基于SQL Server的关联规则算法在高校招生中的应用
2014-06-12杨丽玲
杨丽玲
(漳州职业技术学院 计算机工程系, 福建 漳州 363000)
随着计算机互联网技术的发展,各个高校逐渐实现了信息化管理,如何从收集到的数据中挖掘出有用的信息,从而帮助我们更有效地管理变得越来越重要.在大专院校的招生录取过程中,如何为那些志愿填报不理想、可又愿意专业调剂的考生调剂到一个较为满意的专业,是一个很重要的工作,这关系着高校的录取报到率.但是,由于现在的录取都是通过网络进行,高校面对的是考生填报院校各个专业的数据信息,而其中的联系信息在录取结束前是被屏蔽的,导致院校无法与考生直接联系.所以,分析当年考生填报志愿信息,得出考生有报考倾向的其他专业对提高考生的报到率具有重要作用.本文主要是在当前较为流行的关系型数据库Microsoft SQl Server 2005下,利用关联规则进行数据挖掘和分析,找出考生填报专业间的重要性规则,挖掘出考生专业之间的关联关系,为考生的专业安排提供一个有力的依据[1].
1 数据挖掘技术
数据挖掘(Data Mining,DM) 是从大量不完全的、有噪声的、模糊的、随机的数据中,利用自动化或半自动化的工具来分析和挖掘,从而提取出隐含在其中的人们事先不知道,但又有潜在的有用的信息和知识的过程.
基于Microsoft的数据库平台 SQL Server 2005中的数据挖掘组件是数据挖掘工具的典型代表,它在商业智能BI方面提供了集成服务SSIS、分析服务SSAS和报表服务SSRS,并整合到BI DEV Studio的体系结构中.而其中分析服务提供了强大的多维数据分析和处理引擎、多种数据挖掘算法,以及功能丰富的服务器和客户端组件,可以访问两种形式的决策支持机制:数据挖掘和联机分析处理.
本文主要应用BI中的SSAS服务功能对招生过程中的数据信息进行数据挖掘.与传统数据挖掘应用程序相比较,它是易于使用的工具,可以帮助我们从任何数据源中构建数据挖掘模型;具有简单而强大的API,提供了数据挖掘扩展DMX、XMLA、ADOMD.NET等API进行编程,让用户可以对算法进行改进,实现算法嵌入到用户的界面系统中;具有7个世界级的数据挖掘算法,也可以通过.NET存储过程和插件算法对其进行扩展[2].
2 关联规则
数据挖掘的核心就是算法,算法决定了如何分析数据挖掘模型的实例.基于SQL Server 2005的分析服务提供了七种算法作为挖掘工具,而其中关联规则算法是用得最频繁的算法,它提供了一个功能强大的相关性计数引擎,可以执行可伸缩的和高效的购物篮分析,因此本文选择它进行数据挖掘.
关联规则是一个满足支持度和可信度阈值的、只包含蕴涵联结词的一阶谓词逻辑公式,它是隐藏在关系型数据库中的一种特殊有价值的知识,它是形如X→Y的蕴涵式[3].在招生信息中,设I是由所有的专业所构成的项目集,D是全体事务集,其中X⊂I,Y⊂I,且X∩Y=Φ,则挖掘出专业X→专业Y[支持度,可信度]的规则,从而反映考生专业之间的频繁模式、关联、相关系或因果关系.其中用支持度、可信度来衡量关联规则的属性.
为了发现有意义的关联规则,通常还规定关联规则必须满足最小支持度和最小可信度.支持度大于最小支持度的项集称为频繁项度.关联规则挖掘的步骤为:第一步挖掘频繁项集.第二步基于频繁项集产生所期望的规则.关联规则算法的核心部分就是挖掘频繁项集[4].
3 Apriori算法
Apriori 算法基本思想就是采用迭代逐层搜索的方法,通过对数据库多次扫描,使用候选项集来寻找频繁项集.在考生专业关联规则的挖掘中,我们通过对考生数据库多次扫描,使用候选项集来寻找频繁项集,从而生成关联规则.其递归过程是:首先,挖掘出所有大小为1的频繁项集L1,即报考高校其中一个专业的项集,并对每个单项的支持度进行计数,留下支持度大于最小支持度的项;其次基于L1来生成一组大小为2的频繁项集L2,即同时报考二个专业的项集,并对每一个生成的候选项集的支持度进行计数,留下支持度大于最小支持度的项;该算法重复过程,用L2生成频繁项集L3,以此类推,直到找到频繁K-项集.在第k循环中,通过对两个只有一个项不同,即只有一个报考专业不同的属于Lk-1的频集做连接来产生Ck,同时由于一个频繁项集的子集也是频繁项集,基于此性质引入修剪策略,从而由候选项集Ck产生频繁项集Lk[5].
具体算法如下[6]:
--生成大小为1的频繁项集,即只报考一个专业的频繁项集
L1= { 所有大小为1的频繁项集的集合}
--产生频繁项集k-项集
For ( k=1 ; Lk<>Φ; k++)
{ ---利用sql 自连接语句,从频繁项集Lk中生成候选项集Ck+1
insert into Ck+1
Select x1.a1,x1.a2,…,x1.ak,x2.akfrom Lkas x1, Lkas x2
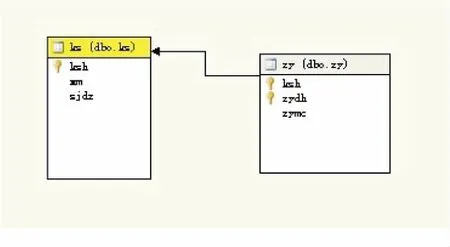
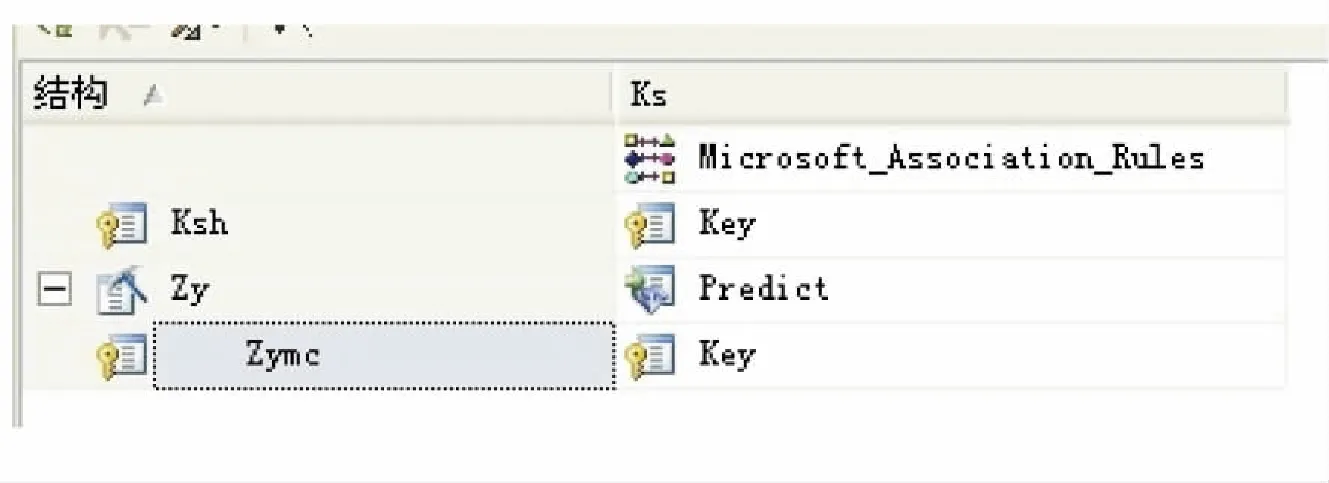
Where x1.a1=x2.a1and x1.a2=x2.a2and …and x1.ak ;---修剪掉非频繁项集的项集 For all itemsets c in Ck+1 { For all k-subsets s of c do { If (s is not in Lk) then delete c from Ck+1;} } ---计算每个项集的支持度 For each transaction t in databases { For each candidate c in Ck+1 { if ct then C(x)++;} } ---排除掉那些支持度小于最小支持度的候选项集 For all c Ck+1 { If C(x)>minimum_support Lk+1=Lk∪{ c} } } ---得到频繁K-项集 While k>=1 do { L=L∪Lk; k--; } Return L ; (1)数据预处理.对2013年的招生数据进行整理,其中共有考生2482名,每个考生最多可填报6个专业志愿.整理后的主要表结构见表1、表2: 表1 考生表ks 表2 志愿表zy 其中考生表ks(2842条记录),与志愿表zy((7567条记录)通过列字段考生号ksh建立一对多的联系,见图1. 图1 考生表ks与志愿表zy的联系 (2)关联规则挖掘模型.以考生表ks为事例表,志愿表zy为嵌套表,指定zymc为键和可预测列,默认系统也会将其设置为输入列.选择关联规则算法作为数据挖掘的算法,如图2. 图2 关联规则挖掘模型的构建 在关联规则数据挖掘时,设定最小的支持度、项集数和最小概率后,挖掘出符合条件的项集和规则,具体如图3. 图3 专业填报的支持度 从第一行记录可看出有601人填报了公共事务管理的同时也填报了人力资源管理. 图4 专业填报的规则 在图4中,第一行记录显示了考生填报旅游管理(酒店服务与管理方向)专业后填报涉外旅游(涉外酒店管理方向)的概率有54% .在这里我们以重要性为度量规则.有时有些规则的概率很高,但有可能该规则并没有多大的指导意义.反过来,重要性越高,则规则越重要.如图5的关系依赖网络图所示: 图5 专业填报的关系依赖图 (3)关联规则结果分析.从挖掘结果中产生强规则关系,如考生填报旅游管理(酒店服务与管理方向)专业后填报涉外旅游(涉外酒店管理方向)的概率有54% ,而考生填报涉外旅游(涉外酒店管理方向)专业后填报旅游管理(酒店服务与管理方向)的概率有89%.通过对两个专业的双向预测,指导我们对仅填报其中一个专业且处于调剂状态的考生,将其调剂到规则右侧的专业中,既避免了由于考生志愿填报失误造成退档,同时又提高了高校的录取率. 在数据挖掘中,核心是算法.本文基于数据库平台 Microsoft SQL Server 2005,结合BI Development Studio的分析服务功能SSAS对招生系统中考生报考专业的合理安排进行研究,利用Microsoft关联规则算法挖掘出考生填报专业间的规则,实现将那些志愿填报不理想又愿意专业调剂的考生调剂到一个较为满意的专业. 参考文献: [1]罗孟华.基于布尔关联规则Apriori算法的高校决策应用的研究[J].电脑知识与技术,2014,10(1):170-171. [2](美)Zhaohui Tang,Jamie Maclennan.Data Mining With SQL Server 2005[M].北京:清华大学出版社,2007. [3]李佐军.基于关联规则兴趣度挖掘在招生管理中的应用[J].临沧师范高等专科学校学报,2014,23(1):136-140. [4]陈丽芳.基于Apriori算法的购物篮分析[J].重庆工商大学学报(自然科学版),2014,31(5):84-88. [5]李平荣.Apriori算法的研究与改进[J].喀什师范学院报,2014,35(3):35-37. [6]苏新宁,杨建林,等.数据仓库和数据挖掘[M].北京:清华大学出版社,2006.4 Apriori算法在高校招生中的数据挖掘





5 结束语
