K-均值算法支持的优质网络学习资源筛选方法研究*
2014-05-25叶海智程清杰黄宏涛
□ 叶海智 程清杰 黄宏涛
K-均值算法支持的优质网络学习资源筛选方法研究*
□ 叶海智 程清杰 黄宏涛
网络学习资源建设是教育信息化的重要组成部分。面对海量的网络学习资源,如何筛选出高质量的学习资源就变得尤为重要。本文以自主研发的精品资源共享课程公共服务平台为支撑,提出一种优质网络学习资源的筛选方法。该方法首先使用K-均值聚类算法对大量网络学习资源进行自动分类,然后通过支配关系对聚类后的资源进行评价,通过引入优胜劣汰机制筛选优质网络学习资源,以消除学习者在资源选择时的盲目性,有效提高网络学习的效率与效果。
网络学习资源;K-均值算法;最优候选集;支配关系;优质资源筛选
引言
随着教育信息化进程的不断推进,基于网络的学习资源量增长迅速,各种网络学习资源平台上的资源数量庞大,但质量却参差不齐。学习者如何在这些海量学习资源中快速选择出自己所需的优质资源,已经成为影响网络学习成效的关键问题。如果能在网络资源平台中引入优胜劣汰机制,以筛选优质网络学习资源,同时淘汰质量不佳的学习资源,就有可能使这一问题得到解决。
筛选优质网络学习资源的核心问题是如何对资源的质量进行评价。网络学习资源平台数据库中保存了大量关于学习者对资源的下载量、访问频次和点赞数量(好评比率)等日志数据,可以通过对这些原始数据的分析,对网络学习资源的质量做出客观评价,从而达到筛选优质网络学习资源的目的。鉴于对各种网络学习资源使用情况的数据数量极其庞大,只有借助计算机程序对相关日志文件进行处理,才能够对这些数据进行全面、准确的分析。对大量包含学习资源相关信息的日志文件进行处理是一项复杂的问题,而数据挖掘中的聚类分析为这一问题的解决提供了有效的途径。聚类分析作为数据挖掘的一种方法[1],能够根据特定指标对大量对象进行有意义的分类,通过对分类中心样本进行分析,达到对大量网络学习资源进行评价的目的。近年来,以聚类分析为代表的数据挖掘方法已经成功地应用于教育领域,把大量的原始数据转化为有用的信息和知识,从而对学生的表现进行评估[2]。本文以网络学习平台的学习资源为研究对象,利用聚类分析技术对资源的质量进行评价,以筛选优质网络学习资源。
一、聚类分析和K-均值算法
1.聚类分析
聚类分析作为数据挖掘中的一种重要分类方法,能将海量数据分成若干个簇或类,并且同类的数据对象之间具有相同或相似性质,而不同类别的数据对象则具有较大差别[3]。聚类过程主要包含三个步骤:①数据预处理:通过特征整合、分配属性等将输入的原始数据转化为有效格式;②数据分类:按照聚类分析算法,并辅以各种挖掘工具对数据进行分类;③数据解释:该阶段通过对分类获得的信息进行解释、分析,最终做出决策。聚类分析的工作流程如图1所示。聚类算法可分为分层算法和非分层算法两类,前者用于数据集中簇数目不确定的情况[4],而后者更适用于数据集数量较大且数据集中簇数目可预测的情况。
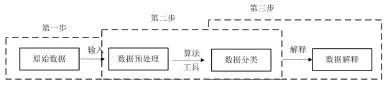
图1 聚类分析流程图
由于聚类分析算法采用的核心思想不同,目前的聚类算法主要有划分聚类算法、层次聚类算法、基于密度的算法、基于网格的算法等。其中划分聚类算法主要包括K-均值(K-means)算法、K-中心点(K-medoids)算法等;层次聚类算法主要包括自顶向下的层次聚类和自底向上的层次聚类。通过阅读文献,分析对比部分聚类算法的时间复杂度、处理大规模数据集等方面的性能[5],发现当结果簇比较密集,而簇与簇之间性质差别较大时,运用K-均值(K-means)算法进行聚类分析最为合理,因为该算法对于大规模数据集是相对可扩展的,并且收敛速度较快[6]。
2.K-均值算法
由于教学资源服务平台中资源的类别和数量庞大,本文使用划分聚类算法——K-均值算法进行分类。该算法利用初始聚类信息计算出质心的一组试验集群,然后将每个对象划分到最近的质心,划分结束后重新计算质心并分配对象,这个过程循环进行,直到群集成员不再变化[7]。K-均值算法对网络学习资源进行聚类的流程如下:
(1)从网络资源库中随机选择K个资源作为初始聚类中心;
(2)计算每个资源到所选的K个聚类中心的距离,并将其划分至距离最短的簇中;
(3)重新计算新簇的聚类中心;
(4)循环执行(2)和(3),直到聚类中心不再变化。
表1利用欧式距离算法计算数据样本Xi=(xi1, xi2,xi3,xi4,xi5)与 Xm=(xm1,xm2,xm3,xm4,xm5)之间的距离S(3-4行)。S越小,样本越相似,差异度越小,即可分属于同一簇Ck(5-6行);然后利用误差平方和准则函数E评价聚类性能(10-11行);接着计算新的簇中心-Xj(8-9行)后,再次计算距离。重复进行这个过程,直到E不再变化。

表1 K-均值算法
二、优质网络学习资源的筛选方法
K-均值算法能够按照给定指标快速地实现对大量网络学习资源的聚类,聚类的结果是对与各自聚类中心性质接近的若干资源进行分类,接下来以聚类中心为代表对各类网络学习资源的优劣进行评价。然而,资源优劣的评价不是简单的单一指标比较,而是一个多指标、多角度的寻优问题,它与学习时间、访问频次、好评比率(点赞数量)等多个指标相关,不能仅凭某一个指标来衡量资源的优劣,例如,对于一些较为吸引人但内容质量不高的学习资源,其访问频次可能较高,但其在线时间和好评比率可能较低,这样的资源就不能称为优质资源。因此,对资源优劣进行评价是一个多指标的综合评价问题。鉴于此,本文以K-均值算法为基础,借助多目标优化问题中的支配关系,给出一种优质网络学习资源筛选方法。
目标优化问题中的支配关系为优质网络学习资源的筛选奠定了坚实的理论依据。为了引入支配关系,首先假定仅从访问频次和学习时间两个指标对网络学习资源进行评价。对于网络学习资源库中任意资源1和资源2,如果资源1在访问频次和学习时间两个指标上都优于资源2,则称资源1支配资源2或资源2被资源1支配[8]。同理,如果存在某个资源使得资源库中的任意其他资源都不能支配该资源,则称该资源为非劣资源,所有这类非劣资源的集合称之为最优候选集。相反,如果资源库中存在某个资源不能够支配资源库中的任意其他资源,则称该资源为非优资源,这些所有非优资源的集合被称为最劣候选集。
由于聚类的结果是少量的分类,因此对资源的评价可以以分类为单位进行。优质网络学习资源的筛选方法可描述为:第一步,运用K-均值算法对网络学习资源进行分类;第二步,以各分类的聚类中心为代表,对聚类结果进行支配关系运算,采用优胜劣汰机制筛选出优质网络学习资源。对于中心点处于最优候选集中的聚类,意味着该类资源都是非劣资源,即质量较高的优质资源;而中心点位于最劣候选集中的聚类,则为质量较差的劣质资源。
三、筛选方法的实验研究
1.实验方案
本研究的实验目的是对基于K-均值算法的优质网络学习资源筛选方法的可行性进行验证。本文借鉴相关研究工作[9][10][11],选取河南省高校教育信息工程技术研究中心研发的精品资源共享课公共服务平台(以下简称“平台”)为测试环境。“平台”包含了多种学习资源,如在线视频、演示课件、教学案例、拓展文献等。所有这些资源都是在课程建立时由任课教师统一组织上传的,它们在系统中的生存时间相同。同时“平台”可自动记录学习者访问资源的名称、访问频次及学习时间等信息。
首先,教师安排网络学习活动及课外作业并进行管理。学生根据教师的课外要求,登录平台进行预习、课外拓展等学习活动。利用本文所给出优质资源筛选方法,把平台数据库中的网络学习资源按照一定的性质划分为多个簇,使得簇中每个元素都有一定的相似性,且簇与簇之间的特征具有明显的差异性,从而进一步以簇为单位对学习资源进行分析评价[12],最终达成催生优质网络学习资源的目标。实验方案如图2所示。
2.实验对象
本研究以河南师范大学教育技术学专业必修课——《教学系统设计》课程中的全部资源和相关数据为例,以教育技术学专业2011级和2012级本科生(其中2011级111人,2012级118人)为实验对象,在教学中采用混合式教学模式,除了传统课堂教学外,学生根据教师的安排,通过“精品资源共享课公共服务平台”进行《教学系统设计》课程的预习、复习、答疑等活动。两个年级的学生均通过服务平台进行了网络学习,在学习过程中服务平台监视并记录了学生的学习行为、参与程度等相关数据,如学生使用资源的名称、学习时间及访问频次等数据均记录在PostgreSQL9.2数据库中。由于这些平台数据库中资源在系统中的生存时间相同,也确保了对资源进行评价时的公平性和可信性。
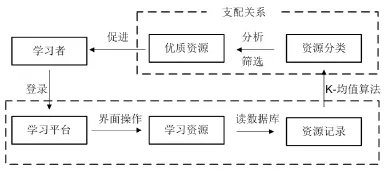
图2 基于K-均值(K-means)算法的优质资源筛选方法实验方案
3.实验数据分析
(1)数据提取
数据分析采用IBMSPSSStatistics19.0中的K-均值算法模块。提取数据为《教学系统设计》课程资源(包括视频资源类,演示课件类,拓展资源类等)相关的服务平台中数据库记录(包括资源名称、访问频次、学习时间、下载次数、按赞数量等)。表2是平台运行过程中自动记录的学生使用资源的日志。
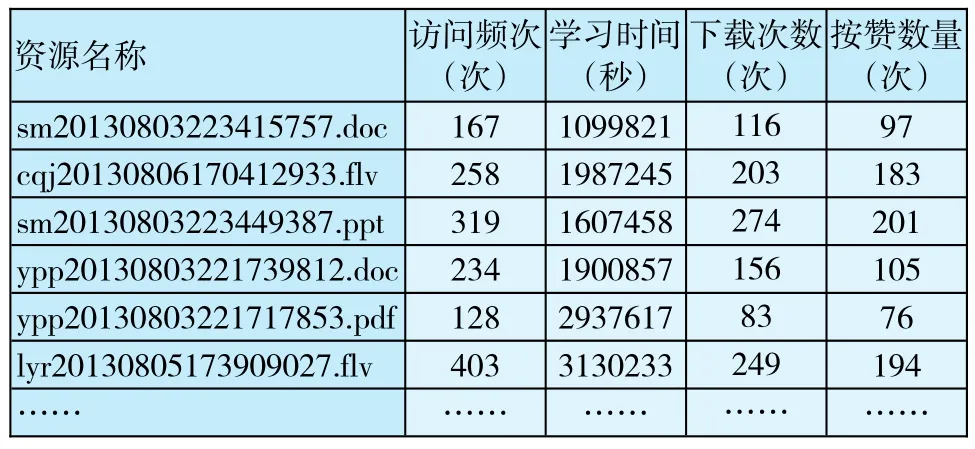
表2 学生访问资源日志记录信息
(2)聚类结果
以“访问频次”、“学习时间”、“下载次数”、“按赞数量”为聚类分析的目标变量,由于需要使用SPSS软件对数据进行K-均值聚类,本文对原始目标变量进行标准化转换,并将聚类数目设置为12。表3给出的是SPSS的K-均值聚类模块输出的结果。
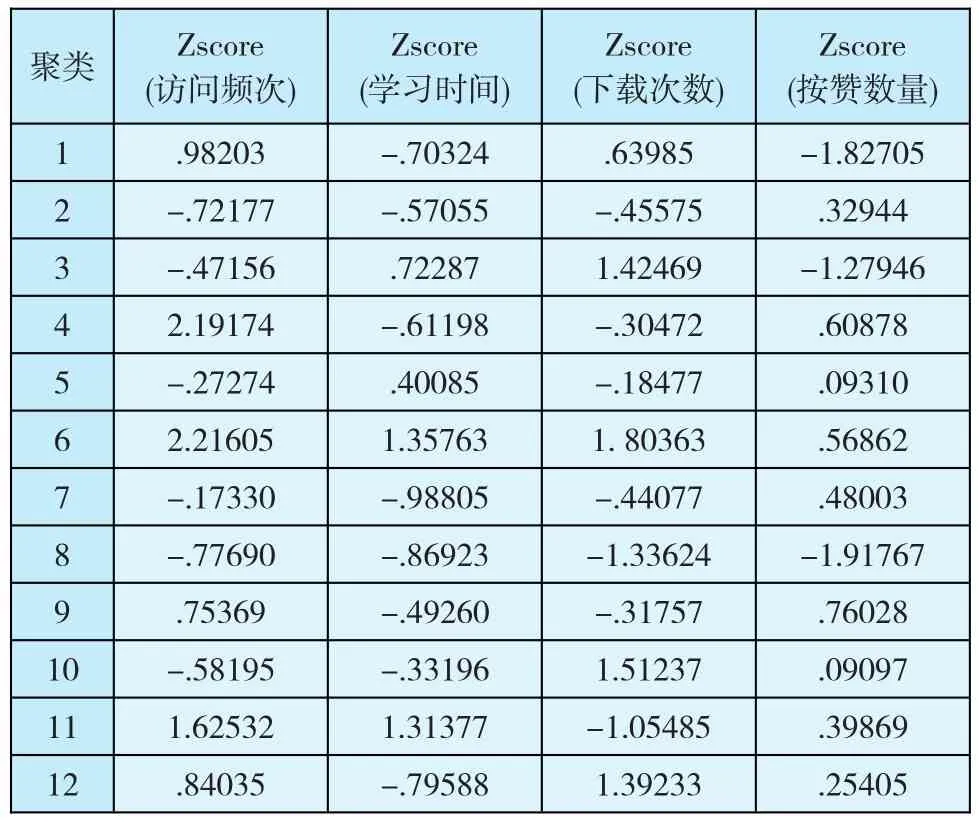
表3 K-均值聚类中心表
表中第一个聚类中心Zscore(访问频次)为.98203(标准化后的值),它迭代7次就已经收敛,对应于库中的sm20130911210952822.flv学习资源。随着K-均值迭代次数的增加,其他11个类别中心点也分别找到所对应的资源。表4是运用ANOVA方差分析工具,对K-均值聚类给出的分析结果。
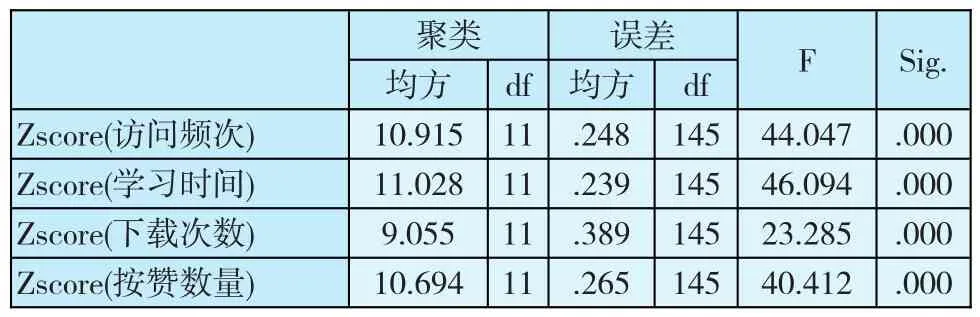
表4 ANOVA方差聚类分析表
从表4中可以看出,分类后各变量在不同类别之间的差异显著性概率为P=.000<0.05,分类之间存在显著差异,验证了基于K-均值聚类方法对网络学习资源进行分类的可行性和合理性。
(3)优质资源筛选
上述结果表明,K-均值算法能够按照资源特性对大量网络学习资源进行高效的自动分类。由于每个聚类中心都是其所在簇特征的典型代表,因而可以以聚类中心为代表对网络学习资源以分类为单位进行评价,从而筛选出优质资源。由于资源的判别指标包括访问频次、学习时间、下载数量等四项,就不能只追求单个属性的最优。图3是以按赞数量(f1)和访问频次(f2)两项指标为例,以本文中的支配关系原理对聚类中心的优劣得出的结果。其中,A~L分别代表第一至第十二个聚类中心的资源,横坐标f1表示按赞数量,纵坐标f2表示访问频次。

图3 二维指标资源最优候选集分析
从图3可以得出,按照本文所给出的筛选方法,就各个聚类中心而言,显然中心D所代表的那类资源要优于A、B、C、E、G、H、J、K、L类资源,中心F所代表的那类资源要优于A、B、C、E、H、J、K、L类资源,I要优于B、C、E、G、H、J类。由于D、F、I之间无法确定优劣,且没有优于它们的其他中心资源,如果从学习时间和按赞数量两方面综合考虑,把它们所代表的资源可以评价为非劣资源(即优质资源)是合乎情理的;同样,由于H所代表的中心资源不能支配任何其他资源,显然属于非优资源。此外,对12个聚类中心资源从四维指标对它们的资源最优候选集也进行了分析,结果显示:D、F、I聚类中心所代表的资源在访问频次、学习时间、下载次数以及按赞数量四个方面都不能被其他资源所支配,构成最优质资源候选集,H聚类中心所代表的资源构成最劣资源的候选集。
4.应用结果分析
实验结束之后,采用问卷对实验对象进行调查,内容主要涉及学习效率、学习效果和资源认可度三个结构指标。本次调查实际发放问卷229份,回收229份,其中228份问卷有效。通过对228份问卷数据分析得知,88.91%的学习者认为该方法筛选出的学习资源重点突出,教学目标明确,属于优质资源;82.46%的学习者认为该方法消除了资源选择的盲目性,学习效率有所提升;76.32%的学习者认为网络学习资源的筛选有利于提升学习效果,方便随时进行知识巩固。
总之,基于K-均值的聚类算法对网络学习资源进行快速分类,在此基础上依据支配关系对聚类结果进行评价,从而筛选优质网络学习资源的方法是可行的和有效的。利用该方法不仅可以把质量最优的资源优先推送给学习者,消除学习者在选择学习资源时的盲目性,而且可以把质量最差的资源从系统中剔除,减轻资源服务器的负担,实现网络学习资源的优胜劣汰。但由于实验样本数据有限,该方法还需要更为广泛的实验验证,以保证其有效性和科学性。
四、结语与展望
面对不断增加的网络学习资源,如何从中快速准确地选择所需的高质量资源,对网络学习的效率和质量至关重要。本文给出了一种基于K-均值算法的优质网络资源筛选方法,使用基于K-均值的聚类算法对网络学习资源进行分类,然后根据支配关系对聚类结果进行评价,筛选优质网络学习资源。实验结果表明,该方法能够高效、准确地对网络学习资源的质量进行评价,对促进网络资源共享服务平台中资源质量的提高,推动资源提供者制作更加优质的网络教学资源,具有一定的现实意义和应用价值。但是,由于K-均值算法初始聚类中心K值的选择无准则可依,K值的选择不当可能会造成聚类结果不平衡。因此,下一步研究的重点将转移到如何优化K-均值算法,以降低K值对聚类结果的影响,并将新的算法应用于资源筛选方案之中,促进优质资源推送的自动化。
[1][9]Valsamidis,S.,Kontogiannis,S.,Kazanidis,I.,etal.AClustering MethodologyofWebLogDataforLearningManagementSystems[J]. EducationalTechnology&Society,2012,15(2):154-167.
[2][10]Abdous,M.,He,W.,&Yen,C.-J..UsingDataMiningforPredict⁃ingRelationshipsbetweenOnlineQuestionThemeandFinalGrade [J].EducationalTechnology&Society,2012,15(3):77-88.
[3]王鑫,王洪国,张建喜等.聚类分析方法及工具应用研究[J].计算机科学,2006,33(2):197-200.
[4][11]Antonenko,P.D.,Toy,S.,&Niederhauser,D.S..Usingcluster analysisfordataminingineducationaltechnologyresearch[J].Edu⁃cationTechnologyResearch,2012(60):383-398.
[5]贺玲,吴玲达,蔡益朝.数据挖掘中的聚类算法综述[J].计算机应用研究,2007,(1):10-13.
[6]杨小兵.聚类分析中若干关键技术的研究[D].杭州:浙江大学,2005:24-25.
[7]朱建宇.K均值算法研究及其应用[D].大连:大连理工大学,2013:16-17.
[8]刘华蓥,王静,许少华等.基于空间划分树的多目标粒子群优化算法[J].吉林大学学报(理学版),2011,49(4):698-704.
[12]陈益均,殷莉.基于数据挖掘的学生成绩影响模型的研究[J].现代教育技术,2013,23(1):93-96.
G40-057
A
1009—458x(2014)10—0062—05
2014-04-30
叶海智,博士,教授,河南省高校教育信息工程技术研究中心主任;程清杰,在读硕士;黄宏涛,博士,副教授。河南师范大学(453007)。
责任编辑 日 新
河南省政府决策招标项目:加快我省信息化研究(编号:2013B184);河南省教育厅科学技术研究重点项目:基于量子竞争决策的优质教育资源催生方法研究(编号14A880018)。
