基于扩展查询表达式的XML关键字查询
2014-06-07朱菁华王晓玲
朱菁华,王晓玲
(复旦大学计算机科学技术学院,上海200433)
基于扩展查询表达式的XML关键字查询
朱菁华,王晓玲
(复旦大学计算机科学技术学院,上海200433)
目前可扩展标示语言(XML)关键字查询大多是基于最小公共祖先(LCA)语义子树产生查询结果,而未能加入除LCA语义子树之外与用户查询意图相关的结果。为解决该问题,提出一种基于扩展查询表达式的XML关键字查询方法。将用户查询日志作为查询扩展统计模型,对其进行统计分析,并结合最佳检索概念判断是否需要扩展查询表达式。使用XML TF-IDF方法计算候选属性的权重,根据初检结果的上下文信息,利用聚类方法获得与查询意图最相关的扩展查询关键字,从而扩展查询表达式。实验结果表明,与XSeek和基于语义词典的查询扩展方法相比,该方法的平均F度量值分别提高了7%和17%,具有较高的查询质量。
信息检索;可扩展标示语言;最小公共祖先语义;关键字查询;查询扩展;上下文信息
1 概述
信息检索中的一个主要挑战就是如何精确判断用户的查询意图,而关键字查询方式由于缺乏足够的结构和语义信息,使得其查询结果往往无法令用户满意。如今,可扩展标示语言(eXtensible Markup Language,XML)由于其灵活性等优点,被广泛应用于Web上。所以,如何帮助用户产生精确的查询表达式对于XML关键字查询是很有必要的。
目前,XML关键字查询的研究大多都是基于最小公共祖先(Lowest Common Ancestor,LCA)概念来确定相关语义片段子树[1]。针对LCA存在嵌套的问题,文献[2]提出了最近最小公共祖先(Smallest LCA,SLCA)。SLCA是一个最小LCA子树,包含所有关键字且该子树的任一子树都不再包含所有关键字。
虽然现在多数的XML关键字查询方法通过对LCA语义片段的裁剪能有效地去除不相关的信息,但它们都是只针对LCA子树中的内容进行裁剪,而把LCA子树外的内容认为是不相关的。显然这样的查询结果未必能满足用户的查询意图。由于XML文档层次特点与用户查询意图相关的内容完全可能不在LCA子树中,而基于多数LCA语义的XML关键字查询方法,虽然可以过滤与查询不相关的信息,但也会降低查询的查全率。
为解决该问题,因此本文提出一种基于扩展查询表达式的方法。总结了多数基于LCA语义的XML关键字查询方法工作,并指出了它们的不足之处,即查询结果受限于LCA语义子树,未能加入LCA语义子树外并与用户查询意图相关的结果。本文主要解决了2个问题,即判断查询表达式是否需要扩展和查询表达式如何进行扩展。新的查询表达式的检索结果与初检结果相比,会添加未被LCA语义子树包含但与用户查询意图相关的信息,从而实现“内容+结构”的XML关键字查询扩展。
2 相关工作
XSeek[3]是基于LCA语义子树的XML关键字查询的一个比较典型的方法。该方法借鉴关系数据库中的ER模型思想为XML树中的节点分类,同时用类似于XQuery的语法分析了关键词查询匹配模式,结合两者生成的语义信息对SLCA子树进行裁剪。图1是一个eBay在线拍卖的数据的XML树。对于查询{Seller Tony},观察查询语义可以猜测用户想了解卖家Tony的相关信息。XSeek方法只返回图中以“Seller”为根节点的子树,而把其他内容认为是不相关的。显然这样的查询结果未必能满足用户的查询意图,用户完全可能对Payment和Shipping等信息感兴趣。

图1 eBay在线拍卖的XML文档树
目前,国内外的查询扩展方法主要有3类:对语料库或知识库分析后的扩展,局部分析方法和全局分析方法。根据语料库获得的查询扩展方法是利用语义知识词典,然后甄选与初始查询关键字概念相近或等同的词来进行查询扩展。如文献[4-5]以WordNet为语义本体,能同时对查询关键字的狭义词、广义词、同义词和近义词等进行匹配,有效地提升查询质量。但是,这种方法有着十分明显的缺陷,即其扩展的查询关键字往往受限于参考的语料库,并且只是简单地根据语义概念进行链接,从而导致很多无关的关键词加入查询表达式,进而影响查准率。文献[6-7]以查询日志作为语料库进行分析和数据挖掘,能较好地保证扩展用词和原查询以及查询结果是相关联的。但是其未能考虑诸如XML文档这样的半结构化数据,只适用于传统的文本文档。
局部分析方法的核心思想是通过连续2次的查询来解决查询表达式扩展问题。通过初次查询获得最相关的K个结果作为查处扩展词的来源,然后,将权值较高的N个词加入查询表达式进行新的查询[8]。目前较流行的有相关反馈方法和伪相关反馈方法[9]。虽然局部分析方法是目前十分受欢迎和普通应用的查询扩展方法,但其查询质量十分依赖初检结果的相关性。换言之,如果第一次查询后获得文档与用户查询意图相关度较小时,其查询扩展的质量较差。
以相似性词典[10]等为代表的全局分析方法是在用户提交查询前,对所有文档中的词或词组进行统计分析,并计算各个词或词组间的关联程度。当用户提交查询后,根据先前计算的词或词组间的相关关系,把与查询相关的词添加获得扩展后的查询表达式。全局分析方法的优势是可以十分有效地探究数据集中的词间关系,但是这种方法仅限与符号层面的匹配,而无视了查询关键词与目标文档语义上的关联程度。同时,当数据集大小逐渐增大后,该方法在时间和空间上的开销也十分高昂。
文献[11]提出了结合2种扩展方式的方法。该方法基于对初检结果以及查询日志的分类和数据分析,获得相关的扩展词。虽然该方法不仅面向XML数据,同时也取得了较优的查询质量,但是其查询扩展表达式仍旧是对LCA语义子树的裁剪分类,未能有效考虑潜在的相关联的信息。
3 数据模型
由于XSeek方法有较好的查询质量,因此本文提及的查询结果子树均是指用XSeek方法产生的LCA子树。通过分析大部分XML文档树,可以发现XML文档树都是具有一定的语义,可以把XML文档树的节点从语义角度分为3类节点:值节点,属性节点和实体节点。
定义1(值节点) 称XML文档树T中叶子节点为值节点。例如,图 1中的“Tony”和“848”等节点。
定义2(属性节点) 称XML文档树T中值节点的父亲节点为属性节点。例如,图 1中的“SellerName”节点。
定义3(实体节点) XML文档树T中的节点若既不是属性节点也不是值节点,那么称该节点为实体节点。例如,图1中“Seller”和“HighBidder”等节点为实体节点。
对于XML文档中既有叶子节点又有非叶子节点作为孩子节点的情况,认为该节点属于实体节点。
定义4(查询结果子树) 对于一个查询Q和XML文档树T,按XSeek方法获得一颗子树t称作查询结果子树。
定义5(实体序列) 对于查询结果子树t,按先后次序遍历并记录其中的实体节点,所产生的序列称作实体序列。
定义6(查询上下文) 对于一个关键字查询Q,其查询上下文是:

其中,域ES为查询结果子树的实体序列;域WHE表示了查询Q的限制条件,类似于SQL中的where集合;域SEL为查询想要获取的信息,类似于SQL中的select集合。
由于XML文档为半结构化数据且关键词查询方式不包含任何结构信息,一个明显的问题是如何确定域WHE和SEL的值。观察SQL语言可知,查询限制条件往往是包含了具体数值信息,而查询目的则往往只提供不带数值信息的数据类型信息。根据定义1~定义3可知,实体节点和属性节点对应于数据类型信息,而值节点则对应数据值类型。根据以上分析并结合文献[12]对XML关键词查询匹配模式的研究,本文由以下2个原则分别确定域WHE和SEL的值:
(1)如果关键字查询中的某个关键字k1匹配某个实体节点或者属性节点,且不存在另一个关键字k2满足:匹配某个值节点,且该值节点与k1匹配的节点存在祖先-后代关系。那么关键字k1表示该查询想要获取的信息内容,k1会被添加至SEL域中。
(2)未被添加至域SEL的关键字,即与值节点匹配的关键字,为查询的限制条件,会被添加至域WHE。
4 扩展查询表达式的判断
显然,不是所有的查询表达式都要扩展,有些能完全满足查询意图。因此,需要判断哪些需要扩展。
4.1 查询结果分析
通常,用户提交了查询Qi后,如果其查询结果子树是相关的但缺少部分感兴趣的内容,会在Qi的基础上提交新的查询Qj。对于2个连续查询Qi和Qj,如果Qj是对Qi的扩展,那么它们两者有一定的联系。
例如,对图 1的 XML文档树,如果 Qi是{IBM},Qj是{IBM Seller},Qi的查询结果子树以“ItemInfo”为根节点,Qj的查询结果子树是Qi的查询结果子树加上以Seller为根节点的子树。比较它们的查询上下文可以发现:Qi的ES是Qj的ES的子集,即Qj的结果是Qi的结果的结构上的扩展;它们的查询限制条件,即域WHE,均为“IBM”,都是想查询和“IBM”相关的信息,可以说它们的查询意图有一定的交集。不同的是 Qj还指出想要获取“Seller”的信息。因此,可猜测Qj的查询结果是对Qi的查询结果的扩充。换言之,查询表达式Qj是对查询表达式Qi的扩展,即{IBM Seller}才是真正能获得满足用户兴趣的查询。因为如果Qi的结果是正确的但不能完全满足查询需求时,从语义上看,用户不会改变他的查询限制,但会加入新的查询意图,而从结构上看,Qj的查询子树会比Qi的“大”且包含Qi的整个查询子树。
另外一个例子,如果Qi是{Tony SellerRating}, Qj是{Seller Tony ItemInfo}。虽然Qj在结构上是对Qi的扩充,但显然它们不是感兴趣的查询结果扩展。因为它们不存在任何语义连续性。显然Qi只是对属性“SellerRating”的值感兴趣,而Qj则是对“Seller”为“Tony”所拍卖的物品信息感兴趣。通过观察它们查询上下文的域WHE便可作出判断。因此,在这种情况下,Qj不能作为Qi的查询扩展表示式。
定义7(查询表达式扩展) 对于2个连续的查询Qi和Qj,如果Qj是对Qi的查询表达式扩展,那么必须满足以下条件:

4.2 查询表达式扩展决策策略
本文中查询表达式扩展的目的是为原本的查询结果添加更多与查询意图相关的信息,即可等价看作查询结果的扩展。本文对于每一个查询表达式的扩展,等同于查询结果子树的扩展,同时也可看作是对该实体信息的扩展。
根据定义7对查询日志进行分析和统计,可以得到每个实体信息的查询结果扩展几率。显然,每一个查询结果的扩展操作都会对搜索引擎带来额外的开销。众所周知,用户不仅要求搜索引擎可以返回相关的结果,同时也希望获得良好的查询处理时间。所以,对于确定哪些实体需要被扩展这个问题便转换为确定哪些实体的结果扩展具有较高的收益和较低的代价。
定义8(查询表达式扩展代价) 对于2个查询Qi与Qj,及其相应的原始结果i和扩展结果j,从i扩展到j的代价是从i的根节点出发到j同时满足如下2个条件的节点的路径和:
(1)该节点只存在于j中而不存在于i中;
(2)该节点出现在Qj的查询上下文中的域SEL内。
仍以图1所示的XML文档树为例,如果Qi为{IBM},Qj为{IBM Seller}。由定义7可知,Qj的结果是Qi结果的扩展。此外,从定义6可知,域SEL的内容反映每个查询的意图,而查询表达式扩展的目的是尽可能给用户提供所有相关的信息。因此,如果要对当前的查询表达式扩展只需添加最终结果中的域SEL中的节点信息。对Qi的查询表达式扩展应该添加属性“SellerName”和“SellerRating”。因此,根据定义8,对Qi查询表达式扩展代价是从节点“ItemInfo”到节点“Tony”和“848”的路径长度之和,为8。
结合文献[13]中的最佳检索概念和概率排序原则,得到确定是否对结果(即实体)进行扩展的决策策略:
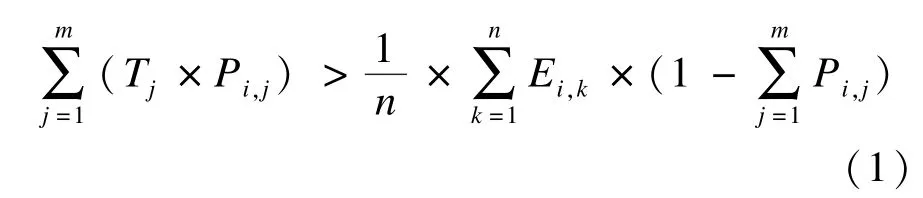
其中,Pi,j表示从初始结果i到最终结果j的扩展概率;m为初始结果i有m种不同的最终结果;Tj表示生成结果j的代价,这里用该树中边的数目总和表示;Ei,k表示把初始结果i扩充到最终结果k的扩展代价。
由于对用户查询意图猜测是一个概率问题,很难完全确定当前结果是否能完全满足用户的查询意图,因此该决策策略要求右半部分值小于左半部分值,即要求如果为i进行结果扩展,那么该操作带来的收益应该大于该操作本身增加的系统负载。
5 扩展查询表达式的上下文信息添加
定义9(候选属性) 对于XML文档树中任意一个属性节点a和任意一个实体节点e,如果a不在以e为根节点的子树里,那么属性a称作是实体e的候选属性。
对于给定的实体e,把其所有的候选属性构成的集合称为候选属性集。如果要扩展当前查询表达式,那么需要添加的上下文信息必定在该查询结果子树对应的实体的候选属性集中。显然,不同的候选属性其权重也不同。根据 TF-IDF方法的思想[14],利用XML TF-IDF方法计算各候选属性的权重,计算方法如下:


在完成了对候选属性计算权重后,接下来是对不同的实体,确定添加多少候选属性。本文使用非加权组平均法(Unweighted Pair Group Averaging Method, UPGMA)[15]为每个实体的候选属性集进行聚类,聚成2类。然后计算2个聚类的平均权值,舍弃最低的那个。剩余的那个聚类中的候选属性可作为该实体对应的查询表达式的扩展部分。
6 系统实现
图2显示了基于扩展查询表达式的系统结构,该系统分为在线和离线两部分。
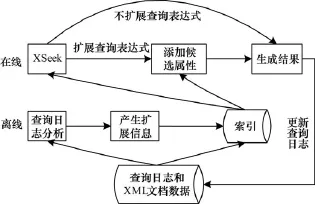
图2 基于扩展查询表达式的系统结构
在线部分的工作具体如下:
(1)当用户提交一个查询后,系统用XSeek方法生成初步结果;
(2)当前查询表达式不需要被扩展时,则直接输出结果;
(3)当前查询表达式需要被扩展时,系统会从离线生成的索引系统中快速获取需要添加的信息(即候选属性值),然后根据新的查询表达式用XSeek输出结果;
(4)对于每一个查询,系统输出结果的同时会按照设定记录该查询的相关内容。
离线部分主要工作为:保存XML文档和查询日志,查询日志统计分析和更新日志等信息。
值索引主要负责按照文档顺序存储和关键字匹配的各个节点的Dewey编码,以快速获得和关键字匹配的节点,该索引类似于倒排索引。
当给定一个Dewey编码时,Dewey索引负责提供给系统该节点的“入口”,包括该节点的名称、孩子节点的数目、指向孩子节点和父亲节点的指针以及该节点的类型(实体节点或属性节点或值节点)。因为系统会经常遍历连续的Dewey编码,而B+树的结构能够改进局部地区数据检索较为集中情况下的效率,所以Dewey索引通过B+树的形式实现。
7 实验结果与分析
7.1 实验设置
实验运行在一台操作系统是64位Windows 7企业版的计算机上,CPU为Intel i5 2.50 GHz处理器,物理内存为8.0 GB。实验中的XML文档均来自于文献[16]:关于UWM大学课程信息和关于eBay在线物品拍卖交易的数据。
将本文方法与XSeek和基于语义词典的查询扩展[5]方法进行比较,包括查准率、查全率和 F度量值[17]。
7.2 查询质量对比
实验首先用XSeek方法生成系统,以用户一个月内用该系统产生的4 982条记录作为日志进行分析统计工作。
对于评价查询的效果,最终用户通常最有发言权。因此,邀请5位志愿者参与到实验评估中。由于XML数据查询结果信息的主要载体是属性名称和其属性值,因此对于XML关键字查询,查询结果是否能满足查询需求就是判断其感兴趣的属性是否出现在结果中。为了引导他们为每个查询结果定义一个可用于评估的基准,该5位用户获悉了2个数据集所有的属性名称和其相关的语义。除此之外,他们并不知晓DTD和属性层次分布等信息,从而保证实验的真实性与可靠性。这些用户为每个数据集提供了5个查询测试用例,如表1所示。限于篇幅,表2、表3显示了部分查询测试用例使用本文方法后扩展的查询表达式以及用户给出的查询意图。
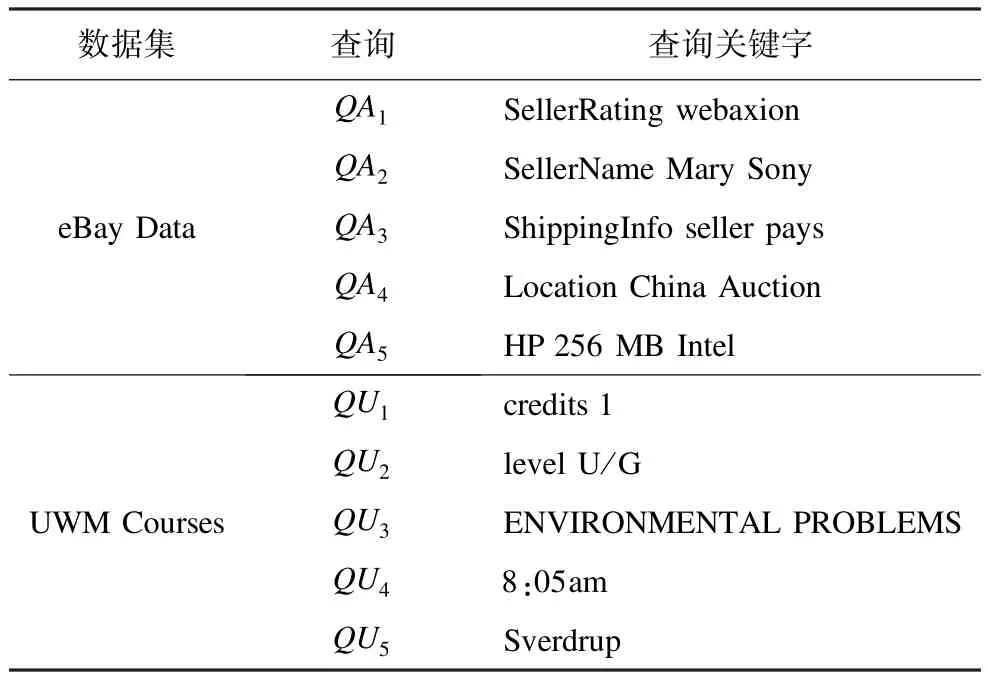
表1 查询测试用例

表2 原始查询与扩展查询
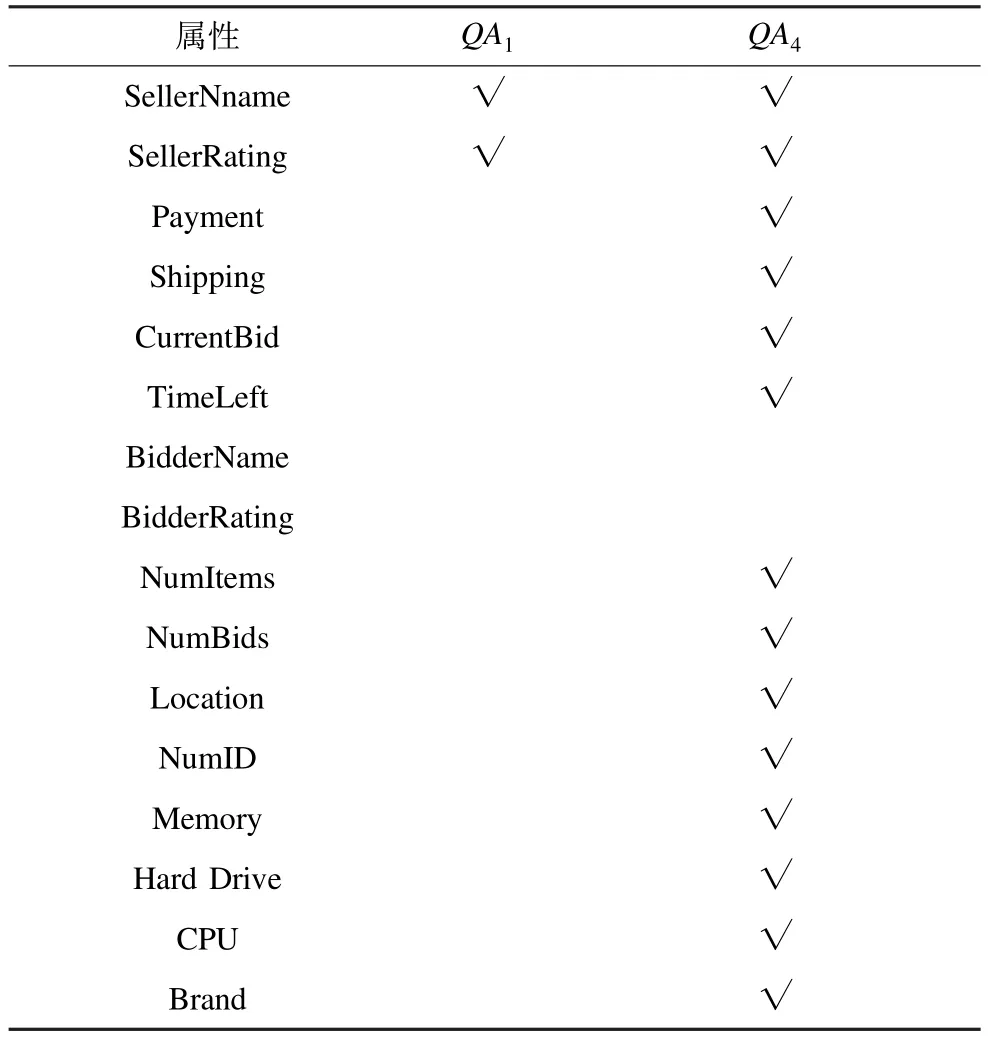
表3 QA1和QA4查询
7.2.1 查准率与查全率
查准率与查全率的计算方法如式(3)和式(4)所示:
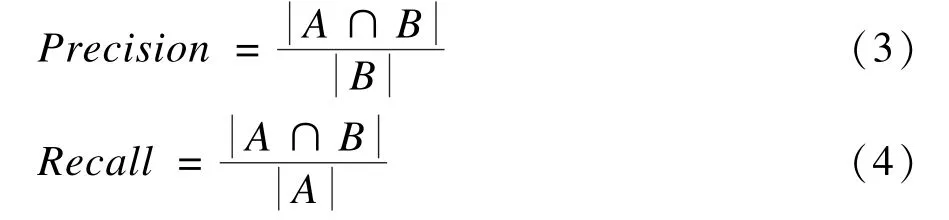

表4显示了查准率实验数据。对于QA1,本文方法的查准率远低于XSeek方法,可以发现原因是QA1想查找满足条件 SellerName为 wenaxion的SellerRating属性值,可猜测该用户只对该属性内容感兴趣。在这种情况下,对实体SellerInfo的扩展是多余的,因此,导致了本文方法对于QA2查准率数值偏低。而对于和QA1相似的查询QA2,可判断QA2的查询意图是寻找售卖Sony电脑的卖家Mary的相关信息。对于QA2,本文查询扩展添加的属性多数都是和查询相关的,所以本文方法对于QA2的查准率比QA1高的多。从表4可知,在多数情况下本文方法的查准率与XSeek、基于语义词典的查询扩展方法较接近。
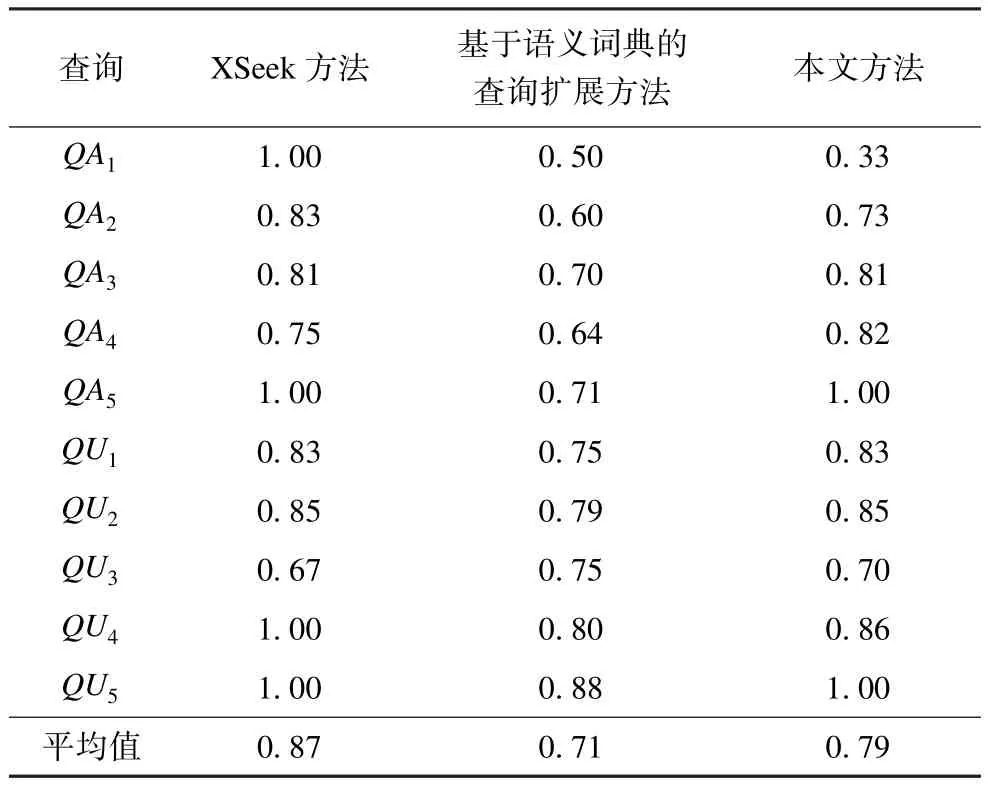
表4 查准率结果对比
表5显示了查全率实验数据。对于QA2,XSeek方法产生的结果仅限于LCA子树。由上文分析可知,该查询意图显然不止该子树,而本文方法的查全率数据明显较优。从表5可以发现,本文方法在查全率方面优于XSeek和基于语义词典的查询扩展方法,说明了本文方法对于改进查询质量的有效性。
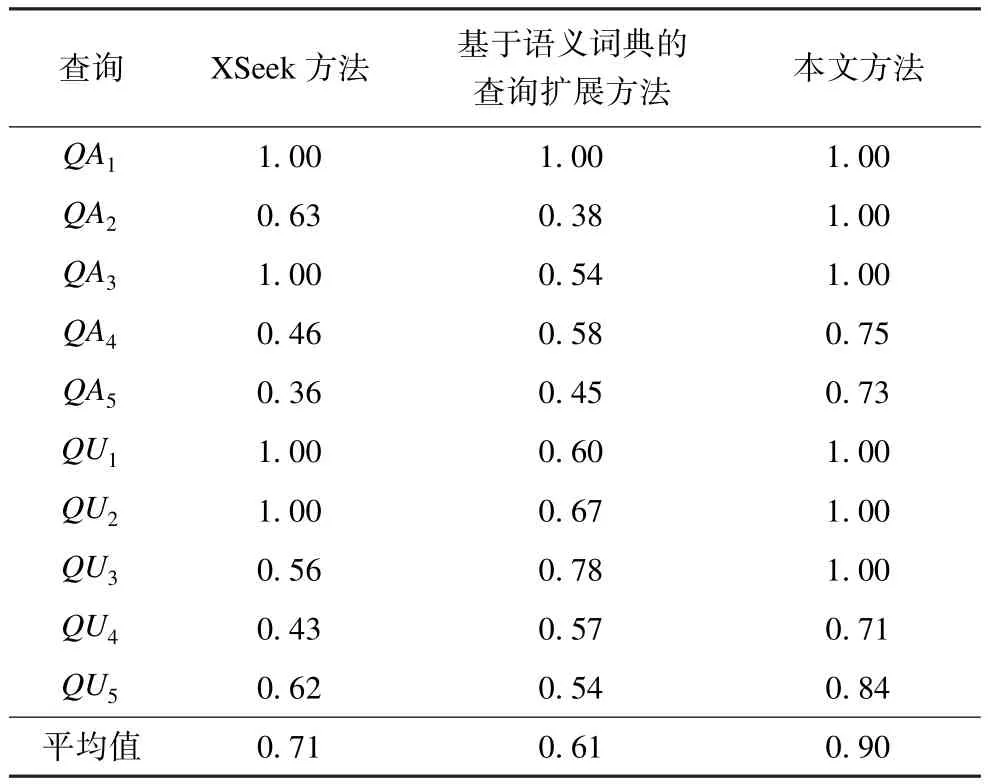
表5 查全率结果对比
7.2.2 F度量值
为同时考虑查全率和查准率,使用F度量值作为查询质量评价的标准,计算方法如下所示:

其中,a用于衡量两者的权重。如果a=1则认为两者同样重要;如果a=0.5,则认为查准率更重要;如果a=2,则认为查全率更加重要。本文认为两者同样重要,因此a=1。
表6显示了F度量值实验数据。基于语义词典的查询扩展方法由于其扩展词来源过度依赖知识库,而忽略了用户查询用词与XML文档间的语义联系,因此其查准率、查全率和F度量值均未优于本文方法。综合衡量所有查询测试用例的查全率和查准率实验数据,可以发现,本文方法在多数情况下都要优于XSeek方法,由此证明本文方法的有效性。

表6 F度量值结果对比
8 结束语
本文重点研究了如何通过查询表达式扩展的方法改进XML关键字查询技术。通过扩展查询表达以及添加查询表达式的上下文信息,实现本文方法,并对查询日志进行数据挖掘,减少了表达式扩展方法对知识库或初检结果的依赖。实验结果表明,本文方法对查询质量,尤其是查全率和F度量值,起到了一定的优化作用。今后将考虑如何更加准确地判断查询意图和解决LCA查询语义二重性问题,使本文方法具有更好的普适性。
[1] Vagelis H,Nick K,Yannis P,et al.Keyword Proximity Search inXML Tree[J].IEEE Transactionson Knowledge and DataEngineering,2006,18(4): 525-539.
[2] Xu Yu,Papakonstantinou Y.Efficient Keyword Search for Smallest LCAs in XML Databases[C]//Proceedings of 2005 ACM InternationalConferenceonSpecial Interest Group on Management of Data.New York, USA:ACM Press,2005:529-538.
[3] Liu Zhiyang,ChenYi.IdentifyingMeaningfulReturn Information for XML Keyword Search[C]//Proceedings of 2007 ACM International Conference on Special Interest Group on Management of Data.New York,USA:ACM Press,2007:329-340.
[4] Snasel V,Moravec P,Pokorny J.WordNet Ontology Based Model for Web Retrieval[C]//Proceedings of 2005 International Workshop on Challenges in Web Information Retrieval and Integration.[S.l.]:IEEE Computer Society,2005:220-225.
[5] 王水利,黄广君,霍亚格.基于语义分析的查询扩展方法[J].计算机工程,2011,37(16):77-79.
[6] Cui Han,Wen Jirong,Nie Jianyun,et al.Probabilistic Query Expansion Using Query Logs[C]//Proceedings of the 11th International Conference on World Wide Web.New York,USA:ACM Press,2002:325-332.
[7] Chirita P A,Firan C S,Nejdl W.Personalized Query Expansion for the Web[C]//Proceedings of the 30th International Conference on ACM Special Interest Group on Information Retrieval.New York,USA:ACM Press, 2007:7-14.
[8] Xu J,Croft W.Improving the Effectiveness of Information Retrieval with Local Context Analysis[J]. ACM Transactions on Information Systems,2000,18 (1):79-112.
[9] Ricardo Y B,Berthier N R.Modern Information Retrieval[M].[S.l.]:Pearson Education Limited, 1999:16-65.
[10] Qiu Yonggang,Frei H.Concept Based Query Expansion [C]//Proceedings of the 16th International Conference on ACM SpecialInterestGroup on Information Retrieval.New York,USA:ACM Press,1993:160-169.
[11] Liu Ziyang,NatarajanS,ChenY.QueryExpansion Based on Clustered Results[J].Proceedings of the VLDB Endowment,2011,4(6):350-361.
[12] Bao Zhifeng,Ling T W,Chen Bo,et al.Effective XML Keyword Search with RelevanceOriented Ranking [C]//Proceedings of 2009 IEEE International Conference on Data Engineering.Washington D.C., USA:IEEE Computer Society,2009:517-528.
[13] Chauduri S,Das G,Hristidis V,et al.Probabilistic Ranking of Database Query Results[C]//Proceedings of the 30th International Conference on Very Large Data Bases.[S.l.]:ACM Press,2004:888-899.
[14] Paik J H.A NovelTF-IDF WeightingSchemafor Effective Ranking[C]//Proceedings of the 36th International Conference on ACM Special Interest Group on Information Retrieval.New York,USA:ACM Press, 2013:343-352.
[15] Helmer S.Measuring the Structural Similarity of Semistructured Documents Using Entropy[J].The VLDB Journal,2012,21(5):1022-1032.
[16] UW XML Data Repository[EB/OL].(2012-05-17). http://www.cs.washington.edu/research/xmldatasets.
[17] Croft B,Metzler D.Search Engines:Information Retrieval in Practice[M].[S.l.]:Addison-Wesley,2009:286-287.
编辑 陆燕菲
XML Keyword Search Based on Extended Query Expression
ZHU Jing-hua,WANG Xiao-ling
(School of Computer Science,Fudan University,Shanghai 200433,China)
Most existing eXtensible Markup Language(XML)keyword searches are based on Lowest Common Ancestor(LCA)semantics tree to generate search result,but they do not consider the data which is not included in LCA semantics tree while is relevant with user search intention.To solve this problem,an XML keyword query method based on extended query expression is proposed.The query expansion statistical model is based on user query log.Through analyzing query log and combined with optimal retrieval concept,it can judge whether the query expression should be expanded.After that,an XML TF-IDF method is employed to calculate the weight of candidate attribute.According to the context information and using cluster method,it gets the query expression keywords which are most relevant with search intention.Then the expanded query expression is generated.Compared with XSeek and semantics dictionary based query expression method,experimental result shows this method can improve the query quality by average 7%and 17%in F-measure respectively.
information retrieval;eXtensive Markup Language(XML);Lowest Common Ancestor(LCA)semantic; keyword search;query expansion;context information
1000-3428(2014)10-0025-07
A
TP391
10.3969/j.issn.1000-3428.2014.10.006
国家自然科学基金资助项目(60773075)。
朱菁华(1985-),男,硕士研究生,主研方向:XML信息检索,数据库技术;王晓玲,教授、博士。
2013-11-05
2013-11-27E-mail:jh_zhu@fudan.edu.cn
中文引用格式:朱菁华,王晓玲.基于扩展查询表达式的XML关键字查询[J].计算机工程,2014,40(10):25-31.
英文引用格式:Zhu Jinghua,Wang Xiaoling.XML Keyword Search Based on Extended Query Expression[J]. Computer Engineering,2014,40(10):25-31.
