具有权重因子的细粒度情感词库构建方法
2014-06-07黄高峰周学广
黄高峰,周学广,李 娟,刘 华
(1.海军工程大学a.信息安全系;b.计算机工程系,武汉430033;2.75753部队,广州510600)
具有权重因子的细粒度情感词库构建方法
黄高峰1a,周学广1a,李 娟1b,刘 华2
(1.海军工程大学a.信息安全系;b.计算机工程系,武汉430033;2.75753部队,广州510600)
情感词库在文本情感分析中发挥重要作用,但在分析细粒度情感如人类情绪状态时却无法正确区分。针对该问题,提出一种基于义原相似度计算的细粒度情感词库构建方法。对词语之间的义原相似度进行计算分析,构建7类细粒度情感词库,并在此基础上给出细粒度情感词在词库中的权重计算方法,最终得到7类具有权重值的细粒度情感词库。实验结果表明,应用引入权重的细粒度情感词库后,文本情感倾向判别的准确率可提升5%左右。
义原相似度;情绪;细粒度情感;权重计算;权重因子;词库构建
1 概述
目前,中文语言处理领域已经存在一些通用的情感词库,它们在文本情感分析中发挥了重要作用,然而,它们在细粒度情感分析上发挥的作用还非常不足。主要表现为:已存在的通用情感词库主要有正极性词库、负极性词库等,不论是对句子的情感分析,还是对文档的情感分析,较多的是侧重褒义、贬义还是中立,然而,有时人们更想得到是用户对于某个主题对象所表现的内心的情绪,比如高兴、忧愁、悲伤、愤怒、喜爱等细粒度情感,从而可以提取更为有价值的信息,而这些是传统词库无法做到和区分的。因此,构建能反映用户心理状态的细粒度情感词库显得尤为必要。
文献[1]通过分析《知网》的知识描述结构,利用义原的上下位关系计算词语义原相似度;文献[2]考虑层次树的深度、密度及语义路径等多因素对义元相似度计算影响,对词汇语义相似度计算进行了改进;文献[3-5]分别对中文基础情感词进行了扩展,并对基准词的应用进行了相关研究,取得了不错的效果;文献[6]利用词语极性评分进行语句级的观点抽取。大量文献提供了文本情感分析的典型方法,但文献中均未曾提及对细粒度情感词分类及词库构建的相关研究。
本文以义原相似度计算为基础,提出一种表现人类情绪的细粒度情感词库构建方法,并针对词库所含词语设计一种权重值计算方法,从而实现文本中所表现情绪状态的准确分类。
2 细粒度情感词的区分
人类情感非常丰富,儒家学派把人类情感表述为七情:喜,怒,哀,惧,爱,憎,欲。举例,表达“喜”的词语:高兴,兴奋,快乐,喜悦等;表达“怒”的词语:愤怒,恼怒,气愤,愤慨,怒火冲天,大发雷霆等;表达“爱”的词语:喜爱,可爱,爱惜,怜悯,怜爱,同情,感激等;表达“欲”的词语:期望,渴望,期盼,盼望,失望,思念等。这里的七情中的“欲”,实际是对人类“七情六欲”中“六欲”:见欲,声欲,香欲,味欲,触欲,意欲的总称,泛指人类生理需求和欲望,把这些统一归类为一种人类情感。
相似度是一个数值,一般取值范围在[0,1]之间。一个词语与其本身的语义相似度为1。如果2个词语在任何上下文中都不可替换,那么其相似度为0。本文通过对情感词的相似度计算,得出一个能反映其情感倾向强度的权值来区分细粒度情感词。知网中词语相似度是以词的义原为基础计算得来。知网中将同类的义原组成一棵层次树,《知网》中层次结构如图1所示,因而把义原的相似度计算转化为义原之间在层次树中的路径距离的计算。
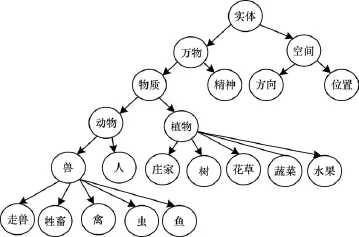
图1 实体类义原层次树
假设两个词语W1,W2的2个义原s1,s2在这个层次体系中的路径距离为dist(s1,s2),则这两个义原的义原相似度如式(1)所示。

其中,s1和s2表示两个不同义项之间的义原;dist(s1,s2)表示它们在义原树中的距离;∂是一个调节参数,表示相似度为0.5时的两个词在义原树中的距离长度,一般取1.6。一个词语有时存在多个义原,在计算多义原词语间的相似度时,取义原之间相似度最大值作为词语的相似度。对于两个中文词语W1,W2,假设它们分别有多个义原,W1的义原m个,分别为s11,s12,…,s1m;W1的义原n个,分别为s21,s22,…,s2n,则它们的相似度计算如式(2)所示。
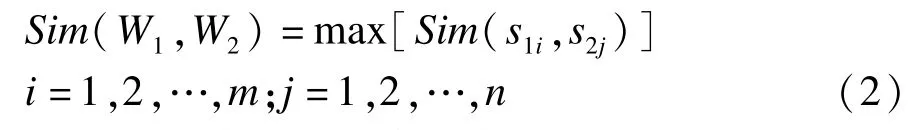
细粒度情感词的情感权值大小由这个词与基准词的义原相似程度有关,基准词是指那些表达情感非常明显、最常用的、具有代表性的词语。与基准词联系越紧密,则词语的倾向性越强。因此,可以通过计算细粒度情感词与基准词之间的义原相似度来区分不同的细粒度情感词汇。
但是,要注意的是相似度的大小表示的是趋近于某种情感的程度而不是情感强度。比如表达“喜”的词中,词频最高的是“高兴”一词,利用上述公式判断某个词与“高兴”的相似度越大表示该词越准确地在表达“喜”的情感。再如“喜极而泣”的词频就没有“高兴”的词频高,但比“高兴”所表达的“喜”的情感强度更强。
3 细粒度情感权重词库的构建
3.1 种子词集的生成
若要判别一个词是否属于细粒度情感词,只用一个基准词进行情感相似度计算所得到的准确性是有限的,这时需要有若干个基准词构成一个基准词集,再由基准词集计算该新词的相似度值,这样就能更准确地判断某个词语的情感类别,该基准词集称为种子词集。
种子词的选择,必须选取若干个表达某类情感强烈且最常用的词[7]。由《知网》提供的情感分析词语集对表达7类情感较强烈的词进行人工筛选[3],再利用搜索引擎对这些词语的使用条目数进行统计,该词语的使用条目数即认为该词的词频,选取词频最高的前n个词作为备选种子词,这里的n根据该类情感词的高频常用词的数量来定,高频常用词的数量越多n就越大,反之n就越小。再在n个词中人工进行情感强度判断,得出较准确的表达该类情感强烈且最常用的m个词,即为该类细粒度情感种子词集。一般m≈15% ×n最佳[3]。
3.2 细粒度情感词库构建
针对细粒度情感词库的构建,本文提出了一种通过情感种子词集与情绪词库进行义原相似度计算,再进行阈值比较并归类的构建方法,依次可生成7类词集,具体流程如图2所示。

图2 细粒度情感词库构建流程
实验过程如下:
(1)对情绪语料进行分词、去噪处理。
(2)从词语库取出某个词与7类情感种子词集分别进行义原相似度计算,按式(2)进行运算。
(3)把运算结果进行阈值比较,阈值范围的定义为[0.75,1],若相似度在阈值范围内的词最终判决属于细粒度情感词;若相似度在(0.25,0.75)之间的属于不确定词集,进行人工筛选;若相似度在[0,0.25],则最终判决该词不属于此类情感词,直接丢弃。
实验中需要注意的是情绪语料库要求尽可能详尽,能较全面地涵盖基本情感词语。
3.3 情感词权重计算
假设选定用seedi,j代表第j类情感的种子词,i表示该j类情感种子词的序号,总数为Q。情感词语α在第j类情感的情感倾向值(Sentiment Orientation,SO)用soj(α)′表示,soj(α)′的数值越大表示其越趋近于j类情感。本文提出计算情感词语α在第j类情感的情感倾向权值,如式(3)所示。

需要注意区分的是,这里的情感倾向值同样是指趋向于该类情感的准确程度而不是指情感强度,倾向值越大表示越准确地趋向于该类情感。即soj(α)′,j=1,2,…,7,在这7类情感中,第j类取到最大值,则soj(α)′代表更准确地趋近于第j类情感。
3.4 情感词权重值的线性变换
在生成情感权重词库的过程中,研究发现得到的情感词语的情感权值较小。利用线性变换进行转换,计算方法如式(4)所示。
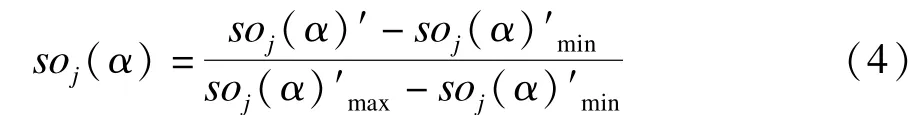
其中,soj(α)′是根据式(3)计算得到的情感权值;soj(α)是规划后的情感词情感权值;soj(α)′min表示式(3)计算出的所有情感权值中的最小值;soj(α)′max为最大值。
4 实验及结果分析
为了验证所构建的细粒度情感权重词库的分类效果,本文研究进行了以下实验。先使用TF-IWF算法,进行微博情感倾向性计算。然后再把细粒度情感权重词库得到的情感词权重值引入TF-IWF算法,再次进行微博情感倾向性加权计算。通过比较前后的准确率,以验证该方法的有效性。实验中对7类情感分别进行了权重词库的构建,这里仅列举了3类情感权重词库的构建方法,其余的以此类推。实验结论适用于7类细粒度情感的情感倾向性的分析判断。
选取由《知网》提供的情感分析词语集[8](内含正面情感词836个,负面情感词1 254个)作为训练集生成细粒度情感权重词库。用3类关键词“令人高兴”、“令人恐惧”和“令人伤心”进行Google中文微博相关主题的搜索(http://blogsearch.google.com.cn),按相关性排序[9-10],再从每类排名靠前的微博中选取主题情感倾向明显的100篇微博进行抓取作为测试集[11],以此来验证情感词库对于微博情感倾向判别的准确率。测试生成的情感权重词库部分内容如表1所示。
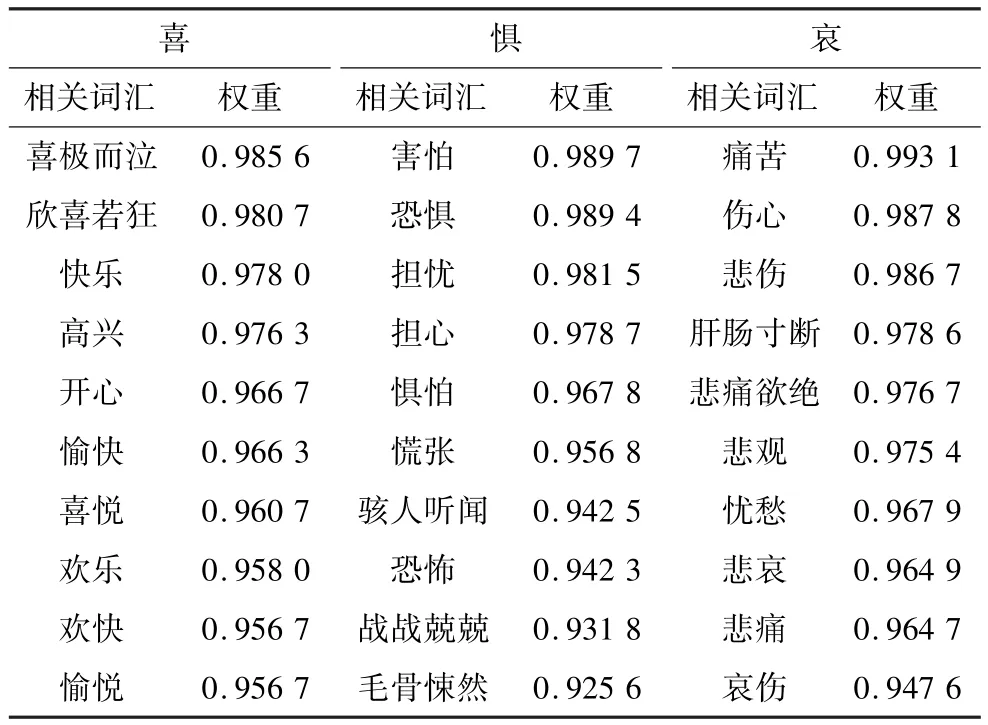
表1 细粒度情感权重词库部分内容
TF-IWF算法比TF-IDF算法的改进之处在于: TF-IWF算法中用特征频率倒数的对数值IWF代替IDF;TF-IWF算法中采用IWF的平方来平衡权重值对特征频度的倚重[12]。TF-IWF算法如式(5)所示。
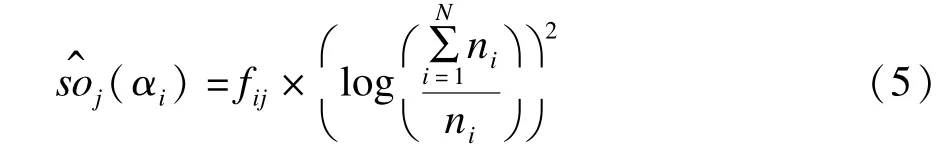
(αi)表示特征项αi在训练文本Dj中的权重,其中,fij表示特征项αi在训练文本Dj中出现的频度;ni为特征项αi在训练集中出现的次数;N为特征项的个数;i表示测试集与情感权重词库匹配的词语的数量;j表示每类微博的数量,取1~100。训练集{Dj}即微博测试集。这里所说的特征项即情感词,利用式(5)计算得出情感词的权重值,表示该情感词在整个训练集中的权重值。而这个词在情感权重词库中也对应了一个权重值,因此,为了得到更准确的结果,把两者进行结合,得到该情感词的最终情感权重值SOj(αi),利用式(6)计算。
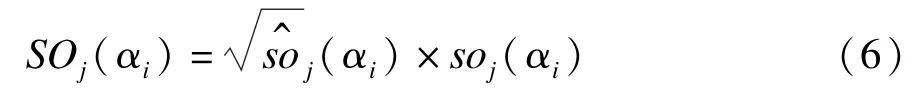
soj(αi)表示情感词αi在j类情感权重词库中的权重值。则该微博在j类情感微博中的情感权重值Wj,利用式(7)计算得出。
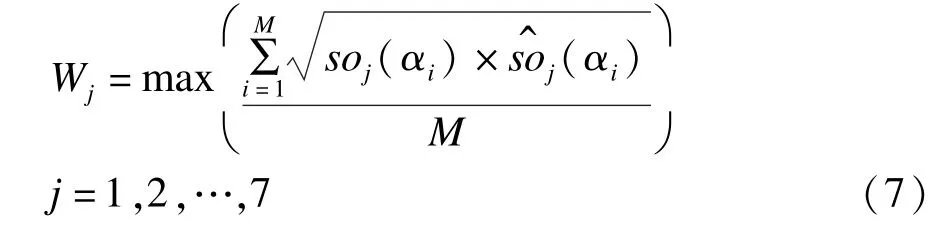
利用情感词库的词对测试集进行搜索匹配和权重计算,因此情感词库中匹配的情感词总数量即为特征项的总数量,定为M。若该微博在第j类情感微博中取得最大值,则该微博归类为第j类情感微博。
对上述3类情感的微博测试集进行实验,得到的准确率如表2所示。
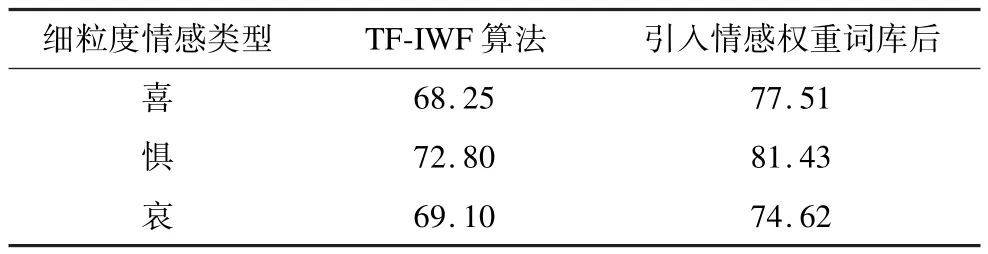
表2 3种细粒度情感微博的判断准确率 %
以上实验结果表明,单独用TF-IWF算法进行情感权重判断的准确率明显低于引入细粒度情感权重词库以后的准确率。TF-IWF算法的准确率受训练语料库大小的限制,训练语料库越大准确率越高。细粒度情感权重词库的引入使情感特征词不再受训练语料库大小的约束,两者的结合恰好削弱了这种影响,从而使得判断准确率得到大幅度提升。
5 结束语
本文提出的细粒度情感权重词库构建方法,以义原相似度分析为基础,通过情感基准词的义原相似度计算获得初步的细粒度情感词库。整个词库生成由计算机进行义原相似度的自动运算、比较并结合人工筛选来完成,具有较高的准确性和适应性,可以推广到其他的文本特征分类领域。构建的细粒度情感权重词库,可以利用其权重值来分析计算句子级、篇章级的文本细粒度情感倾向,为进一步研究细粒度情感倾向分析提供了依据。下一步将对本文方法进行改进和优化,并考虑词语之间义原的深度和区域密度分布因素,以进一步提高算法准确率。
[1] 刘 群,李素建.基于《知网》的词汇语义相似度的计算[C]//第三届汉语词汇语义学研讨会论文集.台北:出版者不详,2002:59-67.
[2] 蒋 溢,丁 优,熊安萍,等.一种基于知网的词汇语义相似度改进计算方法[J].重庆邮电大学学报:自然科学版,2009,21(4):533-537.
[3] 柳位平,朱艳辉,栗春亮,等.中文基础情感词词典构建方法研究[J].计算机应用,2009,29(10): 2875-2877.
[4] 张 彬,杨志晓.基于基准词的文本情感倾向性研究[J].电脑知识与技术,2011,7(8):1881-1885.
[5] 彭学士,孙春华.面向倾向性分析的基于词聚类的基准词选择方法[J].计算机应用研究,2011,28(1): 114-116.
[6] Ku L W,Lo Y S,Chen H H.Using Polarity Scores of Words for Sentence-level Opinion Extraction[C]// Proceedings of the 6th NTCIR Workshop Meeting.Tokyo,Japan:[s.n.],2007:316-322.
[7] 张清亮,徐 健.网络情感词自动识别方法研究[J].现代图书情报技术,2011,(10):25-28.
[8] 董振东,董 强.知网[EB/OL].(2011-06-23).http:// www.keenage.com.
[9] Kang J H,Lerman K,Plangprasopchok A.Analyzing Microblogs with Affinity Propagation[C]//Proceedings of the 1st KDD Workshop on Social Media Analytic.New York,USA:ACM Press,2010:67-70.
[10] Ramage D,Dumais S,Liebling D.Characterizing Microblogs with Topic Models[C]//Proceedings of International AAAI Conference on Weblogs and Social Media.Menlo Park,USA:AAAI Press,2010:130-137.
[11] Kaji N,Kitsuregawa M.Building Lexicon for Sentiment Analysis from Massive Collection of HTML Documents[C]//Proceedings of EMNLP-CoNLL 2007.Prague,Czech:[s.n.],2007:1075-1083.
[12] 宗成庆.统计自然语言处理[M].北京:清华大学出版社,2008.
编辑 金胡考
Construction Method of Fine-grained Emotion Thesaurus with Weight Factor
HUANG Gaofeng1a,ZHOU Xueguang1a,LI Juan1b,LIU Hua2
(1a.Information Security Department;1b.Computer Engineering Department, Naval University of Engineering,Wuhan 430033,China;2.75753 Troops,Guangzhou 510600,China)
Emotion thesaurus plays an important role in the text sentiment analysis,but it is particularly inadequate in the analysis of fine-grained emotions such as human emotions.To solve this problem,this paper presents a fine-grained emotion thesaurus construction method via the calculation of sememe similarity,and finishes the construction of seven sorts of thesaurus.Based on this work,this paper researches on the calculation method of the weight of fine-grained emotion words,and proposes a new weight calculation method of emotion words.Finally,this paper finishes the construction of seven sorts of thesaurus with weight value.Experimental results show that the introduction of the finegrained emotion thesaurus with weights can make the accuracy rate of the text emotional tendencies increased by about 5%.
sememe similarity;emotion;fine-grained emotion;weight calculation;weight factor;thesaurus construction
1000-3428(2014)11-0211-04
A
TP391.1
10.3969/j.issn.1000-3428.2014.11.041
国家自然科学基金资助项目(611100042)。
黄高峰(1979-),男,讲师、CCF会员,主研方向:网络舆情分析,自然语言处理;周学广,教授;李 娟,副教授、博士研究生;刘 华,工程师、硕士。
2013-12-05
2014-02-10E-mail:huanggaofeng@163.com
中文引用格式:黄高峰,周学广,李 娟,等.具有权重因子的细粒度情感词库构建方法[J].计算机工程,2014, 40(11):211-214.
英文引用格式:Huang Gaofeng,Zhou Xueguang,Li Juan,et al.Construction Method of Fine-grained Emotion Thesaurus with Weight Factor[J].Computer Engineering,2014,40(11):211-214.
