实时数据仓库中一种改进的数据流更新算法
2014-06-07潘郑冰戴牡红
潘郑冰,戴牡红
(湖南大学软件学院,长沙410082)
实时数据仓库中一种改进的数据流更新算法
潘郑冰,戴牡红
(湖南大学软件学院,长沙410082)
为实现数据仓库中数据的高效集成,针对数据偏斜分布现象,提出一种改进的数据流更新算法EH-JOIN。该算法对传统散列连接方法进行改进,利用索引将部分频繁使用的主数据存储在内存中,解决了高速数据流下的磁盘频繁访问问题。实验结果表明,与MESHJOIN算法和R-MESHJOIN算法相比,EH-JOIN算法的服务速率在磁盘存储关系集保持适当大小时分别提高了96%和81%,在内存大小不同时提高了57%和48%。
实时数据仓库;数据转换;数据流更新;基于流的连接;哈希索引;偏斜分布
1 概述
为给企业提供及时有效的决策支持,实时数据仓库正在向数据新鲜度更高水平的方向发展,提供这些新的服务水平的工具和技术也正在迅速发展[1-2]。在实时数据仓库的环境下,数据更新中连接运算的选择主要取决于源数据的来源以及到达速率。源数据可能是突发性很强的大容量数据流,这会带来极大的磁盘I/O开销。由于存储在磁盘中查找表的访问速率相对缓慢,因此在连接操作中会出现瓶颈[3]。
为解决该问题,文献[4-5]提出一种MESHJOIN算法,特别针对一些如动态数据仓库的连续数据流和存储在磁盘中关系集的连接,但该算法对于连接组件之间的内存分配不够理想,而且访问磁盘存储关系采取的策略不够高效。文献[6]利用一种改进的算法解决了连接部件中内存的最佳分配问题。文献[7]提出基于分块的连接算法来改善MESHJOIN的性能,可以处理间歇的数据流。除此之外,还有一些研究更关注于实时数据流的连接响应效率问题,如PMJ算法[8]和RPJ算法[9],都支持在不用完全排序的基础上尽可能快地产生一小部分连接结果,以达到快速响应的效果。文献[10]采用多线程并发连接技术,合理调度了实时元组和准实时元组的执行。文献[11]提出一种支持服务质量的更新和查询的调度算法,实现了更新和查询的实时调度。
虽然MESHJOIN算法能有效地分摊快速的输入流带来的磁盘I/O开销,但它不能适应实际应用中的一般特征,比如在许多市场上少数产品具有较高的购买频率[12]。本文针对实际中常见的数据偏斜分布情况,提出一种改进的数据流更新算法:扩展混合连接算法(EH-JOIN)。EH-JOIN的关键特征是将存储在磁盘的关系集使用最多的部分存在内存中,使其与数据流中的频繁项相匹配。
2 基于数据流的连接
数据连接作为实时数据仓库的ETL(Extraction, Transformation,Loading)过程中常见的数据转换操作,通常表示为SR,其中,S表示特定的数据源;表示特定的连接操作;R表示数据仓库中的关系集合。如图1所示,对于实时数据流中的数据更新来说,S包含内容与到达速率都在不断变换的数据元组,到达的每一个元组都要和R完成连接操作。R是一个包含了大量主数据的关系集合,通常存储在磁盘中。在实际连接操作中,由于内存大小的限制,R不能全部导入到内存中,因此必须将R中的元组不停地读入有限的内存中,这就带来了巨大的I/O开销。当磁盘I/O速率比数据元组的到达速率慢时,就会造成连接操作的瓶颈,影响ETL的实时性。在MESHJOIN算法中,尽管R中的数据元组是分批读入到内存中的,这有助于分摊I/O开销,但对于每一批数据流元组,R都需完整地读入到内存中。而实际情况并不是R中所有元组都要和数据流中的数据元组做连接操作,这就导致很多无效元组被读入内存中,带来了很多无效的磁盘I/O。

图1 基于数据流连接的实例
3 一种改进的数据流更新算法EH-JOIN
3.1 基于索引的哈希连接结构
相比MESHJOIN,EH-JOIN有2个关键的改进: (1)修改了Hash连接组件让它可以利用索引。(2)将频繁使用的主数据缓存到内存中,极大地减少了I/O消耗。
EH-JOIN将基于磁盘存储的关系集R和数据流S相连接。假设R的连接属性有一个非聚集索引,并且这个连接属性对于主数据来说是唯一的。这种假设是很自然的,并且符合常见的应用领域,比如在密钥交换中。
EH-JOIN算法的体系结构如图2所示。该算法主要消耗内存的部分为磁盘缓存、哈希表、队列和数据流缓存,而存储在磁盘中的关系集R和数据流S作为输入流。假设R拥有连接属性的索引作为键。该算法将数据流元组存在哈希表中,该哈希表占用的算法内存最多。此外,本文算法还为数据元组提供了标识符,并将这些标示符存入队列中,tm队列需要支持随机删除,最简单的实现方法是双向链表。
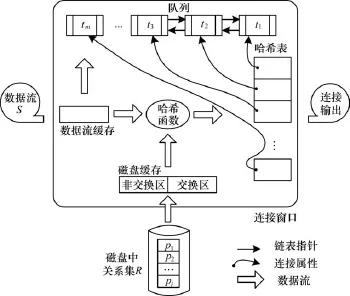
图2 EH-JOIN算法的体系结构
EH-JOIN是一种迭代算法,在每次迭代中,磁盘关系集R的一个分块作为一个探测输入。因此,这个分块被装载到磁盘缓存中且仅占用磁盘缓存的一部分。之后,本文算法执行了一个典型的哈希连接操作,即它遍历磁盘缓冲区的所有元组,并在哈希表中进行查找。每一次匹配成功,算法就会输出那个匹配的数据流元组。
同样地,在每次迭代中,EH-JOIN都会弹出匹配的元组。假设联接属性是R中唯一证明这个操作正确性的属性。弹出一个元组意味着同时从哈希表和队列中删除这个元组。本文算法还保留一个计数器ω来计算弹出元组的数目。在处理完整个磁盘缓存后,算法从数据流缓冲中读取ω个新元组,将它们装入哈希表中同时在队列中插入标识符。
为选择R中的下一个分块,EH-JOIN考虑队列中最旧的数据流元组的连接属性。利用索引,把R中具有该连接属性值的分块加载到磁盘缓存中,这样每个加载分块都至少可以和一个数据流元组匹配,进一步保持它的自适应性。
与MESHJOIN一样,EH-JOIN能在任何数据分布情况下工作。然而,在实践中,某些特定分布十分常见。目前研究表明,销售数据通常服从幂次法则,或者Zipfian分布[11]。符合幂次法则分布的主要区别在于它们的指数。指数等于1时,得到的分布满足Zipf定律,也就是通常所说的Zipfian分布。在商业中,80/20规则被用于模拟场景,当少量商品的出售频率远高于其他产品时,往往简化成80/20规则[11],该规则在商业应用中非常普遍。80/20规则对应于一个指数略小于1的幂次分布情况。
3.2 EH-JOIN算法
EH-JOIN算法具体如下:
输入 磁盘存储带有索引的关系集R以及更新数据流S
输出 S与R的连接
参数 S中ω个元组以及R中的一个分块pi

一旦将内存分配给连接组件,就开始按照上述步骤执行算法。在开始实际连接操作前,本文算法先将磁盘存储的关系集R中的一部分读进磁盘缓存的非交换区(第1行)。一开始,哈希表H是空的;因此,将hS赋给ω(第2行)。本文算法包含2层循环。一个是外层循环,这是一个无限循环(第3行)。外层循环的主要目的是把数据流压入到哈希表中。在外层循环中,还有2个独立的内层循环。一个是实现磁盘缓存非交换区的探测功能,另一个是实现磁盘缓存交换区的探测功能。外层循环一启动,算法就开始观测数据流缓存的状态。如果数据流可以读取,算法就从数据流缓存中读取ω个元组存入哈希表中,并将它们的属性值存入队列中。读完后算法将ω重设为0(第4行~第7行),然后开始执行第一个内层循环,遍历磁盘缓存的非交换区中的所有元组并在哈希表中查找它们。一旦有元组匹配,就产生一个连接输出。由于采用多重哈希映射表,因此一个磁盘元组可能有多个数据元组匹配。产生连接输出后,就从哈希表中删除所有匹配过的元组,并且从队列中删除它们对应的节点。哈希表中每删除一个元组,计数器ω就加1(第8行~第13行)。在开始第二个内层循环之前,算法读取队列中最旧的连接属性值,利用这个连接属性值作为索引将磁盘分块pi(2≤i≤n)读到磁盘缓存的交换区中(第14行~第15行)。当特定的磁盘分块被读入到磁盘缓存的交换区后,算法开始执行第二个内层循环,然后开始重复上述第一个内层循环的所有步骤(第16行~第21行)。
4 实验结果与分析
本文通过实验比较EH-JOIN算法和MESHJOIN算法,使用已知倾斜分布的合成数据集来做测试。
4.1 实验设置
实验设置具体如下:
(1)硬件说明:实验采用酷睿2处理器,2.13 GHz主频,4 GB内存,操作系统是Window XP,分配给测试程序的最大内存为250 MB。算法用Java实现,实验使用Apache内置插件和Java API,测量内存消耗和处理时间。
(2)数据说明:实验用指数为1的Zipf’s法则生成的数据来测试算法。所生成的数据流具有突发性和自相似性。本文使用MYSQL5.0数据库将关系集R存储在磁盘中,其中,关系集R大小为50万~800万个元组不等,每个元组为120 Byte,流数据中一个元组为20 Byte,队列的一个节点为12 Byte。为准确测量每一次I/O操作中的开销,将提取结果集合的大小和磁盘上一个分区的大小设置为相同。EH-JOIN算法需要在哈希表中一个键对应多个值,实验通过Apache提供的多重哈希映射表来实现。
(3)评价策略:定义服务速率作为算法的性能判断标准,服务速率越高,算法性能越好。服务速率是每秒中被处理的数据元组的个数。每次实验算法执行1 h。实验开始20 min后开始测量,连续测量20 min。为增加准确性,本文实验对每种规格采集3种数据,然后计算出平均值。
4.2 实验结果
将EH-JOIN算法与MESHJOIN算法、R-MESHJOIN算法进行实验,比较结果如下:
(1)性能比较:能够直接影响算法性能的2个参数是可用内存总量以及磁盘存储的关系集大小。在实验中,测试不同参数对算法的影响,并比较它们的性能。
(2)不同大小磁盘存储关系集下的性能比较,如图3所示,假设分配给连接的内存大小是固定的,同时磁盘存储的关系集大小呈指数级增长。如图3(a)所示,对于所有不同大小的关系集R,EH-JOIN的性能总体优于所有其他算法。在R保持适当大小时, EH-JOIN算法的服务速率比MESHJOIN算法提高了96%,比R-MESHJOIN算法提高了81%,即使由于R逐渐增到导致算法性能降低时,EH-JOIN相对于其他算法性能仍具有一定优势。
(3)可用内存大小不同时的性能比较:在第(2)组实验中,关系集R的大小固定为2×107个元组,分析EH-JOIN使用不同大小内存时的性能。实验结果如图3(b)所示。

图3 算法性能比较
实验数据表明,对于不同的内存大小,EH-JOIN的性能明显优于其他算法。在相同条件下,EHJOIN算法的服务速率比MESHJOIN算法提高了57%,比R-MESHJOIN算法提高了48%。可见,EHJOIN在磁盘缓存中保持一个交换区和一个非交换区对性能提升有较大作用。
非交换部分在数据流处理中的作用:为更好地了解磁盘缓存中非交换部分的作用,统计仅用磁盘缓存中的非交换部分处理的数据流元组,实验结果如图4所示,设置非交换部分的大小和交换部分的大小一样。

图4 4 000次迭代中非交换区处理的数据元组总量
从图4可以看出,在4 000次迭代中,当内存大小为50 MB,关系集R的大小为2×107个元组时,大约4×104个数据流元组要通过磁盘缓存中的非交换部分处理,而且如果实验增大整体分配的内存,那么这个数量还会增加。对于250 MB内存和同样大小的关系集R,这个数量会达到2×107以上。在其他算法中,由于这种非交换的部分每次从磁盘中载入,因此I/O成本会明显增加。
5 结束语
偏斜分布的数据集在实际应用场景中十分常见,而经典的MESHJOIN算法在这种数据集上进行连接操作的性能很差,因此,本文提出一种改进的数据流更新算法EH-JOIN,该算法使用磁盘存储的主数据的索引结构来迅速存取磁盘分块,并且缓存了主数据中使用最频繁的元组匹配数据流中的频繁项,大大减少了磁盘的访问量。实验结果表明,在不同磁盘关系集或者不同内存大小下,该算法都能在性能上得到较好的提升。在今后工作将进一步提高算法的内存使用效率。
[1] Karakasidis A,Vassiliadis P,Pitoura E.ETL Queues for Active Data Warehousing[C]//Proc.ofthe 2nd InternationalWorkshop on Information Quality in Information Systems.New York,USA:ACM Press, 2005:28-39.
[2] 林子雨,杨冬青,宋国杰,等.实时主动数据仓库中的变化数据捕捉研究综述[J].计算机研究与发展, 2007,44(z3):447-451.
[3] Golab L,Johnson T,SeidelJ S,etal.Stream Warehousing with Data Depot[C]//Proc.of the 35th SIGMOD International Conference on Management of Data.New York,USA:ACM Press,2009:847-854.
[4] Polyzotis N,Skiadopoulos S,Vassiliadis P,etal. Supporting Streaming Updatesin an Active Data Warehouse[C]//Proc.of the 23rd International Conference on Data Engineering.New Jersey,USA: IEEE Computer Society,2007:476-485.
[5] Polyzotis N,Skiadopoulos S,Vassiliadis P,etal. Meshing Streaming Updates with Persistent Data in an Active Data Warehouse[J].IEEE Transactions on Knowledge and DataEngineering,2008,20(7): 976-991.
[6] Naeem M,Dobbie G,Weber G.R-MESHJOIN for Nearreal-time Data Warehousing[C]//Proc.of the 13th InternationalWorkshop on Data Warehousing and OLAP.New York,USA:ACM Press,2010:53-60.
[7] Chakraborty A,Singh A.A Partition-based Approach to Support Streaming Up-dates over Persistent Data in an Active Data Warehouse[C]//Proc.of 2009IEEE InternationalSymposium on Parallel& Distributed Processing.Washington D.C.,USA:IEEE Computer Society,2009:1-11.
[8] Chandrasekaran S,Franklin M J.PSoup:A System for Streaming Queries over Streaming Data[J].The VLDB Journal,2003,12(2):140-156.
[9] Tao Yufei,Yiu M,Papadias D.Producing Fast Join Results on Streams Through Rate-based Optimization [C]//Proc.of ACM SIGMOD International Conference on Management of Data.New York,USA:ACM Press, 2005:371-382.
[10] 林子雨,林 琛,冯少荣,等.MESHJOIN*:实时数据仓库环境下的数据流更新算法[J].计算机科学与探索,2010,4(10):927-939.
[11] 师金钢,鲍玉斌,冷芳玲,等.实时数据仓库中支持QoS的更新和查询任务调度[J].小型微型计算机系统,2011,32(5):801-806.
[12] Erik B,Hu Yu,Duncan S.Goodbye Pareto Principle, Hello Long Tail:The Effect of Search Costs on the Concentration ofProductSales[J].Management Science,2011,57(8):1373-1386.
编辑 陆燕菲
An Improved Data Stream Update Algorithm in Real-time Data Warehouse
PAN Zheng-bing,DAI Mu-hong
(College of Software,Hunan University,Changsha 410082,China)
To achieve data efficient integration in data warehouse,aiming at the phenomenon of data skew distribution,this paper proposes an improved data stream update algorithm——Extended Hybrid Join(EH-JOIN).The algorithm improves the traditional Hash join method,and it can adapt to common skewed data and greatly reduce the disk I/O cost through using index structure and storing some parts of the master data in memory.Experimental results show that the service rate of proposed algorithm is improved by 96%and 80%compared with MESHJOIN algorithm and R-MESHJOUIN algorithm as the relation set keeps an appropriate size,and the service rate of proposed algorithm is improved by 57%and 48%compared with MESHJOIN algorithm and R-MESHJOUIN algorithm as the memory size differs.
real-time data warehouse;data transformation;data stream update;stream-based join;Hash index; skewed distribution
1000-3428(2014)10-0043-04
A
TP311.13
10.3969/j.issn.1000-3428.2014.10.009
湖南省自然科学基金资助项目(2011FJ3034)。
潘郑冰(1988-),女,硕士研究生,主研方向:数据库技术,决策支持,知识工程;戴牡红,副教授。
2013-08-13
2013-10-12E-mail:panzhengbing@163.com
中文引用格式:潘郑冰,戴牡红.实时数据仓库中一种改进的数据流更新算法[J].计算机工程,2014,40(10):43-46,51.
英文引用格式:Pan Zhengbing,Dai Muhong.An Improved Data Stream Updating Algorithm in Real-time Data Warehouse[J].Computer Engineering,2014,40(10):43-46,51.
