齐普夫定律在中文字频测定的推广①
2014-06-14吴冰
吴 冰
(黑龙江省图书馆,黑龙江哈尔滨 154000)
1 齐普夫定律的定义与推论
齐普夫定律(Zipf’s law)的表述为:当文章作者给出的文献语料库中的词汇足够多时,单词出现频率呈现出一定的分布规律.研究发现:不同的作者的用词取向和用词频度是不同的,这种规律被称为“语言指纹”.
所谓用词频度(词频)是指每一个词在一定长?之文件中出現的频率占总词数的比,如对一个由K个词组成的总长度为L的语料库中,词的出现频率由高到低排序为r的词频为Pr.而依词频从高到低将词排序的序号则是计量的另一个最基本的数量指标.早在1916年,法国速记学家艾思杜(J.Estoup)发现了在较长文章中,词的出现频率分布的定量化形式,即:

(1)式中r词依词频从高到低排列的序号,Pr是第r个词相应的词频,c是一个常数.
1932年,哈佛大学的语言学家齐普夫(G K Zipf)在研究英文单词的出现频率时,发现如果把单词频率从高到低的次序排列,每个单词出现频率和它的符号访问排名存在简单反比关系:
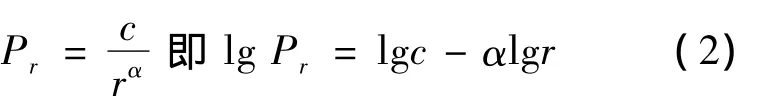
(2)式对应图像为截距为lgc,斜率为-α(α=tanθ)的直线.
上式中,r表示词在词表中的序号,Pr表示序号为r的词的频率,c和γ都是常数,齐普夫由实验测出,α ≈1,c≈0.1.
对于一个总词数汇容量为L,共有词K个的语料库,r=K时:
显然:Pk≥1/L

此后,朱斯(M.Joos)、曼德尔布洛特(B.Mandelbrot)以及齐普夫本人,先后对上述定律进行过研究,因而又称齐普夫定律为齐普夫—朱斯—曼德尔布洛特定律(Zipf-Joos-Mandelbrot law).新定律表述为:如果词表包含词足够多(1×105词以上),则其中前1000个最常用的词占该语言的各种文章中全部出现的词的80%.
用数学算式表现为:
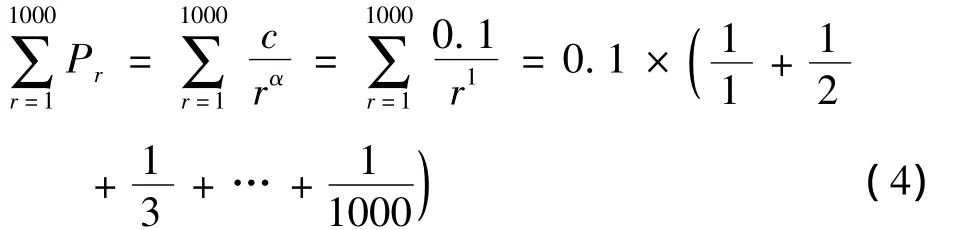
因为:调和数列的和
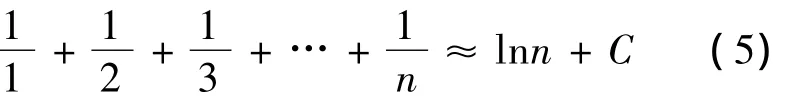
上式:C≈0.57722,C为欧拉常数(欧拉初始)将(5)入(4)式得:

设前r1个词的词频和为30%,由上式得:
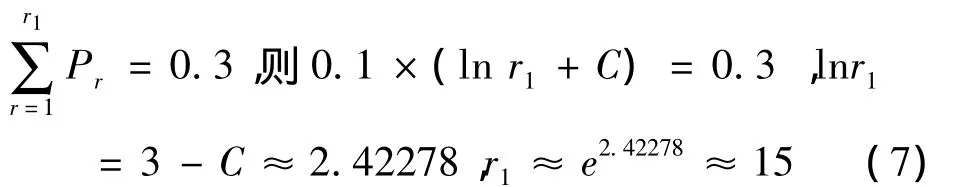
即英文语料库中前15个高频词的词频和即可达到30%.
以上式检验齐普夫对Brown语料库前135个单词的出现词频的和:
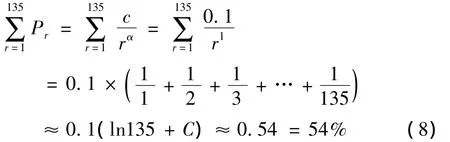
计算结果表明,齐普夫所选的语料库长度小于朱斯等人的研究对象.
针对不同的作者的写作用词频率的研究发现,不同的作者对同一词的用“力”是大小不同的,即同一词在不同作者的文章中出现的频率是不同的,而在同一作者的不同文章中出现的频率是基本相同的,这个现象被称为“语言指纹”.
造成不同的作者在写作中所使用的词汇及其频率的不同的原因有很多,如受教育的程度,个人性格、从事研究的领域、年龄、性格、出生地的方言、宗教信仰、对文字的避讳等各种因素的不同或差异都可能造成作者在写作中无意识的用词频率不的同,这种在语言表达上的特征即“语言指纹”.
2 齐普夫定律对汉语言文本字频的测定
与拼音文字不同,汉语多是以单字作为词素来组成一个或多个词素的词语的,目录,收录汉字最多的1994年出版的《中华字海》收入了87019个汉字,北京国安咨询设备公司的汉字字库,收入汉字91251个,而我国1988年公布的《现代汉语常用字表》选收的常用字为2500个、次常用字为1000个,合计3500字.
而根据国家出版局的抽样统计,汉字中最常用字560个,常用字807个,次常用字1033个.三者合计2400个,占一般书刊用字的99%.国家标准GB2312-80《信息交换用汉字编码字符集* 基本集》中一级字库3755个为常用字,二级字库3008个,为不常用字.一级字库的3755个字,使用频率合计达99%,而二级字库的3008个字,使用频率合计为0.3%,余下的80256个汉字的使用频率之和为 0.7%.
国家出版局的统计结果显示,最高频的“的一是了我”5个汉字的字频率之和为10%.次高频的“不人在他有这个上们来到时”12个汉字的字频之和为10%.再次高频的“大地为子中你说生国年着就那和要她出也得里后自以会”25个汉字的字频之和为10%.即仅42个汉字的字频之和为30%,可见,汉字字频的分布与拼音文字存在很大的差异,其图像中的|α|值更小,即图像中的直线下降更缓慢.
将上述结果用数学版式表达为:

下面以《红楼梦》文本为语料库对上式进行验证:
统计《红楼梦》120回本正文部分共872247个字符,除去标点符号,共731017汉字,累计使用4462个单字.
即:L=731017 >1×105,K=4462 >1×103,语料库满足研究要求.
考虑到时代不同对作者用词的影响,本次选取“的一是了我不人在他有这个上们来到时大地为子中你说生国年着就那和要她出也得里后自以会”42个高频词进行比对,并将作者时代还没有的“她”合并为“他”.增补《红楼梦》中统计所得高频字“玉儿女又才贾见”共48个汉字,统计其词频得出下表:

的一是了我不人在他有这个14890 12166 10452 21176 9202 15068 10544 3996 7682 6005 7841 5682上们来到时大地为子中你说

?
按字频从高到低排序,前五个分别是:了(21176),不(15068),的(14890),一(12166),来(11511),列表如下:

1 2 3 4 5 Pr 0.029 0.022 0.020 0.017 0.015 r
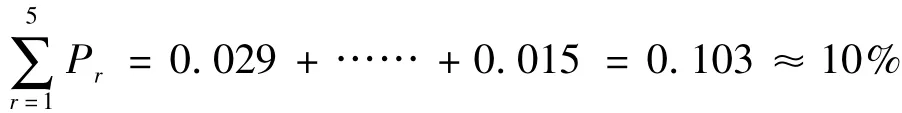
选取前 17个高频字:了(21176),……,道(11061),人(10544),是(10452),说(9686),我(9202),这(7841),他(7682),和(6138),生(6123),儿(6059),玉(6063),有(6005)
列表如下:

r 1 …… 6 7 8 ……17 Pr0.029 …… 0.015 0.014 …… 0.008
以上测算,验证了齐普夫定律对中文文本的适用性的推测,并验证了c和α的近似值,同时也通过字频序号的变化证明了清代文本语言特征与当代的差异,进一步研究词或词组的频度可以找出同一时代不同作者的语言指纹.
[1]马费城,布拉德福特一齐普夫分布系的概率模型[J].情报科学,1982(2):22-33.
[2]Malcolm Coulthard.Author Identification,Idiolect and Linguistic Uniqueness[J].Applied Linguistics 25,4,2004:431-447.
[3]中国百科网.常用汉字[EB/OL].http://www.chinabaike.com/article/baike/1056/2008/200811071597607.html.
