基于聚类评分的暴雨/冰雹分类模型
2014-06-05孙红跃
范 文,王 萍,孙红跃
(天津大学电气与自动化工程学院,天津 300072)
基于聚类评分的暴雨/冰雹分类模型
范 文,王 萍,孙红跃
(天津大学电气与自动化工程学院,天津 300072)
针对暴雨和冰雹2种强对流天气的区分问题,研究了主成分分析联合线性鉴别分析对雷达图像中提取的冰雹及暴雨特征降维和去相关的作用,设计了基于聚类评分的暴雨/冰雹分类模型,采用K均值聚类评分的办法确定具有高分类性的主成分,并以此主成分设计分类器对暴雨和冰雹进行区分.结果表明:主成分分析联合线性鉴别分析进行特征处理能够在降维的同时保留大部分分类性信息,基于聚类评分的分类模型有利于提高冰雹识别的命中率并降低其误警率,且对一般类型公共数据分类问题有效.
暴雨/冰雹分类;聚类评分;主成分分析;线性鉴别分析
随着气候变化的影响,强冰雹和短时强降水等强对流天气频发.强对流天气是造成气象灾害的主要天气类型之一,主要包括冰雹、龙卷、雷雨大风和暴洪,其突发性强、历时短、范围小、局地性强,是多尺度天气系统相互作用的结果,因而其演变方式难以掌握.其中冰雹虽然出现范围小,持续时间短,但其来势猛烈、强度大,给农牧业、工矿企业、电讯、交通运输及人民生命财产造成的损失较大,是一种严重的灾害性天气.冰雹云的发生发展具有突发性、移动迅速、生命史短等特点,为准确识别及预报造成困难.新一代天气雷达应用于对流天气的探测和预警,为冰雹的预报提供了良好的手段.任何对流风暴(雷暴)都是由对流单体构成,对流单体在雷达反射率图上表现为一个个分立的密实区域.即将形成暴雨的单体和即将形成冰雹的单体有其共同特点,即:自云团外至内,反射率强度由弱逐步加强,内部的反射率值高达50,dBz以上,并且区域达到一定规模;它们之间的不同点则反映在强弱间过渡带的分布特点、变化梯度乃至边界形态等细节上.目前我国采用新一代天气雷达CINRAD,其组成部分雷达产品生成(radar products generated,PRG)子系统接收雷达数据采集(radar data acquisition,RDA)子系统雷达基数据,对其处理生成各种产品,再通过主用户处理器(principal user processor,PUP)存储和显示产品.与传统天气雷达相比,CINRAD的强天气预警方面有很大改善,例如,局地强风暴的命中率(probability of detection,POD)达到0.83,误警率(false alarm rate,FAR)为0.49[1].在应用新一代雷达进行冰雹预警过程中,较高的命中率能够满足气象预报要求,但居高不下的误警率成为急需解决的新问题.通过对雷达反射率图的分析,由算法自动识别大冰雹云、小冰雹云、暴雨云,在保持冰雹较高命中率的同时降低误警率,对于冰雹灾害预报有着重要的意义.
气象预报工作人员从雷达反射率图的信息中发现,从某些特征观测,即将形成冰雹的不同单体特征之间趋向于彼此相似,即将形成暴雨的不同单体特征之间也趋向于彼此相似,但冰雹单体和暴雨单体特征则趋向于不相似.并不是所有特征都有助于暴雨/冰雹分类问题,另外某些特征可能具有很好的分类信息,但合并成特征向量时,由于相关性,会弱化甚至消除分类信息.选择具有充分分类信息的特征,对于简化分类器的设计、提高分类器性能非常重要.基于此,笔者将特征综合考虑,对特征向量进行线性变换,通过聚类来指导特征选择,在特征空间中找到对于暴雨和冰雹具有最大区分力的特征和特征组合,从而进行有效的暴雨/冰雹分类.
1 暴雨、冰雹云特征预处理
1.1 特征提取
前期工作中,利用链码技术、纹理特征、分布特征、动态特征提取算法等图像处理方法从雷达图像提取面积最大准核平均反射率强度等25项冰雹云图像特征[2-4].这些特征从不同角度阐述冰雹云的特点,特征之间存在这样的关系:①任何一项特征都不足以将冰雹云与暴雨云分开,需要各项特征互相配合,协同判断;②各项特征之间不是相互独立的,具有相关性,也存在信息重复性;③单体的各特征值量级差异大,有些特征取值范围宽,这为后续的特征值处理增加了难度.
1.2 特征处理
鉴于前述冰雹云单体所提取特征的数值特点,需要对特征进行处理.特征处理主要考虑以下几个方面:第一,数据归一化处理.所要处理的单体特征值具有不同的动态范围,大特征值比小特征值的影响更大,但并不能反映特征所具有的重要程度,所以需要通过特征归一化,使特征值位于相似的范围内.可以采用各特征的均值和方差的估计值做归一化.第二,消除各特征之间的相关性.单体特征是采用不同方法提取的,均从某一侧面反映冰雹单体的特性,各特征之间存在相关性和信息冗余,通过特征空间变换去相关并减少冗余.第三,减少特征数量.由于有些聚类算法不适用于高维数据,特征数量过多,在进行聚类时容易受到局限,所以在充分保留分类信息的情况下,尽可能减少特征数量.
2 基于特征变换的暴雨/冰雹聚类评分方法
2.1 聚类评分基础
主成分分析(principal component analysis,PCA)和线性鉴别分析(linear discriminant analysis,LDA)都是采用变换的方式从高维特征中提取低维特征[5],所不同的是PCA侧重于表达原始模式特征,而LDA侧重于样本的判别特征.PCA变换最大程度地保留样本信息,而LDA获得最有辨别力的特征,即使样本类间离散度和样本类内离散度的比值最大的特征[6].
PCA的原理可以做如下描述.设x1,…,xp是原始变量集,ξi,i=1,…,p是原始变量的线性组合

式中:ξ和x为随机变量向量;A为系数矩阵.根据方差var(ξ1)最大的原则,依次得到p个主成分.总方差中第i个主成分的方差所占比例称为主成分ξi的贡献率,前b个主成分累计贡献率反映了前b个主成分综合原始变量信息的能力,用θ 表示,则

由于p个主成分之间是相互独立的,故主成分分析可以解决特征相关性的问题,p个主成分的贡献率依次递减,即综合原始变量信息的能力依次递减.若b<p则可以用于数据降维,降维时通常选取能够表达原始信息的85%以上的前b个主成分[7].对于分类问题采用PCA降维时,选择的前b个主成分是综合原始变量信息能力最强的b个,并不一定是具有分类能力最强的;而分类能力强的主成分,可能是排序靠后的主成分.在分类问题中直接采用PCA降维,取前b个主成分组成特征空间,就有可能因丢失重要的分类信息而导致分类困难的现象出现.
LDA的目的是找到一些特征使得类间离散度和类内离散度的比值最大.样本的类内离散度矩阵和类间离散度矩阵可以定义为

式中:Pi为先验概率;ˆi∑为i类协方差矩阵;mi为i类的均值;m为所有样本的均值.定义准则函数为

若Sω是非奇异矩阵,投影后,各类样本之间尽可能分开,类内样本尽量密集,即求出准则函数取最大值时对应的特征向量[7].
本文提出用LDA提取主成分的方法:在数据PCA主成分得分空间进行LDA,通过交叉检验,选取最具分类特征的b个主成分,以这b个主成分得分构成聚类空间进行聚类,验证选中特征的分类性,最终目的是原始数据去相关、降维的同时,最大程度地保留了特征的分类性,便于分类器的设计和分类效果的提升.
2.2 聚类评分算法描述
本文聚类算法采用K均值聚类.K均值聚类是基于准则函数最优的聚类算法,其计算复杂度是O(ndkl)(n为样本数量,d为样本维数,k为类别数,l为迭代次数),虽然K均值聚类算法是以确定类别数和选定的初始聚类中心为前提,分类结果受到类别数和初始聚类中心的影响,但由于其方法简单,效果可以令人满意,所以在众多领域获得应用[8].
本文提出的基于特征变换的聚类评分算法,即在原始特征的主成分空间选出最具分类性的主成分,并用K均值聚类验证所选主成分的直观分类特性.算法描述如下:
步骤1 将所有特征样本进行PCA,得到主成分得分;
步骤2 对主成分得分进行LDA,取最具分类性的前若干个主成分,计算所选主成分的累计贡献率θ,直至选定的b个主成分的累计贡献率达到80%以上(所选的主成分既要保证具有强的分类性,又要保证对原始信息的保持能力);
步骤3 以b个主成分得分代替原始数据执行K均值聚类算法;
步骤4根据聚类结果对所选取主成分得分做分类评价.
3 实验及结果分析
3.1 实验设置
为验证本文方法的有效性,笔者采用气象数据和公共数据集进行实验,实验结果分别呈现在第3.2节和第3.3节部分.气象数据实验使用雷达图像的冰雹云图像特征数据和暴雨云图像特征数据,选取自2003—2007年共505例,其中暴雨271例,冰雹234例.数据为25维数据,各维数值分别表示面积最大准核平均反射率强度、等效准核面积、单体整个的平均梯度值、单体钩的曲率半径等雷达图像特征.公共数据采用UCI标准数据集的wine数据,因本文方法适用于2类问题,故取其前2类数据class1和class2共130个样本.为验证算法效果,使用线性分类器进行分类实验,以分类准确率评价算法性能.分类准确率定义为

式中:n为样本数;la为真实标签;c为分类结果;num(·)表示真实标签与分类结果相同的样本个数.气象实验中,利用命中率和误警率考察本方法冰雹识别能力.在考察本文算法降维同时保持分类特性时,采用PCA降维算法作为对比,该算法取保留原始数据信息80%以上的主成分得分作为聚类的样本.
3.2 气象数据实验
将原始数据做PCA,各主成分贡献率如图1所示.第1主成分贡献率为26.87%.前10个主成分的累计贡献率为87.98%,提供原始数据的绝大部分信息.通过LDA算法选取的最具有分类性的10个主成分依次为:p1,p3,p2,p24,p20,p4,p25,p14,p9,p5,如图2所示.这10个主成分的累积贡献率达到80.57%.其累计贡献率较前10个主成分的累计贡献率有所下降,说明选取这10个主成分会失去一些原始数据信息.对于第1主成分p1,原始信息保留率最大,同时也是最具有分类性的主成分,而原始信息保留率第2的主成分p2的分类性却不如原始信息保留率第3的主成分p3,原始信息保留率很小的p24、p25,其分类性在主成分中排名第4和第7.若通过PCA降维方法,将原始信息保留率较小的主成分舍弃,将会损失大量的分类信息.
为验证本文聚类评分方法中采用特征变换方法所选取主成分的分类性信息对样本分类效果的有效性,本文采用数据直接聚类、PCA后聚类、PCA+LDA后聚类3次实验进行聚类效果验证.聚类结果见表1.度地体现数据的分类能力,PCA+LDA降维的方法对于分类问题有很好的效果.

图1 气象数据各主成分贡献Fig.1 Each principal component contribution rate of meteorological data
根据聚类结果,分别取第1、第2以及第1、第3主成分作散点图,如图3所示.从图3中可知,图3(b)比3(a)点的聚集性好一些,重合率低,更容易分类.这是由于图3(a)采用反映原始数据信息最多的第1、第2主成分作图,图3(b)是采用最具有分类特性的第1、第3主成分作图.虽然图3(b)与3(a)相比,缺失了更多的原始数据信息,但分类特性被很好地保留下来,这样更容易实现高维数据聚类效果在平面上的可视化.

图2 气象数据按分类特性排列的主成分贡献率Fig.2 Principal component contribution rates arranged by the classification characteristics of meteorological data

表1 气象数据聚类效果Tab.1 Clustering effect of meteorological data

图3 气象数据散点图Fig.3 Scatter diagram of meteorological data
从表1中可以看出,将原始数据直接进行K均值聚类,效果非常不理想,不能聚类;将原始数据映射到贡献率最高主成分组p1,p2,p3,p4,p5,p6,p7,p8,p9,p10(记为P1)所张成的子空间,聚类效果较好,有一定误分率8.515%;将原始数据映射到分类特性最高主成分组p1,p3,p2,p24,p20,p4,p25,p14,p9,p5(记为P2)所张成的子空间,聚类效果非常好,误分率只有3.366%.实验表明,原始数据虽然含有全部信息,但由于特征之间的相关性,使得数据分类特性并不明显,导致无法正确聚类.经过PCA之后,笔者只取10个主成分的得分进行聚类,聚类效果明显变好,说明PCA对于去除特征相关性和降维是非常有效的.而笔者取LDA算法得出的最具分类特性的10个主成分,聚类效果最好,说明最能表达原始数据信息的主成分并不一定是最具分类特征的主成分,虽然P2主成分组丧失较多的原始数据信息,却能最大限
分别取P1得分数据和P2得分数据的1/3作为训练集,构造线性分类器进行分类实验,实验结果见表2.根据本文算法结果设计分类器,分类效果好于直接应用PCA降维数据设计分类器.另外,从冰雹识别的方面来看,采用本文算法设计的分类器进行冰雹和暴雨的判断既有很高的命中率,又将误警率降到极低,达到很好的冰雹识别效果,相对直接采用PCA降维数据设计分类器的实验结果,本文算法的分类准确率和命中率更高,误警率更低.
3.3 公共数据实验
采用公共数据Wine实验.PCA各主成分贡献率见表3.前8个主成分(记为PW1)累积贡献率为91.32%,由LDA选出的最具分类特性的主成分依次为pw1,pw4,pw3,pw7,pw10,pw6,pw8,pw2(记为PW2),其累积贡献率为86.93%.本文方法与PCA降维直接分类方法的比较结果见表4.本文方法的误分率略有降低,分类准确率略有提高.说明本文算法具有一定的适应性,对一般数据有可推广意义.
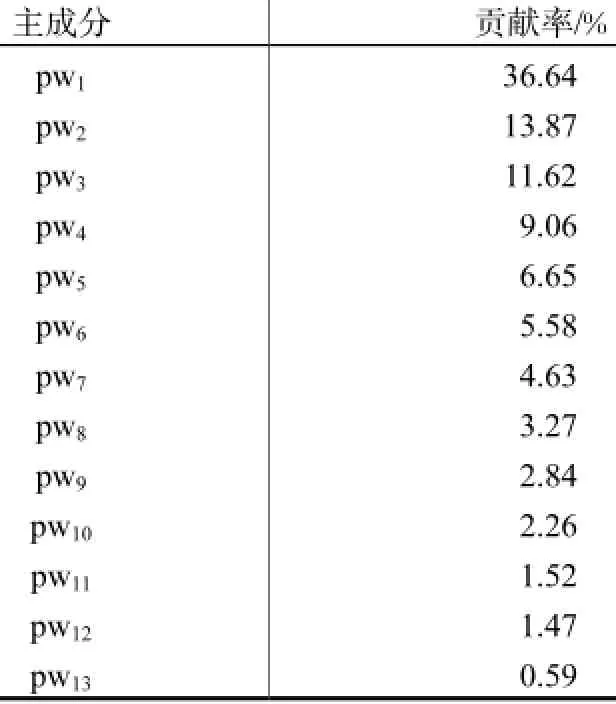
表3 Wine数据各主成分贡献率Tab.3 Each principal component contribution rate of Wine data

表4 Wine数据分类结果Tab.4 Classification results of Wine data
4 结 论
(1) 基于聚类评分的分类模型能有效地进行暴雨和冰雹分类,使用简单的线性分类器即可达到满意的冰雹识别,提高命中率的同时降低了误警率.
(2) 采用PCA进行特征变换可以达到降维、去相关的目的,联合使用LDA在舍弃较多原始特征信息的情况下,保留绝大部分类别信息,突出了分类性特征,从而简化分类器设计,提高分类准确率.
(3) 采用聚类验证特征分类性方法是有效的.根据聚类结果,借用二维平面上点的关系,近似表示高维数据结构,从而为分类提供可视化的指导.
(4) 基于聚类评分的分类模型是针对单独出现的暴雨和冰雹提出的,实际情况中,有时冰雹和暴雨同时出现,本文提出的分类模型并不适用.本分类模型采用了传统的聚类算法和线性降维方法,而改进的聚类算法以及非线性降维方法对于提高模型分类准确率和运行效率等方面的作用,是下一步工作要考虑和研究的问题.
[1] 俞小鼎,姚秀萍,熊廷南,等. 多普勒天气雷达原理与业务应用[M]. 北京:气象出版社,2009.
Yu Xiaoding,Yao Xiuping,Xiong Tingnan,et al. Description and Application of Doppler Radar[M]. Beijing:China Meteorological Press,2009(in Chinese).
[2] 王 萍,强兆庆,许晋玮,等. 基于链码描述的图像图形特征提取[J]. 计算机应用2009,29(8):2065-2067.
Wang Ping,Qiang Zhaoqing,Xu Jinwei,et al. Feature extraction of images and graphics based on chain code description[J]. Journal of Computer Applications,2009,29(8):2065-2067(in Chinese).
[3] 王 萍,董晓凯,贾惠珍. 基于雷达回波反射率图的雹云特征提取[J]. 天津大学学报,2007,40(10):1241-1246.
Wang Ping,Dong Xiaokai,Jia Huizhen. Hail cloud feature extraction based on radar reflectivity image[J]. Journal of Tianjin University,2007,40(10):1241-1246(in Chinese).
[4] Lu Zhiying,Wang Lei,Ma Hongmin,et al. Hailstone detection based on image mining[C]// Proceedings of the 5th International Conference on Fuzzy Systems and Knowledge Discovery. Piscataway,NJ,USA:IEEE Press,2008:39-43.
[5] Niket B S,Adgaonkar R P. Comparative analysis of PCA and LDA[C]// Proceedings of the 2011 International Conference on Business,Engineering and Industrial Applications(ICBEIA 2011). Piscataway,NJ,USA:IEEE Press,2011:203-206.
[6] Barshan E,Ghodsi A,Azimifar Z,et al. Supervised principal component analysis:Visualization,classification and regression on subspaces and submanifolds[J]. Pattern Recognition,2011,44(7):1357-1371.
[7] Kim H,Drake B L,Park H. Multiclass classifiers based on dimension reduction with generalized LDA[J]. Pattern Recognition,2007,40(11):2939-2945.
[8] Webb A R. Statistical Pattern Recognition[M]. 2nd ed. England:John Wiley & Sons Ltd,2002.
(责任编辑:孙立华)
Heavy Rain/Hail Classification Model Based on Cluster Scoring
Fan Wen,Wang Ping,Sun Hongyue
(School of Electrical Engineering and Automation,Tianjin University,Tianjin 300072,China)
For the discrimination of two severe convective weathers,heavy rain and hail,we investigated the effectiveness of combination of principal component analysis(PCA) and linear discriminant analysis method on the dimension reduction and feature decorrelation,and a classification model based on K-means cluster scoring was devised. This classification model is able to determine the principal component with high classification performance and distinguish heavy rain and hail based on this principal component design classifier. The experimental results show that most of the classification information is remained by principal component analysis and linear discriminant analysis in the dimension reduction. Moreover,classification model based on cluster scoring can improve the probability of detection(POD) and reduce the false alarm rate(FAR) of hail identification. This model has similar effectiveness for general data classification problem as well.
heavy rain/hail classification;cluster scoring;principal component analysis(PCA);linear discriminant analysis(LDA)
TP274
A
0493-2137(2014)07-0608-05
10.11784/tdxbz201303015
2013-03-08;
2013-06-04.
公益性行业(气象)科研资助项目(GYHY200706004);天津市自然科学基金资助项目(09JCYBJC07500).
范 文(1978— ),女,博士研究生,fanfanwen@126.com.
王 萍,wangps@tju.edu.cn.
时间:2013-06-24.
http://www.cnki.net/kcms/detail/12.1127.N.20130624.1055.001.html.
