基于加权有限状态机的动态匹配词图生成算法
2014-05-22郭宇弘肖业鸣潘接林颜永红
郭宇弘 黎 塔 肖业鸣 潘接林 颜永红
基于加权有限状态机的动态匹配词图生成算法
郭宇弘*黎 塔 肖业鸣 潘接林 颜永红
(中国科学院语言声学与内容理解重点实验室 北京 100190)
由于现有的加权有限状态机(WFST)解码网络没有精确词尾标记,导致当前已有的词图生成算法不含精确的词尾时间点,或者仅是状态、音素级别的词图,无法应用到关键词检索中。该文提出在WFST静态解码器下的语音识别词图生成算法。首先从理论上分析了WFST解码音素图和词图的可转换关系,然后提出了字典的动态音素匹配方法解决了WFST网络中词尾时间点对齐的问题,最后通过令牌传递的遍历方法生成了词图。同时,考虑到计算量优化,在令牌传递过程中引入了剪枝算法,使音素图转词图的耗时不到解码耗时的3%。得到的词图,不仅可以用于语言模型重打分,由于含有精确的词尾时间点,还可以直接应用到关键词检索系统中。实验结果表明,该文的词图生成算法具有较高的计算效率;和已有动态解码器的词图相比,词图中包含更多解码信息,在大词汇连续语音识别的重打分结果和关键词检索中都能取得更好的性能。
自动语音识别;加权有限状态机;词图生成;关键词检索
1 引言
作为大词表连续语音识别的核心模块,语音识别解码器负责利用上下文相关的声学模型、字典和语言模型等知识源把语音信号转换为文本。评价语音识别解码器性能的一项关键指标就是识别器的准确率。在非常理想的情况下,语音识别应具有非常高的识别准确率,此时仅仅选用语音识别的解码首选结果就可以使语音搜索、关键词检错等应用的准确率非常高。然而,考虑到现实应用经常出现的信道不匹配、说话人不匹配或者说话人发音不标准的问题,导致大词表连续语音识别(Large Vocabulary Continuous Speech Recognition, LVCSR)的首选结果在电话环境一类语音的识别错误率通常在40%左右。在这种较低准确率的情况下仅仅使用解码的首选结果往往是不够的。识别结果可以以多候选(N-Best)或者词图等形式输出,这种多候选或者词图结果保留了识别中的更多识别信息,把它们交由后处理模块能有效提高识别结果的准确性。常见的后处理技术包括:基于词图的重打分[1]、多遍解码[2]、混淆网络[3]等。
和多候选结果相比,词图形式包含了更多的信息,它不仅有多个识别词序列结果,更包含了每个词、音素的声学得分、语言得分以及时间点等信息,并且它合并了多候选的冗余信息,其表示也更加高效[4]。因此,词图在语音识别后处理中得到非常广泛的应用。例如:可以从词图里面直接抽取多候选结果;另外词图本身已经具有了图的性质,在某些场合第1遍解码用比较精细的模型会带来计算量过高的问题,此时可以用简单的模型在第1遍解码时生成词图,再用精细的模型在词图上进行2遍解码或者重打分则可获得更好的效果;而在关键词检索的应用中,词图或者词图的混淆网络形式可以作为检索器的输入。因此,词图成为了语音识别中第1遍解码和后处理模块之间的桥梁。
词图的生成过程是由解码器搜索解码网络,记录下搜索路径从而转化成相应的词图。解码网络是由各个知识源构成的一个搜索空间,一般来讲可以分为动态构建的解码网络和静态网络。基于动态网络的解码器,以前缀树的发音词典作为搜索网络,语言模型则通过动态查询的方式把得分引入解码过程之中,然后利用重入字典树或者字典树拷贝的方式对整个解码网络进行搜索[5]。动态网络解码器的优势在于,由于字典和语言模型是分离的,其占用内存较少,同时,由于搜索空间为一个前缀树的字典,字典里面有准确的词尾节点,这样,在进行词图生成的时候,可以准确地获取到词尾时间点。然而,动态网络解码器的最大缺点在于它的时间复杂度较高[6],相对于静态网络解码器,它的速度较慢。对于当今的大规模的语音识别应用,往往需要更快的响应速度,因而解码速度更快的静态网络解码器更加适合。静态网络的解码器基于加权有限状态机(Weighted Finite State Transducer, WFST)[7]。WFST 解码器的特点是实现简单,解码速度快,对于知识源有统一的建模方式,并且它具有完善的理论框架以及成熟的优化算法。应用在语音识别的WFST 网络输入一般为上下文相关的三音素或者隐马尔科夫模型(HMM) 状态,输出为识别词。为了让解码器网络得到充分优化加快解码速度和降低解码的内存占用,解码网络中不含词边界信息,这就为WFST 解码器生成含有精确时间点的词图造成了一定困难。文献[8]中提出了最早的WFST 解码器的词图生成算法,准确说文献[8]是介绍了一种记录WFST 格式的解码路径的算法,它并不包含词的边界和时间信息,它产生的词图主要用于语言模型重打分。文献[6]提出了在构建解码网络的时候插入额外的词尾标记用于找回词尾时间信息,但额外的词尾标记会导致解码网络得不到充分优化,从而网络变大,并且,解码网络格式的变化也导致解码网络的使用缺乏兼容性,需要为生成词图的解码器重新构建网络。Povey 等人[9]提出了一种WFST 的词图生成算法并应用在开源项目Kaldi[10]中。但是这种算法产生的是一种HMM 状态级别的词图,仍然不是标准的词图。文献[9]在文中提到不同解码器产生的词图在格式上不统一的问题,要做统一的比较和解释比较困难。
本文在给出了语音识别标准词图和WFST 的解码音素图的定义之后,探索了两者之间的联系,提出在WFST解码器下的词图生成算法。本文首先提出了一种动态字典匹配的方法,此方法可以用来进行词的时间点对齐,解决了WFST解码网络没有精确词尾节点的问题。然后提出了一种基于令牌传递(token passing)的方法,把WFST 的解码音素图转换为标准词图。由于本文提出的WFST 词图生成算法生成的是标准的词图,可以应用到已有的重打分、关键词检索等一系列后处理应用中而无需额外操作,且由于没有对网络进行特殊处理,本算法在网络使用上具有兼容性,无需重新构建解码网络。
本文的组织结构如下:第2节介绍背景知识,给出了WFST 的定义和解码框架以及标准词图的定义;第3节揭示了WFST 音素图和词图的联系和映射关系;第4节和第5节分别给出了词图的生成算法和相应的实验结果及分析;最后,第6节给出结论。
2 背景知识
2.1 基于WFST 的解码框架
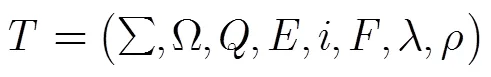
在语音识别中常用的权值半环有Log半环和Tropical半环[7],为了达到更精确的识别率,本文采用Log半环。最终的静态解码网络的构建可以表示成为


2.2 标准词图
标准词图是一个含有解码信息的有向无环图,可以定义为一个五元组:
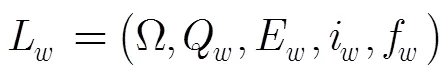
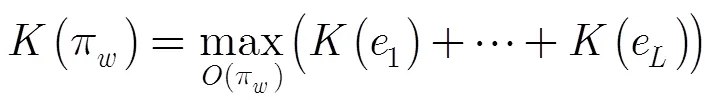
3 WFST音素图和标准词图的转换关系
3.1 WFST解码音素图
3.2 WFST的音素图和标准词图的联系
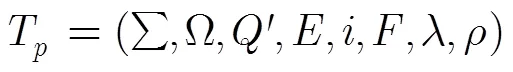
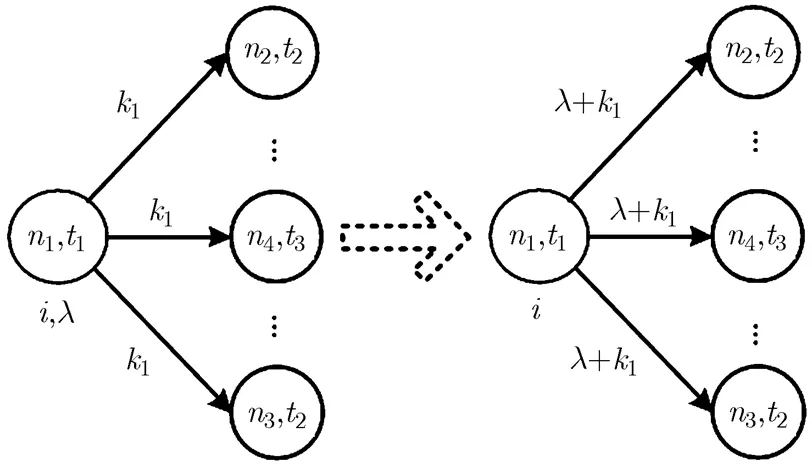
图1 音素图起始状态的权重处理
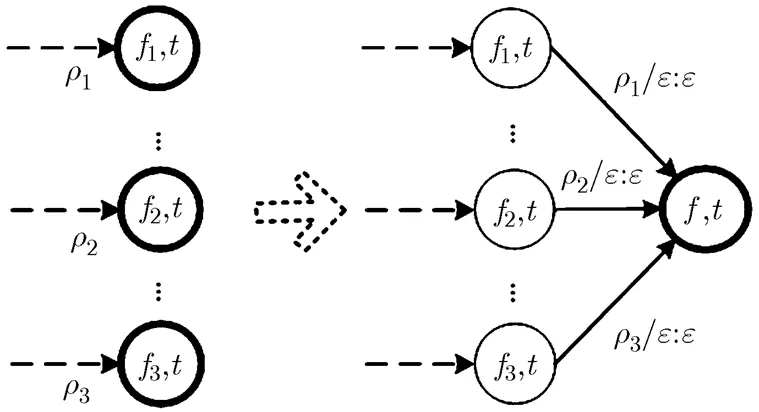
图2 音素图终止状态集的归一处理
4 WFST的词图生成算法
4.1 动态词匹配
词图生成的理论基础由文献[4]提出,其中的一个假设是词对无关假设,即:任何一对词的词时间点和这对词的历史无关,只与这对词本身有关。这个假设是针对于动态网络解码器提出的。对于本文上下文相关音素级别的WFST 解码器,由于WFST 做了网络优化,词的历史可能不会唯一,但WFST输入为上下文相关的三音素模型,词对无关假设可以变为音素对无关假设,即:任何一对音素的时间点和其历史无关。因此,由WFST 解码器记录下来的音素图中音素的时间点是准确的。但WFST 的解码网络缺乏明确的词尾标记,解码时候产生的音素图的词输出可能在其发音音素的任何位置,需要一个词时间点对齐的方式来重新找回准确的时间点。
本文不采取直接的字典发音匹配进行词时间点对齐(即只要当前的音素序列和词的一个发音匹配即可进行对齐)。直接的字典发音匹配缺少通用性,其问题在于,当字典中的词存在多发音且一个发音是另外一个发音的前缀的时候,前缀发音总会被优先匹配,而导致长的发音无法得到匹配。例如,英语中的缩写单词“Corp.”,其发音可以是缩写的发音“k ao r p”也可以是完整发音“k ao r p er ey sh ah n ”,缩写的发音是完整发音的前缀。
本文提出动态的词匹配方式进行词时间点对齐。此方法不仅仅是记录一个词就进行词边界的对齐,而是记录多个词和多个音素,动态进行发音匹配。其方法如下:(1)当记录的词序列长度达到3个词时开始尝试匹配,要求第1个和第2个词的发音完全匹配,第3个词中已记录的发音要匹配(由于此时第3个词的发音可能还未记录完全,无需完全匹配);(2)这种匹配的方式有且只有一种方法。满足这两个条件时可以确定第1个词的边界位置。示例如图3所示,词1包含两个多发音,前缀发音含有4个音素,长发音有6个音素,词2和词3分别含有3个及2个音素的发音。在尝试匹配时,如果某种匹配方式出现无法匹配的音素,则违背条件(1),需要更换匹配方式,如图3的错误1;如果匹配前两个词的方式不只一种,则违背了条件(2),这有可能是因为第1个词的发音去掉前缀发音后的部分刚好为第2个词的前缀,如图3中的错误2,此时需要加入后面更远的词输入进行匹配(如:加入第4个或以上的词);只有条件(1)和条件(2)同时满足的匹配方法才能确定第1个词的边界如图3的正确匹配。
4.2 音素图转词图
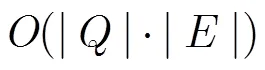
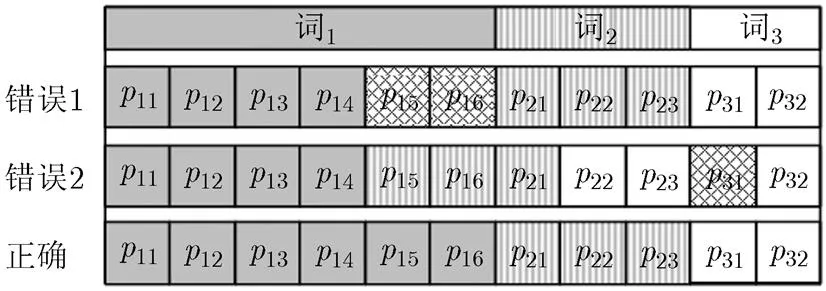
图3 动态词匹配正确和错误的匹配示例
表1音素图转词图的算法描述

算法1. 音素图转词图 (1) 对音素图的状态集进行拓扑排序 (2) 初始化令牌,把令牌挂在的初始状态上 (3) for all in do (4) for all in, s Token List do (5) if动态词匹确认了词边界then (6) 在词图中连接旧状态和目标状态 (7) if 词图目标状态已存在then (8) 删除当前 (9) end if (10) end if (11) 传播并加入经过边的信息 (12) end for (13)end for
5 实验结果和分析
5.1 实验参数设置
本文实验所采用的WFST 解码器为文献[14]描述的解码器,参与对比的解码器为动态网络解码器TDecoder[15]。测试任务包含了大词汇连续语音识别和关键词检索两种,每种任务各有两个测试集。具体的测试集和模型参数如表2所示,其中电话语音和实网语音由于信道和环境的原因,语音效果较差。
5.2 词图的产生效率
本实验采用电话语音测试集和对应的模型,因为电话语音的信道较差,语音的混淆性较大,解码时产生的路径也较多,能充分体现词图的产生算法的时间效率。对于转词图过程中令牌传递剪枝和未剪枝的情况,本实验记录了这两种情况下核心函数调用的平均次数。如表3所示,加入剪枝后,核心函数的调用次数从上百万次降低到1000次左右,剪枝对于减少计算量有非常明显的效果。加入剪枝后,转词图部分所占实时率仅为0.0011,占整个解码实时率的2.5%,相对解码耗时的比例非常小。因此,本文提出的词图算法具有非常高的效率。仍然保持了WFST 解码器在应用上快速的优势。
表2测试集和模型参数

测试集名时长(h)词典条数声学模型语言模型(Million) 高斯数目HMM状态数二元文法数三元文法数 LVCSR语音输入法1.092k16865511M19M 电话语音1.043k12588429M33M 关键词检索实网语音3.443k16203099M35M 采访对话2.5
表3 转词图的时间效率

未剪枝调用次数加剪枝调用次数转词图实时率转词图时间比例 114277810720.00112.5%
5.3 大词汇连续语音识别
本实验在语音输入法测试集和电话语音测试集上进行。参与对比的参数为解码器的首选字错误率、词图错误率和用一个大的语言模型进行词图重打分后的首选字错误率。词图错误率是指用词图中和答案最匹配的路径计算识别的错误率,它体现了词图用于重打分可以取得的错误率的下限。对于语音输入法测试集,参与重打分的语言模型为一个三元文法语言模型(3-gram)含有2-gram 30 M和3-gram 58 M;对于电话语音进行重打分的模型为五元文法模型,含有2~5元文法共447 M。实验结果分别见图4和图5。
从两个测试集的纵向比较来看,由于电话语音的效果较差,错误率要比语音输入法高很多。但是由于电话语音所采用的重打分语言模型更精准,因此,电话语音在重打分上错误率的下降要比语音输入法更加明显。从两个解码器的横向比较来看,在语音输入法测试集上,本文解码器在首选的极限结果上略差于TDecoder,但是无论从重打分还是词图错误率都比TDecoder的错误率下降更为明显;在电话语音测试集上本文解码器首选结果的极限结果好于TDecoder,在重打分和词图错误率的下降仍然好于TDecoder。也就是说,本文的词图生成算法相对于TDecoder保留了更多了词路径,包含更多的解码信息。
5.4 关键词检索
本文采用的关键词检索系统由文献[16]所述。图6给出了在两个关键词测试上,本文方法和TDecoder的关键词的检测误差图(Detection Error Tradeoff, DET)。关键词有两个重要的指标:等错点和最大召回率。等错点是DET图中漏警率和虚警率相同的点。召回率的定义为

图4 在语音输入法测试集上的词图效果
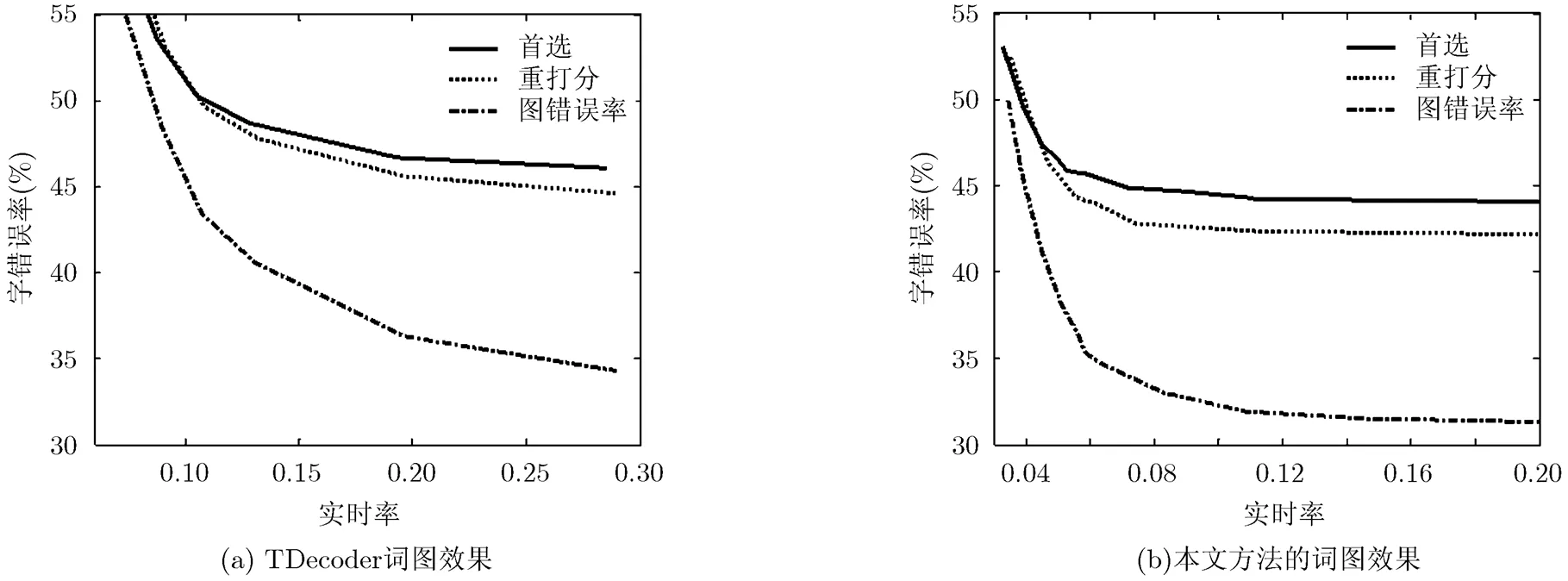
图5 在电话语音测试集上的词图效果

最大召回就是关键词检索系统所能够实现的最大的召回率。DET图和等错点以及最大召回率均由图6所示。为了方便比较,把本文的解码器和TDecoder系统的等错点调到相当的水平,可以看到,在等错点相当的时候,基于本文的词图生成算法的关键词系统具有较高的最大召回率,从而有效减少关键词检索时信息的丢失,同时仍然说明了本算法生成的词图具有更多的信息。
6 结束语
本文针对以往的WFST词图算法不含精确词尾时间点的问题,提出了一种在WFST框架下的能产生含有精确词尾时间点的词图的生成算法。本文从理论上分析了WFST解码音素图和标准词图的转换关系,并从实际上提出动态词匹配和基于拓扑排序及令牌传递的词图生成算法。从实验结果上看,本文的词图生成算法具有较快的速度,同时,本算法生成的词图比已有动态网络解码器的词图包含更多的解码信息,在关键词,LVCSR重打分上具有更好的表现。
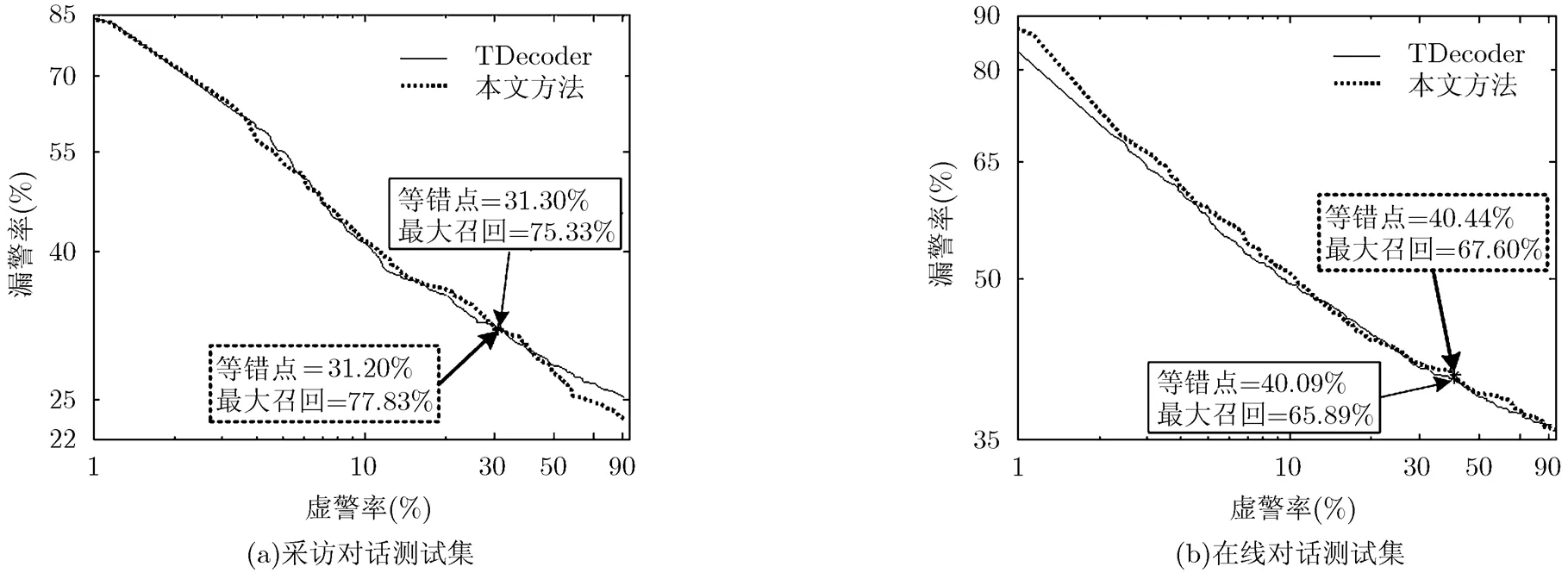
图6 在关键词测试集上的DET图
[1] Shore T, Faubel F, Helmke H,.. Knowledge-based word lattice rescoring in a dynamic context[C]. Proceedings of Interspeech, Portland, 2012: 1337-1340.
[2] Zhang Hao and Gildea D. Efficient multipass decoding for synchronous context free grammars[C]. Proceedings of the Association for Computational Linguistics,Columbus, 2008: 209-217.
[3] Mangu L, Brill E, and Stolcke A. Finding consensus in speech recognition: word error minimization and other applications of confusion networks[J].&, 2000, 14(4): 373-400.
[4] Ortmanns S, Ney H, and Aubert X. A word graph algorithm for large vocabulary continuous speech recognition[J].&, 1997, 11(1): 43-72.
[5] Demuynck K, Duchateau J, Compernolle D V,.. An efficient search space representation for large vocabulary continuous speech recognition[J]., 2000, 30(1): 37-53.
[6] Rybach D, Schluter R, and Ney H. A comparative analysis of dynamic network decoding[C]. Proceedings of IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Prague, 2011: 5184-5187.
[7] Mohri M, Pereira F C N, and Riley M. Speech Recognition with Weighted Finite-State Transducers[M]. Handbook of Speech Processing, Verlag Berlin Heidelberg, Springer, 2008: 559-582.
[8] Ljolje A, Pereira F, and Riley M. Efficient general lattice generation and rescoring[C]. Proceedings of 6th European Conference on Speech Communication and Technology, Budapest, 1999: 1251-1254.
[9] Povey D, Hannemann M, Boulianne G,..Generating exact lattices in the WFST framework[C]. Proceedings of IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Kyoto, 2012: 4213-4216.
[10] Povey D, Ghoshal A, Boulianne G,.. The Kaldi speech recognition toolkit[C]. Proceedings of Automatic Speech Recognition and Understanding Workshop, Hawaii, 2011: 10.1109/ASRU.2011.6163923.
[11] Young S, Russell N, and Thornton J. Token passing: a simple conceptual model for connected speech recognition systems [R]. Report of University of Cambridge, Department of Engineering, 1989: 1-23.
[12] Nolden D, Rybach D, Ney H,.. Joining advantages of word-conditioned and token-passing decoding[C]. Proceedings of IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Kyoto, 2012: 4425-4428.
[13] Satoshi K, Takaaki H, Yoshikazu Y,.. Efficient beam width control to suppress excessive speech recognition computation time based on prior score range normalization [C]. Proceedings of Interspeech, Portland, 2012: 1649-1652.
[14] Guo Yu-hong, Li Ta, Si Yu-jing,.. Optimized large vocabulary WFST speech recognition system[C]. Proceedings of 9th International Conference on Fuzzy Systems and Knowledge Discovery, Chongqing, 2012: 1243-1247.
[15] Shao Jian, Li Ta, Zhang Qing-qing,.. A one-pass real-time decoder using memory-efficient state network[J]., 2008, 91(3): 529-537.
[16] 张鹏远, 韩疆, 颜永红. 关键词检测系统中基于音素网格的置信度计算[J]. 电子与信息学报, 2007, 29(9): 2063–2066.
Zhang Peng-yuan, Han Jiang, and Yan Yong-hong. Phoneme lattice based confidence measures in keyword spotting[J].&, 2007, 29(9): 2063-2066.
郭宇弘: 男,1985年生,博士生,研究方向为语音识别、音频信号处理.
黎 塔: 男,1983年生,助理研究员,研究方向为大词汇连续语音识别.
肖业鸣: 男,1983年生,博士生,研究方向为语音识别、声学模型.
潘接林: 男,1965年生,研究员,博士生导师,主要研究领域包括大词汇连续语音识别、声学模型建模、搜索算法等.
颜永红: 男,1967年生,研究员,博士生导师,2002年入选中科院百人计划,现为中科院语言声学与内容理解重点实验室主任和所长助理.
Exact Word Lattice Generation in Weighted Finite State Transducer Framework
Guo Yu-hong Li Ta Xiao Ye-ming Pan Jie-lin Yan Yong-hong
(,,100190,)
The existing lattice generation algorithms have no exact word end time because the Weighted Finite State Transducer (WFST) decoding networks have no word end node. An algorithm is proposed to generate the standard speech recognition lattice within the WFST decoding framework. The lattices which have no exact word end time can not be used in the keyword spotting system. In this paper, the transformation relationship between WFST phone lattices and standard word lattice is firstly studied. Afterward, a dynamic lexicon matching method is proposed to get back the word end time. Finally, a token passing method is proposed to transform the phone lattices into standard word lattices. A prune strategy is also proposed to accelerate the token passing process, which decreases the transforming time to less than 3% additional computation time above one-pass decoding. The lattices generated by the proposed algorithm can be used in not only the language model rescoring but also the keyword spotting systems. The experimental results show that the proposed algorithm is efficient for practical application and the lattices generated by the proposed algorithm have more information than the lattices generated by the comparative dynamic decoder. This algorithm has a good performance in language model rescoring and keyword spotting.
Automatic speech recognition; Weighted Finite State Transducer (WFST); Lattice generation; Keyword spotting
TP391.42
A
1009-5896(2014)01-0140-07
10.3724/SP.J.1146.2013.00422
2013-04-01收到,2013-07-18改回
国家自然科学基金(10925419, 90920302, 61072124, 11074275, 11161140319, 91120001, 61271426),中国科学院战略性先导科技专项(XDA06030100, XDA06030500),国家863计划项目(2012AA012503)和中科院重点部署项目(KGZD-EW-103-2)资助课题
郭宇弘 guoyuhong@hccl.ioa.ac.cn
