基于语义共现图的中文微博新闻话题识别
2014-07-08王路路郑涛程倩倩姬东鸿
王路路,郑涛,程倩倩,姬东鸿
武汉大学计算机学院,武汉 430072
基于语义共现图的中文微博新闻话题识别
王路路,郑涛,程倩倩,姬东鸿
武汉大学计算机学院,武汉 430072
提出一种在大规模微博短文本数据集中自动发现新闻话题的方法。该方法在微博数据预处理之后,综合TF-IDF、文档频率增长率和命名实体识别等几个因素抽取微博数据中的主题词。根据主题词之间的语义关系来构建主题词的语义共现图,计算出语义共现图的连通子图,把每个不连通的簇集看成一个新闻话题。在新浪微博数据集上进行实验,实现了对微博中新闻话题的识别。该方法能较好检测出当前时间的热门话题,能够在一定程度上有效地避免错误传播,实验结果验证了该方法的有效性。
微博;主题词;语义共现图;新闻话题识别
1 引言
微博客(微博)是一个基于用户关系的信息分享、传播及其获取平台。用户可以通过Web、Wap以及各种客户端组建个人社区,以140字左右的文字更新信息,并实现及时分享。随着互联网的快速发展,微博改变了人们获取信息的方式,能够让普通网民更快更准确地了解当前的社会动态。如何从海量微博数据中检测出当前的热门新闻话题,对于舆情监控、民意调查、行业调研等都有着十分重要的意义。
微博具有传播快、数量大、语言简练等特点,对舆情分析提出了更高的要求。如何对微博文本进行分析、聚类,是发现热点话题的关键,很多研究者在这方面做了尝试:闫瑞等[1]提出了一种面向短文本的动态组合分类算法,获得了较好的准确率和召回率。彭泽映等[2]提出了一种大规模短文本的不完全聚类算法,可以有效地提高短文本的聚类性能。Liu等[3]提出了一种基于part-ofspeech和How Net的方法来扩展词汇的词义特征,增加文本特征向量的维度,进而改进聚类效果。王乐等[4]针对即时短语消息关键词数量少甚至是隐藏的这一特性,提出了WR-KMeans短语消息聚类方法。
微博短文本用词精炼,叙事简洁,传统的基于词共现的聚类算法[5-8]忽视了微博的语义关系,不能达到很好的聚类效果,从而难以识别出微博中描述的热门话题。鉴于微博文本的短小和主题词分布的稀疏性,基于模型的话题识别方法[9-12]训练周期较长、数据标注困难,很难达到满意的准确率。如何计算微博之间的语义关系,对微博文本进行语义层面的聚类,是微博话题识别的一个大胆尝试。例如,有如下两条微博:
(1)噢,本来我工资不高,可这个月饼贵,所以我缴纳了月饼税~
(2)中秋将至,不少单位把月饼当做福利发给员工。今日,地税部门也接到市民电话咨询企业发放月饼及其代金券给员工,应该如何代扣个人所得税。
上述两条微博相似度较高,因此可以将之划分为同一类别。但是从字符串角度判断除了共有的一个词“月饼”,很难判断两条微博属于同一类别。
在实验过程中,还发现传统的基于词共现的聚类算法很容易导致“错误传播”。例如,一个微博话题描述“章子怡出席电影节”,其相关的主题词为:[章子怡、上海、电影节、红毯];另一个微博话题描述“章子怡和汪峰密恋”,其相关的主题词为:[章子怡、汪峰、纽约、酒店、密恋]。由于词“章子怡”在两个话题中出现的频率都很高,基于词共现的聚类算法很难区分这两个微博话题。
针对微博数据稀疏性、实时性、不规范性的特点,本文提出了一种语义共现图模型。首先将微博短文本按照特定的时间窗口进行划分,综合TF-IDF,主题词文档频率增长率和命名实体等因素,来提取主题词。然后构建了一个语义集合,把微博主题词进行语义层面的聚类,从而识别出新闻话题。实验表明,本文中的方法能够降低“错误传播”发生的概率,比较准确地识别新闻话题。
2 微博新闻话题识别
2.1 方法思想和基本框架
从大规模的短文本微博客中识别新闻话题,需要克服两个难点:(1)如何从短文本中提取有效的能直接反映话题内容的主题词;(2)如何对主题词准确聚类,以便发现新闻话题。
本文提出的方法框架可以用图1来表示。
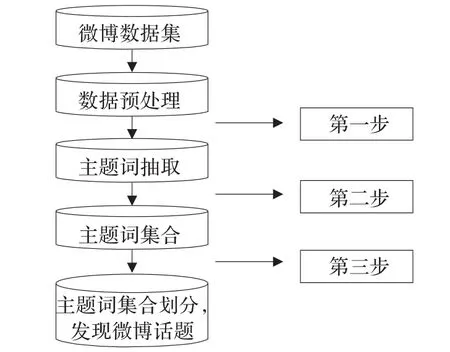
图1 微博中发现新闻话题的整体框架图
下面将依次介绍上面提出的3个步骤。
2.2 数据预处理
在进行主题词抽取之前,首先用中科院张华平等开发的ICTCLAS(Institute of Computing Technology,Chinese Lexical Analysis System)[13]的分词工具进行分词,然后进行词性过滤、停用词过滤等。预处理之后便可对得到的文本数据抽取主题词。预处理的过程如图2所示。
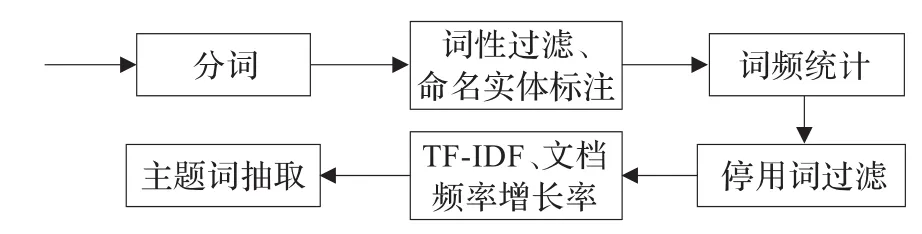
图2 预处理过程
2.3 主题词的抽取
(1)TF-IDF
一个与话题相关的主题词,相对于其他词汇,通常是非常热门的,即主题词出现的频率相对较高。TF-IDF是一种统计方法,用于评估一字词对于一个文件集或者一个语料库中的其中一份文件的重要度。TF表示词条在文档d中出现的频率。IDF的主要思想是:如果包含词条t的文档越少,也就是n越小,IDF越大,则说明词条t具有很好的类别区分能力。在微博数据集中TF可以衡量该微博描述新闻话题的广泛性,而IDF可以衡量其典型性。本文中采用归一化的TF-IDF函数,将一个词对新闻话题识别贡献度进行量化:
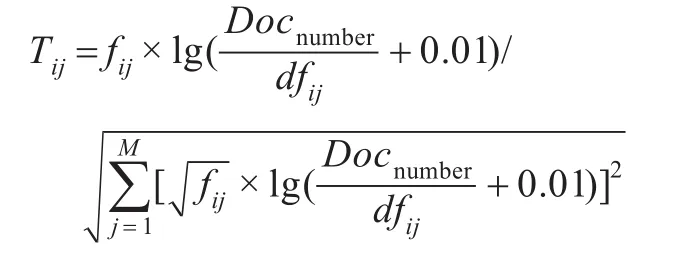
式中,Tij是词汇i相对于文档j的TF-IDF值,fij是词汇i在j时间窗口的频率,Docnumber是文档数目,这里指有效的微博条数。dfij表示词汇i在j时间窗口的文档频率。M为文档j中包含的词语个数。
(2)文档频率的增长率
一个与话题相关的词,在某个时间窗口内出现的频次会明显增加,即主题词在某个窗口内相对于其之前窗口的频次明显增多。这种词频的变化率在一定程度上意味着它和当前一些比较新的新闻话题关联。文档频率增长率能够客观衡量主题词的典型性,因此本文使用文档频率增长率进行量化。

式中,Gij表示词汇i在j时间窗口内文档频率增加率,dfij表示词汇i在j时间窗口内的文档频率。
对微博数据进行分词,词性过滤,词频过滤,命名实体标注等预处理之后,有选择地留下有意义的动词和名词,并对名词进行更细粒度的划分为时间、地点、人物、机构等,在此基础上考察TF-IDF和词频增加率两个方面的复合权值来评价一个特征词的权重W:
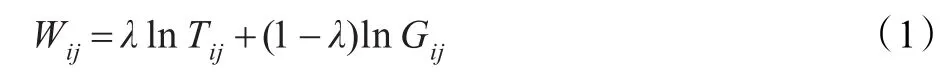
式中,Wij值表示特征词的权重,权重越大说明该词汇是主题词的概率越大;λ参数用来调节TF-IDF和词频增加率的比重关系。TF-IDF主要用来控制主题词汇的广泛性,文档频率增加率主要用来调节主题词汇的典型性。
对每个时间窗口内的词计算其Wij值,按照阈值T选取出其中权值最大的特征词得到一个主题词表。根据主题词表,就可以对这些主题词进行语义共现分析来构建语义共现图,进而实现新闻话题识别。
2.4 微博新闻话题识别
2.4.1 主题词共现图的构建
词的共现分析是自然语言处理技术在信息检索领域的成功应用之一,它的核心思想是词与词之间的共现频率在某种程度上反映了词与词之间的语义关联。为了从理论上进一步地阐述词共现理论在微博新闻话题识别的原理,给出了下面的定义。
定义1词汇x与词汇y的共现度定义如下:

故有C(x,y)=C(y,x)。式中,f(x,y)为单位时间段窗口内词x与词y在同一条微博中共同出现的次数。f(x)为词x在单位时间段窗口内出现的次数。
按照词共现原理,当2个主题词经常出现在同一条微博中,则可以认为这两个主题词在意义上相互关联,表述同一个潜在的主题信息。计算每一对主题词之间的共现度,得到一个词共现度矩阵M:

式中,keyi表示由主题词抽取算法抽取的第i个主题词。C(keyi,keyj)是由公式(2)计算得到的主题词的共现度。
考虑微博语义层面的相似度,计算任意两个主题词的语义相似度,得到主题词语义相似度矩阵N:
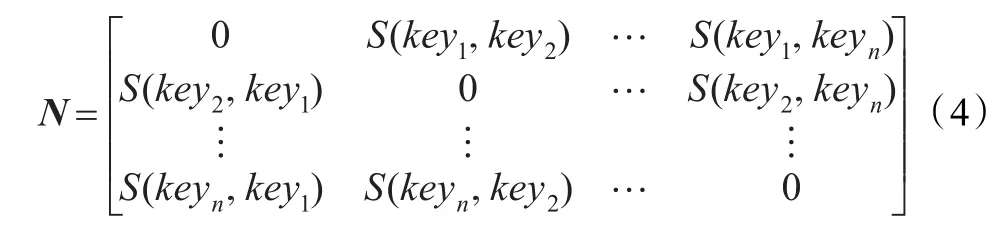
式中,keyi表示由主题词抽取算法抽取的第i个主题词。S(keyi,keyj)是由参考文献[16]的语义计算公式计算得到的主题词的语义相似度。
2.4.2 微博新闻话题识别
为了提升主题词聚类的效果,进而引入集合的概念。为此把矩阵M、N每行均按照公式(5)做归一化处理得到矩阵M',N'。
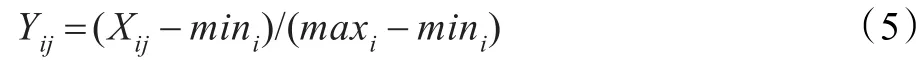
其中Yij为归一化之后的值,Xij为矩阵M和N中的元素第i行和第j列的元素,mini、maxi分别为矩阵M和N中第i行的最小值和最大值。
在聚类之前,根据矩阵M'和N'为每一个主题词抽取了共现度最高的k个词构成该主题词的候选语义集合,标记为KEYi={ki1,ki2,…,kik}。k值的大小直接影响主题词聚类的效果,从而调控“错误传播”发生的概率。k值过大会造成本来不属于同一语义集合的词汇信息也融入到计算中,会使实验结果产生一定的偏差;k值太小会漏掉同一语义集合中词汇的信息,从而造成实验结果精度缺失。k值由实验调参得到,本文中取k为4。
为描述方便,引入如下公式:
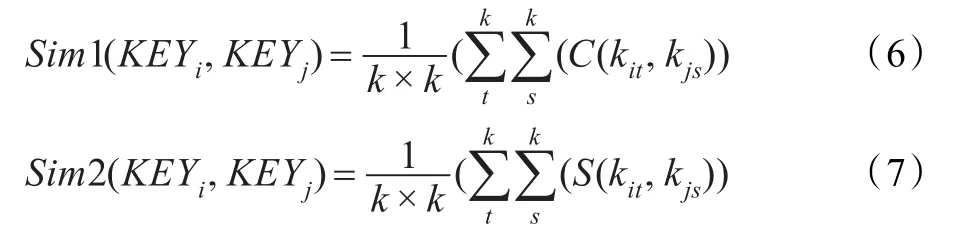
其中,Sim1描述两个语义集合词词素共现的信息,Sim2描述两个语义集合语义层面共现的信息。
语义集合更直观、准确地反映了两个主题词汇之间的语义关系,在本文中使用如下公式对主题词进行聚类:
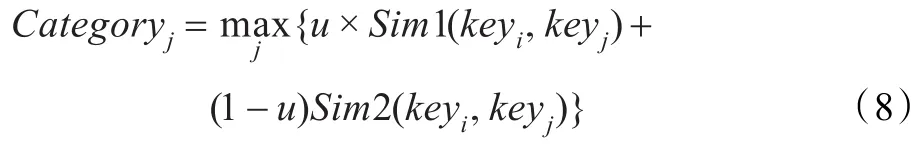
即,第i个主题词应该归入使上式最大化的主题词j的集合KEYj。
最后根据矩阵M'和N',把同一语义集合内的主题词之间连边,并把孤立点去除之后得到语义共现图。共现图中可能包含多个簇,也就意味着该时间窗口中包含多个热点话题,簇的大小也直观地反映了该话题的热度。
本文提出的算法不是单纯地考虑两个主题词之间的共现度,而是对微博进行了语义计算,从而构建语义共现图。实验证明,本文采用的方法能够有效地降低“错误传播”的风险,提升主题词汇聚类的正确率。
3 实验与结果分析
3.1 数据准备
为了本文的研究,使用由武汉大学自然语言处理实验室共享的新浪微博话题检测数据集。该数据集包括2013年4月16日到2013年4月24日,共9天约150万条的实时微博数据。除去停用词之后,将长度小于5的微博删除,剩下的微博作为有效的微博。有效微博的分布情况如图3。
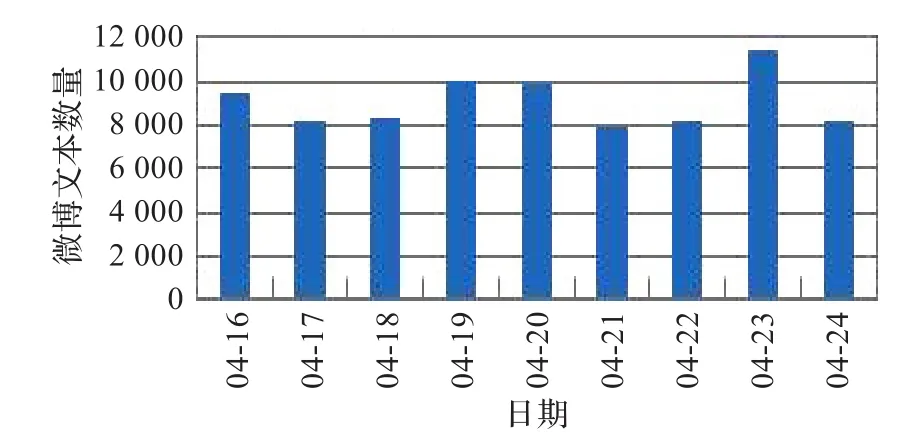
图3 有效微博文本分布图
3.2 评测主题词的抽取
为了评估主题词的抽取效果,把2013-04-16到2013-04-24共9天的微博数据分成了9组(以天为单位),对该时间段内的微博数据进行人工标注。该时间段内微博热议的主要新闻话题有“复旦投毒案”、“波士顿爆炸”、“黄金暴跌”、“雅安地震”等事件。对每个时间窗口中的数据按照前面所述的主题词抽取算法进行主题词抽取,考虑到每天新闻话题的数量及其主题词的分布,实验中设定阈值T为100,即权重最高的100个词作为主题词。为了评估主题词抽取的质量,人工计算该100个主题词与当前标注的新闻话题相关的主题词数,最后求平均值。实验中λ依次从0.1取到0.9,比较λ对相关主题词数的影响,如图4所示。
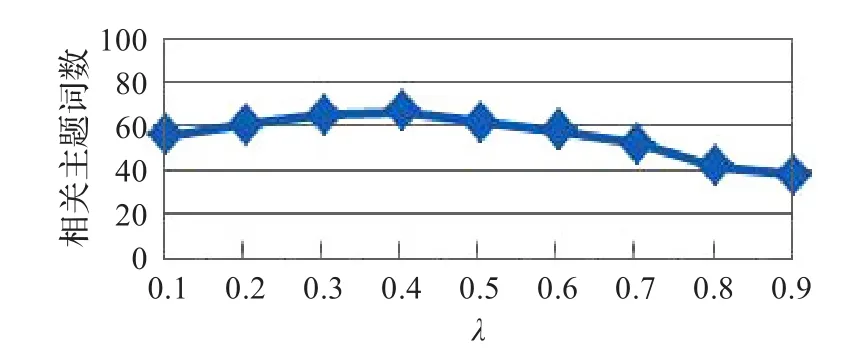
图4 λ对相关主题词的影响
实验表明,当λ取0.4时,主题词的抽取效果达到最佳,此时前100个主题词中有64个是相关主题词。
3.3 评测话题识别
为了评估主题词聚类的效果,选取了若干热门话题,u依次从0.1取到0.9,比较u对这些话题相关主题词数的影响,如图5所示。实验表明,当u取0.6时,主题词的聚类效果达到最佳。

图5 u对话题质量的影响
图6给出了本文方法抽取的4月26日的热门话题,可以看出,本文方法不仅检测出了热门的新闻话题,“黄金暴跌”、“国防部公布海陆空力量”这样的新闻话题也被检测出来,这说明本文的方法具备一定的灵敏性,能够识别出尽可能多的新闻话题。

图6 主题词共现图
表1是若干天的实验结果(仅列出最热门的一个话题)。从实验结果中可以看出,使用词共现方法检测的话题“波士顿爆炸”和“雅安地震”都存在“错误传播”。原因是波士顿爆炸期间襄樊某地发生了火灾,爆炸案和火灾二者词共现的频率较高,但是二者没有语义上的关联。“雅安地震”话题的错误传播是由于巴基斯坦和雅安先后发生过地震,而二者属于两个不同的热门话题。从对比实验可以看出,本文提出的基于语义共现的方法在一定程度上解决了“错误传播”的问题,抽取出来的话题的质量更高。
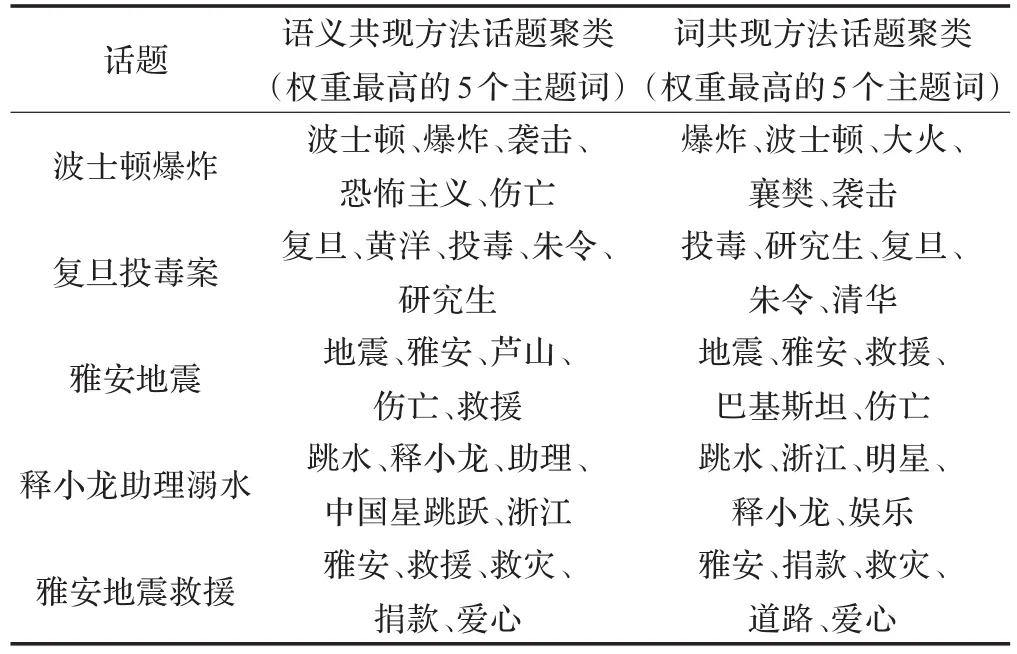
表1 若干天的热门话题
4 结论及下一步工作
微博热点新闻话题的识别研究有着重要的应用背景,本文提出了一种基于语义共现图的微博新闻话题识别的方法。该方法通过预处理、抽取主题词、构建语义共现图等步骤来识别微博新闻话题。实验结果证明了本文方法的有效性、灵敏性。本文充分利用了微博主题词之间的语义关系,从而能够在一定程度上避免“错误传播”,较准确地区分出当前的热门话题。
本文仍有可以改进之处。一方面,分词破坏了词之间的语义关系,尤其对于微博这样的短文本。避开分词,直接提取短语或者词串能够更直观地反应一个新闻话题。另一方面本文只考虑了新浪微博一个数据源,而热门的新闻话题往往广泛分布在不同的数据源中(比如腾讯微博、网易微博等)。整合多个数据源的信息,进而进行热门话题的识别能够保证话题的广泛性和公正性,也是将来工作的方向。
[1]闫瑞,曹先彬,李凯.面向短文本的动态组合分类算法[J].电子学报,2009,37(5):1019-1024.
[2]彭泽映,俞晓明,许洪波,等.大规模短文本的不完全聚类[J].中文信息学报,2011,25(1):54-59.
[3]Liu Zitao,Yu Wenchao,Chen Wei,et al.Short text feature selection for microblog mining[C]//The 4th International Conference on Computational Intelligence and Software Engineer,Wuhan,China,2010:1-4.
[4]王乐,田李,贾焰,等.扩展向量空间上的短语消息聚类[J].计算机研究与发展,2007(2).
[5]路荣,项亮,刘明荣,等.基于隐主题分析和文本聚类的微博客新闻话题发现研究[C]//第六届全国信息检索学术会议论文集.北京:中国中文信息学会,2010.
[6]Yan X,Zhao H.Chinese microblog topic detection based on the latent semantic analysis and structural property[J]. Journal of Networks,2013,8(4):917-923.
[7]Sun Q,Wang Q,Qiao H.The algorithm of short message hot topic detection based on feature association[J]. Information Technology Journal,2009,8:236-240.
[8]郑斐然,苗夺谦,张志飞,等.一种中文微博新闻话题检测的方法[J].计算机科学,2012,39(1):138-141.
[9]周振宇.基于LDA的微博与传统媒体的话题对比研究[D].上海:上海交通大学,2013.
[10]聂恩伦,陈黎,王亚强,等.基于K近邻的新话题热度预测算法[J].计算机科学,2012,39(S6):257-260.
[11]赵爱华.面向网络新闻的话题检测技术研究[D].济南:山东师范大学,2013.
[12]林雪能,陈光,朱帅,等.基于语义框架的新闻话题检测[EB/OL].(2012-12-27).http://www.paper.edu.cn/releasepaper/content/201212-1055.
[13]张华平,刘群.计算所汉语词法分析系统ICTCLAS[EB/OL].(2010-08-25).http://www.nlp.org.cn/project/project.php.
[14]Wartena C,Brussee R.Topic detection by clustering keywords[C]//19th International Workshop on Database and Expert Systems Application,2008:54-58.
[15]Chen K Y,Luesukprasert L,Chou S.Hot topic extraction based on timeline analysis and multidimensional sentence modeling[J].IEEE Transactions on Know ledge and Data Engineering,2007,19(8):1016-1025.
[16]刘群,李素建.基于《知网》的词汇语义相似度计算[J].中文计算语言学,2002,7(2):59-76.
WANG Lulu,ZHENG Tao,CHENG Qianqian,JI Donghong
School of Computer,Wuhan University,Wuhan 430072,China
A method of new s topics detection from large-scale short posts of microblogs is proposed.The TF-IDF,the document frequency increase rate and the named entity recognition are considered to extract new keywords from microblogs after pretreatment.A semantic co-occurrence graph is build by co-occurrence degrees of keywords,each unconnected cluster in a semantic co-occurrence graph is taken as a new s topic.Experiments are taken on Sina microblogs data sets and the experimental results show the proposed method works well.
microblog;keywords;semantic co-occurrence graph;new s topic detection
WANG Lu lu,ZHENG Tao,CHENG Qianqian,et al.Discovering new s topics from microb logs based on semantic co-occurrence.Computer Engineering and Applications,2014,50(17):150-154.
A
TP391.1
10.3778/j.issn.1002-8331.1312-0102
国家自然科学基金重点项目(No.61133012);国家自然科学基金面上项目(No.61173062)。
王路路(1989—),男,硕士生,研究领域为社交网络数据挖掘、个性化推荐等;郑涛(1992—),男,硕士生,研究领域为信息检索等;程倩倩(1989—),男,硕士生,研究领域为机器学习、数据挖掘等;姬东鸿(1968—),男,博士,博士生导师,研究领域为自然语言处理、语义网技术、机器学习、数据挖掘等。E-mail:wang_uu89@163.com
2013-12-09
2014-01-07
1002-8331(2014)17-0150-05
能够准确地描述一个新闻话题,主题词的抽取效果直接影响着新闻话题识别的效果。根据文献[14-15],一般新闻话题中的主题词有两个重要的特性:(1)广泛性,一个话题的出现的短期内,会引起大量的关注,从而与该话题相关的主题词将广泛分布在微博中;(2)典型性,新闻话题一般内容新颖,之前很少出现相似的内容,在某个特定时间段内忽然出现。本文把TF-IDF和文档频率增长率作为抽取主题词的2个主要影响因素。
