need to implement the proposed framework.
massive data;cloud storage system;HDFS
TP312
A
1671-0436(2014)03-0038-05
2014-05-06
常州市2012年科技局应用基础研究计划项目(CJ20120009);常州工学院2013年度校级科研基金项目(YN1316)
费贤举(1975— ),男,硕士,讲师。
责任编辑:陈 亮
